所有现代的审核系统都使用
众包或机器学习,这已经成为经典。 在Yandex的下一次ML培训中,康斯坦丁·科蒂克(Konstantin Kotik),伊戈尔·加利茨基(Igor Galitsky)和阿列克谢·诺斯科夫(Alexey Noskov)谈到了他们参与大批冒犯性评论的比赛。 比赛在Kaggle平台上举行。
大家好! 我叫康斯坦丁·科蒂克(Konstantin Kotik),我是“生命之钥”公司的数据科学家,物理系的学生,莫斯科国立大学商学院的学生。
今天,我们的同事Igor Galitsky和Alexei Noskov将向您介绍有关“有毒评论分类挑战赛”的比赛,在该比赛中,我们的DecisionGuys团队在4551个团队中排名第十。
在线讨论对我们重要的主题可能很困难。 在线发生的侮辱,侵略和骚扰经常迫使许多人放弃对他们感兴趣的问题的各种适当观点的搜索,拒绝表达自己。
许多平台都难以有效地在线交流,但这常常导致许多社区仅关闭用户评论。
来自Google和另一家公司的一个研究小组正在研究工具,以帮助改善在线讨论。
他们关注的技巧之一是探索负面的在线行为,例如有毒评论。 这些评论可能令人反感,无礼,或者仅迫使用户退出讨论。

迄今为止,该小组已经开发了一种公共API,可以确定评论的毒性程度,但是他们当前的模型仍然会出错。 在这场比赛中,我们(即Kegglers)面临挑战,要求他们建立一个模型,该模型能够识别包含威胁,仇恨,侮辱等内容的评论。 理想情况下,要求此模型要优于其API的当前模型。
我们的任务是文本处理:识别注释,然后对其进行分类。 作为培训和测试样本,从Wikipedia讨论页面提供了评论。 火车上大约有16万条评论,测试中有15.4万条评论。

训练样本标记如下。 每个评论都有六个标签。 如果注释包含这种类型的毒性,则标签的值为1,否则为0。 可能所有标签均为零,这是一个足够的注释情况。 或者,可能一个评论包含多种类型的毒性,立即构成威胁和淫秽。
由于我们正在进行直播,因此我无法演示这些课程的具体示例。 对于测试样品,对于每个注释,有必要预测每种毒性的可能性。
质量指标是在毒性类型上平均的ROC AUC,即每个类别的ROC AUC的算术平均值。
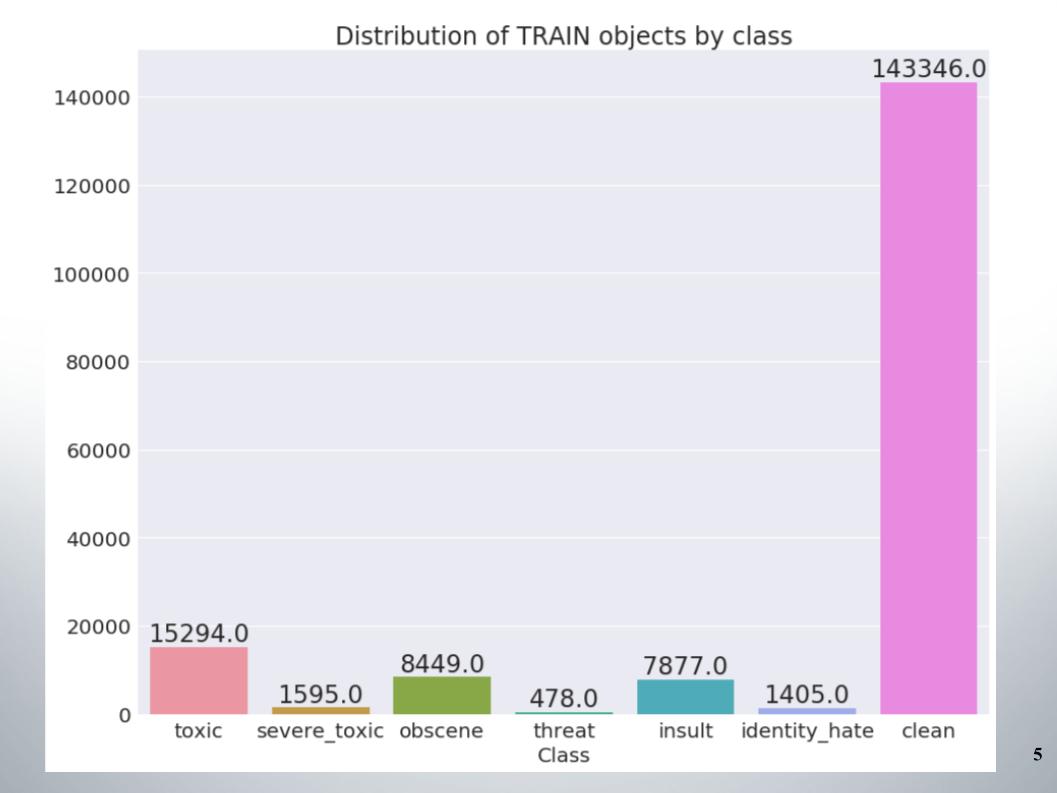
这是训练集中按类的对象分布。 可以看出,数据非常不平衡。 我必须马上说,我们的团队在处理不平衡数据的方法样本中得分很高,例如过采样或欠采样。

在构建模型时,我使用了两阶段的数据预处理。 第一个阶段是数据的基本预处理,这些是幻灯片上视图的转换,这会将文本转换为小写,删除链接,IP地址,数字和标点符号。

对于所有模型,均使用此基本数据预处理。 在第二阶段,对数据进行了部分预处理-用相应的单词替换表情符号,解密缩写,纠正亵渎性拼写错误,将不同类型的垫子变成相同的形式,并删除图像。 在某些评论中,指示了指向图像的链接,我们只是删除了它们。
对于每个模型,都使用了部分数据预处理及其各种元素。 进行所有这些操作是为了使基础模型在构建进一步的组合时减少基础模型之间的互相关。
让我们继续进行最有趣的部分-建立模型。
我立即放弃了经典的言语方式。 由于采用这种方法,每个单词都是一个单独的属性。 这种方法没有考虑一般的单词顺序;假定单词是独立的。 在这种方法中,发生文本的生成,使得单词中存在某种分布,从该分布中随机选择一个单词并将其插入到文本中。
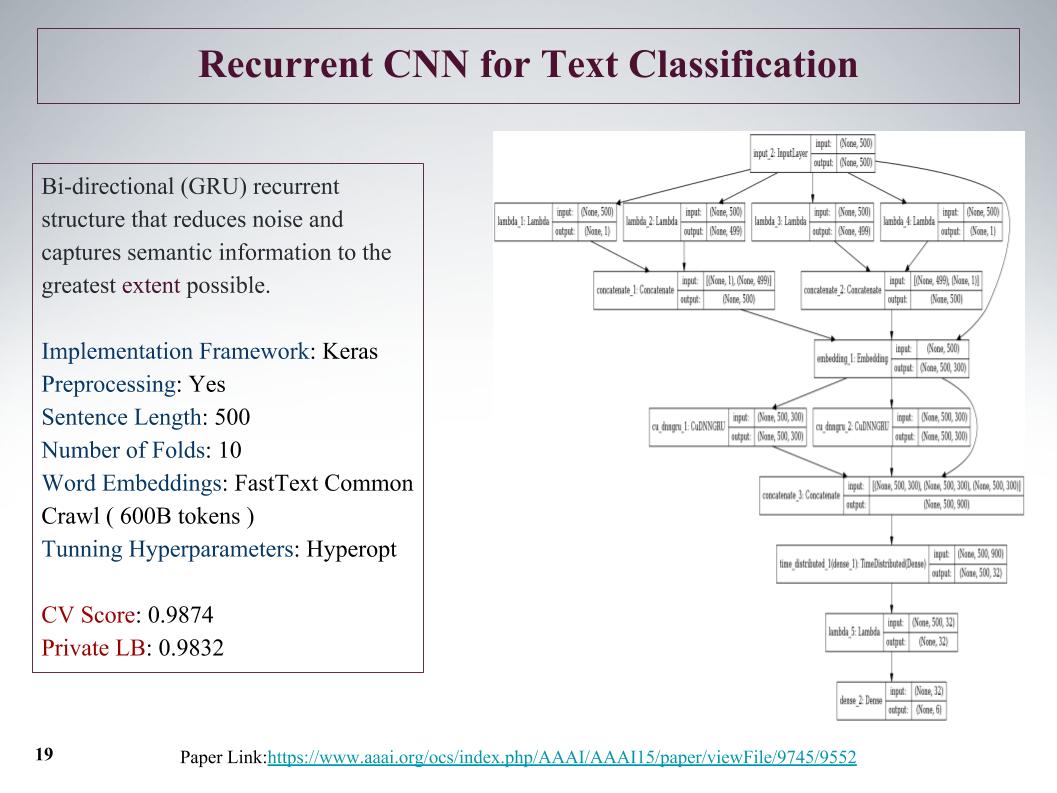
当然,有更复杂的生成过程,但是本质没有改变-这种方法没有考虑一般的单词顺序。 您可以去看英语,但是这里只考虑单词的窗口顺序,而不是一般的。 因此,我也了解我的队友,他们需要使用更智能的东西。
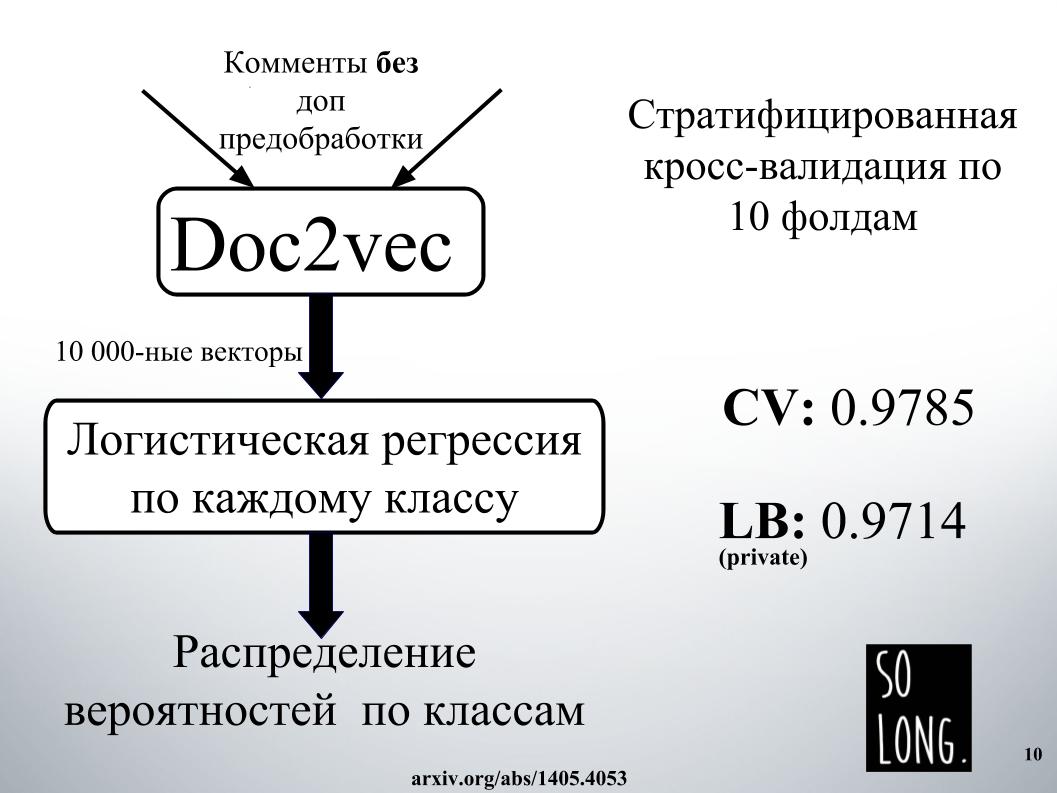
我想到的第一个聪明的事情是使用Doc2vec的矢量表示。 这是Word2vec加上一个考虑到特定文档的唯一性的向量。 在原始文章中,此向量称为id段落。
然后,根据这种向量表示,研究了逻辑回归,其中每个文档都由10,000维向量表示。 质量评估是对10倍的交叉验证进行的,已进行分层,重要的是要注意,对每个类别进行了逻辑回归研究,分别解决了六个分类问题。 最后,结果是按类别的概率分布。
逻辑回归已经训练了很长时间。 我通常不适合放入RAM。 在Igor的工厂里,他们花了一天的时间来获得结果,就像在幻灯片上一样。 因此,由于期望很高,我们立即拒绝使用Doc2vec,尽管如果对注释进行了额外的数据预处理,则可以将其提高1000。

我们和其他竞争对手使用的更智能的是递归神经网络。 他们依次在入口处接收单词,在每个单词之后更新其隐藏状态。 Igor和我使用GRU递归网络将单词嵌入fastText,它的特殊之处在于它解决了许多独立的二进制分类问题。 独立预测上下文词的存在或不存在。
我们还对十折交叉验证进行了质量评估,此处未分层,此处概率是按班级立即获得的。 二元分类的每个问题都没有单独解决,但是立即生成了六维向量。 这是我们最好的单机之一。
你问,成功的秘诀是什么?
它由混合,混合,堆叠和联网组成。 网络方法需要描述为有向图。
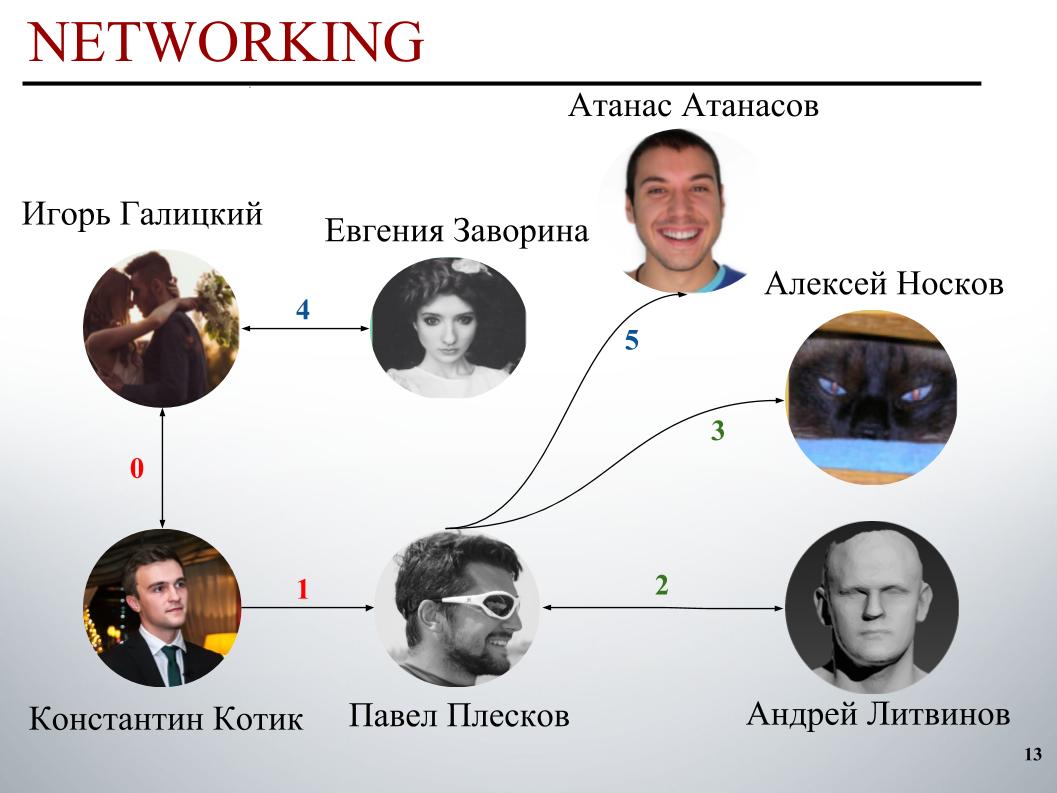
比赛开始时,DecisionGuys团队由两人组成。 然后,ODS Slack频道中的Pavel Pleskov表达了他希望与前200名中的某个人合作的愿望。 当时我们在第157位,帕维尔·普列斯科夫(Pavel Pleskov)在第154位,在附近。 伊戈尔注意到了他加入的愿望,我邀请他加入团队。 然后安德烈·利特维诺夫(Andrey Litvinov)加入了我们,然后帕维尔(Pavel)邀请了大师阿列克谢·诺斯科夫(Alexei Noskov)加入我们的团队。 伊戈尔-尤金。 我们团队的最后一个伙伴是保加利亚的Atanas Atanasov,这是国际人类合奏的结果。
现在,伊戈尔·加利茨基(Igor Galitsky)将讲述他如何教授gru,他将更详细地讨论帕维尔·普列斯科夫(Pavel Pleskov),安德烈·利特维诺夫(Andrei Litvinov)和阿塔纳斯·阿塔纳索夫(Atanas Atanasov)的思想和方法。
伊戈尔·加利茨基(Igor Galitsky):
-我是Epoch8的数据科学家,我将讨论我们使用的大多数架构。
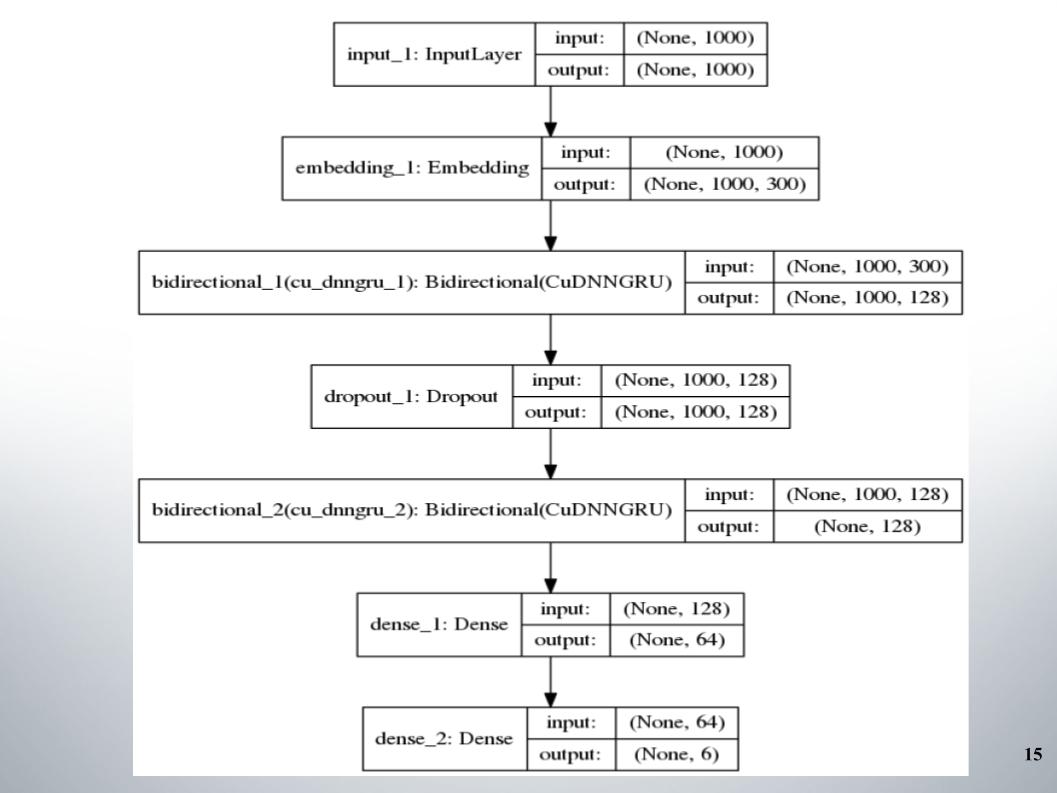
这一切都始于具有两层的标准双向gru,几乎所有团队都使用了它,并且EL激活功能fastText被用作嵌入。
没有什么特别的要说的,简单的架构,没有多余的装饰。 她为什么给我们这么好的成绩,使我们在相当长的时间内保持在前150名? 我们对文本进行了很好的预处理。 有必要继续前进。
保罗有他自己的方法。 与我们的产品融合后,这大大增加了。 在此之前,我们在Doc2vec上进行了gru和模型混合,得到了61磅。
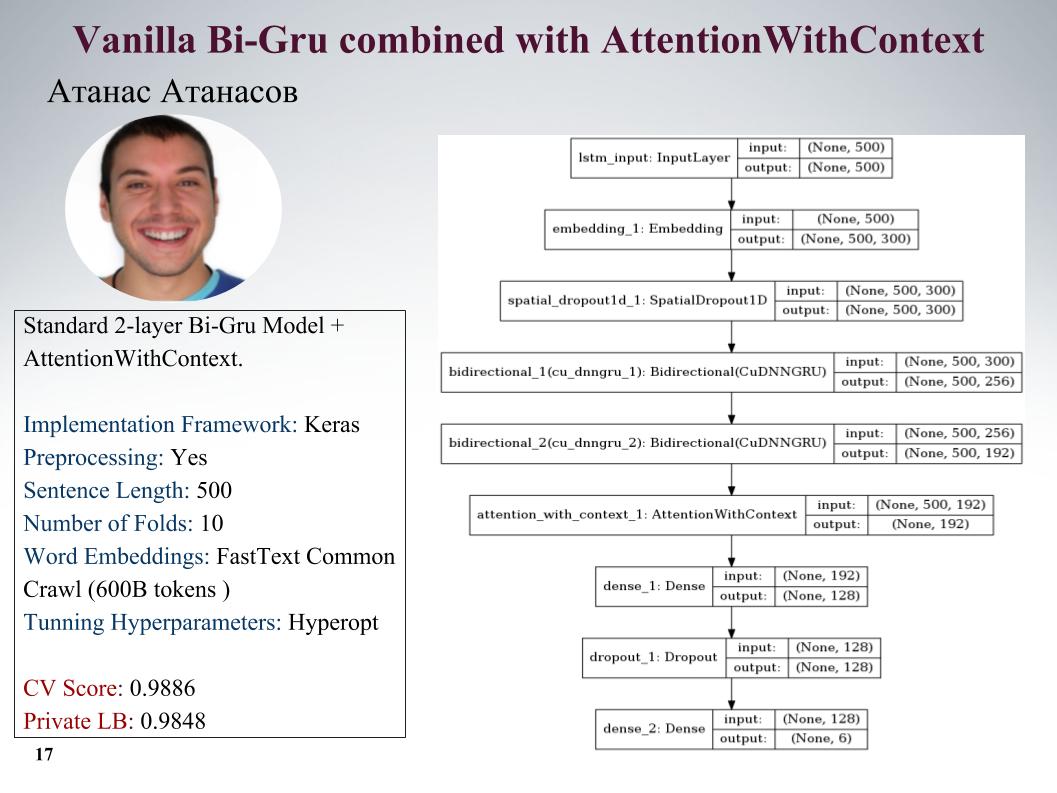
我将向您介绍Atanas Atanasov的方法,他直接是任何新文章的发烧友。 请注意幻灯片上的所有参数。 他有很多非常酷的方法,但是直到最后一刻,他都使用了预处理程序,所有利润都得到了平衡。 在幻灯片上加快速度。
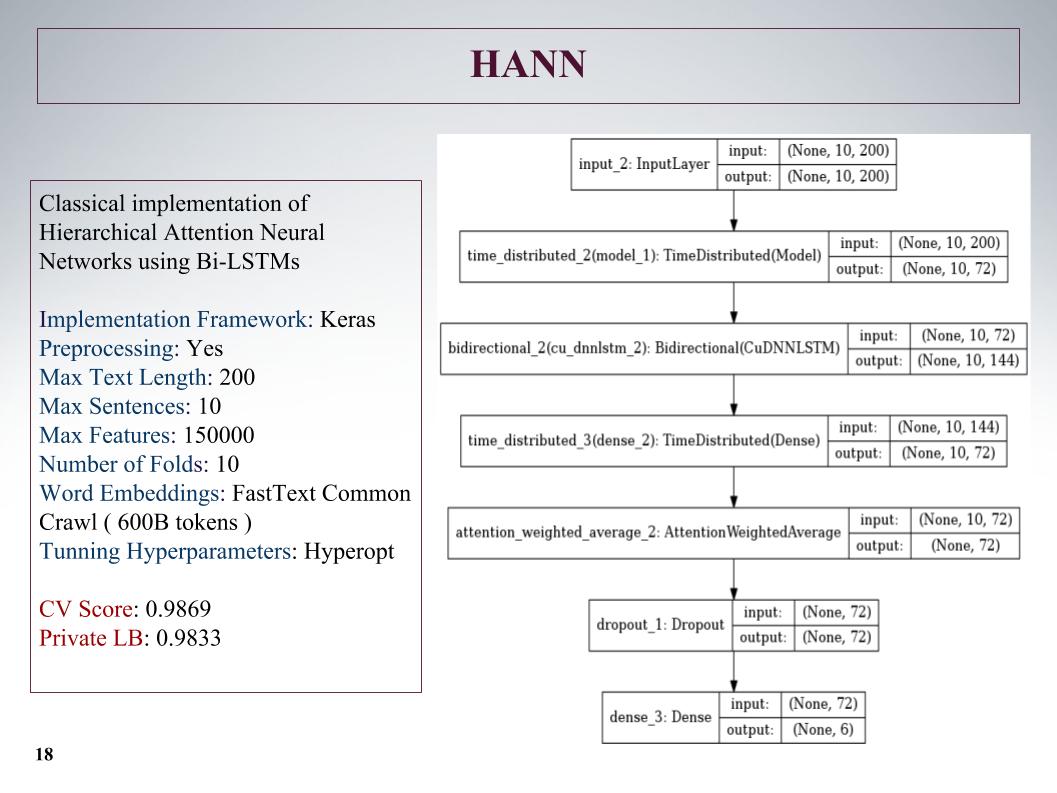
然后受到了层次结构的关注,结果却更糟,因为最初它是一个用于对包含句子的文档进行分类的网络。 他搞砸了,但是方法不是很好。
有一种有趣的方法,我们可以从头到尾从产品开始获得功能。 借助卷积,卷积层,我们分别在树的左侧和右侧获得要素。 这是从句子的开头和结尾开始,然后它们合并并再次遍历gru。

还有Bi-GRU与注意块。 这是当时最好的私有网络之一,网络比较深,显示出良好的效果。

下一种方法是尽可能突出显示功能? 在循环网络层之后,我们再进行三个并行的卷积层。 在这里,我们花了很短的句子,将它们减少到250个,但是由于三次卷积,结果很好。

这是最深的网络。 正如Atanas所说,他只是想教一些有趣的大事。 从文本特征中学到的普通卷积网格,结果没有什么特别的。

这是一个相当有趣的新方法,2017年有一篇有关该主题的文章,用于ImageNet,它使我们可以将之前的结果提高25%。 它的主要特征是平行于卷积块发射一小层,它教导了该块中每个卷积的权重。 尽管减刑,她还是采取了很酷的方法。
问题在于这些任务中句子的最大长度达到1500个单词,其中有非常大的注释。 其他团队也考虑过如何抓住这个大要约,如何寻找,因为一切都不是很顺利。 许多人说,句子结尾处有一个非常重要的INFA。 不幸的是,在所有这些方法中,都没有考虑到这一点,因为这是开始的。 也许这会进一步增加。

这是AC-BLSTM体系结构。 底线是,如果将下部划分为两部分,除了注意,还可以巧妙地将其拉开,但是平行仍然是正常的,这都是具体化的。 效果也不错。

而Atanas是他的整个模型动物园,那真是太酷了。 除了模型本身之外,我还添加了一些文本功能,通常包括长度,大写字母数,不良词数,字符数。 交叉验证五折,并在私人LB 0.9867上获得了出色的结果。
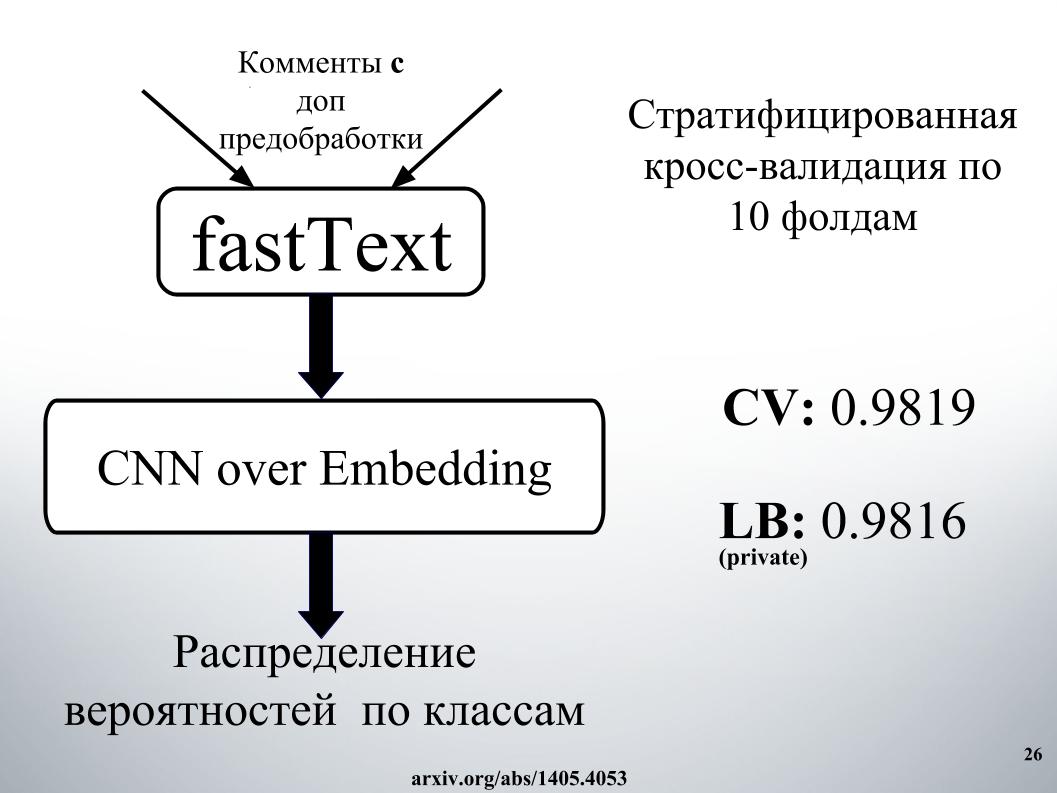
第二种方法,他采用了不同的嵌入方式进行教学,但结果却更糟。 通常每个人都使用fastText。
我想谈谈我们的另一位同事Andrei在ODS上的昵称Laol的方法。 他教了很多公共内核,他好像自己都不喝了一样就喝了,这确实产生了非常酷的结果。 您无法做到所有这些,但是即使在tf-idf上,也可以使用许多不同的公共内核,其中有各种各样的gru卷积。
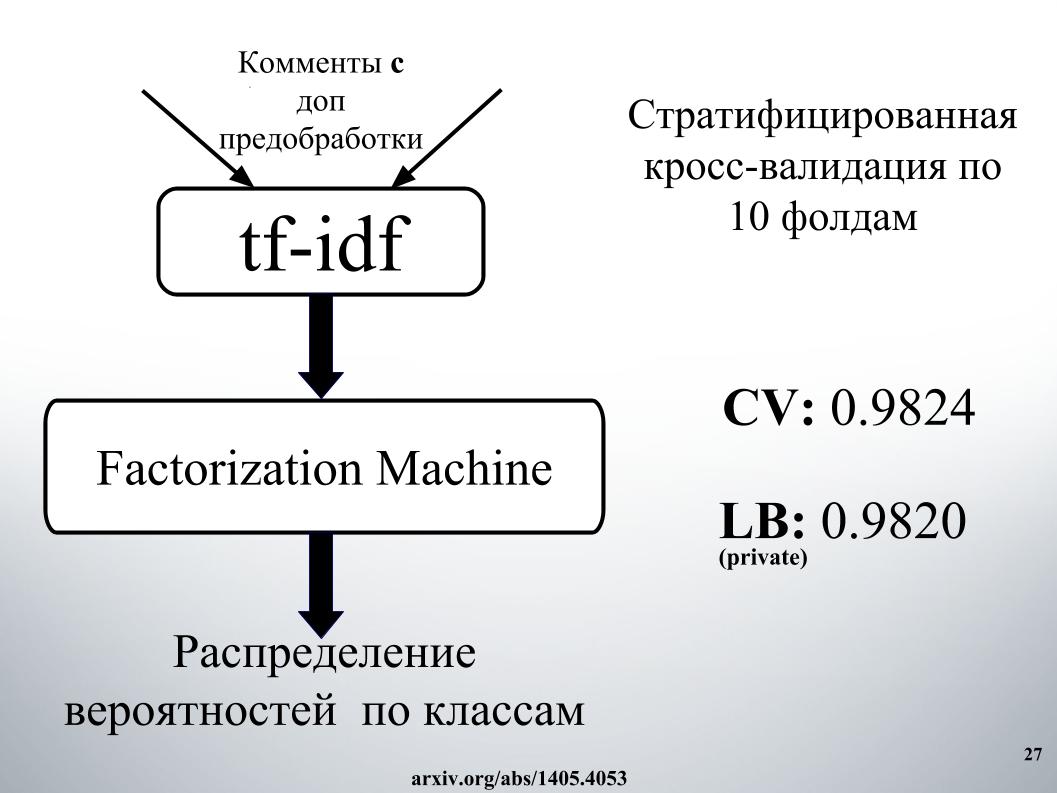
他拥有最好的方法之一,我们一直在前15名中待了很长时间,直到Alexey和Atanas加入我们为止,他将所有这一切融合在一起。 这也是一个非常酷的时刻,据我所知,没有一个团队使用过,然后我们还根据组织者API的结果创建了功能。 关于这个进一步告诉亚历克斯。
阿列克谢·诺斯科夫(Alexey Noskov):
嗨 我将向您介绍我使用的方法以及我们如何完成该方法。

一切对我来说都足够简单:交叉验证的10倍,模型在具有不同预处理的不同向量上进行了预训练,因此它们在集合中具有更多的多样性,少量的扩充和两个开发周期。 第一个基本上从一开始就起作用,它训练了一定数量的模型,研究了交叉验证错误,弄清了哪些示例上明显的错误,并根据此示例纠正了预处理,因为这样更清楚了如何修复它们。
最后使用的第二种方法讲授了一些模型集,研究了相关性,发现了彼此之间弱相关的模型块,加强了由它们组成的部分。 这是我的模型之间的交叉验证相关性矩阵。
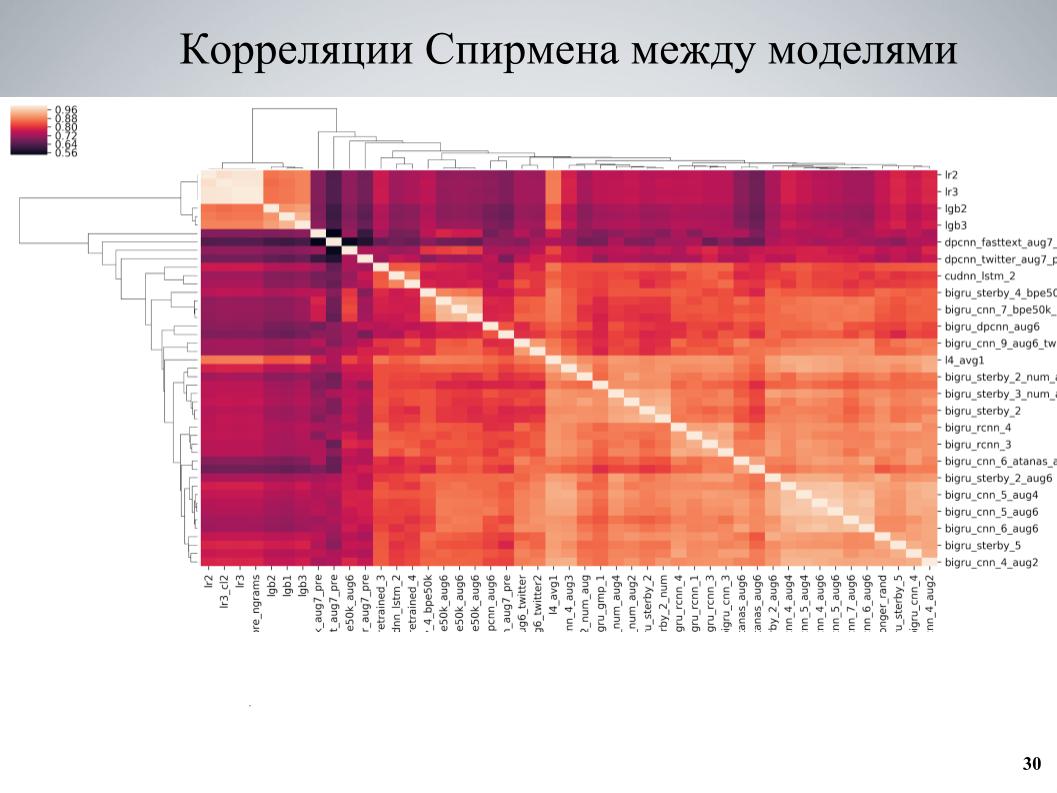
可以看出,它在某些地方具有块状结构,虽然有些模型质量很好,但是与其他模型之间的关联性很弱,当我以这些模型为基础,教给他们几种不同的变化时,会获得很好的结果。超参数或预处理,然后添加到集合中。

对于增强,由Pavel Ostyakov在论坛上发布的想法最引人注目。 它包含以下事实:我们可以发表评论,将其翻译成其他语言,然后再返回。 作为双重翻译的结果,获得了重新格式化,虽然有些损失,但是总体上却获得了类似的略有不同的文本,也可以对其进行分类,从而扩展数据集。
第二种方法并没有多大帮助,但也有所帮助,是您可以尝试进行两个任意注释(通常不会很长),将它们粘在一起,然后将标签的组合或一点点热情作为目标上的标签,其中只有一个他们包含一个标签。
如果不事先将它们应用于整个集合,而是更改每个时代都应应用增强的示例集,这两种方法都将很好地工作。 举例来说,在形成批处理过程的每个时代,我们都会选择30%的示例进行翻译。 相反,预先在内存中已经存在并行的位置,我们只需根据它选择要翻译的版本,然后在培训期间将其添加到批处理中。

一个有趣的区别是在BPE训练的模型。 有一个SentencePiece-一个Google令牌生成器,可让您拆分为完全没有UNK的令牌。 一个有限的字典,其中任何字符串都被分解为一些标记。 如果实际文本中的单词数大于词典的目标大小,则它们会分解成较小的片段,从而在字符级和单词级模型之间获得一种中间方法。
那里使用了两种主要的构造算法:BPE和Unigram。 对于BPE算法,在网络中找到预先标记的嵌入很容易,并且使用一些固定的词汇表-我只有50k的词汇量-我还可以训练模型,这些模型给出了很好的(听不清-大约是Ed),还差一点,与fastText上的平常相比,它们之间的关联性非常弱,并且可以提供很好的提升。
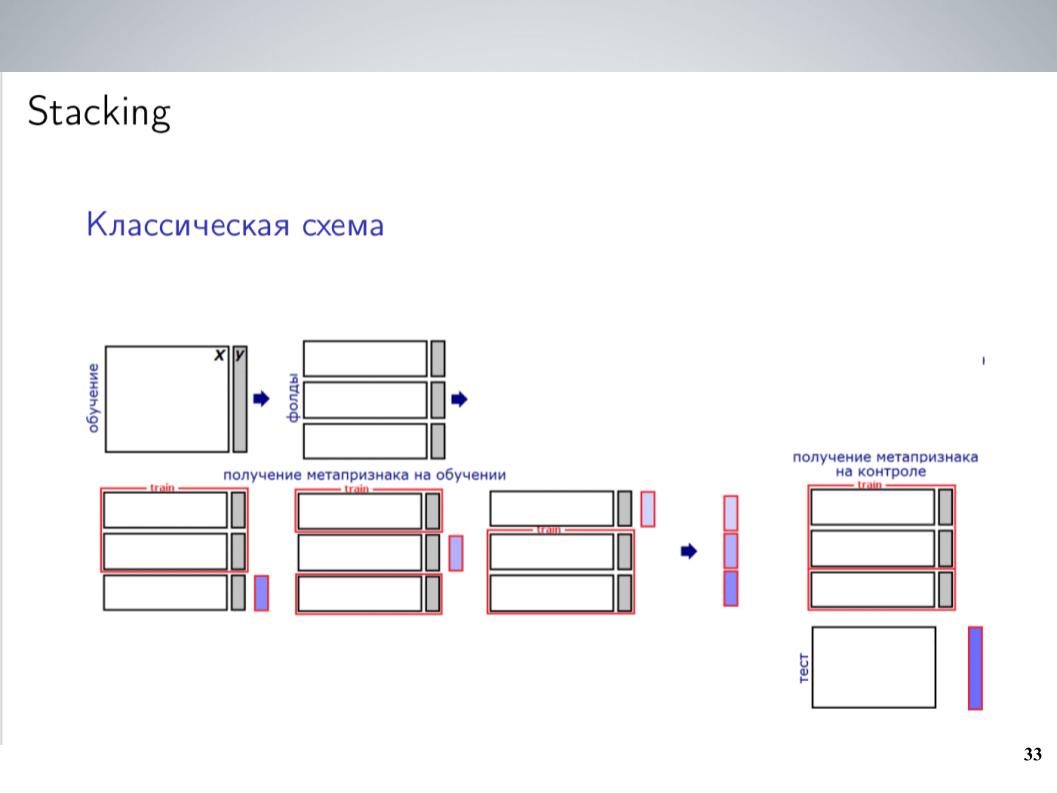
这是经典的堆叠方案。 通常,在比赛的大部分时间里,在合并之前,我通常只是简单地混合所有模型而没有权重。 这给出了最好的结果。 但是合并之后,我得到了一个稍微复杂一点的方案,最终给了我很大的帮助。

我有很多型号。 只是将它们全部丢入某种堆垛机中? 他对其进行了重新训练,但效果不是很好,但是由于模型是高度相关的组,因此我将它们简单地组合成这些组,在每个组中,我平均了5-7组非常相似的模型,这些模型作为下一级别使用平均值。 我对此进行了培训,对20个带有不同示例的发布进行了测试,上传了一些类似于Atanas所做的元功能,最终它终于开始工作,比简单平均有了更多的推动力。

最重要的是,我添加了Andrei发现的API,该API包含一组相似的标签。 组织者最初为他们建立了模型。 由于最初是不同的,因此参与者没有使用它,因此不可能简单地将它与我们需要预测的结果进行比较。 但是,如果将它作为元功能投入到功能完善的堆栈中,那么它将会带来极大的提升,尤其是在TOXIC类中,这显然是排行榜上最困难的一环,并且使我们最终可以进入最后几个位置,就在最后一天。

由于我们发现堆栈和API对我们来说效果很好,因此在最终提交之前,我们毫不怀疑它会被移植到私有平台上。 它的工作非常可疑,所以我们根据以下原则选择了两个提交:一个-混合了之前没有收到API的模型,再加上与API的形而上学的堆叠。 事实证明,在公开场合为0.9880,在私有场合为0.9874。 在这里,我的标记感到困惑。

第二个是没有API的模型的混合,没有使用堆栈,也没有使用LightGBM,因为有人担心这是对公众的某种较小的再培训,我们可以这样做。 确实发生了,他们没有飞走,因此,以0.9876的私人成绩我们获得了第十名。 仅此而已。