
3月,我们的开发团队以“ Hands-Auki”为傲,在黑客马拉松AI.HACK的数字领域进行了为期两天的战斗。 总共提出了来自不同公司的五项任务。 我们专注于Gazpromneft的任务:预测B2B客户对燃料的需求。 根据匿名数据,有必要学习如何根据燃料购买地区,燃料编号,燃料类型,价格,日期和客户ID来预测特定客户将来会购买多少。 展望未来-我们的团队以最高的精度解决了这个问题。 客户分为三个部分:大,中和小。 除了主要任务,我们还建立了每个细分市场的总消费量预测。
卸载包含2016年11月至2018年3月15日期间的客户购买数据(2018年1月1日至2018年3月15日期间的数据不包括数量)。
样本数据:
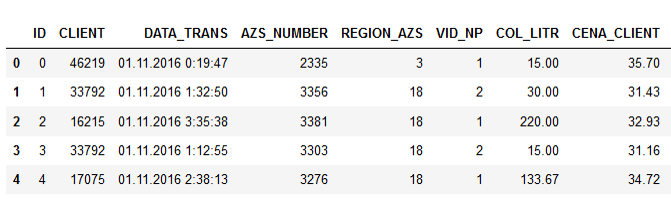
列的名称说明一切,我认为没有任何解释的意义。
除了培训样本,组织者还提供了今年三个月的测试样本。 价格是针对公司客户的,并考虑到特定的折扣,折扣取决于特定客户的消费,特殊优惠和其他要点。
接收到初始数据后,我们像其他所有人一样,开始尝试经典的机器学习方法,尝试建立合适的模型,以感觉到某些信号的相关性。 我们尝试提取其他功能,构建回归模型(XGBoost,CatBoost等)。
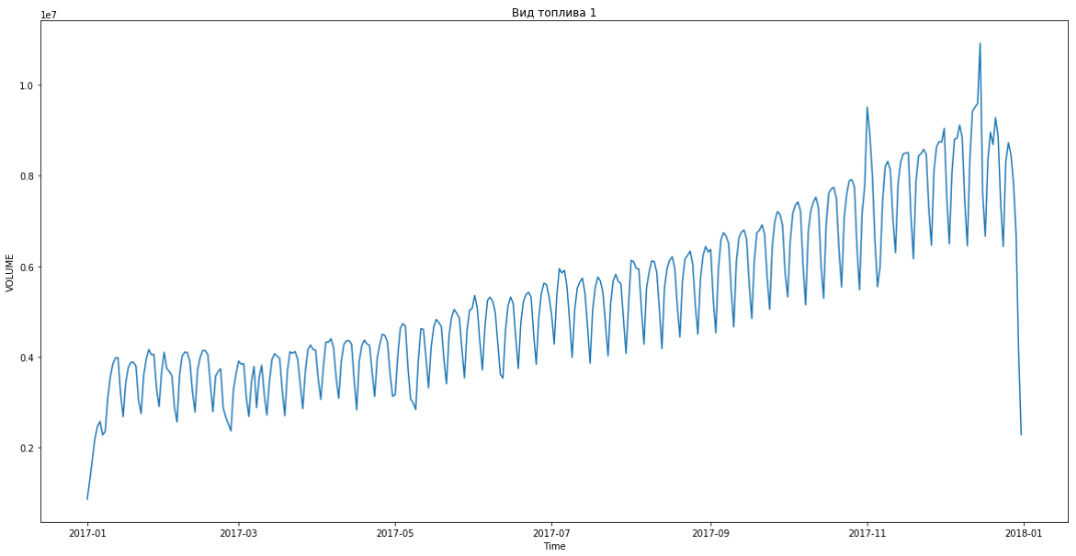
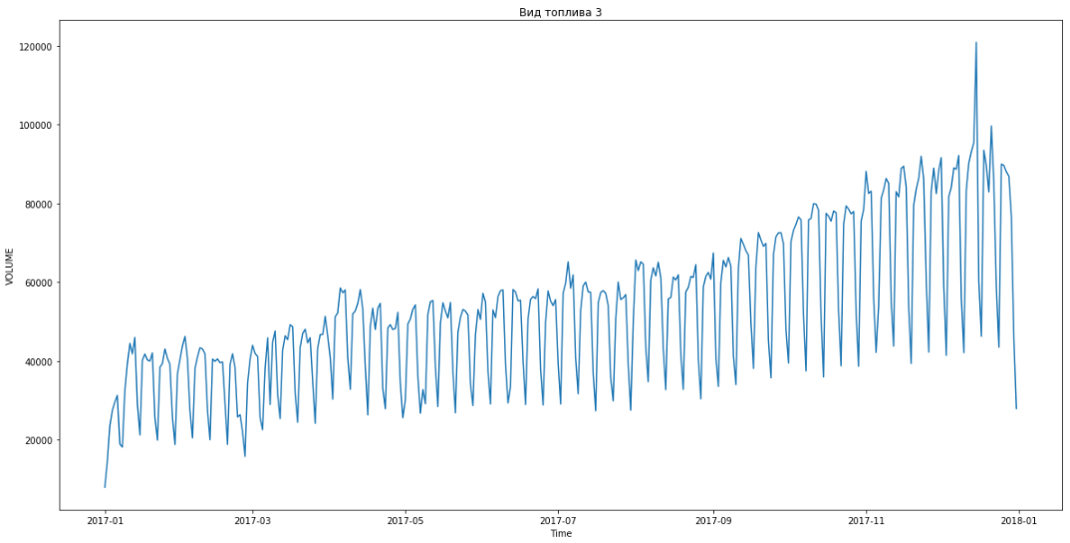
问题本身的陈述最初暗示燃料价格以某种方式影响需求,因此有必要更准确地理解这种依赖性。 但是,当我们开始分析提供的数据时,我们发现需求与价格不相关。

符号相关:
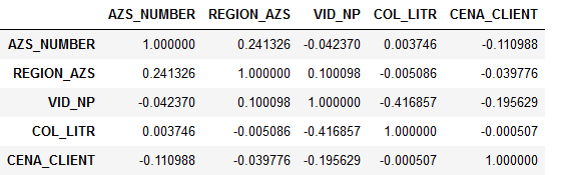
事实证明,升数实际上不取决于价格。 逻辑上对此进行了解释。 驾驶员在高速公路上行驶,他需要加油。 他可以选择:要么在公司合作的加油站加油,要么在其他地方加油。 但是驾驶员并不在乎燃油成本,而是由组织支付。 因此,他只是关闭了最近的加油站并给油箱加油。
但是,尽管付出了所有努力并进行了反复试验的模型,仍无法达到使用以下公式(对称平均绝对百分比误差)计算得出的最低可接受的预测精度(基线):
我们尝试了所有选项,但没有任何效果。 然后我们中间的一个人开始使用机器学习,并转向良好的旧统计数据:只取燃油类型的平均值,进行验证并查看您获得的准确度。
所以我们首先超过了阈值。
我们开始考虑如何改善结果。 我们尝试按客户群,燃料类型,地区和加油站数量获取中间值。 问题在于,在测试数据中,培训样本中大约30%的客户ID丢失了。 也就是说,新客户出现在测试中。 这是组织者未检查的错误。 但是我们必须自己解决问题。 我们不知道新客户的消费量,因此无法为他们建立预测。 机器学习在这里起到了作用。
在第一阶段,缺失的数据用整个样本的平均值或中值填充。 然后这个想法浮出水面:为什么不根据现有数据创建新的客户资料? 我们按地区,有多少客户在那购买燃料,以什么频率,什么类型来削减。 我们将现有客户聚集在一起,为不同地区编译特定的配置文件,并对他们进行培训,然后“完成”新客户的配置文件。
这使我们跃居第一。 总结结果还剩下三个小时。 我们很高兴并开始解决奖金问题-提前三个月按细分进行预测。
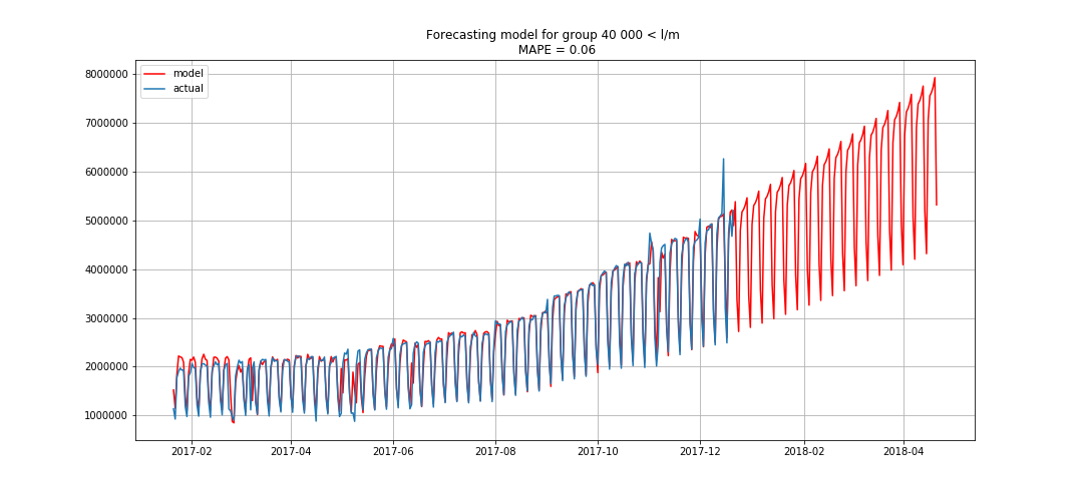
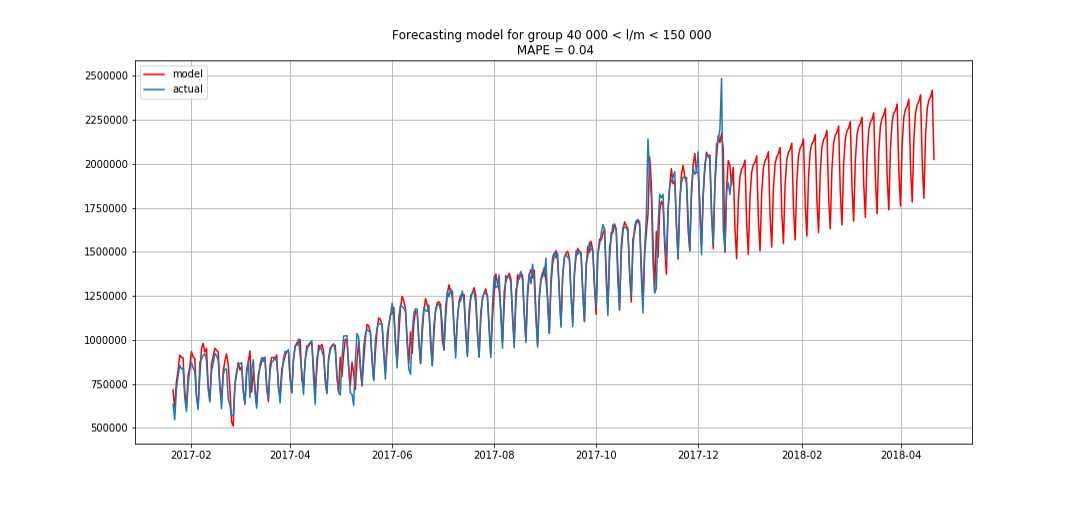
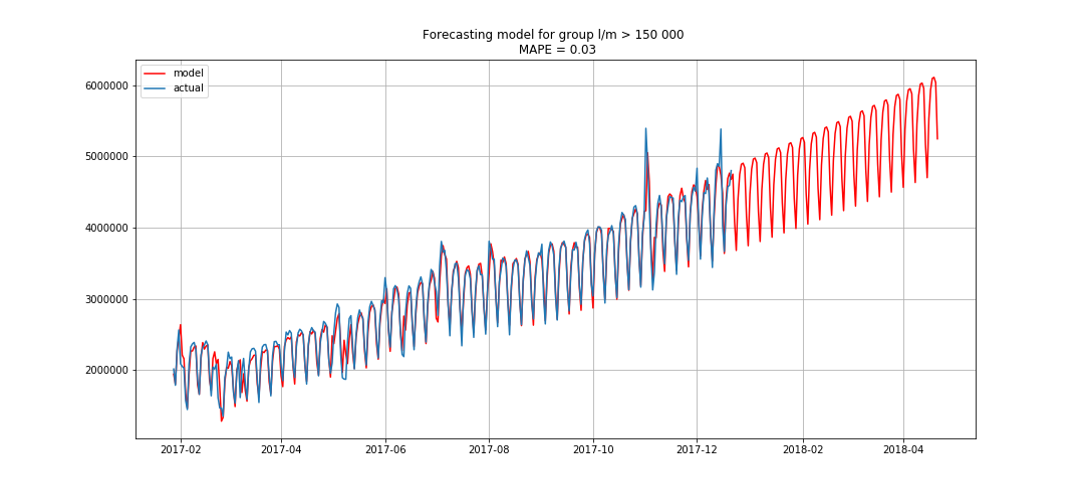
蓝色显示实际数据,红色显示预测。 误差范围为3%至6%。 例如,考虑到季节性高峰和假期,甚至可以更准确地进行计算。
在我们这样做的同时,一支团队开始追赶我们,每15至20分钟改善一次我们的成绩。 我们也开始大惊小怪,并决定采取行动,以防他们追上我们。
他们开始并行制作另一个模型,该模型按显着性对统计数据进行排名,其准确性略低于第一个模型。 当竞争对手击败我们时,我们尝试将两种模型结合起来。 这使我们略微提高了指标-达到了37.24671%,因此,我们重新获得了第一名并将其保持到最后。
为了取得胜利,我们的Ruki-Auki团队获得了10万卢布,荣誉,尊敬和……充满自尊的证书,我去了温泉浴场! ;)
Jet信息系统开发团队