最近,我们在团队中寻找一名数据科学家(并发现-您好,
nik_son和Arseny!)。 在与候选人交谈时,我们意识到许多人想换工作,因为他们在做“餐桌上的事情”。
例如,他们接受了主管提议的复杂预测,但是该项目停止了,因为该公司不了解在生产中包括什么以及如何将其包括在内,如何获利,如何“收回”在新模型上花费的资源。

HeadHunter没有像Yandex或Google这样的强大计算能力。 我们知道将复杂的ML投入生产有多么困难。 因此,许多公司都将最简单的线性模型投入生产这一事实。
在推荐系统中下一次实施ML的过程以及寻找空缺的过程中,我们遇到了许多经典的“ rakes”。 如果您打算在家中实施ML,请注意它们:也许此列表将帮助您不要继续学习它们,
而不会
找到自己的个人耙子 。
Rake No. 1:数据科学家-自由艺术家
在每家开始将机器学习(包括神经网络)引入其工作的公司中,数据科学家想要做什么与对生产有益的差距都很大。 包括因为企业不能总是解释什么是收益以及如何提供帮助。
我们通过以下方式处理此问题:我们讨论所有新出现的想法,但仅实施将对公司有利的现在或将来。 我们不会在真空中进行研究。
在每次实施或试验后,我们都会考虑质量,资源和经济影响并更新我们的计划。
耙数2:更新库
在许多情况下会发生此问题。 出现了许多新的方便的库,几年前没人听说过,或者根本没有听说过。 我想使用最新的库,因为它们更方便。
但是有几个障碍:
1.如果产品使用的是第14个Ubuntu,则很可能其中根本没有新库。 解决方案是将服务转移到docker并使用pip(而不是deb软件包)安装Python库。
2.如果将代码相关的格式用于数据存储(例如pickle),则会冻结使用的库。 也就是说,当使用scikit-learn版本15库获取机器学习模型并以pickle格式保存时,为了正确恢复模型,将需要15个版本的scikit-learn库。 您不能升级到最新版本,这是比第1段中描述的更加隐蔽的陷阱。
有两种解决方法:
- 使用与代码无关的格式存储模型
- 始终能够重新训练任何模型。 然后,在更新库时,有必要训练所有模型并将其保存在新版本的库中。
我们选择了第二条路径。
耙数3:使用旧型号
在旧的,学到的模型中执行新操作要比在新的模型中执行简单操作有用。 最终,通常会发现,引入更简单但更新鲜的模型会更有用,而且工作量也会更少。 重要的是要记住这一点,并始终在搜索模式时考虑到共同的努力。
耙数4:仅本地实验
许多数据科学专家喜欢在其机器学习服务器上进行本地实验。 只有产品没有这种灵活性:因此,揭示了很多原因,因此无法将这些实验投入生产。
配置DS专家和销售工程师之间的通信以达成共识是很重要的-该模型或该模型在生产中将如何工作,是否具有推广该模型的必要能力和物理能力。 此外,模型和因素越复杂,使它们变得可靠并能够随时对其进行重新训练就越困难。 与Kaggle竞赛不同,在生产中通常最好牺牲千分之一的本地度量标准,甚至牺牲一点在线KPI,但是实现模型版本要简单得多,结果稳定且易于计算资源。
代码的共同所有权(开发人员和数据科学家知道其他开发人员编写的代码是如何工作的),在学习过程中和在生产过程中在各种模型中重用符号和元属性(我们得到了我们的框架),我们经常进行的单元测试和自动测试,代码集成和重新测试。 我们将最终模型放入git存储库中,并在生产中也使用它们。
耙数5:仅测试产品
我们每个开发人员和数据科学家都有自己的测试平台,有时甚至没有。 生产HH的主要组件已部署在其上。 它很昂贵,但是却为质量和开发速度付出了代价。 这是必要的,但还不够。 我们不仅加载已经投入生产的模型,还加载即将推出的模型。 这有助于及时了解对于5%的用户而言,在本地计算机,测试台或生产环境中运行良好的模型是否太重,而在100%打开时,它们太重了。
我们使用了多个测试阶段。 我们非常快速地检查代码(这是关键点)-在存储库中添加或更改组件时,将收集代码,并在相应的组件上进行单元测试和自动测试,如有必要,我们还手动对其进行重新测试-如果出现问题,请给出答案“你很沮丧,决定。”
瑞克数字6:长时间的计算和失去焦点
如果某个模型需要一周的训练,那么由于切换到另一个项目,很容易失去对任务的专注。 我们试图一方面不给开发人员和数据科学家两个以上的任务。 而且不超过一个紧急状态,因此您可以在计算或A / B实验完成后立即切换到该状态。 为了避免失去注意力,此规则是必要的,并且出于担心其中某些任务通常会丢失的风险,而另一部分的推出则比必要的时间晚得多。
我们踩了耙,但没有放弃
我们最近完成了将神经网络引入推荐系统的实验。 首先,内部黑客马拉松在两天内编写了一个预测履历表响应的模型,这极大地促进了寻找合适空缺的机会。
但是后来我们了解到:要将其投入生产,您需要进行几乎所有的更新-例如,将考虑标志和教学模型的双重用途系统转移到docker,以及更新机器学习库。
怎么样了
我们将DSSM模型与单层神经网络一起使用。 在最初的Microsoft文章中,使用了三层神经网络,但是随着层数的增加,我们没有观察到质量的提高,因此我们选择了一层。

简而言之:
- 查询文本和空缺标题被转换为两个符号三元组向量。 我们使用20,000个字符的字母组合。
- Trigram向量被馈送到单层神经网络的输入。 在神经网络层的输入处,有64个数字,输出为20,000。本质上,神经网络是一个20,000 x 64矩阵,乘以尺寸为1 x 20 000的输入三元组矢量,然后将一个尺寸为1 x 64的常数矢量添加到乘法结果中。这样的神经网络的输出对应于请求(或对应于空缺头)。
- 计算查询dssm向量和空位标头dssm向量的标量积。 乙状结肠功能适用于作品。 最终结果是dssm元符号。
当我们首次尝试包含此模型时,本地指标变得更好,但是当我们尝试将其纳入A / B测试时,我们发现并没有任何改进。
之后,我们尝试将第二层神经元增加到256个-由5%的用户推出:事实证明推荐系统和搜索变得更好,但是当您打开100%模型时,突然发现它太重了。
我们分析了模型为何如此沉重,移除了词干,然后再次对该神经网络进行了实验。 直到那之后,他们才重新摸索,发现该模型是有用的:推荐系统中的响应每天增加700次,而搜索后的重新计数最终增加了4200次。
这种不太复杂的神经网络的引入使我们的客户每天可以通过hh.ru雇用数十名额外的员工,在实施过程中,我们解决了很大的难题。 因此,我们计划进一步开发神经网络。 计划是尝试进行一般的词干处理,附加的词形化处理,处理空缺的全文并恢复,对拓扑进行实验(隐藏层以及可能的RNN / LSTM)。
我们使用此模型所做的最重要的事情是:
- 不要将实验放在中间。
- 我们计算了响应增加指标,发现在此模型上进行的工作值得。 了解每个此类实现带来的收益非常重要。
有趣的是,我们创建并最终添加到产品中的模型与应用于矩阵的主成分方法(PCA)非常相似[查询文本,文档标题,是否单击]。 也就是说,对于行对应于唯一查询的矩阵,列对应于唯一的空缺标题; 如果在此请求之后用户单击具有此标题的空缺,则单元格中的值为1;如果没有单击,则为0。
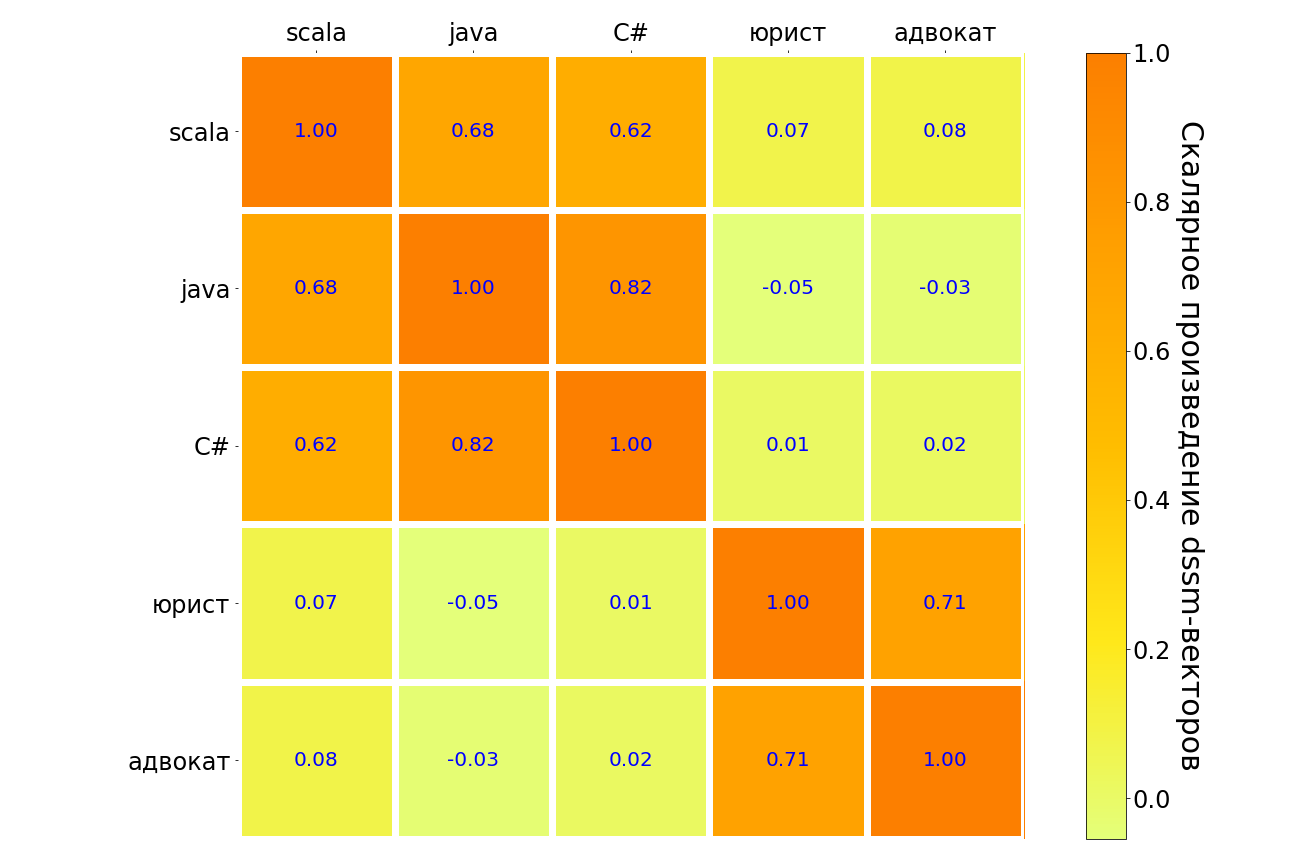
下表将这个模型应用于scala,java,C#,“ lawyer”,“ lawyer”请求的结果。 意思相似的查询对以深色(而不是浅色)突出显示。 可以看出,该模型理解了不同编程语言之间的联系,在请求“律师”与“律师”之间有很强的联系。 但是在“律师”和任何编程语言之间,这种联系非常薄弱。
在某个时候,我真的很想放弃-实验正在进行中,但并未“点燃”。 在这一点上,数据科学家可能会发现支持团队并再次计算收益很有用:“埋葬空姐”而不是尝试“骑死马”是值得的,这不是失败,而是成功的实验,结果是负面的。 或者,在权衡利弊之后,您将进行另一个可以“拍摄”的实验。 事情就这样发生在我们身上。