使用容器部署kubernetes HA

尊敬的哈伯读者,下午好! 2018年5月24日,在Kubernetes官方博客上发表了一篇名为Kubernetes Containered Integration Goes GA的文章,其中指出Containerd与Kubernetes的集成已准备就绪。 另外,Flant公司的家伙在博客上发布了文章翻译成俄语的内容 ,并增加了一些澄清。 阅读github上的项目文档后,我决定尝试将容器包装在“我自己的皮肤”上。
我公司有几个项目处于“还远远没有生产”阶段。 因此它们将成为我们的实验; 对于他们来说,我们决定尝试使用容器化部署Kubernetes的故障转移群集,并查看没有docker的生命。
如果您有兴趣了解我们的工作方式和发展成果,欢迎与我们联系。
示意图和部署说明
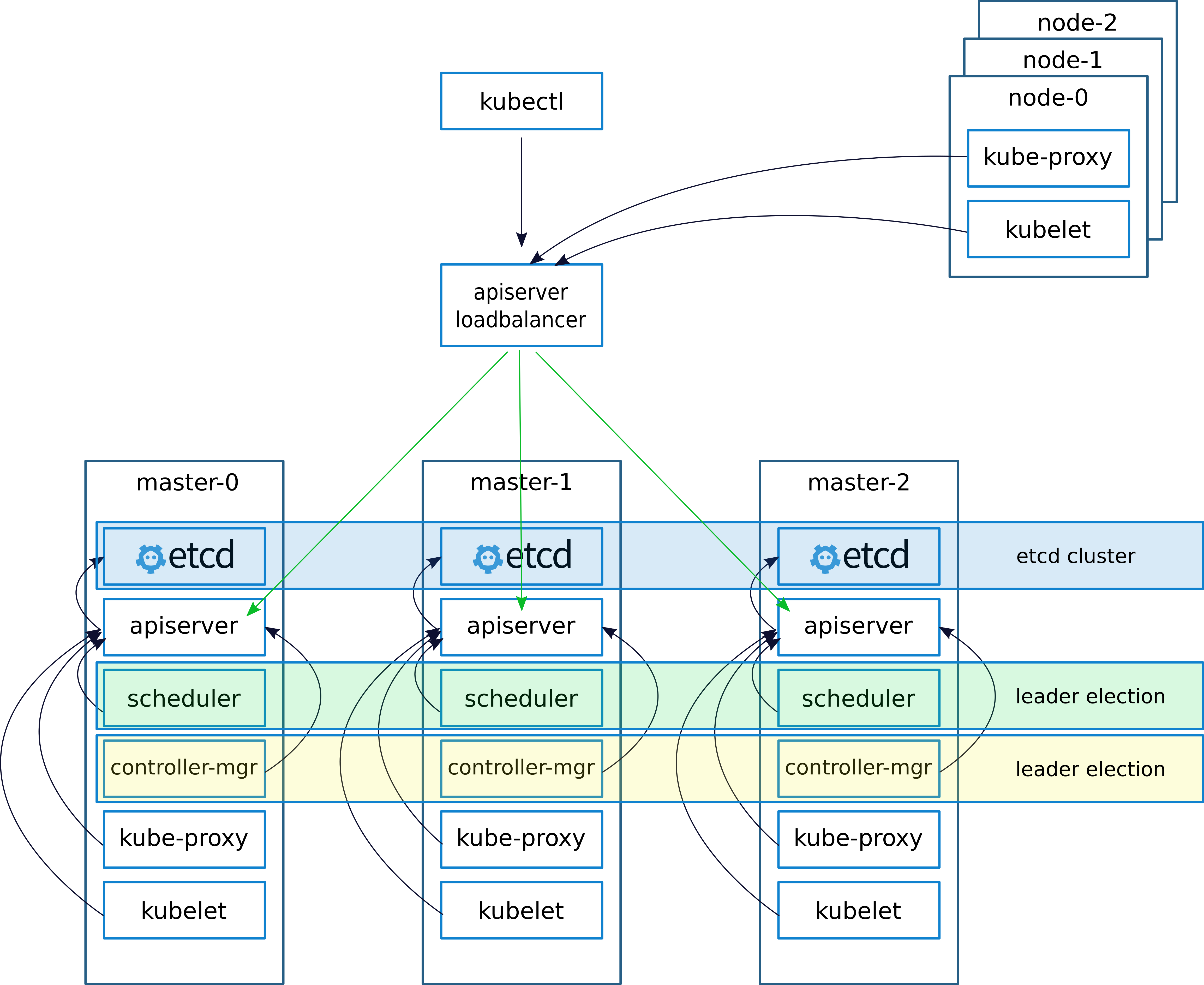
像往常一样,在部署集群时,(我在上一篇文章中谈到了这一点。
keepalived-适用于Linux的VRRP(虚拟路由器冗余协议)的实现Keepalived创建一个虚拟IP(VIRTIP),该虚拟IP“指向”(创建子接口)三个主机之一的IP。 keepalived守护程序监视计算机的运行状况,并在发生故障时,根据在每台服务器上配置keepalived时指定的“权重”,通过将VIRTIP切换到另一台服务器的IP,将故障服务器从活动服务器列表中排除。
Keepalived守护程序通过VRRP进行通信,互相发送消息到地址224.0.0.18。
如果邻居还没有发送消息,则在这段时间之后,他被认为已经死亡。 崩溃的服务器开始将其消息发送到网络后,一切都恢复原状
我们在kubernetes节点上使用API服务器配置工作,如下所示。
安装集群后,配置kube-proxy,将端口从6443更改为16443(以下详细信息)。 在每个主节点上,都部署了nginx,它充当负载平衡器,侦听端口16443,并在端口6443上对所有三个主节点进行上游(详细信息如下)。
通过使用keepalived以及使用nginx,此方案已提高了容错能力,从而实现了向导上API服务器之间的平衡。
在上一篇文章中,我描述了在docker中部署nginx和etcd的方法。 但是在这种情况下,我们没有docker,因此nginx和etcd将在masternodes上本地工作。
从理论上讲,可以使用容器化部署nginx和etcd,但是如果出现任何问题,这种方法会使诊断变得复杂,因此我们决定不进行本地试验和运行。
部署服务器的说明:
| 名称 | 知识产权 | 服务项目 |
|---|
| VIRTIP | 172.26.133.160 | ------ |
| kube-master01 | 172.26.133.161 | kubeadm,kubelet,kubectl,etcd,容器化,nginx,keepalived |
| kube-master02 | 172.26.133.162 | kubeadm,kubelet,kubectl,etcd,容器化,nginx,keepalived |
| kube-master03 | 172.26.133.163 | kubeadm,kubelet,kubectl,etcd,容器化,nginx,keepalived |
| kube-node01 | 172.26.133.164 | kubeadm,kubelet,kubectl,集装箱 |
| kube-node02 | 172.26.133.165 | kubeadm,kubelet,kubectl,集装箱 |
| kube-node03 | 172.26.133.166 | kubeadm,kubelet,kubectl,集装箱 |
安装kubeadm,kubelet,kubectl和相关软件包
所有命令均从root运行
sudo -i
apt-get update && apt-get install -y apt-transport-https curl curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update apt-get install -y kubelet kubeadm kubectl unzip tar apt-transport-https btrfs-tools libseccomp2 socat util-linux mc vim keepalived
安装conteinerd
cd / wget https://storage.googleapis.com/cri-containerd-release/cri-containerd-1.1.0-rc.0.linux-amd64.tar.gz tar -xvf cri-containerd-1.1.0-rc.0.linux-amd64.tar.gz
配置容器配置
mkdir -p /etc/containerd nano /etc/containerd/config.toml
添加到文件:
[plugins.cri] enable_tls_streaming = true
我们开始conteinerd,我们检查一切正常
systemctl enable containerd systemctl start containerd systemctl status containerd ● containerd.service - containerd container runtime Loaded: loaded (/etc/systemd/system/containerd.service; disabled; vendor preset: enabled) Active: active (running) since Mon 2018-06-25 12:32:01 MSK; 7s ago Docs: https://containerd.io Process: 10725 ExecStartPre=/sbin/modprobe overlay (code=exited, status=0/SUCCESS) Main PID: 10730 (containerd) Tasks: 15 (limit: 4915) Memory: 14.9M CPU: 375ms CGroup: /system.slice/containerd.service └─10730 /usr/local/bin/containerd Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Get image filesystem path "/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs"" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=error msg="Failed to load cni during init, please check CRI plugin status before setting up network for pods" error="cni con Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="loading plugin "io.containerd.grpc.v1.introspection"..." type=io.containerd.grpc.v1 Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start subscribing containerd event" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start recovering state" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg=serving... address="/run/containerd/containerd.sock" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="containerd successfully booted in 0.308755s" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start event monitor" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start snapshots syncer" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start streaming server"
安装并运行etcd
重要说明,我安装了kubernetes集群版本1.10。 几天之后,在撰写本文时,发布了1.11版,如果安装了1.11版,则设置变量ETCD_VERSION =“ v3.2.17”,如果设置1.10,则设置ETCD_VERSION =“ v3.1.12”。
export ETCD_VERSION="v3.1.12" curl -sSL https://github.com/coreos/etcd/releases/download/${ETCD_VERSION}/etcd-${ETCD_VERSION}-linux-amd64.tar.gz | tar -xzv --strip-components=1 -C /usr/local/bin/
从gitahab复制配置。
git clone https://github.com/rjeka/k8s-containerd.git cd k8s-containerd
在配置文件中配置变量。
vim create-config.sh
create-config.sh文件变量的描述
每个节点的本地计算机上的设置(每个节点都有自己的)
K8SHA_IPLOCAL-在其上配置脚本的节点的IP地址
K8SHA_ETCDNAME -ETCD集群中的本地计算机名称
K8SHA_KA_STATE-保持角色 一个MASTER节点,所有其他BACKUP。
K8SHA_KA_PRIO-保持优先级,主节点的剩余101和100为102。当编号为102的节点掉下时,编号为101的节点代替。
K8SHA_KA_INTF-保持网络接口。 keepalived将监听的接口的名称。
所有主节点的常规设置都相同:
K8SHA_IPVIRTUAL = 172.26.133.160-群集的虚拟IP
K8SHA_IP1 ... K8SHA_IP3-主站的IP地址
K8SHA_HOSTNAME1 ... K8SHA_HOSTNAME3-主节点的主机名。 重要的一点是,通过这些名称kubeadm将生成证书。
K8SHA_KA_AUTH-保持密码。 您可以指定任何
K8SHA_TOKEN-集群令牌。 可以使用kubeadm令牌generate命令生成
K8SHA_CIDR-炉膛的子网地址。 我使用法兰绒,所以CIDR为0.244.0.0/16。 确保屏幕-在配置中应为K8SHA_CIDR = 10.244.0.0 \ / 16
运行将配置Nginx,Keepalived,etcd和kubeadmin的脚本
./create-config.sh
我们开始etcd。
etcd我没有tls就解除了。 如果需要tls,则在
kubernetes官方文档中会详细说明如何为etcd生成证书。
systemctl daemon-reload && systemctl start etcd && systemctl enable etcd
状态检查
etcdctl cluster-health member ad059013ec46f37 is healthy: got healthy result from http://192.168.5.49:2379 member 4d63136c9a3226a1 is healthy: got healthy result from http://192.168.4.169:2379 member d61978cb3555071e is healthy: got healthy result from http://192.168.4.170:2379 cluster is healthy etcdctl member list ad059013ec46f37: name=hb-master03 peerURLs=http://192.168.5.48:2380 clientURLs=http://192.168.5.49:2379,http://192.168.5.49:4001 isLeader=false 4d63136c9a3226a1: name=hb-master01 peerURLs=http://192.168.4.169:2380 clientURLs=http://192.168.4.169:2379,http://192.168.4.169:4001 isLeader=true d61978cb3555071e: name=hb-master02 peerURLs=http://192.168.4.170:2380 clientURLs=http://192.168.4.170:2379,http://192.168.4.170:4001 isLeader=false
如果一切正常,请继续执行下一步。
配置kubeadmin
如果您使用的是kubeadm 1.11版,则可以跳过此步骤
为了使kybernetes不能与docker开始工作,而是与容器化工作,请配置kubeadmin配置
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
[服务]之后,在块中添加一行
Environment="KUBELET_EXTRA_ARGS=--runtime-cgroups=/system.slice/containerd.service --container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///run/containerd/containerd.sock"
整个配置应如下所示: [Service] Environment="KUBELET_EXTRA_ARGS=--runtime-cgroups=/system.slice/containerd.service --container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///run/containerd/containerd.sock" Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf" Environment="KUBELET_SYSTEM_PODS_ARGS=--pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true" Environment="KUBELET_NETWORK_ARGS=--network-plugin=cni --cni-conf-dir=/etc/cni/net.d --cni-bin-dir=/opt/cni/bin" Environment="KUBELET_DNS_ARGS=--cluster-dns=10.96.0.10 --cluster-domain=cluster.local" Environment="KUBELET_AUTHZ_ARGS=--authorization-mode=Webhook --client-ca-file=/etc/kubernetes/pki/ca.crt" Environment="KUBELET_CADVISOR_ARGS=--cadvisor-port=0" Environment="KUBELET_CERTIFICATE_ARGS=--rotate-certificates=true --cert-dir=/var/lib/kubelet/pki" ExecStart= ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_SYSTEM_PODS_ARGS $KUBELET_NETWORK_ARGS $KUBELET_DNS_ARGS $KUBELET_AUTHZ_ARGS $KUBELET_CADVISOR_ARGS $KUBELET_CERTIFICATE_ARGS $KUBELET_EXTRA_ARGS
如果您安装版本1.11并想尝试CoreDNS而不是kube-dns并测试动态配置,请在kubeadm-init.yaml配置文件中取消注释以下块:
feature-gates: DynamicKubeletConfig: true CoreDNS: true
重新启动kubelet
systemctl daemon-reload && systemctl restart kubelet
初始化第一个向导
在启动kubeadm之前,您需要重新启动keepalived并检查其状态。
systemctl restart keepalived.service systemctl status keepalived.service ● keepalived.service - Keepalive Daemon (LVS and VRRP) Loaded: loaded (/lib/systemd/system/keepalived.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2018-06-27 10:40:03 MSK; 1min 44s ago Process: 4589 ExecStart=/usr/sbin/keepalived $DAEMON_ARGS (code=exited, status=0/SUCCESS) Main PID: 4590 (keepalived) Tasks: 7 (limit: 4915) Memory: 15.3M CPU: 968ms CGroup: /system.slice/keepalived.service ├─4590 /usr/sbin/keepalived ├─4591 /usr/sbin/keepalived ├─4593 /usr/sbin/keepalived ├─5222 /usr/sbin/keepalived ├─5223 sh -c /etc/keepalived/check_apiserver.sh ├─5224 /bin/bash /etc/keepalived/check_apiserver.sh └─5231 sleep 5
检查是否VIRTIP ping
ping -c 4 172.26.133.160 PING 172.26.133.160 (172.26.133.160) 56(84) bytes of data. 64 bytes from 172.26.133.160: icmp_seq=1 ttl=64 time=0.030 ms 64 bytes from 172.26.133.160: icmp_seq=2 ttl=64 time=0.050 ms 64 bytes from 172.26.133.160: icmp_seq=3 ttl=64 time=0.050 ms 64 bytes from 172.26.133.160: icmp_seq=4 ttl=64 time=0.056 ms --- 172.26.133.160 ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3069ms rtt min/avg/max/mdev = 0.030/0.046/0.056/0.012 ms
之后,运行kubeadmin。 确保包括--skip-preflight-checks行。 默认情况下,Kubeadmin搜索docker且不跳过检查将失败并显示错误。
kubeadm init --config=kubeadm-init.yaml --skip-preflight-checks
kubeadm工作后,保存生成的行。 需要将工作节点输入集群。
kubeadm join 172.26.133.160:6443 --token XXXXXXXXXXXXXXXXXXXXXXXXX --discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
接下来,指示admin.conf文件的存储位置
如果我们以root身份工作,则:
vim ~/.bashrc export KUBECONFIG=/etc/kubernetes/admin.conf source ~/.bashrc
对于简单的用户,请按照屏幕上的说明进行操作。
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
将另外两个向导添加到群集。 为此,请将证书从kube-master01复制到kube-master02,将kube-master03复制到/ etc / kubernetes /目录。 为此,我为root配置了ssh访问,并在复制文件后将设置返回了。
scp -r /etc/kubernetes/pki 172.26.133.162:/etc/kubernetes/ scp -r /etc/kubernetes/pki 172.26.133.163:/etc/kubernetes/
复制到kube-master02和kube-master03后,运行。
kubeadm init --config=kubeadm-init.yaml --skip-preflight-checks
安装CIDR法兰绒
在kube-master01上执行
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.10.0/Documentation/kube-flannel.yml
当前版本的flanel可以在kubernetes文档中找到。
我们等到所有容器创建完毕。
watch -n1 kubectl get pods --all-namespaces -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE kube-system kube-apiserver-kube-master01 1/1 Running 0 17m 172.26.133.161 kube-master01 kube-system kube-apiserver-kube-master02 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-apiserver-kube-master03 1/1 Running 0 6m 172.26.133.163 kube-master03 kube-system kube-controller-manager-kube-master01 1/1 Running 0 17m 172.26.133.161 kube-master01 kube-system kube-controller-manager-kube-master02 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-controller-manager-kube-master03 1/1 Running 0 6m 172.26.133.163 kube-master03 kube-system kube-dns-86f4d74b45-8c24s 3/3 Running 0 17m 10.244.2.2 kube-master03 kube-system kube-flannel-ds-4h4w7 1/1 Running 0 2m 172.26.133.163 kube-master03 kube-system kube-flannel-ds-kf5mj 1/1 Running 0 2m 172.26.133.162 kube-master02 kube-system kube-flannel-ds-q6k4z 1/1 Running 0 2m 172.26.133.161 kube-master01 kube-system kube-proxy-9cjtp 1/1 Running 0 6m 172.26.133.163 kube-master03 kube-system kube-proxy-9sqk2 1/1 Running 0 17m 172.26.133.161 kube-master01 kube-system kube-proxy-jg2pt 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-scheduler-kube-master01 1/1 Running 0 18m 172.26.133.161 kube-master01 kube-system kube-scheduler-kube-master02 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-scheduler-kube-master03 1/1 Running 0 6m 172.26.133.163 kube-master03
我们将kube-dn复制到所有三个主机
在kube-master01上执行
kubectl scale --replicas=3 -n kube-system deployment/kube-dns
安装和配置Nginx
在每个主节点上,安装nginx作为Kubernetes API的平衡器
我在debian上拥有所有集群机器。 在nginx软件包中,流模块不支持,因此添加nginx存储库并从nginx`a存储库安装。 如果您使用的是其他操作系统,请参阅nginx文档 。
wget https://nginx.org/keys/nginx_signing.key sudo apt-key add nginx_signing.key echo -e "\n#nginx\n\ deb http://nginx.org/packages/debian/ stretch nginx\n\ deb-src http://nginx.org/packages/debian/ stretch nginx" >> /etc/apt/sources.list apt-get update && apt-get install nginx -y
创建nginx配置(如果尚未创建)
./create-config.sh
nginx.conf用户nginx;
worker_processes自动;
error_log /var/log/nginx/error.log警告;
pid /var/run/nginx.pid;
事件{
worker_connections 1024;
}
http {
包括/etc/nginx/mime.types;
default_type应用程序/八位字节流;
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; keepalive_timeout 65; #gzip on; include /etc/nginx/conf.d/*.conf;
}
流{
上游apiserver {
服务器172.26.133.161:6443权重= 5 max_fails = 3 fail_timeout = 30s;
服务器172.26.133.162:6443权重= 5 max_fails = 3 fail_timeout = 30s;
服务器172.26.133.163:6443权重= 5 max_fails = 3 fail_timeout = 30s;
} server { listen 16443; proxy_connect_timeout 1s; proxy_timeout 3s; proxy_pass apiserver; }
}
我们检查一切正常,然后应用配置
nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful systemctl restart nginx systemctl status nginx ● nginx.service - nginx - high performance web server Loaded: loaded (/lib/systemd/system/nginx.service; enabled; vendor preset: enabled) Active: active (running) since Thu 2018-06-28 08:48:09 MSK; 22s ago Docs: http://nginx.org/en/docs/ Process: 22132 ExecStart=/usr/sbin/nginx -c /etc/nginx/nginx.conf (code=exited, status=0/SUCCESS) Main PID: 22133 (nginx) Tasks: 2 (limit: 4915) Memory: 1.6M CPU: 7ms CGroup: /system.slice/nginx.service ├─22133 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf └─22134 nginx: worker process
测试平衡器
curl -k https://172.26.133.161:16443 | wc -l % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 233 100 233 0 0 12348 0 --:--:-- --:--:-- --:--:-- 12944
配置kube-proxy以与平衡器一起使用
配置平衡器后,在kubernetes设置中编辑端口。
kubectl edit -n kube-system configmap/kube-proxy
将服务器设置更改为https://172.26.133.160:16443
接下来,您需要配置kube-proxy以使用新端口
kubectl get pods --all-namespaces -o wide | grep proxy kube-system kube-proxy-9cjtp 1/1 Running 1 22h 172.26.133.163 kube-master03 kube-system kube-proxy-9sqk2 1/1 Running 1 22h 172.26.133.161 kube-master01 kube-system kube-proxy-jg2pt 1/1 Running 4 22h 172.26.133.162 kube-
我们删除所有Pod,将其删除后会自动使用新设置重新创建
kubectl delete pod -n kube-system kube-proxy-XXX ```bash . ```bash kubectl get pods --all-namespaces -o wide | grep proxy kube-system kube-proxy-hqrsw 1/1 Running 0 33s 172.26.133.161 kube-master01 kube-system kube-proxy-kzvw5 1/1 Running 0 47s 172.26.133.163 kube-master03 kube-system kube-proxy-zzkz5 1/1 Running 0 7s 172.26.133.162 kube-master02
将工作节点添加到集群
在每个根注释上,执行kubeadm生成的命令
kubeadm join 172.26.133.160:6443 --token XXXXXXXXXXXXXXXXXXXXXXXXX --discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX --cri-socket /run/containerd/containerd.sock --skip-preflight-checks
如果该行“丢失”,则需要生成一个新的
kubeadm token generate kubeadm token create <generated-token> --print-join-command --ttl=0
在/etc/kubernetes/bootstrap-kubelet.conf和/etc/kubernetes/kubelet.conf文件中的工作节点上
服务器变量值到我们的virtip
vim /etc/kubernetes/bootstrap-kubelet.conf server: https://172.26.133.60:16443 vim /etc/kubernetes/kubelet.conf server: https://172.26.133.60:16443
并重启容器化和kubernetes
systemctl restart containerd kubelet
仪表板安装
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml
创建具有管理员权限的用户:
kubectl apply -f kube-dashboard/dashboard-adminUser.yaml
我们获得了进入令牌:
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
通过VIRTIP上的NodePort配置仪表板访问
kubectl -n kube-system edit service kubernetes-dashboard
我们将类型:ClusterIP的值替换为类型:NodePort,并在端口部分:添加nodePort的值:30000(或您要访问面板的端口在30000至32000的范围内):

该面板现在位于https:// VIRTIP:30000
堆子
接下来,安装Heapster,这是一种用于获取群集组件指标的工具。
安装方式:
git clone https://github.com/kubernetes/heapster.git cd heapster kubectl create -f deploy/kube-config/influxdb/ kubectl create -f deploy/kube-config/rbac/heapster-rbac.yaml
结论
使用容器处理时,我没有发现任何特殊问题。 移除部署后,一旦出现炉膛故障,情况将难以理解。 Kubernetes认为under被删除了,但是under变成了一个奇特的“僵尸”。它仍然存在于节点上,但处于扩展状态。
我相信Containerd更适合作为kubernetes的容器运行时。 将来,很可能作为在Kubernetes中启动微服务的环境,有可能并且有必要使用面向不同任务,项目等的不同环境。
该项目发展很快。 阿里云已经开始积极使用conatinerd,并强调这是运行容器的理想环境。
根据开发人员的说法,谷歌云平台Kubernetes中容器的集成现在等同于Docker集成。
crictl控制台实用程序的一个很好的例子 。 我还将从创建的集群中给出一些示例:
kubectl describe nodes | grep "Container Runtime Version:"

Docker CLI缺少Kubernetes的基本概念,例如pod和命名空间,而crictl支持这些概念
crictl pods

如有必要,我们可以使用常用格式查看容器,例如docker
crictl ps

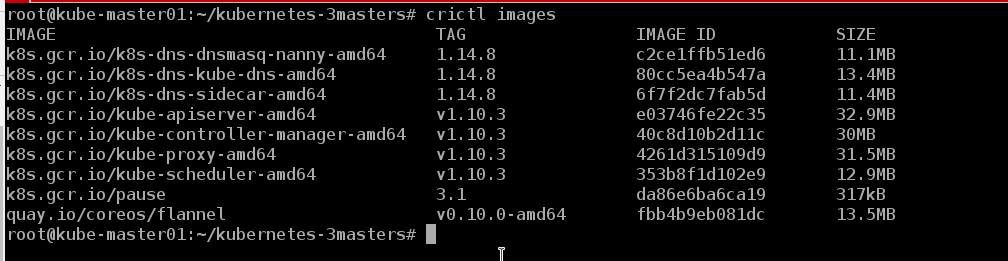
我们可以看到节点上的图像
crictl images
事实证明,没有码头工人的生活是:)
现在谈论错误和故障还为时过早,该集群已经与我们合作了大约一个星期。 在不久的将来,测试将被转移到其中,如果成功,则很可能是其中一个项目的开发人员。 为此,有一个想法是撰写涵盖DevOps流程的一系列文章,例如:创建集群,设置入口控制器并将其移动到单独的集群节点,自动化映像组装,检查映像的漏洞,部署等。 同时,我们将研究工作的稳定性,寻找错误并开发新产品。
另外,本手册适用于通过docker部署故障转移群集,您只需要根据Kubernetes官方文档中的说明安装docker,并跳过安装容器和配置kubeadm配置的步骤。
或者,您可以将容器化的容器和docker同时放置在同一主机上,并且,正如开发人员保证的那样,它们将完美地协同工作。 容器化是konbernetes容器启动器的启动环境,而docker就像docker)))
容器式存储库有一个
有趣的手册,用于设置单向导集群。 但是,用我的双手“举起”系统以更详细地了解每个组件的配置并了解其工作原理对我来说更有趣。
也许有一天,我的手会伸手去拿,而且我会写我的剧本来部署HA集群,因为在过去的六个月中,我已经部署了十几个集群,可能是时候使该过程自动化了。
另外,在撰写本文时,发布了kubernetes 1.11版。 您可以在Flant博客或官方kubernetes博客中了解主要更改。 我们将测试群集更新到版本1.11,并用CoreDNS替换了kube-dns。 此外,我们还包括DynamicKubeletConfig函数,用于测试配置的动态更新功能。
所用材料:
感谢您阅读到最后。
由于在RuNet中关于kubernetes的信息(尤其是在实际条件下运行的集群上)非常稀缺,因此欢迎提供不准确的迹象,以及对一般集群部署方案的评论。 我将尝试考虑它们并进行适当的更正。 我随时准备在评论,有关githab以及我个人资料中指示的任何社交网络中回答问题。
真诚的,尤金。