在今年冬季结束时,举行了IEEE信号处理协会-相机模型识别竞赛。 我以导师的身份参加了这项团队比赛。 关于团队建设的另一种方法,决定和削减第二阶段。
 tldr.py
tldr.pyfrom internet import yandex_fotki, flickr, wiki commons from Andres_Torrubia import Ivan_Romanov as pytorch_baseline import kaggle dataset = kaggle.data() for source in [yandex_fotki, flickr, wiki_commons]: dataset[train].append(source.download()) predicts = [] for model in [densenet201, resnext101, se_resnext50, dpn98, densenet161, resnext101 d4, se resnet50, dpn92]: with pytorch_baseline(): model.fit(dataset[train]) predicts.append(model.predict_tta(dataset[test])) kaggle.submit(gmean(predicts))
问题陈述根据照片,有必要确定在其上获得该照片的设备。 数据集由十个类别的图片组成:两部iPhone,七部Android智能手机和一部相机。 训练样本包括每个班级的275张全尺寸图像。 在测试样本中,仅显示了512x512中心作物。 此外,将三种扩充中的一种应用于其中的50%:jpg压缩,使用三次插值调整大小或进行gamma校正。 可以使用外部数据。
 精华素(tm)
精华素(tm)如果您尝试用简单的语言来解释任务,则该想法将在下图中呈现。 通常,现代神经网络被教导区分照片中的物体。 即 您需要学会区分猫与狗,色情与泳衣或坦克与道路。 同时,对于如何以及在哪种设备上拍摄猫和坦克的图片,应该总是毫不关心。

在同一比赛中,一切都相反。 无论照片中显示了什么,都需要确定设备的类型。 也就是说,使用诸如矩阵噪声,图像处理伪像,光学缺陷等之类的东西。 这是关键的挑战-开发一种可捕获图像低级特征的算法。
团队合作特色绝大多数kaggle团队的组成如下:在排行榜上处于领先地位的参与者被团结成一个团队,而每个人都从头到尾地看到自己的解决方案版本。 我写了一篇有关这种演讲的典型例子的文章。 但是,这次我们走了另一条路,那就是:将决策的各个部分划分为人。 此外,根据比赛规则,排名前三的学生团队还将获得第二阶段加拿大的入场券。 因此,当骨干聚集时,我们的团队人员不足以遵守规则。
解决方案为了在此任务上显示良好的结果,有必要根据优先级组装以下难题:
- 查找并下载外部数据。 这项比赛被允许使用无限数量的外部数据。 很快,很明显,一个大型外部数据集正在拖延。
- 过滤外部数据。 人们有时会发布经过处理的图像,这会破坏设备的所有功能。
- 使用可靠的本地验证方案。 由于甚至一个模型都显示出0.98+左右的精度,并且在测试中只有2000张照片,因此选择模型的检查点是一项单独的任务
- 训练模型。 论坛上发布了非常强大的基准。 然而,由于没有魔法,他只允许银牌。
资料收集这部分由
亚瑟·法塔霍夫 (
Arthur Fattakhov )占据。 对于此任务,获取外部数据非常容易,这些只是某些手机型号的图片。 Arthur编写了一个Python脚本,该脚本使用该库来方便地解析名为
BeautifulSoup的 html页面。 但是,例如,在flickr相册页面上,动态加载了照片块,为了解决这个问题,我不得不使用
selenium ,它模拟了浏览器的操作。 从yandex.fotki,flickr和Wiki Commons总共下载了500+ GB的照片。
资料筛选这是我对代码形式的解决方案的唯一贡献。 我只是看了看原始照片的样子并制定了一系列规则:1)特定模型的典型尺寸2)jpg质量超过阈值3)模型必需的元标记的存在4)处理的正确软件。
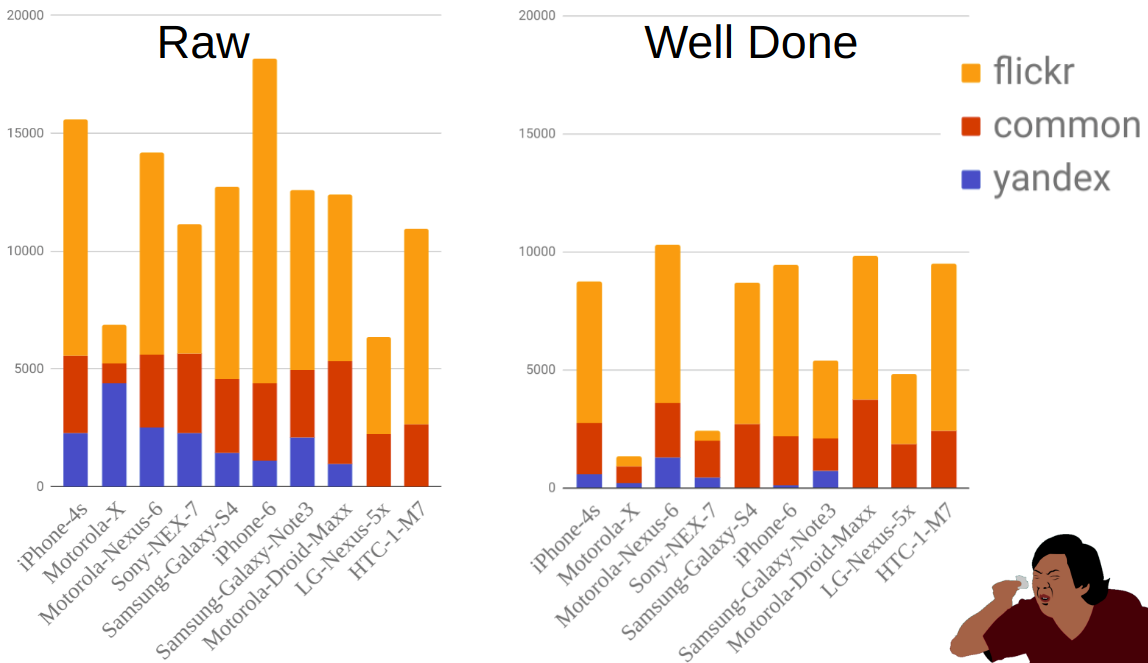
该图显示了过滤之前和之后按来源和移动设备显示的照片分布。 如您所见,例如Moto-X比其他手机小得多。 同时,在过滤之前有很多过滤器,但是由于此手机有很多选择,而且所有者并不总是正确地指出型号,因此大部分过滤器被淘汰了。
验证方式Ilya Kibardin完成了带有培训和验证的部分的实施。 在一块kaggle火车上进行的验证根本不起作用-网格淘汰了几乎1.0的准确性,而在排行榜上的准确性约为0.96。
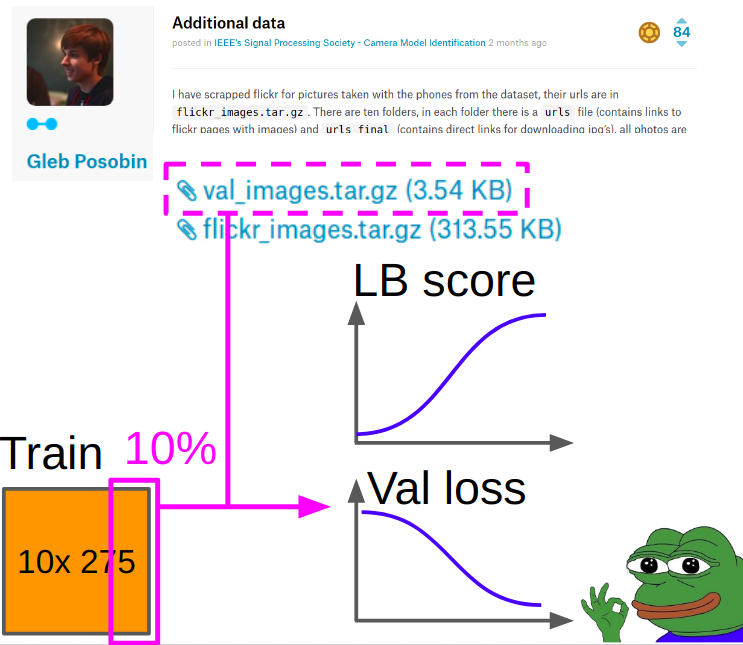
因此,验证是为
Gleb Posobin拍摄的照片,他从所有站点拍摄了带有电话评论的照片。 里面有一个错误:不是iPhone 6,而是iPhone 6+。 我们用一台真正的iPhone 6代替了它,并从kagla火车上删除了10%的图像,以平衡各个班级。
在学习指标时,考虑如下:
- 我们从验证中考虑了作物中心的交叉熵和akurasi。
- 我们考虑8种操作中的每一种的交叉熵和akurasi(操作+作物中心),将8种操作的平均值和算术平均值进行平均。
- 我们将权重为0.7和0.3的项目1和项目2的速度相加。
根据第3节中获得的加权交叉熵选择最佳检查点。
模型训练在比赛中的某个地方,
安德烈斯·托鲁比亚 (
Andres Torrubia)发布了完整的
代码以做出决定 。 就最终模型的准确性而言,他是如此出色,以至于一群团队随他一起飞上了排行榜。 但是,他是用keras编写的,并且所需的代码级别。
当
伊万·罗曼诺夫(Ivan Romanov)发布了该代码的
pytorch版本时,情况再次发生了变化。 它速度更快,此外,它还可以轻松并行到多个视频卡。 但是,代码级别仍然不是很好,但这并不是那么重要。
可悲的是,这些家伙分别排在第30位和第45位,但在我们心中,他们始终排在前列。
我们团队中的Ilya接受了Misha的代码,并进行了以下更改。
预处理:- 从原始图片中随机裁剪960x960。
- 概率为0.5,将应用一种随机操作。 (取决于是否使用了is_manip = 1或0)
- 随机裁剪480x480
- 共有两个训练选项:在特定方向上随机旋转90度(模拟手机的水平/垂直拍摄),或D4组的随机转换。
 培训课程
培训课程训练是在整个网络范围内进行的,没有冻结分类器的卷积层(我们拥有大量数据+直观地讲,由于我们需要低级功能,因此可以将猫/狗形式的高级对象提取的权重相加)。
 Sheduling:
Sheduling:亚当的lr = 1e-4。 当验证损失在2-3个时期内不再改善时,我们将lr减少一半。 所以要收敛。 用SGD代替Adam并用从1e-3到1e-6的循环lr学习三个周期。
最终合奏:我要求伊利亚(Ilya)实施上一次比赛中的方法。 对于孝子合奏,我们训练了9个模型,从每个模型中我们选择了3个最佳检查点,每个检查点都使用TTA进行了预测,最后所有预测均通过几何平均值进行平均。
 第一阶段的后记
第一阶段的后记结果,我们在排行榜上排名第二,在学生团队中排名第一。 这意味着我们已经进入了比赛的第二阶段,成为
2018年加拿大
IEEE声学,语音和信号处理国际会议的一部分。 值得注意的是,获得第三名的团队也是正式学生。 如果我们计算速度,事实证明我们绕过了一张正确预测的图片。
2018年最终IEEE信号处理杯在收到所有确认之后,我,瓦莱里和安德烈决定不去加拿大进行第二阶段的活动。 伊利亚(Ilya)和亚瑟·F(Arthur F.)决定离开,他们开始安排一切事情,他们没有得到签证。 为了避免国际社会对来自俄罗斯最强大的科学家的压迫的丑闻,这些狂欢节被允许远程参加。
时间轴是这样的:
03.03-根据火车数据
04.09-发布测试数据
12.04-我们被允许远程参加
13.04-我们开始查看数据中包含的内容
04/16-决赛
第二阶段的特点在第二阶段,没有排行榜:最后只需要发送一个提交即可。 也就是说,甚至预测的格式也无法得到验证。 另外,相机型号也不为人所知。 这意味着一次有两个文件:使用外部数据将无法正常工作,并且本地验证可能非常具有代表性。
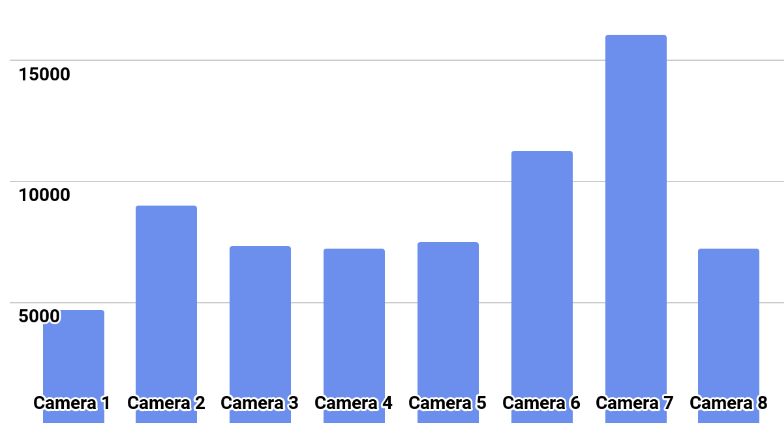
图片中显示了班级分布。
解决方案我们尝试从最佳模型的第一阶段开始就按照计划训练模型。 所有模型的褶皱都令人愉快地训练到0.97+的精度,但是在测试中,他们给出了0.87范围内的预测交集。
我认为这是过硬的。 因此,他提出了一个新计划:
- 我们将第一阶段的最佳模型用作特征提取器。
- 我们从提取的功能中提取PCA,以便所有内容都能在一夜之间学习。
- 学习LightGBM。

这里的逻辑如下。 已经对神经网络进行了训练,以提取传感器,光学器件,演示算法的低级特征,同时又不依赖于上下文。 另外,在最终分类器之前提取的特征(实际上是逻辑回归)是强烈非线性变换的结果。 因此,人们可以简单地教一些简单的,不易再训练的东西,例如逻辑回归。 但是,由于新数据可能与第一阶段的数据有很大不同,因此最好训练一些非线性的东西,例如在决策树上进行梯度提升。 我在多次比赛中使用了这种方法,并在其中发布了代码。
由于只有一个提交者,所以我没有可靠的方法来测试我的方法。 但是,事实证明DenseNet是最好的特征提取器。 Resnext和SE-Resnext网络在本地验证中显示出较低的性能。 因此,最终决定看起来像这样。
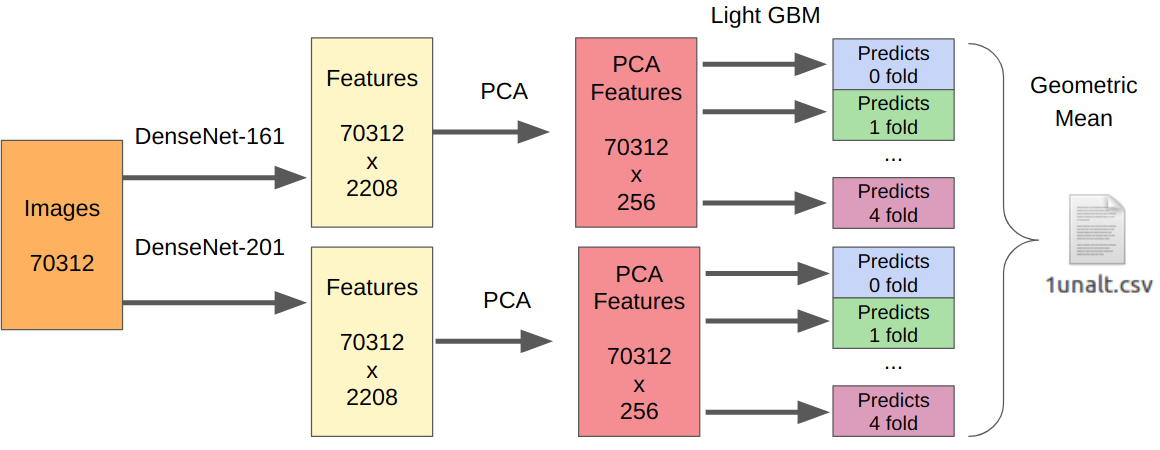
对于带有操作的部分,所有训练样本的数量都需要乘以7,因为我分别从每个操作中提取了特征。
后记结果,在最后阶段我们获得了第二名,但仍有很多保留意见。 首先,不是根据算法的准确性而是根据陪审团的表现估计来授予该地点。 获得第一名的团队不仅制作了Preza,还通过他们的算法进行了现场演示。 好吧,我们仍然不知道每个团队的最终速度,即使在直接提出问题后,组织也不会以通信的方式披露它们。
有趣的事情是:在第一阶段,我们社区的所有团队都以团队名称[ods.ai]表示,并且非常有力地占据了排行榜的位置。 在那之后,诸如Inversion和
Giba之类的怪诞传说决定加入我们,看看我们在这里做什么。

作为指导者,我真的很高兴。 根据参加以前比赛的经验,我能够提供一些有关改善基准线以及建立本地验证的宝贵提示。 将来,这种格式将不仅仅如此:作为解决方案的架构师的Kaggle Master / Grandmaster +编写代码和测试假设的2-3 Kaggle Expert。 在我看来,这是纯粹的双赢,因为有经验的参与者已经懒得编写代码,也许花的时间还不多,而且初学者会获得更好的结果,不要因经验不足而犯小错,甚至可以更快地获得经验。
→
我们的解决方案代码→
通过ML锻炼记录表现