我们将继续分享我们在组织数据仓库方面的经验,我们在上一篇文章中开始谈到。 这次我们要谈谈如何解决CDH安装任务。

CDH安装
我们启动Cloudera Manager服务器,将其添加到自动加载并检查它是否已切换为活动状态:
systemctl start cloudera-scm-server systemctl enable cloudera-scm-server systemctl status cloudera-scm-server
上升之后,我们单击链接“主机名:7180 /”,登录(admin / admin)并从GUI继续安装。 授权后,安装将自动开始,并将过渡到用于将主机添加到群集的页面:

建议添加所有将以某种方式与已部署环境连接的主机(即使它们将不托管Cloudera服务)。 这些机器可以是具有连续集成工具,BI或ETL工具或数据发现工具的机器。 将这些计算机包含在群集中将使您能够安装包含文件的群集服务(网关)的网关以及群集服务的配置和位置,这将简化与第三方程序的集成。 Cloudera Manager还提供了方便的监视工具,并在单个窗口中为所有群集计算机创建了关键指标的监视器,这将简化操作过程中问题的定位。 使用“新建搜索”按钮添加主机-切换到用于将计算机添加到群集的页面,建议在该页面中为主机提供通过SSH连接的数据:

添加主机后,我们进入选择安装方法的阶段。 由于我们下载了Parsels,因此我们选择“ Use Parcels(Recommended)”方法,现在我们需要添加存储库。 我们单击“更多选项”按钮,删除那里安装的所有默认存储库,并使用CDH解析器添加存储库地址-“主机名/包裹/ cdh /”。 确认后,在“选择CDH版本”字样的右侧,应显示下载的解析器中显示的CDH版本。 对于此安装方法,无法在此选项卡上配置任何内容:

下一个选项卡将提示您安装JDK。 由于我们已经为安装做准备了,因此我们跳过此步骤:

当您转到下一个选项卡时,将开始在指定主机上安装群集组件。 安装完成后,即可进行下一步转换。 如果在安装过程中遇到错误(在安装本地Dev环境时遇到了这种情况),则可以使用命令“ tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log”查看其详细信息。并点击表格右侧的“详细信息”按钮:

在下一个安装步骤中,系统将提示您选择准备的服务集之一进行安装。 以后,可以手动配置服务及其角色,因此在此选项卡上选择什么并不是很重要。 在我们的案例中,通常安装了“ Core with Impala”。 您还可以在此处指示需要安装Cloudera Navigator。 如果要安装企业版,则应安装此有用的工具:

在用于所选集合的服务的下一个选项卡上,建议选择将要安装它们的角色和主机。 以下是在主机上安装角色的一些准则。
HDFS角色
NameNode-放置在一个主节点(最好是最不负载)上的单个副本中,因为它对集群的运行非常重要,并且对资源利用做出了重大贡献。
SecondaryNameNode-放置在一个主节点上的单个副本中,最好与NameNode不在同一节点上(以确保容错)。
平衡器 -放在一个主节点上的单个副本中。
HttpFS -HDFS的附加API,您无法安装。
NFS网关 -一个非常有用的角色,允许您将HDFS挂载为网络驱动器。 它被放置在一个主节点上的单个副本中。
DataNode-放在所有数据节点上。
蜂巢角色
网关 -Hive配置文件。 它放置在群集的所有主机上。
Hive Metastore Server (元数据服务器)安装在一个主节点上的单个副本中(例如,安装了PostgreSQL的一个节点-它在那里存储数据)。
WebHCat-无需安装。
HiveServer2-与Hive Metastore Server
安装在同一主节点上的单个副本中(共同工作的要求)。
色调角色
Hue Server -HDFS的GUI,安装在一个主节点上的单个副本中。
负载平衡器 -HDFS的GUI上的负载平衡器安装在一个主节点上的单个副本中。
黑斑羚角色
Impala StateStore-放置在一个主节点上的单个副本中。
Impala Catalog Server-放在一个主节点上的单个副本中。
Impala守护程序 -置于所有数据节点上(您可以保留默认值)。
Cloudera Manager服务角色
Service Monitor,Activity Monitor,Host Monitor,Reports Manager,Event Server,Alert Publisher安装在一个主节点上的单个副本中。
Oozie角色
Oozie Server-放在一个主节点上的单个副本中。
角色纱
ResourceManager-放在一个主节点上的单个副本中。
JobHistory Server-安装在一个主节点上的单个副本中。
NodeManager-置于所有数据节点上(您可以保留默认值)。
ZooKeeper角色
ZooKeeper服务器-为确保容错能力,它一式三份地安装在主节点上。
Cloudera Navigator角色
Navigator Audit Server-安装在一个主节点上的单个副本中。
Navigator Metadata Server-放在单个副本中的一个主节点上。

分配角色之后,将出现一个选项卡,其中列出了已安装服务的简短设置列表。 它们的更改将在安装后可用,并且在此阶段可以保持不变:

在服务设置之后,有需要它们的服务的数据库配置。 我们输入安装了PostgreSQL的主机的全名,在“数据库类型”列表框中,选择适当的项目,然后在其余字段中指定用于连接到相应数据库的数据。 输入所有数据后,单击“测试连接”按钮并检查数据库是否可用。 如果是这种情况,则在每个数据库对面的表格的右侧,将显示“成功”字样:

一切准备就绪,可以部署服务。 转到下一个选项卡,并观察此过程。 如果我们做对了所有事情,那么所有步骤将成功完成。 否则,该过程将在以下步骤之一被中断,并且通过按箭头可以查看错误日志:

恭喜-CDH已启动并正在运行!

您可以继续安装其他Parsels。
设置其他parsels
如果基本的CHD服务集不够用或需要更新的版本,则可以安装其他Parsels,以扩展可在群集中部署的服务的可用列表。 在我们的项目期间,我们需要Spark 2.2版服务来启动开发的任务和数据发现工具的功能。 它不是CDH的一部分,因此请单独安装。 为此,请单击“主机”按钮,然后选择“包裹”下拉列表项:

将打开一个带有parsels的选项卡,显示此Cloudera Manager管理的集群的列表以及安装在它们上的parsels。 要使用Spark 2.2添加解析器,请选择所需的群集,然后单击右上角的“配置”按钮。

我们单击“ +”按钮,在出现的行中,使用Spark 2.2解析器(“主机名/包裹/ spark /”)指示存储库的地址,然后单击“保存更改”按钮:

完成这些操作后,一个名为SPARK2的新名称应出现在上一个选项卡上的解析列表中。 最初,它显示为可供下载,因此下一步是通过单击“下载”按钮来下载它:

下载的Parsel需要分散在群集节点上,以便可以从中安装服务。 为此,请单击显示在带有SPARK2解析器的行右侧的“分发”按钮:

处理包裹的最后一步是激活包裹。 我们通过单击“激活”按钮来激活它,该按钮显示在带有解析器的行的右侧:

确认后,就可以安装我们需要的服务。 但是有细微差别。 要在集群中安装某些服务,除了安装解析器外,还需要执行其他任何操作。 通常,这是在官方网站上有关安装和更新此服务的部分中写的(这是她的Spark 2示例-www.cloudera.com/documentation/spark2/latest/topics/spark2_installing.html )。 在这种情况下,您需要下载Spark 2 CSD文件(可在“版本和打包信息”页面上找到-www.cloudera.com/documentation/spark2/latest/topics/spark2_packaging.html ),使用Cloudera Manager将其安装在主机上,然后重新启动后者。 让我们开始吧-下载此文件,将其传输到所需的主机,然后从指令中执行命令:
mv SPARK2_ON_YARN-2.1.0.cloudera1.jar /opt/cloudera/csd/ chown cloudera-scm:cloudera-scm /opt/cloudera/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar chmod 644 /opt/cloudera/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar systemctl restart cloudera-scm-server
当Cloudera Manager上升时,一切都准备就绪,可以安装Spark2。在主屏幕上,单击集群名称右侧的箭头,然后在下拉菜单中选择“添加服务”项:

在可用于安装的服务列表中,选择我们需要的服务:

在下一个选项卡上,选择新服务的依赖项集。 例如,列表较宽的那个:

接下来是带有角色和主机选择的选项卡,将在这些角色和主机上进行安装,类似于CDH的安装过程。 建议您将历史服务器角色放置在一个主节点上的一个副本中,并将网关放置在所有群集服务器上:

选择角色后,建议检查并确认在安装服务期间对集群所做的更改。 您可以在此处默认保留所有内容:

确认更改将开始在群集中安装服务。 如果一切正确完成,则安装将成功完成:
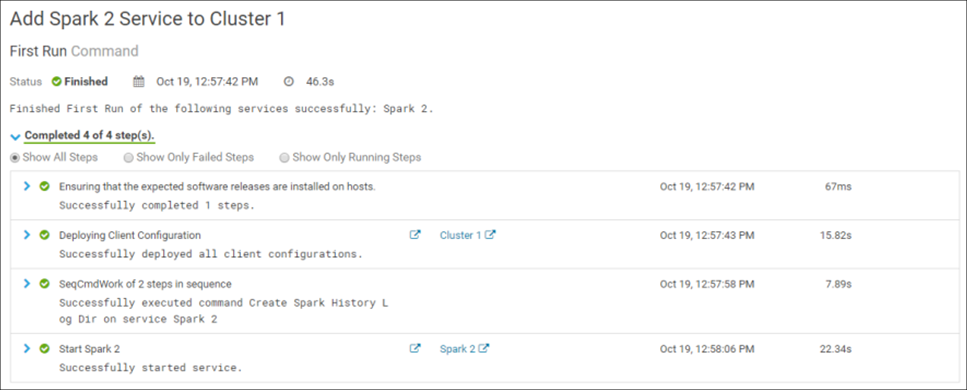
恭喜你! Spark 2已成功安装在集群中:

您必须重新启动集群才能完成安装过程。 之后,一切准备就绪。
在服务的安装阶段可能会发生错误。 例如,在其中一种环境上安装时,无法部署Spark 2 Gateway的角色。 通过将文件/ var / lib / alternatives / spark2-conf的内容从已成功安装此角色的主机复制到问题机器中的类似文件,可以帮助解决该问题。 要诊断安装错误,使用相应进程的日志文件很方便,这些日志文件存储在/ var / run / cloudera-scm-agent / process /文件夹中。
今天就这些了。 该系列的下一篇文章将讨论CDH群集管理的主题。