你好 我叫Sergey,我是Sbertekh的总工程师。 我从事IT领域已有10年左右,其中6年从事数据库,ETL流程,DWH以及与数据相关的所有工作。 在本文中,我将讨论Vertica-一种分析型,真正的柱状DBMS,它可以有效地压缩,存储,快速交付数据,并且非常适合作为大数据解决方案。

一般资讯
大数据在2000年代开始发展,需要能够消化所有数据的引擎。 为此,出现了许多用于此目的的柱状DBMS-包括Vertica。
Vertica不仅将其数据存储在列中,而且还以高度压缩的方式合理地进行了处理,还有效地调度了查询并快速给出了数据。 在Vertica上,该信息(在经典的小写DBMS中将占用大约1 TB的磁盘空间)将占用大约200-300 GB的空间,因此,我们可以节省大量磁盘空间。
Vertica最初设计为列DBMS。 其他基础基本上只是尝试模仿各种列机制,但由于引擎仍被设计为处理字符串,因此它们并不总是成功。 通常,模仿者只是简单地转置表格,然后使用常规的行机制对其进行处理。
Vertica是容错的,它没有控制节点-所有节点都相等。 如果集群中的一台服务器出现问题,我们仍将接收数据。 通常,按时接收数据对于业务客户至关重要,尤其是在报表关闭且您需要向财务机构提供信息的时候。
应用领域
Vertica主要是一个分析数据仓库。 您不应该在小额交易中给它写信,也不要将它拧到任何站点上,等等。 Vertica应该被视为一种批处理层,值得将数据沉浸在大包装中。 如有必要,Vertica可以非常迅速地提供此数据-数百万行的查询将在几秒钟内完成。
这在哪里有用? 以一家电信公司为例。 Vertica可用于地理分析,网络开发,质量管理,有针对性的营销,研究来自联络中心的信息,管理客户外流以及反欺诈/反垃圾邮件解决方案。

在其他业务部门,一切都差不多-及时可靠的分析对于获利至关重要。 例如,在贸易中,每个人都在尝试以某种方式个性化客户,为此分发折扣卡,收集有关某人在何处,何处以及何时购买的数据等。 通过分析来自所有这些渠道的信息阵列,我们可以对其进行比较,建立模型并做出导致利润增长的决策。
入境门槛
今天,任何雇主都需要分析师来了解什么是SQL。 如果您知道ANSI SQL,则可以将您称为Vertica的自信用户。 如果您可以用Python和R建立模型,那么您只是数据的“按摩师”。 如果您精通Linux并具有Vertica管理的基本知识,那么您可以作为管理员工作。 通常,Vertica中的进入阈值很低,但是,当然,只有在操作过程中用手塞一下才能发现所有细微差别。
硬件架构
考虑群集级别的Vertica。 该DBMS在“无共享”分布式计算体系结构中提供了大规模并行数据处理(MPP),原则上,任何节点都准备好承担任何其他节点的功能。 主要性能:
- 没有单点故障
- 每个节点都是独立的
- 整个系统没有单点连接,
- 基础设施节点重复,
- 群集节点上的数据将自动复制。
群集线性扩展,没有任何问题。 我们只需将服务器放在架子上,然后通过图形界面进行连接即可。 除了串行服务器之外,还可以部署到虚拟机。 扩展可以实现什么?
- 新数据量增加
- 增加最大工作量
- 增强弹性。 群集中的节点越多,群集由于故障而失败的可能性就越小,因此,我们越接近确保24/7可用性。
但是有一些事情要考虑。 必须定期从群集中删除节点以进行维护。 在大型组织中,另一个相当普遍的情况是服务器已超出保修范围,从生产环境过渡到某种测试环境。 取而代之的是受到制造商保修的新产品。 根据所有这些操作的结果,必须进行重新平衡。 这是一个在节点之间重新分配数据的过程-因此,工作量也被重新分配。 这是一个资源密集型过程,在具有大量数据的群集上,它会大大降低性能。 为避免这种情况,您需要选择服务窗口-负载最小的时间,在这种情况下,用户将不会注意到它。
投影
要了解数据如何在Vertica中存储,您需要处理一个基本概念-投影。
信息存储的逻辑单元是图表,表格和视图。 物理单位是投影。 投影有几种类型:
创建任何表格时,都会自动创建一个
超级投影 ,其中包含表格的所有列。 如果您需要加快任何常规过程的速度,我们可以创建一个特殊
的面向查询的投影 ,该
投影将包含10列中的3列。
第三类也用于加速度
汇总的投影 。 我不会涉及它们的子类-这不是很有趣。 我想立即警告您,通过创建新的预测值不断解决查询执行问题并不值得。 最终,群集将开始变慢。
创建投影时,我们需要评估查询是否具有足够的超投影。 如果我们仍要进行实验,则严格添加一个新的投影。 如果出现问题,将更容易找到根本原因。 对于大表,创建分段投影。 它分为多个部分,这些部分分布在多个节点上,这增加了容错能力,并最大程度地减少了一个节点上的负载。 如果平板电脑较小,则最好进行非分段投影。 它们被完全复制到每个节点,从而提高了性能。 我会保留一点:就Vertica而言,一个“小”表大约有100万行。
容错能力
Vertica中的容错功能是使用K-Safety机制实现的。 就描述而言,这非常简单,但在引擎级别的工作方面则非常复杂。 可以使用K-Safety参数对其进行控制-它的值可以为0、1或2。此参数设置分段投影数据的副本数。
投影的副本称为伙伴投影。 我试图通过Yandex-translator来翻译这个短语,结果发现它像是“搭档投影”。 Google提供了更多的选择和有趣的地方。 通常,根据其功能目的,将这些投影称为伙伴或相邻伙伴。 这些是仅存储在相邻节点上并因此保留的投影。 非分段的投影没有伙伴投影-它们被完全复制。
如何运作? 考虑由五台计算机组成的集群。 令K安全等于1。

节点已编号,并在其下写有存储在其上的伙伴投影。 假设我们有一个断开的节点。 会发生什么?

节点1包含节点2的友好投影。因此,节点1上的负载将增加,但是群集不会停止工作。 现在这种情况:
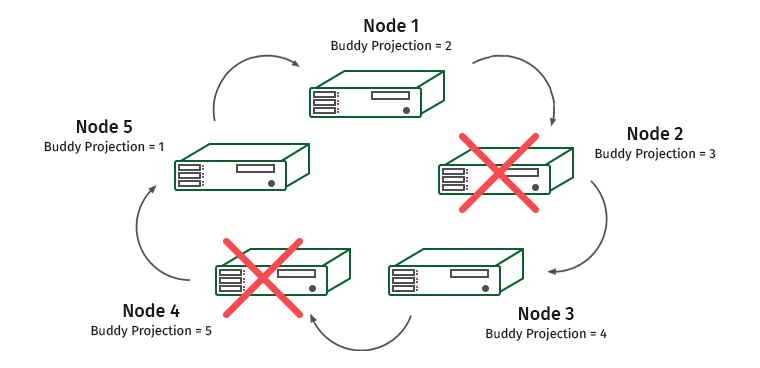
节点3包含节点4的投影,并且节点1和3将过载。
我们使任务复杂化。 K安全= 2,禁用两个相邻节点。
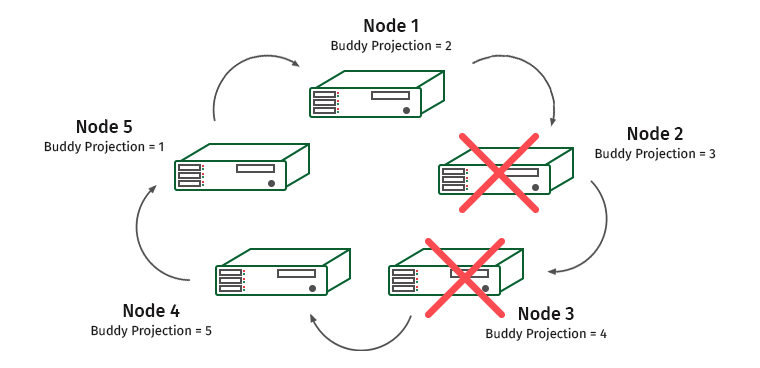
此处,节点1和4将过载(节点2包含节点1的投影,而节点3包含节点4的投影)。
在这种情况下,系统引擎会识别出节点之一没有响应,并且负载已转移到相邻节点。 它将被使用,直到再次还原该节点为止。 一旦发生这种情况,负载和数据将重新分配回去。 一旦我们丢失了一半以上的群集或包含某些数据的所有副本的节点,群集就会启动。
逻辑数据存储
Vertica具有为写入而优化的存储区域,为读取而优化的存储区域以及允许数据从第一个流向第二个的Tuple Mover机制。
当使用COPY,INSERT,UPDATE操作时,我们自动进入WOS(写优化存储)区域,在该区域中,数据没有针对读取而进行优化,并且仅在请求时才进行排序,无需压缩或索引即可存储。 如果数据量对于WOS区域而言太大,则使用附加的DIRECT语句,应立即将它们写入ROS。 否则,WOS将满载,我们将崩溃。
设置中指定的时间到期后,来自WOS的数据将流入ROS(读取优化存储)中-磁盘存储的一种优化的,面向读取的结构。 ROS存储大量数据,在此将其排序和压缩。 ROS数据分为存储容器。 容器是由翻译运算符(COPY DIRECT)创建的一组行,并存储在特定的文件组中。
无论将数据写入何处(在WOS或ROS中),都可以立即使用。 但是,从WOS读取数据的速度较慢,因为数据没有在那里分组。

Tuple Mover是执行以下两项操作的清洁工具:
- Moveout-在WOS中压缩和排序数据,将其移动到ROS,并在ROS中为它们创建新的容器。
- 合并-在使用DIRECT时席卷我们。 我们并非总是能够加载这么多信息来获取大型ROS容器。 因此,它会在后台工作时(根据配置中指定的时间)定期将较小的ROS容器合并为较大的ROS容器,清除标记为删除的数据。
列存储有什么好处?
如果我们读行,那么例如执行一条命令
SELECT 1,11,15 from table1
我们将不得不阅读整个表格。 这是大量信息。 在这种情况下,列方法更有利可图。 它允许您仅计算我们需要的三列,从而节省了内存和时间。

资源分配
为了避免出现问题,需要限制用户。 用户总是有机会编写沉重的请求,这将吞噬所有资源。 默认情况下,Vertica占“常规”区域的很大一部分,此外,突出显示了元组移动器,WOS和系统进程(恢复等)的单独区域。
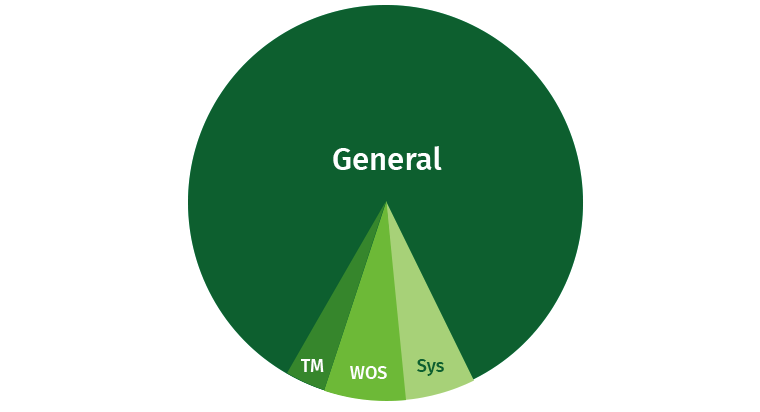
让我们尝试共享这些资源。 我们为作家,读者以及慢速,低优先级的查询创建区域。

如果我们查看存储资源的系统表(资源池),那么我们将看到许多参数,通过这些参数可以更精细地调整所有内容。 开始时,您不应该研究这个问题,最好只是限制自己为某些任务切断内存。 当您获得经验并百分百确定自己所做的一切正确时,就可以进行实验。
精简设置包括执行优先级,竞争性会议和分配的内存量。 即使使用处理器,我们也可以解决问题。要使用这些设置,您需要对操作的正确性充满信心,因此最好寻求业务支持并有权犯错误。
下面是一个请求示例,通过它可以查看常规池的设置:
dbadmin => select * FROM resource_pools WHERE NAME = 'general';
-[ RECORD 1 ]------------+---------------
pool_id | 45035996273721212
name | general
is_internal | t
memorysize |
maxmemorysize | 30G
executionparallelism | AUTO
priority | 0
runtimepriority | MEDIUM
runtimeprioritythreshold | 2
queuetimeout | 0:05
plannedconcurrency | 10
maxconcurrency | 20
runtimecap |
singleinitiator | f
cpuaffinityset |
cpuaffinitymode | ANY
cascadeto |ANSI SQL和其他功能
- Vertica允许您用SQL-99编写-支持所有功能。
- Verica具有强大的分析功能-甚至包括机器学习工具
- Vertica可以索引文本
- Vertica处理半结构化数据
整合性
与所有当前工具一样,Vertica已与其他系统认真集成。 能够与HDFS(Hadoop)良好配合。 在早期版本中,Vertica只能从某些格式的HDFS下载数据,但是现在它可以执行所有操作,并且可以与所有格式配合使用,例如ORC和Parquet。 它甚至可以将文件作为外部表附加,并将其数据直接存储在HDFS上的ROS容器中。 在Vertica的第八个版本中,对HDFS,元数据目录和这些格式的解析速度进行了重大优化。 您可以直接在Hadoop群集上构建Vertica群集。
从7.2版开始,Vertica可以与Apache Kafka一起使用-如果有人需要消息代理。
Vertica 8完全支持Spark。 可以将数据从Spark复制到Vertica,反之亦然。
结论
对于不需要大量输入知识的大数据,Vertica是一个不错的选择。 该DBMS具有广泛的分析功能。 缺点-此解决方案不是开源的,但是您可以尝试免费部署1 TB的限制和三个节点-这足以了解您是否需要Vertica。