在现代互联网上,有超过6.3亿个站点,但其中只有6%包含俄语内容。 语言障碍是网络用户之间知识传播的主要问题,我们认为,这不仅必须通过教授外语来解决,而且必须在浏览器中使用自动机器翻译来解决。
今天,我们将向Habr读者介绍Yandex.Browser转换器中的两项重要技术更改。 首先,现在所选单词和短语的翻译使用混合模型,我们回想起这种方法与专有神经网络的使用有何不同。 其次,翻译器的神经网络现在考虑了网页的结构,我们还将在下文中讨论其功能。
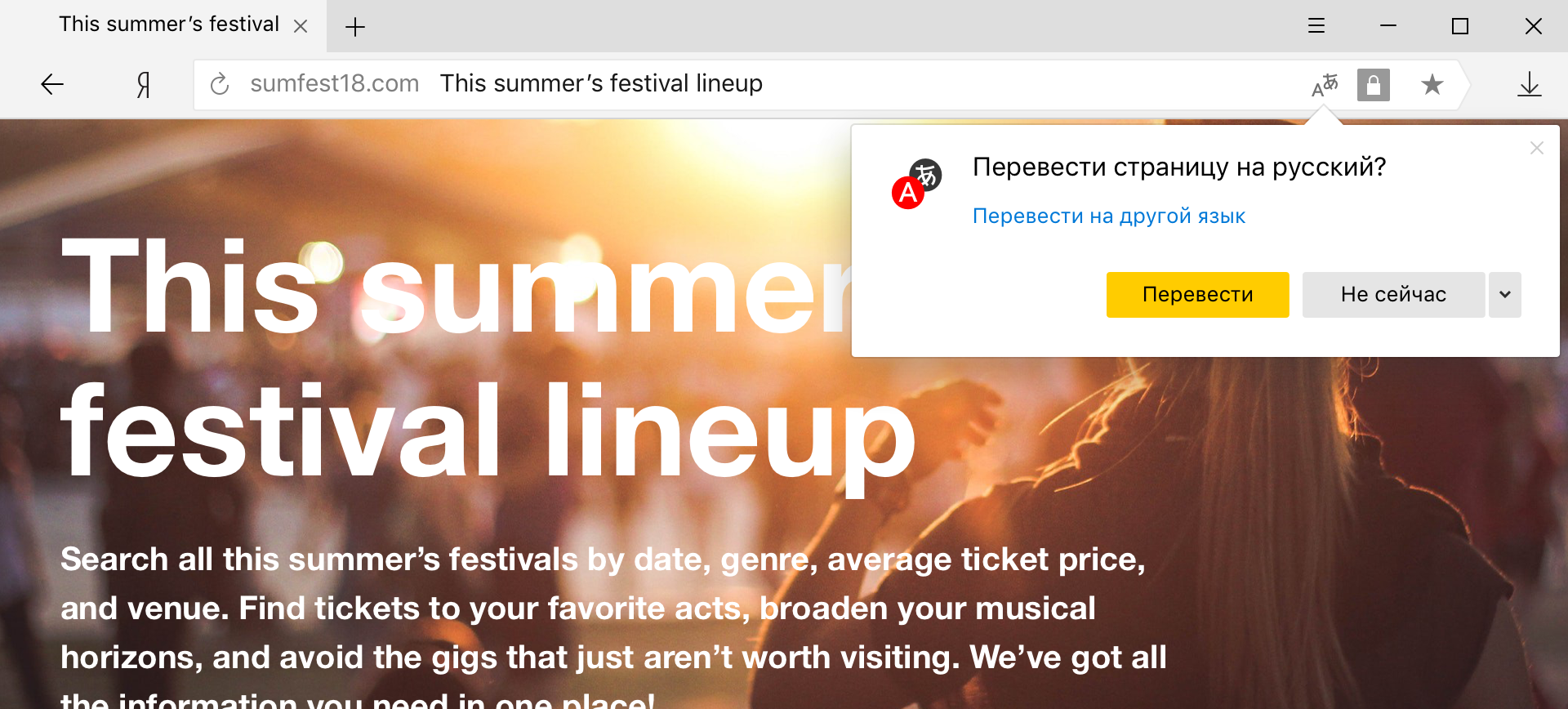
混合单词和短语翻译器
最早的机器翻译系统是基于
字典和规则 (实际上是手写的常规)来确定翻译质量的。 专业的语言学家已经努力多年,提出了越来越详细的手册规则。 这项工作非常耗时,以致只对最流行的几种语言进行了认真的关注,但是即使在它们的框架内,机器也无法很好地应对。 生活语言是一个非常复杂的系统,很少遵守规则。 描述两种语言的对应规则甚至更加困难。
机器能够不断适应不断变化的条件的唯一方法是独立学习大量平行文本(含义相同,但使用不同语言编写的文本)。 这是机器翻译的统计方法。 计算机比较平行文本并独立显示图案。
统计翻译器既有优点也有缺点。 一方面,他很好地记住了稀有而复杂的单词和短语。 如果在平行文本中找到它们,翻译人员将记住它们并继续正确翻译。 另一方面,翻译的结果可能类似于组装后的难题:整体情况似乎是可以理解的,但是如果仔细观察,您会发现它是由单独的部分组成的。 原因是翻译者以标识符的形式呈现单个词,而这些标识符绝不反映它们之间的关系。 这与人们根据单词的使用方式,单词与其他单词的关系以及它们与单词的区别来决定时人们的语言理解方式不同。
神经网络有助于解决这个问题。 通常,在神经机器翻译中使用的单词的矢量表示(单词嵌入)将每个单词与长度为数百个数字的矢量进行匹配。 与统计方法中的简单标识符相反,矢量是在神经网络训练期间形成的,并考虑了词之间的关系。 例如,模型可以识别出,由于“茶”和“咖啡”通常出现在相似的上下文中,因此在新单词“ spill”的上下文中这两个单词都应该是可能的,也就是说,在训练数据中只遇到其中一个。
但是,教学向量表示的过程显然比从机械上记忆示例更需要统计学上的要求。 另外,不清楚如何处理那些罕见的输入字,这些输入字通常不会被网络满足,无法为其建立可接受的矢量表示。 在这种情况下,将两种方法组合在一起是合乎逻辑的。
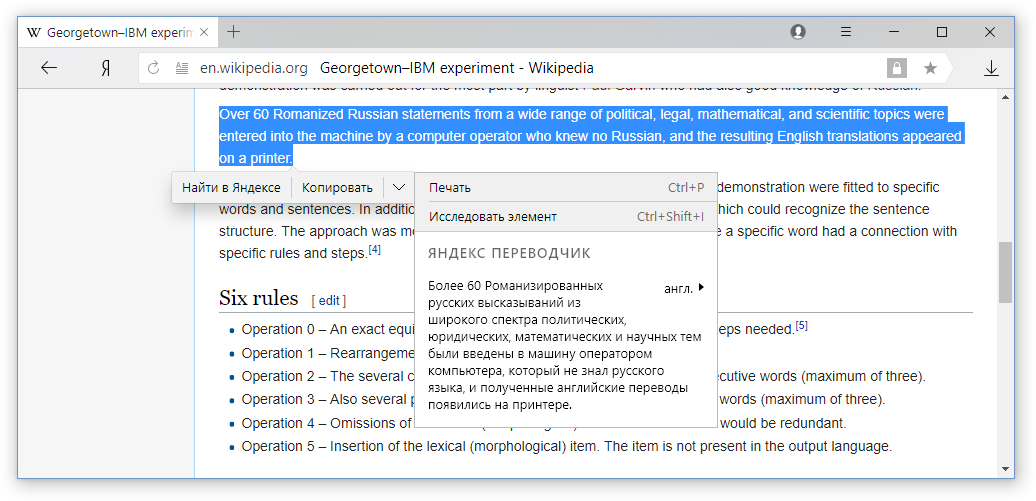
从去年开始,Yandex.Translator一直在使用
混合模型 。 当翻译者从用户处接收文本时,他会将其提供给两个系统-神经网络和统计翻译者。 然后,基于
CatBoost训练方法的算法会评估哪种翻译效果更好。 评分时,要考虑许多因素-从句子的长度(统计模型可以更好地翻译短短语)到语法。 向用户显示公认的最佳翻译。
当用户在页面上选择特定的单词和短语进行翻译时,它就是Yandex.Browser中现在使用的混合模型。
对于一般说外语并且只想翻译未知单词的人来说,此模式特别方便。 但是,例如,如果您遇到的不是中文,而是普通的英语,那么在没有页面翻译器的情况下将很难做到。 看起来差异仅在于翻译文本的数量,而并非如此简单。
网络神经网络翻译器
从
乔治敦(Georgetown)实验时代到今天,几乎所有的机器翻译系统都经过培训,可以分别翻译源文本的每个句子。 网页不仅是一组句子,而且是结构化的文本,其中具有根本不同的元素。 考虑大多数页面的基本元素。
标题 。 通常,当您转到页面时,我们会立即看到明亮的大文本。 标题通常包含新闻的本质,因此正确翻译新闻非常重要。 但这很难做到,因为标题中的文本很小,如果不理解上下文,可能会犯错误。 就英语而言,它仍然更加复杂,因为英语标题通常包含具有非传统语法,不定式甚至是动词的短语。 例如,
《权力的游戏》前传就宣布了 。
导览 有助于我们浏览网站的单词和短语。 例如,如果
Home ,
Back和
My我的帐户位于网站菜单上而不是发布文本中,则几乎不值得翻译为“ Home”,“ Back”和“ My Account”。
主要文字 。 他的一切都变得简单了;他与我们在书中可以找到的普通文本和句子几乎没有什么不同。 但是即使在这里,重要的是要确保翻译的一致性,即确保在同一网页内以相同的方式翻译相同的术语和概念。
对于高质量的网页翻译,仅使用神经网络或混合模型是不够的-您还必须考虑网页的结构。 为此,我们需要应对许多技术难题。
文本段的分类 。 为此,我们再次使用CatBoost和基于文本本身以及基于文档HTML标记的因素(标签,文本大小,每单位文本的链接数等)。 这些因素是非常不同的,因此CatBoost(基于梯度增强)显示出最佳结果(分类精度高于95%)。 但是,仅靠细分市场分类是不够的。
数据不平衡 。 传统上,Yandex.Translator算法从Internet上学习文本。 看来,这是培训网页翻译人员的理想解决方案(换句话说,网络从与我们将在其上使用的文本性质相同的文本中学习)。 但是,一旦我们学会了将不同的细分彼此分开,便发现了一个有趣的功能。 平均而言,内容约占网站上所有文本的85%,而标题和导航仅分别占7.5%。 还记得样式和语法本身的标题和导航元素与本文的其余部分明显不同。 这两个因素共同导致数据偏斜问题。 对于神经网络来说,简单地忽略训练集中这些非常差表示的片段的特征会更有利可图。 网络仅学会很好地翻译主要文本,因此,标题和导航的翻译质量会受到影响。 为了消除这种不愉快的影响,我们做了两件事:对于每对平行句子,我们将三种类型的片段(内容,标题或导航)中的一种归因于元信息,并由于以下事实而将后两者在培训大楼中的集中度人为地提高到33%:开始更多地显示与学习神经网络类似的例子。
多任务学习 。 由于我们现在可以将网页上的文本分为三类,因此训练三个独立的模型似乎是很自然的主意,每种模型都可以处理其自身类型的文本(标题,导航或内容)的翻译。 这确实很好,但是当我们训练一个神经网络一次翻译所有类型的文本时,该方案效果更好。 理解的关键在于
多任务学习 (MTL)的概念:如果多个机器学习任务之间存在内部联系,那么学习同时解决这些问题的模型可以比狭profile的专业模型更好地解决每个问题!
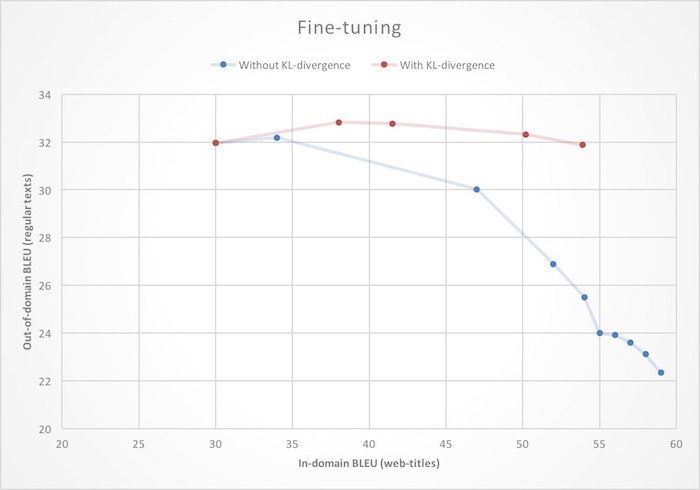
微调 。 我们已经有很好的机器翻译,因此从头开始为Yandex.Browser训练新的翻译器是不合理的。 采用基本的系统来翻译普通文本并对其进行重新培训以使用网页是更合乎逻辑的。 在神经网络中,这通常称为微调。 但是如果您直接处理此任务,即 只是使用完成的模型中的值初始化神经网络权重并开始学习新数据时,您可能会遇到域移位的影响:随着学习,网页翻译的质量(域内)将提高,但是普通的翻译质量(域外) )文字将掉落。 为了摆脱这种令人不快的功能,在重新训练期间,我们对神经网络施加了额外的限制,禁止其与初始状态相比改变太多的权重。
从数学上讲,这是通过在损失函数中添加一项来表示的,该损失函数
是由源网络和经过重新训练的网络生成的下一个单词的概率分布之间的
Kullback-Leibler距离 (KL散度)。 如您在插图中所看到的,这导致以下事实:网页翻译质量的提高不再导致纯文本翻译的质量下降。
 从导航中抛光频率短语
从导航中抛光频率短语 。 在研究新的翻译器的过程中,我们收集了网页各个部分的文本统计数据,并发现了一个有趣的现象。 与导航元素有关的文本非常标准化,因此通常它们是相同的模板短语。 这是一种非常强大的效果,在Internet上找到的所有导航短语中,有超过一半仅占最常用的2000个。
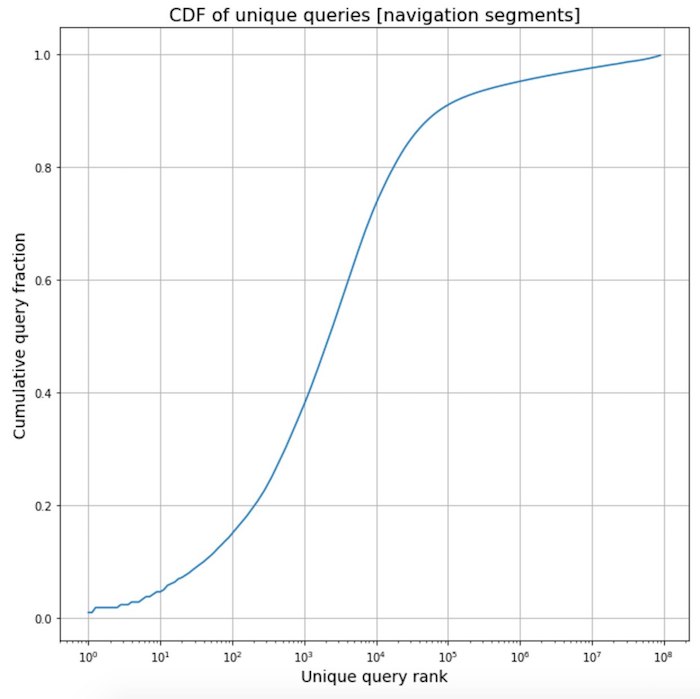
当然,我们利用了这一优势,将数千个最常用的短语及其翻译提供给我们的翻译人员进行验证,以绝对确保其质量。
外部对齐。 浏览器中还有一个重要的网页翻译器要求-它不应该扭曲标记。 当HTML标签位于句子之外或其边界时,不会出现任何问题。 但是,例如,如果句子中有
两个带下划线的单词 ,那么在翻译中我们希望看到“两个
带下划线的单词”。 即 转让的结果必须满足两个条件:
- 翻译中带下划线的片段必须与源文本中带下划线的片段相对应。
- 带下划线的片段边界处的翻译的一致性不应受到侵犯。
为了确保这种行为,我们首先照常翻译文本,然后使用
逐字对齐的统计模型来确定原始文本和翻译文本片段之间的对应关系。 这有助于了解需要强调的内容(斜体突出显示,超链接格式等等)。
交叉口观察员 。 与前几代的统计模型相比,我们训练的强大的神经网络转换模型在服务器(CPU和GPU)上需要大量的计算资源。 同时,用户不一定总是读完页面,因此将网页的所有文本发送到云端似乎是不必要的。 为了节省服务器资源和用户流量,我们教译者使用
Intersection Observer API仅发送屏幕上显示的文本进行翻译。 因此,我们能够将翻译的流量消耗减少3倍以上。
关于考虑到Yandex.Browser中网页结构的神经网络翻译器引入结果的几句话。 为了评估翻译质量,我们使用BLEU *度量标准,该标准比较机器和专业翻译人员进行的翻译,并以0到100%的等级评估机器翻译的质量。 机器翻译与人工翻译越接近,百分比越高。 通常,当BLEU指标增长至少3%时,用户会注意到质量变化。 新的Yandex.Browser翻译器显示了将近18%的增长。

机器翻译是人工智能技术领域中最复杂,最热门和研究最多的任务之一。 这是由于其纯粹的数学吸引力及其在现代世界中的相关性,在互联网上,每一秒钟都以各种语言创建了数量惊人的内容。 直到最近,机器翻译主要引起笑声(记住
鼠标制造商 ),如今它可以帮助用户克服语言障碍。
理想的质量仍然遥不可及,因此我们将继续朝着这个方向走在技术的最前沿,以使Yandex.Browser用户可以超越例如Runet并在Internet上的任何地方为自己找到有用的内容。