如果用几句话描述排序交换的原理,那么:
- 成对比较数组元素
- 如果左侧*的元素大于右侧的元素,则将交换这些元素
- 重复步骤1-2,直到对数组进行排序
*-左侧的元素表示比较对中的该元素,它更靠近数组的左边缘。 因此,右侧的元素更靠近右侧边缘。对于重复的知名材料,我立即表示歉意,但至少本文中的一种算法不太可能对您有所启发。 关于Habré上的这些排序,它已经被写过很多次了(包括我-1,2,3),并问为什么再次回到这个话题? 但是,由于我决定撰写
有关世界上所有分类的
连贯文章 ,因此即使在
速成版中 ,我也必须经历交换方法。 在考虑以下类时,已经有很多新的(很少有人知道)算法,值得单独撰写有趣的文章。
传统上,“交换器”包括元素随机变化(伪)(bogosort,bozosort,permsort等)的排序。 但是,我没有将它们包括在此类中,因为它们缺乏比较。 将会有一篇关于这些排序的文章,我们在其中对宇宙的概率论,组合论和热死亡进行了很多思考。
傻排序::笨拙排序
- 比较(必要时进行更改)子数组末尾的元素。
- 我们从子数组的开始就取其三分之二,然后将通用算法递归应用于这2/3。
- 我们从子数组的末尾抽取三分之二,然后将通用算法递归应用于这2/3。
- 再一次,我们从子数组的开始就取其三分之二,然后将通用算法递归应用于这2/3。
最初,子数组是整个数组。 然后递归将父子数组拆分为2/3,在分段段的末端进行比较/交换,并最终安排所有内容。
def stooge_rec(data, i = 0, j = None): if j is None: j = len(data) - 1 if data[j] < data[i]: data[i], data[j] = data[j], data[i] if j - i > 1: t = (j - i + 1) // 3 stooge_rec(data, i, j - t) stooge_rec(data, i + t, j) stooge_rec(data, i, j - t) return data def stooge(data): return stooge_rec(data, 0, len(data) - 1)
它看起来是精神分裂症,但仍然是100%正确的。
慢速排序::慢速排序
在这里,我们观察到递归神秘主义:
- 如果子数组由一个元素组成,则我们完成递归。
- 如果子数组由两个或多个元素组成,则将其分成两半。
- 我们将算法递归地应用于左半部分。
- 我们将算法递归地应用于右半部分。
- 比较子数组末尾的元素(并在必要时进行更改)。
- 我们将算法递归地应用于没有最后一个元素的子数组。
最初,子数组是整个数组。 递归将继续减半,比较和更改,直到对所有内容进行排序。
def slow_rec(data, i, j): if i >= j: return data m = (i + j) // 2 slow_rec(data, i, m) slow_rec(data, m + 1, j) if data[m] > data[j]: data[m], data[j] = data[j], data[m] slow_rec(data, i, j - 1) def slow(data): return slow_rec(data, 0, len(data) - 1)
看起来像废话,但是数组是有序的。
为什么StoogeSort和SlowSort正常工作?
一个好奇的读者会问一个合理的问题:为什么这两种算法都起作用? 它们似乎很简单,但是可以将类似的东西排序并不是很明显。
首先让我们看一下慢速排序。 该算法的最后一点暗示,迟缓排序的递归工作仅旨在将子数组中最大的元素放在最右边的位置。 如果将算法应用于延迟排序的数组,则尤其值得注意:
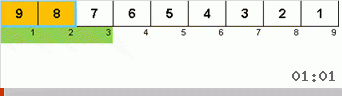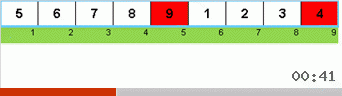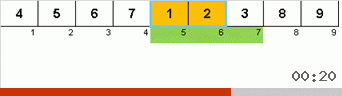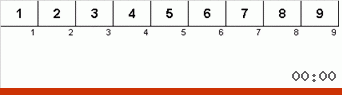
可以清楚地看到,在递归的所有级别上,最大值很快就会向右迁移。 然后将这些最大值(在需要的位置)从游戏中关闭:该算法会自行调用-但没有最后一个元素。
在Stooge排序中,发生了类似的魔术:
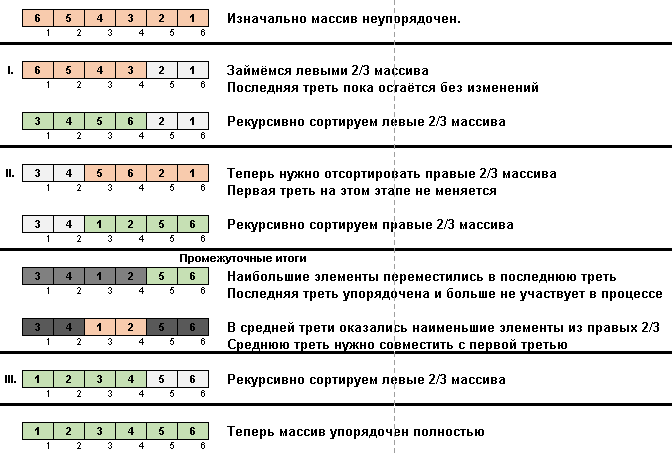
实际上,重点也放在最大的元素上。 只有慢速排序一次将它们移到末尾,而斯托格排序将子阵列的三分之一的元素(最大的元素)压入单元空间的最右边三分之一。
我们转向算法,那里的一切已经很明显了。
哑排序::愚蠢排序

非常仔细的排序。 它从数组的开头到结尾,并比较相邻的元素。 如果必须交换两个相邻元素,以防万一,排序返回到数组的最开始,然后重新开始。
def stupid(data): i, size = 1, len(data) while i < size: if data[i - 1] > data[i]: data[i - 1], data[i] = data[i], data[i - 1] i = 1 else: i += 1 return data
侏儒排序::侏儒排序

几乎是同一件事,但是交换期间的排序不会返回到数组的最开始,而只需要退后一步。 事实证明,这足以解决所有问题。
def gnome(data): i, size = 1, len(data) while i < size: if data[i - 1] <= data[i]: i += 1 else: data[i - 1], data[i] = data[i], data[i - 1] if i > 1: i -= 1 return data
优化的矮人分类

但是,您不仅可以节省撤退费用,而且可以节省前进的费用。 连续进行几次交换后,您必须退后一步。 然后,您必须返回(与已相对排序的元素进行比较)。 如果您记得交换的开始位置,那么在交换完成后,您可以立即跳到该位置。
def gnome(data): i, j, size = 1, 2, len(data) while i < size: if data[i - 1] <= data[i]: i, j = j, j + 1 else: data[i - 1], data[i] = data[i], data[i - 1] i -= 1 if i == 0: i, j = j, j + 1 return data
气泡排序::气泡排序

与愚蠢和侏儒式的分类不同,在气泡中交换元素时,不会有回报-它会继续前进。 到达末尾时,数组的最大元素移到末尾。
然后,分类过程再次重复整个过程,结果,排在第二位的元素排在最后,但只有一个位置。 在下一次迭代中,第三大元素是末尾的第三个元素,依此类推。
def bubble(data): changed = True while changed: changed = False for i in range(len(data) - 1): if data[i] > data[i+1]: data[i], data[i+1] = data[i+1], data[i] changed = True return data
优化气泡排序

您可以从阵列开头的过道中受益。 在此过程中,第一个元素相对于彼此临时排序(此排序部分的大小不断变化-减小,增大)。 这很容易解决,通过新的迭代,您可以简单地跳过一组此类元素。
(稍后我将在这里用Python添加经过测试的实现。我没有时间准备它。)摇床排序::摇床排序
(鸡尾酒排序::鸡尾酒排序)

一种泡沫。 与往常一样,在第一遍操作中-将最大值推到末尾。 然后我们急转弯,将最小值推到开头。 每次迭代后,数组的排序边缘区域的大小都会增加。
def shaker(data): up = range(len(data) - 1) while True: for indices in (up, reversed(up)): swapped = False for i in indices: if data[i] > data[i+1]: data[i], data[i+1] = data[i+1], data[i] swapped = True if not swapped: return data
奇偶排序::奇偶排序

当从左向右移动时,再次对相邻元素进行成对比较迭代。 仅首先,我们比较第一个元素在计数上为奇数,第二个元素为偶数(即第一和第二,第三和第四,第五和第六等)的对。 反之亦然-偶数+奇数(第二和第三,第四和第五,第六和第七等)。 在这种情况下,数组的许多大元素同时进行一次迭代(在气泡中,最大的迭代元素到达末尾,但其余相当大的元素几乎保留在原处)。
顺便说一句,这最初是具有O(n)复杂度的并行排序。 必须在“并行排序”部分中实施
AlgoLab 。
def odd_even(data): n = len(data) isSorted = 0 while isSorted == 0: isSorted = 1 temp = 0 for i in range(1, n - 1, 2): if data[i] > data[i + 1]: data[i], data[i + 1] = data[i + 1], data[i] isSorted = 0 for i in range(0, n - 1, 2): if data[i] > data[i + 1]: data[i], data[i + 1] = data[i + 1], data[i] isSorted = 0 return data
梳子排序::梳子排序

气泡最成功的修改。 速度算法与快速排序竞争。
在所有以前的变体中,我们都比较了邻居。 在这里,首先,要考虑彼此成最大距离的成对元素。 在每次新的迭代中,此距离都会均匀缩小。
def comb(data): gap = len(data) swaps = True while gap > 1 or swaps: gap = max(1, int(gap / 1.25))
快速排序::快速排序

好吧,最先进的交换算法。
- 将数组分成两半。 中间元素是参考。
- 我们从数组的左边缘移到右边,直到找到一个大于引用元素的元素。
- 我们从数组的右边移到左边,直到找到一个小于引用元素的元素。
- 我们交换点2和3中找到的两个元素。
- 我们继续执行项目2-3-4,直到由于相互移动而开会为止。
- 在集合点,数组分为两个部分。 对于每个部分,我们递归地应用快速排序算法。
为什么行得通? 在会合点的左侧是小于或等于参考点的元素。 集合点右侧是大于或等于参考的元素。 即,左侧的任何元素都小于或等于右侧的任何元素。 因此,在集合点,可以将数组安全地划分为两个子数组,并以类似的方式递归地对每个子数组进行排序。
def quick(data): less = [] pivotList = [] more = [] if len(data) <= 1: return data else: pivot = data[0] for i in data: if i < pivot: less.append(i) elif i > pivot: more.append(i) else: pivotList.append(i) less = quick(less) more = quick(more) return less + pivotList + more
K-sort :: K-sort
在Habré上,发表了一篇文章的翻译,其中报道了QuickSort的修改,该修改优于金字塔排序的700万个元素。 顺便说一句,这本身就是一个可疑的成就,因为经典的金字塔分类不会破坏性能记录。 特别是,其渐近复杂度在任何情况下都不会达到O(n)(此算法的一个功能)。
但是事情有所不同。 根据作者(显然是错误的)伪代码,通常无法理解实际上是该算法的主要思想。 就个人而言,我的印象是作者是一些根据这种方法行事的骗子:
- 我们宣布发明超级分类算法。
- 我们使用不起作用且难以理解的伪代码(例如,聪明而清晰,但傻瓜仍然无法理解)来增强该语句。
- 我们提供的图形和表格可以证明该算法在大数据上的实用速度。 由于缺乏真正有效的代码,因此仍然没有人能够验证或驳斥这些统计计算结果。
- 我们以科学文章的名义在Arxiv.org上发布废话 。
- 利润!!!
也许我是在徒劳地与人交谈,实际上该算法有效吗? 谁能解释k-sort的工作原理?
UPD 我对欺诈行为的分类者的广泛指责是毫无根据的:) jetsys用户弄清楚了该算法的伪代码,用PHP编写了一个工作版本,并通过私人消息将其发送给我:PHP中的K-sort function _ksort(&$a,$left,$right){ $ke=$a[$left]; $i=$left; $j=$right+1; $k=$p=$left+1; $temp=false; while($j-$i>=2){ if($ke<=$a[$p]){ if(($p!=$j) && ($j!=($right+1))){ $a[$j]=$a[$p]; } else if($j==($right+1)){ $temp=$a[$p]; } $j--; $p=$j; } else { $a[$i]=$a[$p]; $i++; $k++; $p=$k; } } $a[$i]=$ke; if($temp) $a[$i+1]=$temp; if($left<($i-1)) _ksort($a,$left,$i-1); if($right>($i+1)) _ksort($a,$i+1,$right); }
公告公告
这全是理论,是时候继续实践了。 下一篇文章是测试不同数据集上的排序交换。 我们将发现:
- 最糟糕的排序是什么-愚蠢,无聊或无聊?
- 对气泡排序进行优化和修改真的有用吗?
- 在什么情况下,慢速算法可以轻松快速地实现QuickSort的速度?
当我们找到了这些最重要问题的答案时,我们就可以开始学习下一类-插入排序。
参考文献
Excel应用程序AlgoLab ,您可以使用它逐步查看这些(不仅是这些)排序的可视化。
维基 -
傻 / 笨拙 , 慢 , 矮人 / 侏儒 , 泡泡 / 泡泡 , 摇床 / 摇床 , 奇数 / 偶数 , 梳子 / 梳子 , 快速 / 快速系列文章