我被告知,在新计算机上,一些回归测试变慢了。 这是常见的事情。 Windows中某处的配置不正确,或者BIOS中不是最佳值。 但是这次我们无法找到相同的“淘汰”设置。 由于变化是显着的:9对比19秒(在图表中,蓝色是旧的铁,橙色是新的铁),所以我不得不更深入地研究。
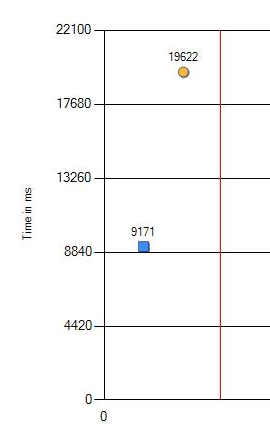
相同的操作系统,相同的硬件,不同的处理器:慢2倍
从9.1秒降低到19.6秒的性能绝对可以称为显着。 我们通过更改测试程序的版本,Windows和BIOS设置进行了其他检查。 但是不,结果没有改变。 唯一的区别仅出现在不同的处理器上。 以下是最新CPU上的结果。
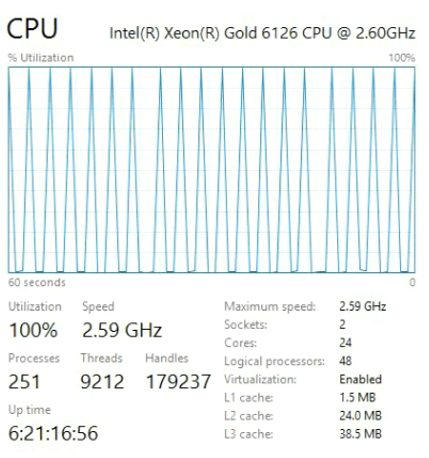
这是用于比较的一个。

自2017年中以来,Xeon Gold在另一种名为Skylake的架构上运行,该架构在新型Intel处理器中通用。 如果您购买了最新的硬件,则将获得具有Skylake架构的处理器。 这些都是好车,但是,正如测试所示,新颖性和速度并不是一回事。
如果没有其他帮助,则需要使用探查器进行深入研究。 让我们在旧设备和新设备上进行测试,然后得到以下内容:
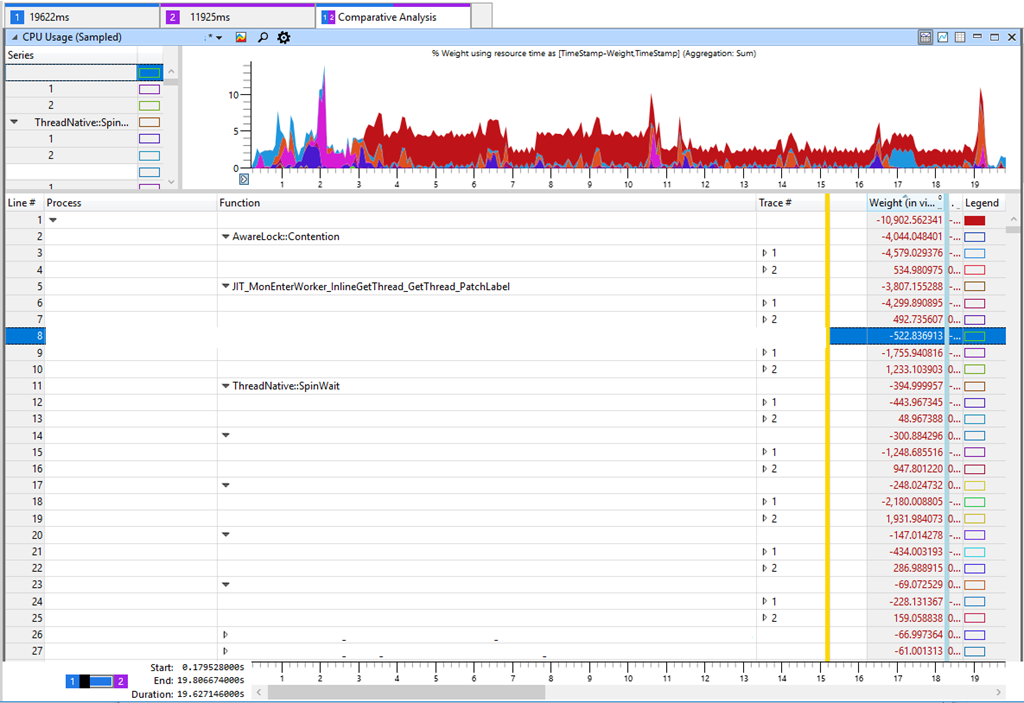
Windows Performance Analyzer(WPA)中的选项卡在表中显示了Trace 2(11 s)和Trace 1(19 s)之间的差异。 表中的负差对应于较慢测试中CPU消耗的增加。 如果您查看CPU消耗方面最明显的不同,我们将看到
AwareLock :: Contention ,
JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel和
ThreadNative.SpinWait 。 一切都表明CPU中有一个“旋转” [旋转-周期性尝试获得锁,大约为1。 per。],当线程为阻塞而战时。 但这是一个错误的标记,因为纺丝不是生产率下降的主要原因。 越来越多的人争抢锁,这意味着我们软件中的某些东西已经放慢了速度并保持了锁,结果导致CPU旋转速度增加。 我检查了锁定时间和其他关键指标(例如磁盘性能),但是找不到任何可以解释性能下降的有意义的信息。 尽管这不合逻辑,但是我还是以各种方法返回了增加CPU负载的方法。
确切地找到处理器卡住的位置将很有趣。 WPA具有文件号和行号列,但是它们仅适用于私有字符,而我们没有,因为这是.NET Framework代码。 我们可以做的第二件事是获取名为Image RVA的指令所在的dll地址。 如果将此dll加载到调试器中并执行
u xxx.dll+ImageRVA那么我们应该看到消耗大多数CPU周期的指令,因为它将是唯一的“热”地址。
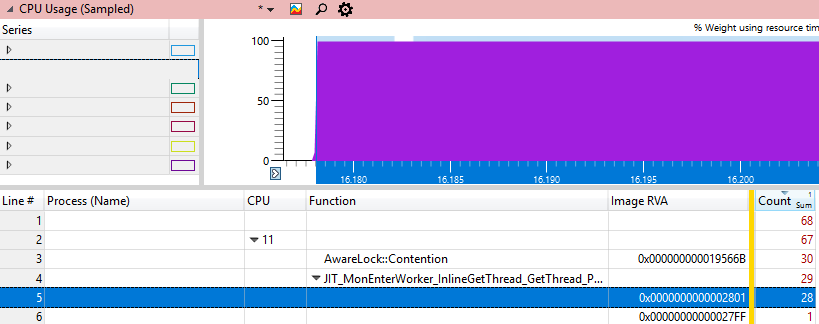
我们将使用多种Windbg方法检查该地址:
0:000> u clr.dll+0x19566B-10
clr!AwareLock::Contention+0x135:
00007ff8`0535565b f00f4cc6 lock cmovl eax,esi
00007ff8`0535565f 2bf0 sub esi,eax
00007ff8`05355661 eb01 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)
00007ff8`05355663 cc int 3
00007ff8`05355664 83e801 sub eax,1
00007ff8`05355667 7405 je clr!AwareLock::Contention+0x144 (00007ff8`0535566e)
00007ff8`05355669 f390 pause
00007ff8`0535566b ebf7 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)以及各种JIT方法:
0:000> u clr.dll+0x2801-10
clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x124:
00007ff8`051c27f1 5e pop rsi
00007ff8`051c27f2 c3 ret
00007ff8`051c27f3 833d0679930001 cmp dword ptr [clr!g_SystemInfo+0x20 (00007ff8`05afa100)],1
00007ff8`051c27fa 7e1b jle clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x14a (00007ff8`051c2817)
00007ff8`051c27fc 418bc2 mov eax,r10d
00007ff8`051c27ff f390 pause
00007ff8`051c2801 83e801 sub eax,1
00007ff8`051c2804 75f9 jne clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x132 (00007ff8`051c27ff)现在我们有了一个模板。 在一种情况下,热地址是一个跳转语句,在另一种情况下,它是一个减法。 但是,两个热门指令之前都带有相同的常规暂停语句。 不同的方法执行同一条处理器指令,由于某种原因,这会花费很长时间。 让我们测量一下pause语句的执行速度,看看我们是否正确推理。
如果记录了问题,则它将成为一个功能。
| 中央处理器 | 暂停在十亿分之一秒 |
| 至强E5 1620v3 3.5 GHz | 4 |
| Xeon®Gold 6126 @ 2.60 GHz | 43 |
新的Skylake处理器的暂停时间要长一个数量级。 当然,任何事物都会变得更快,有时会变得更慢。 但是慢
十倍 ? 它更像是一个错误。 在Internet上进行有关暂停指令的一小段搜索即可找到
Intel的手册 ,其中明确提到了Skylake微体系结构和暂停指令:

不,这不是一个错误,这是有文档记录的功能。 甚至还有一个
页面指示几乎所有处理器指令的执行时间。
- 桑迪桥11
- 常春藤新娘10
- 哈斯韦尔9
- 百老汇9
- SkylakeX 141
此处显示了处理器周期数。 要计算实际时间,您需要将周期数除以处理器频率(通常以GHz为单位),并获得以纳秒为单位的时间。
这意味着,如果您在最后一个硬件上的.NET上运行高度多线程的应用程序,则它们的运行速度会慢得多。 有人已经注意到这一点,并于2017年8月
注册了一个bug 。 该问题已在.NET Core 2.1和.NET Framework 4.8 Preview中
修复 。
改进了几个同步原语中的自旋等待,以在Intel Skylake和更高版本的微体系结构上获得更好的性能。 [495945,mscorlib.dll,错误]
但是,由于距.NET 4.8发行还有一年的时间,因此我要求向后移植这些修补程序,以使.NET 4.7.2在新处理器上恢复正常速度。 由于.NET的许多部分都有互斥锁(自旋锁),因此当Thread.SpinWait和其他旋转方法起作用时,您应该跟踪增加的CPU负载。

例如,Task.Result在内部使用自旋,因此我预计在其他测试中CPU负载会显着增加,而性能会降低。
有多糟
我查看了.NET Core代码,如果在调用WaitForSingleObject支付“昂贵”上下文切换之前未释放锁的情况下,处理器将继续旋转多长时间。 如果许多线程期望同一个内核对象,则上下文切换将花费一微秒甚至更长的时间。
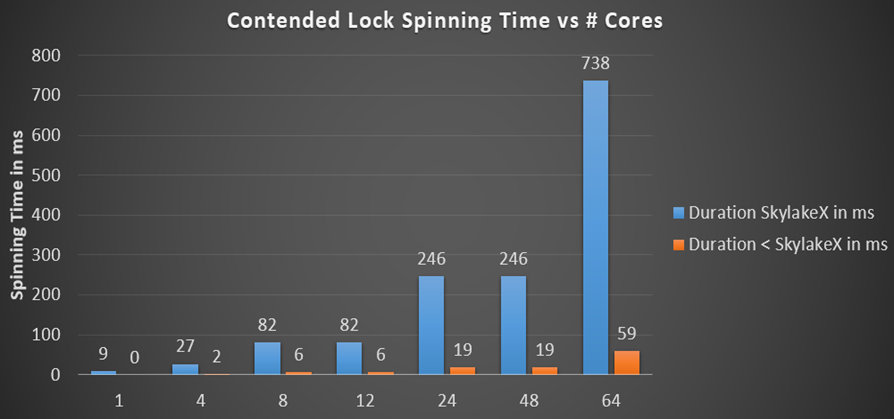
如果我们采取绝对的情况,即每个内核上的线程期望相同的锁定,并且旋转持续足够长的时间,以便每个人在支付内核调用费用之前都能工作一点点时间,.NET锁定会将最大旋转持续时间乘以内核数。 .NET中的旋转从50个暂停调用的周期开始时使用指数老化算法,其中对于每次迭代,旋转次数都会增加三倍,直到下一个旋转计数器超过其最大持续时间为止。 我计算了各种处理器和不同内核数量下每个处理器旋转的总持续时间:
下面是.NET Locks中的简化旋转代码:
/// <summary> /// This is how .NET is spinning during lock contention minus the Lock taking/SwitchToThread/Sleep calls /// </summary> /// <param name="nCores"></param> void Spin(int nCores) { const int dwRepetitions = 10; const int dwInitialDuration = 0x32; const int dwBackOffFactor = 3; int dwMaximumDuration = 20 * 1000 * nCores; for (int i = 0; i < dwRepetitions; i++) { int duration = dwInitialDuration; do { for (int k = 0; k < duration; k++) { Call_PAUSE(); } duration *= dwBackOffFactor; } while (duration < dwMaximumDuration); } }
以前,旋转时间以毫秒为单位(24个内核为19 ms),与前述的上下文切换时间相比已经很大,后者快了一个数量级。 但是在Skylake处理器中,处理器的总旋转时间在24位或48核计算机上仅爆炸246毫秒,这仅仅是因为暂停指令的速度降低了14倍。 真的是这样吗 我写了一个小型测试器来检查CPU的整体旋转情况-计算得出的数字与预期非常吻合。 这是一个等待锁定的24核CPU上的48个线程,我将其称为Monitor.PulseAll:
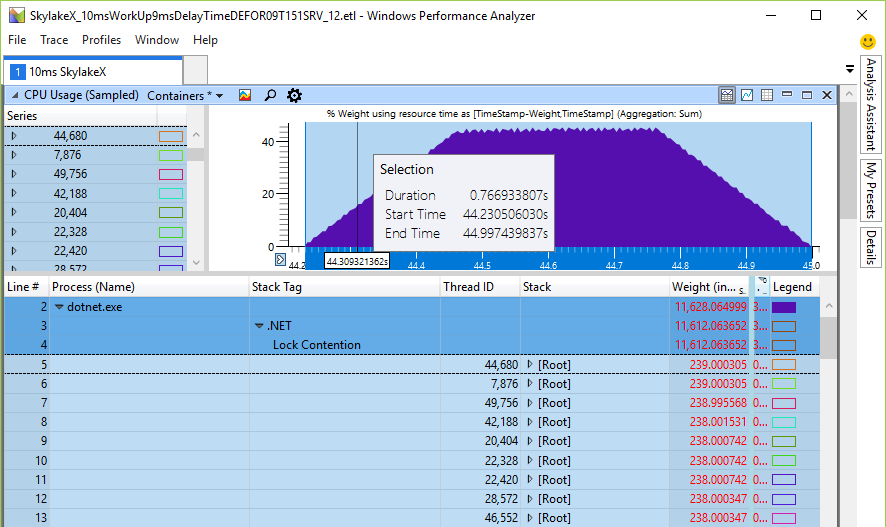
只有一条线会赢得比赛,但是47条线会继续旋转直到失去心率。 这是实验证据,证明我们确实有CPU负载问题,并且长时间旋转是真实的。 它会破坏可伸缩性,因为这些周期会代替其他线程的有用工作,尽管暂停指令会释放CPU的某些共享资源,从而使睡眠时间更长。 旋转的原因是试图在不访问内核的情况下更快地获得锁。 如果是这样,那么增加CPU的负载只是名义上的,而根本不会影响性能,因为内核要执行其他任务。 但是测试表明,几乎单线程操作的性能都会下降,其中一个线程向工作队列中添加了一些内容,而工作线程则需要一个结果,然后对工作项执行特定任务。
原因最容易在图中显示。 对抗性旋转在每个步骤中都会发生三重旋转。 每一轮之后,将再次检查该锁,以查看当前线程是否可以接收该锁。 尽管spin试图做到诚实,并不时切换到其他线程来帮助他们完成工作。 这增加了释放下一张支票上的锁的机会。 问题在于,只有在完整回合结束时才可以进行抽签检查:

例如,如果在第五次旋转回合开始时有锁发出可用性信号,则您只能在回合结束时进行操作。 计算完最后一轮的旋转持续时间后,我们可以估算出流程延迟的最坏情况:

等待直到旋转结束的毫秒数。 这是一个真正的问题吗?
我创建了一个简单的测试应用程序,该应用程序实现了消费者制造商的队列,其中工作流将每个工作项执行10毫秒,并且消费者在下一个工作项之前有1-9毫秒的延迟。 这足以看到效果:
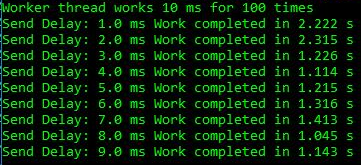
我们看到延迟为1-2 ms,总持续时间为2.2-2.3 s,而在其他情况下,工作速度则加快到1.2 s。 这表明在超线程应用程序中,CPU过度旋转不仅是表面上的问题。 这实际上损害了仅包含两个线程的生产者-消费者的简单线程。 对于上面的运行,ETW数据不言而喻:旋转的增加导致观察到的延迟:
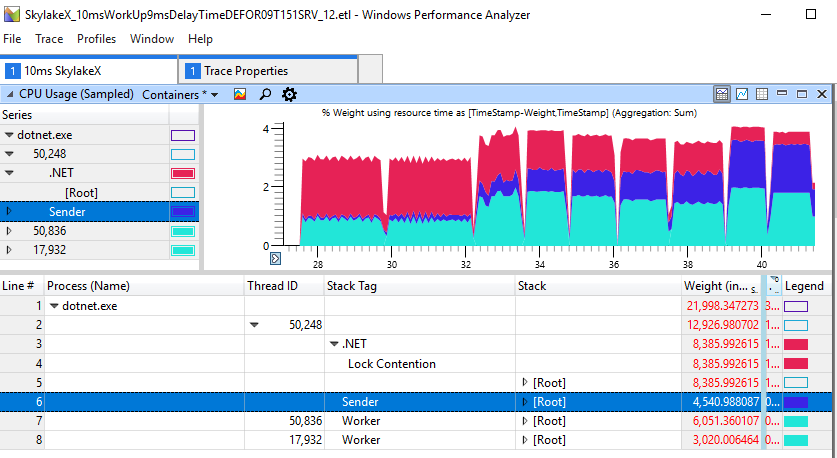
如果您仔细查看带有“刹车”的部分,尽管工人(浅蓝色)已经完成工作并很久以前就锁定了,但我们会在红色区域看到11毫秒的旋转。
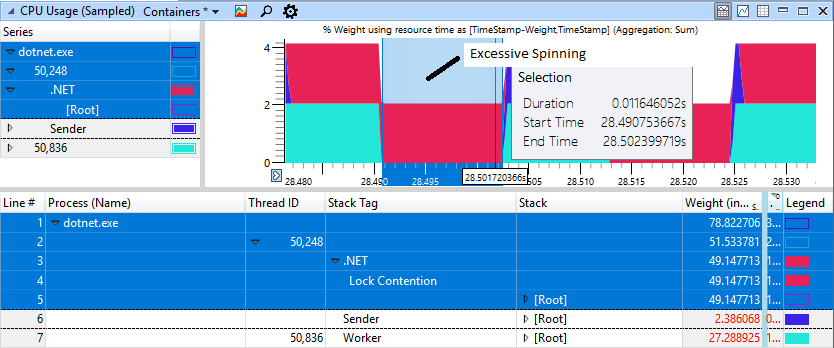
快速的非变性情况看起来要好得多,这里仅花费1毫秒进行旋转来阻止。
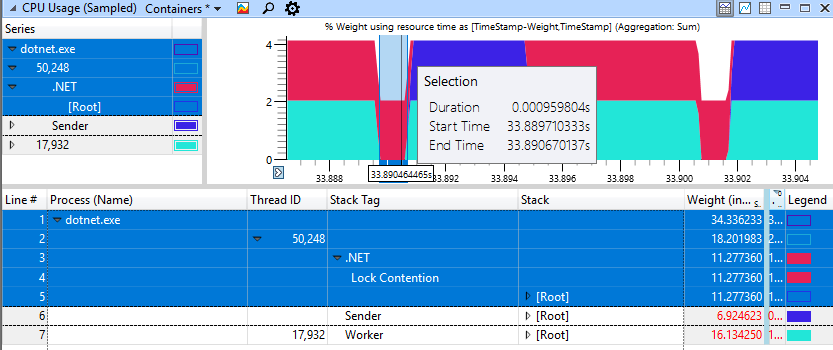
我使用了测试应用程序
SkylakeXPause 。
zip存档包含.NET Core和.NET 4.5的源代码和二进制文件。 为了进行比较,我安装了带有修复程序的.NET 4.8 Preview和.NET Core 2.0,后者仍然实现了旧的行为。 该应用程序是为.NET Standard 2.0和.NET 4.5设计的,同时生成exe和dll。 现在,您可以并排检查新旧纺纱行为,而无需进行任何修复,这非常方便。
readonly object _LockObject = new object(); int WorkItems; int CompletedWorkItems; Barrier SyncPoint; void RunSlowTest() { const int processingTimeinMs = 10; const int WorkItemsToSend = 100; Console.WriteLine($"Worker thread works {processingTimeinMs} ms for {WorkItemsToSend} times"); // Test one sender one receiver thread with different timings when the sender wakes up again // to send the next work item // synchronize worker and sender. Ensure that worker starts first double[] sendDelayTimes = { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; foreach (var sendDelay in sendDelayTimes) { SyncPoint = new Barrier(2); // one sender one receiver var sw = Stopwatch.StartNew(); Parallel.Invoke(() => Sender(workItems: WorkItemsToSend, delayInMs: sendDelay), () => Worker(maxWorkItemsToWork: WorkItemsToSend, workItemProcessTimeInMs: processingTimeinMs)); sw.Stop(); Console.WriteLine($"Send Delay: {sendDelay:F1} ms Work completed in {sw.Elapsed.TotalSeconds:F3} s"); Thread.Sleep(100); // show some gap in ETW data so we can differentiate the test runs } } /// <summary> /// Simulate a worker thread which consumes CPU which is triggered by the Sender thread /// </summary> void Worker(int maxWorkItemsToWork, double workItemProcessTimeInMs) { SyncPoint.SignalAndWait(); while (CompletedWorkItems != maxWorkItemsToWork) { lock (_LockObject) { if (WorkItems == 0) { Monitor.Wait(_LockObject); // wait for work } for (int i = 0; i < WorkItems; i++) { CompletedWorkItems++; SimulateWork(workItemProcessTimeInMs); // consume CPU under this lock } WorkItems = 0; } } } /// <summary> /// Insert work for the Worker thread under a lock and wake up the worker thread n times /// </summary> void Sender(int workItems, double delayInMs) { CompletedWorkItems = 0; // delete previous work SyncPoint.SignalAndWait(); for (int i = 0; i < workItems; i++) { lock (_LockObject) { WorkItems++; Monitor.PulseAll(_LockObject); } SimulateWork(delayInMs); } }
结论
这不是.NET问题。 使用pause语句的所有自旋锁实现都会受到影响。 我迅速检查了Windows Server 2016的核心,但表面上没有此类问题。 英特尔似乎很友善-暗示需要对旋转方法进行一些更改。
2017年8月报告了.NET Core的错误,2017年9月发布了.NET Core 2.0.3
的补丁程序和版本。 该链接不仅显示了.NET Core组的出色反应,还显示了几天前该问题已在主分支中修复的事实,以及有关其他旋转优化的讨论。 不幸的是,Desktop .NET Framework的发展不是那么快,但是面对.NET Framework 4.8 Preview,我们至少在概念上证明那里的修复程序也是可以实现的。 现在,我正在等待.NET 4.7.2的反向移植,以在最后一个硬件上全速使用.NET。 这是我发现的第一个与一条CPU指令导致的性能变化直接相关的错误。 ETW仍然是Windows中的主要探查器。 如果可以的话,我会要求微软将ETW基础结构移植到Linux,因为当前的Linux分析器仍然很糟糕。 他们最近添加了有趣的内核功能,但是仍然没有像WPA这样的分析工具。
如果您使用的是自2017年中以来发布的最新处理器上的.NET Core 2.0或桌面.NET Framework,那么万一性能下降问题,您绝对应该使用探查器检查您的应用程序-并升级到.NET Core,并希望不久后能够.NET桌面 我的测试应用程序将告诉您是否存在问题。
D:\SkylakeXPause\bin\Release\netcoreapp2.0>dotnet SkylakeXPause.dll -check
Did call pause 1,000,000 in 3.5990 ms, Processors: 8
No SkylakeX problem detected或
D:\SkylakeXPause\SkylakeXPause\bin\Release\net45>SkylakeXPause.exe -check
Did call pause 1,000,000 in 3.6195 ms, Processors: 8
No SkylakeX problem detected如果您使用的是.NET Framework而没有适当的更新,并且使用的是Skylake处理器,则该工具将报告问题。
希望您能像我一样对这个问题进行调查。 为了真正理解问题,您需要创建一种重现该问题的方法,使您可以进行实验并寻找影响因素。 其余的工作很无聊,但是现在我更好地了解了周期性尝试获取CPU锁定的原因和后果。