最近,iMaterialist挑战赛(家具)竞赛在Kaggle结束,其任务是将图像分类为128种家具和家用物品(所谓的细分类,类别之间非常接近)。
在本文中,我将介绍使我们在
m0rtido方面获得第三名的方法,但是在继续讨论这一点之前,我建议使用脑中的自然神经网络来解决此问题,并将以下照片中的椅子分为三类。

你猜对了吗? 我也没有
但是先停下来,第一件事。
问题陈述
在比赛中,我们获得了一个数据集,其中提供了128类普通家用物品,例如动漫人物形式的椅子,电视,锅和枕头。
数据集的训练部分包含约19万张图片(由于参与者仅获得了一组下载URL(其中的某些当然不起作用),因此很难说出确切的数字),而且课程的分布也不尽相同(请参见下面的可点击图片) 。

测试数据集由12800张图片表示,并且完全平衡:每个类别有100张图片。 还发布了一个验证数据集,该数据集也具有均衡的类分布,并且恰好是测试数据集的一半。
任务评估指标为
。
我们如何决定?
首先,我们下载了数据并用眼睛看了一小部分。 而不是许多图片,而是下载了1x1图像或有错误的占位符。 我们立即使用脚本删除了此类图像。
转移学习
很明显,在可用图像数量和时间限制的情况下,在此数据集上从头开始训练神经网络并不是一个好主意。 取而代之的是,我们使用了转移学习方法,其思想如下:在一项任务上训练的网络的权重可以用于完全不同的数据集,并具有不错的质量,甚至与从头开始学习相比,其准确性也得到提高。
如何运作? 深度神经网络中的隐藏层充当特征提取器,提取出的特征然后由上层直接用于分类。
我们通过完成一系列先前在ImageNet上进行过训练的深层CNN来利用这一优势。 为此,我们使用了Keras及其模型动物园,其中以下代码足以加载完成的架构:
base_model = densenet.DenseNet201(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg')
之后,我们从网络中提取了所谓的瓶颈标志(位于最后一个卷积层出口处的特征),并训练了softmax并在它们之上放置了drop。
然后,我们将训练后的“最高”权重连接到网络的卷积部分,并立即训练整个网络。
查看代码。 for layer in base_model.layers: layer.trainable = True top_model = Sequential() top_model.add(Dropout(0.5, name='top_dropout', input_shape=base_model.output_shape[1:])) top_model.add(Dense(128, activation='softmax', name='top_softmax')) top_model.load_weights('top-weights-densenet.hdf5', by_name=True) model = Model(inputs=base_model.input, outputs=top_model(base_model.output)) initial_lrate = 0.0005 model.compile(optimizer=Adam(lr=initial_lrate), loss='categorical_crossentropy', metrics=['accuracy'])
通过对网络进行这样的微调,我们设法尝试了以下技巧:
- 数据扩充 。 为了避免过度拟合,我们使用了非常严格的增强方法:水平反射,缩放,移位,旋转,倾斜,添加颜色噪声,颜色通道移位,对五条裁剪线(图像的角度和中心)进行训练。 我们也想尝试FancyPCA ,但是由于缺乏计算资源而失败了。
- 贸易协定 为了预测验证和测试的班级,我们使用了增强方法,其积极性比训练期间要低一些,并对预测结果取平均值以提高准确性。
- 自行车学习率 。 训练速度的周期性增加和减少帮助模型避免陷入局部低点。
- 在一部分班上进行模型训练 。 从上方的图片可以看出,数据集包含非常接近的类。 如此接近,以致于在某些对象簇上(例如,在最多代表8类的椅子和扶手椅上),我们的模型比在其他类型的对象上更容易出错。 我们试图训练一个单独的CNN仅识别椅子,希望这种网络比通用网络更好地区分椅子的种类,但是这种方法并没有提高准确性。
怎么了 该问题的部分答案显示在剪切之前的图片中-这些类是如此相似,以至于即使使用数据的初始标记,放下这些类标签的人也无法区分它们,因此不可能以很高的准确性挤出这些数据。 - 空间变压器网络 。 尽管我们使用它训练了一个网络并获得了相当不错的准确性,但是不幸的是,它并未包含在最终提交中。
- 加权损失函数 。 为了补偿类别的不平衡分配,我们使用了加权损失。 这不仅有助于培训softmax“顶”,而且还有助于进一步培训整个网络。 使用scikit-learn中的函数计算权重,然后将其传递给模型的拟合方法:
train_labels = utils.to_categorical(train_generator.classes) y_integers = np.argmax(train_labels, axis=1) class_weights = compute_class_weight('balanced', np.unique(y_integers), y_integers)
经过这种方式训练的网络占了我们最终合奏的90%。
堆叠瓶颈标签
免责声明:切勿重复现实生活中稍后描述的技术。
因此,正如我们在上一节中确定的那样,可以将ImageNet上训练的网络的瓶颈功能用于其他任务的分类。
m0rtido决定走得更远,并提出了以下策略:
- 我们采用了所有可用的经过预先训练的架构(特别是NasNet Large,InceptionV4,Vgg19,Vgg16,InceptionV3,InceptionResnetV2,Resnet-50,Resnet-101,Resnet-152,Xception,Densenet-169,Densenet-121,Densenet-201 )并从中提取瓶颈标志。 我们还将计算图片的反射版本的标记(例如,简约的增幅)。
- 在SAR的帮助下,将每个模型的功能尺寸减小三倍,以使它们正常地适合我们可用的16 Gb RAM。
- 将这些特征连接成一个大特征向量。
- 我们将在所有这些之上教一个多层感知器,并产生预测。 我们还将训练成折叠并平均所有这些预测。
产生的怪异堆积使整体整体的准确性大大提高。
模型集合
完成以上所有操作后,我们大约有十二个模糊的卷积网络,以及位于瓶颈标志上方的两个感知器。 问题是:如何从所有这一切中获得一个预测?
在最好的Kaggle传统中,以一种很好的方式,我们必须在所有这些之上
堆叠 ,但是为了进行OOF堆叠,我们既没有时间也没有GPU,并且在验证保持上训练顶级模型会导致很大的过拟合。 因此,我们决定为贪婪的合奏创建一个相当简单的算法:
- 初始化一个空的合奏。
- 我们尝试依次添加每个模型并考虑得分。 我们选择最能增加指标的模型,然后将其添加到集合中。 对集合中模型的预测结果进行简单平均。
- 如果没有一个模型可以提高性能,我们将进行整体测试并尝试从中删除模型。 如果结果是删除某些模型以提高分数,我们将执行此操作并返回到步骤2。
作为指标
。 该公式是根据经验选择的
和
原来是差不多的规模。 这样一个完整的指标与
在验证和公共排行榜上。
此外,在每次迭代中我们添加或删除一个模型(即模型权重始终保持为整数)的事实起到了一种正则化的作用,不允许整体在验证数据集下过度拟合。
结果,该合奏包括以下模型:
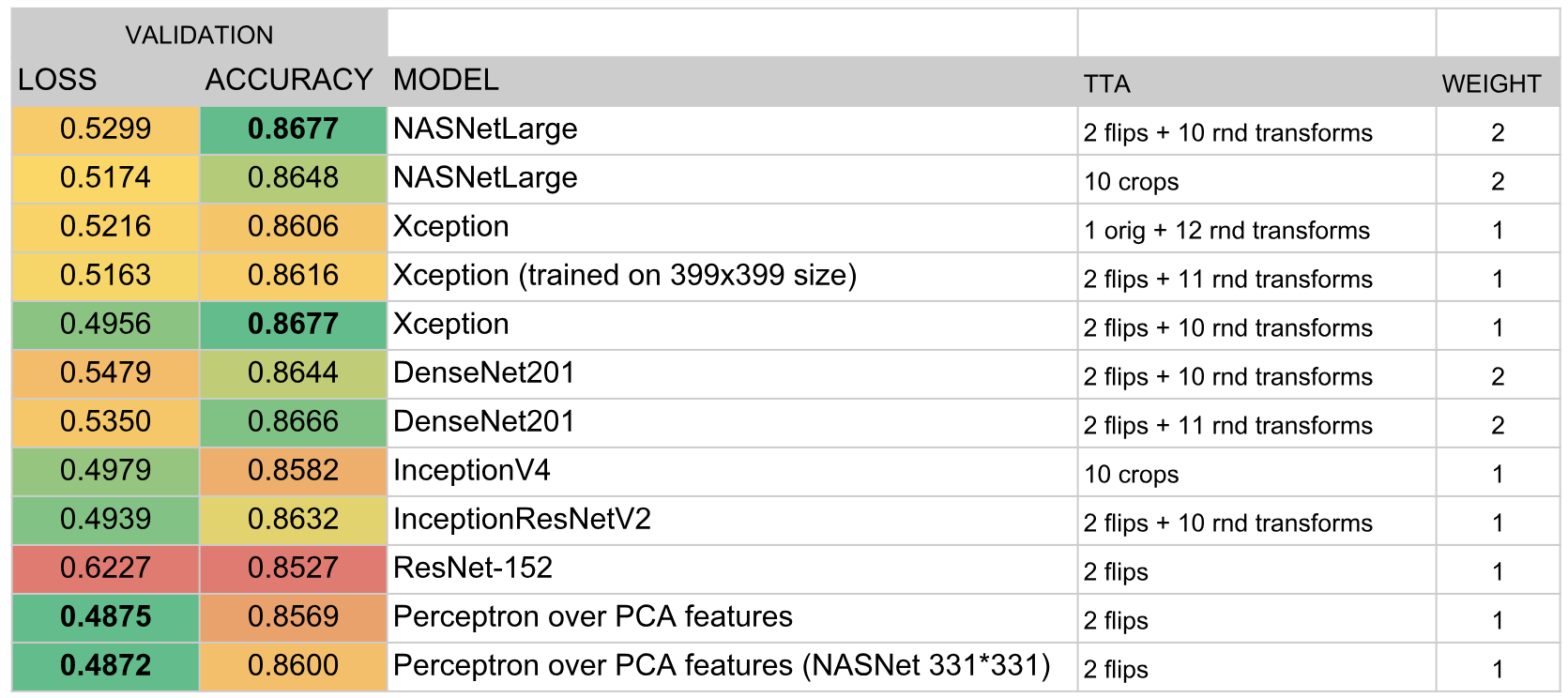
结果
根据比赛结果,我们获得了第三名。 在我看来,成功的关键在于对集成算法的成功选择以及
m0rtido和我在训练大量模型上投入的大量时间。
