在过去的十年中,VTB经历了计算负载的大幅增加。 每年,它增加了一半半,凭证数量增加了两倍。 支持服务尽力而为,但要跟上这种步伐并不容易:查询计划正在移开,磁盘空间用尽,应用程序代码更新正在消耗所有资源。 在这篇文章中,我们将向您展示如何解决该问题而又不花很多钱在另一个IBM System p上。

2013年,卡处理(当时还是VTB24银行)位于当时最强大的服务器之一-IBM System p。 补充了不同报告的副本。 用于报告的副本位于其他设备上:每晚用于每日报告的更新数据库,用于活动Oracle Active Data Guard副本的用于运行报告的工具,以及用于中央银行报告的数据库,我们每月进行更新。
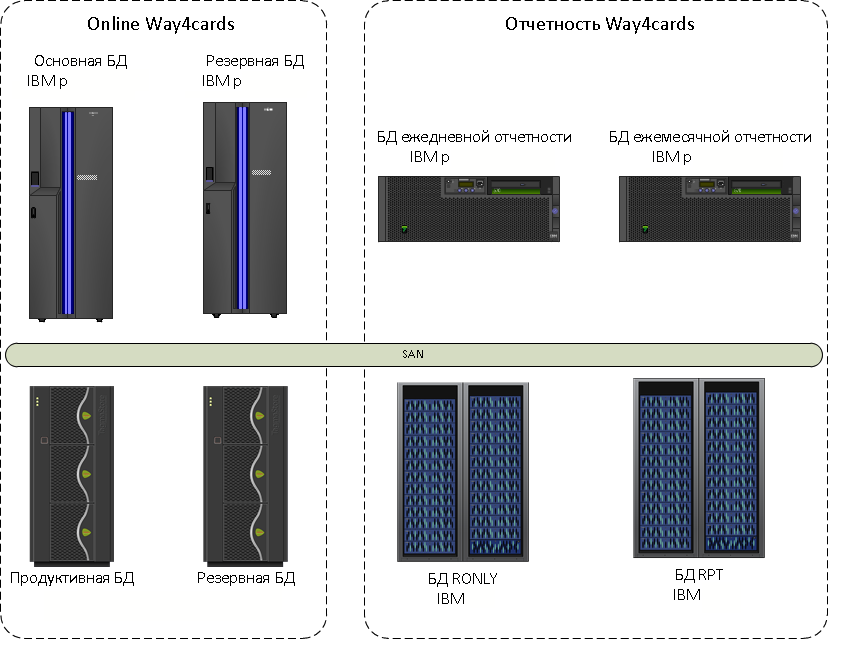
我们积极定制了系统的功能-大多数应用程序代码都被内部改进所占用。 同时,数据增长非常迅速。 结果,四个基地的查询计划经常恶化。 前端系统很慢。 从技术角度来看,还有一个困难:卡交易的OLTP负载与自定义功能和报告的DWH / DSS负载混合在一起。
解决这种情况的标准方法是转储资源并切换到更陡峭的数据存储子系统。 我们提出了一个更有趣的选项-我们采用了两种针对数据库操作进行了优化的Oracle Exadata硬件和软件组合来报告副本。
加工区分为“热”和“热”区。 使用IBM System p时,热区尚未移动到任何地方,并且仅将其数据库保留在其中。 “热”区域是Exadata上主数据库的副本。 这是所有报告和自定义功能。 使用Oracle GoldenGate复制数据。
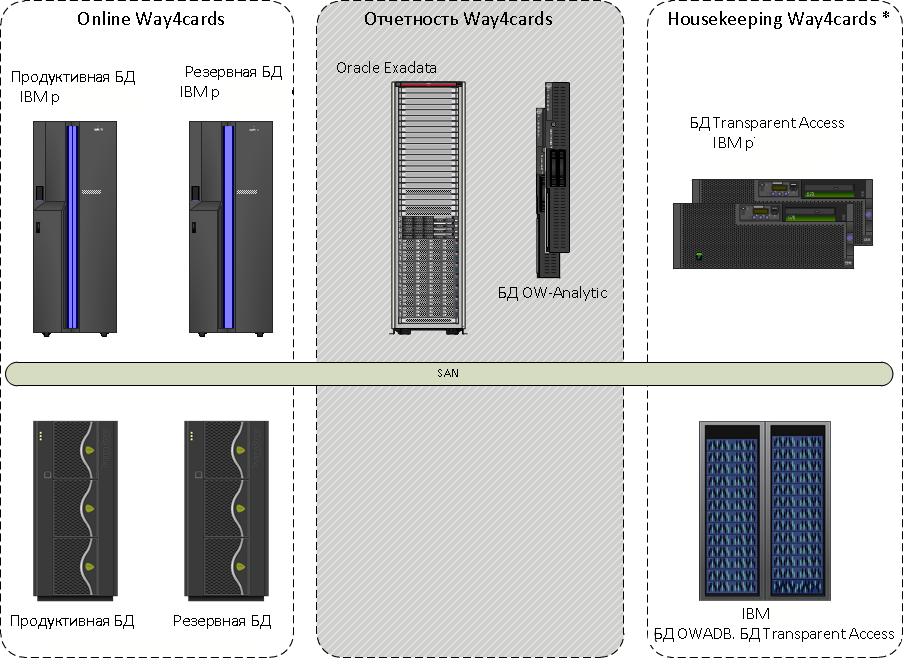
我们在Exadata上进行了副本测试:由于Oracle Exadata Storage软件的架构和功能-智能扫描,存储索引,Bloom过滤器等,平均而言,报告速度提高了五倍。 为中央银行准备报告所需的时间减少了十倍,现在一些报告的编写时间不到1小时。 在移植到Exadata期间优化查询的主要工作是删除以前有助于在旧平台上工作的提示。
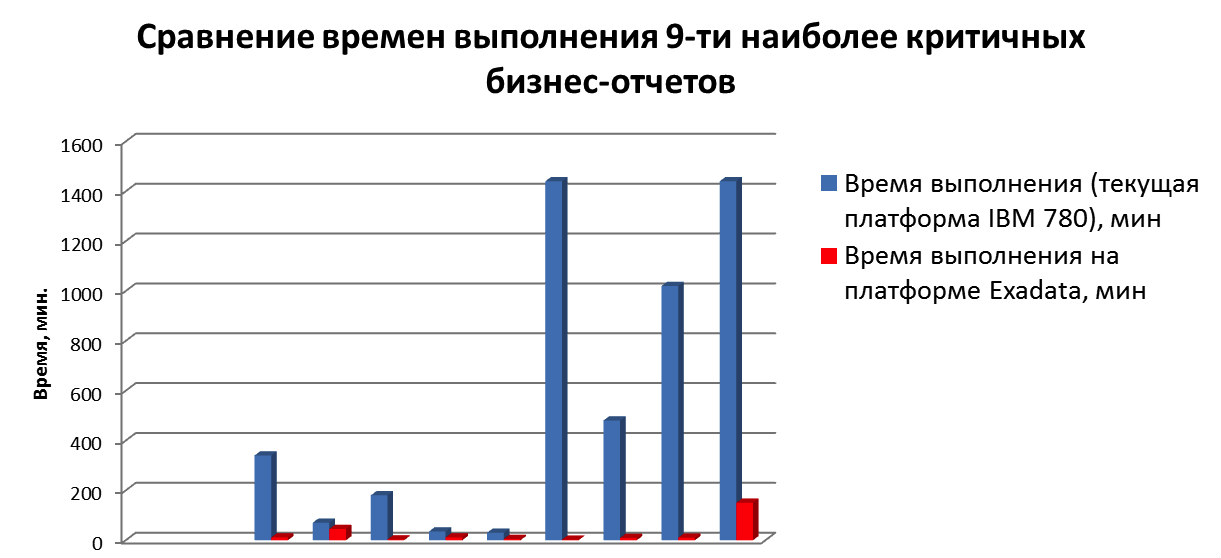
我们进行了可行性研究,将各种参数的选项与当前系统的通常扩展以及两个Exadata复合体的参与进行了比较。
- 性能。 Exadata的IOPS为4万IOPS,而IOPS为40万。 Oracle解决方案面向大量数据,全表扫描要快得多。
- 自定义选项。 在标准解决方案中,我们不能在不更改生产数据库的情况下更改对象的结构,这是供应商禁止的。 在Exadata中,我们可以删除不必要的索引,添加必要的索引,并改善系统的响应。
- 缩放比例。 Exadata以相对较低的成本提供了线性的生产率提高。
- 正在报告。 Exadata综合平台的报告速度提高了5倍,而现有系统的扩展速度提高了1.5倍。
- 服务。 Oracle基础结构具有统一的技术支持,是用于服务器,磁盘子系统和网络基础结构的单个更新系统。 如果采用正常扩展,则需要与其他供应商合作-停机时间会增加,并带来其他不便。
- 费用。 Exadata在这里赢得了胜利。
最初,GoldenGate复制被证明是一个弱点:在源头进行长事务的情况下,它落后了。 我们通过更新和完善一些应用程序流程解决了这一问题。 之后,与Exadata的合作仅对我们揭示了优势。
我们引入了自定义索引和分区,这使我们能够提高自定义函数的性能。 IBM不允许此优化。
将分析报告转移到“热”区可以减少“热”区历史数据的存储深度。 这降低了昂贵的存储成本。 设法加快插入索引的速度。 通过管家模块删除的数据在GoldenGate级别进行了过滤,结果,副本具有新数据和整个故事。
Exadata使用混合列压缩(HCC),可大大节省磁盘空间。 超过一年的数据通过低归档方法压缩,超过一个月的数据通过高级压缩方法压缩,较新的数据不会被压缩以提高速度。
对于升级,用具有更大容量的磁盘和更强大的处理器的存储单元替换Exadata中的整个存储单元是最有效的。 但是您可以在同一系统中使用不同版本的存储单元-Oracle允许这样做。
到目前为止,基于Oracle Exadata和数据库技术实现的卡处理报告运行良好,并且新的银行系统也基于相同的原理构建。