本文提供了卷积神经网络(CNN)的可访问的理论概述,并解释了它们在图像分类问题中的应用。
通用方法:无深度学习
术语“图像处理”指的是一类广泛的任务,其输入数据是图像,而输出可以是图像或一组关联的特征。 有很多选项:分类,分割,注释,对象检测等。在本文中,我们检查图像的分类,不仅因为它是最简单的任务,而且因为它是许多其他任务的基础。
图像分类的一般方法包括以下两个步骤:
- 生成图像的重要特征。
- 根据图像的属性对图像进行分类。
常见的操作序列使用简单的模型,例如多层感知器(MLP),支持向量机(SVM),k最近邻方法和基于人工创建特征的逻辑回归。 使用各种变换(例如灰度和阈值检测)和描述符(例如,定向梯度直方图(
HOG )或尺度不变特征变换(
SIFT )变换)生成属性。等
普遍接受的方法的主要局限性在于专家的参与,这些专家会选择一组步骤和一系列步骤来生成特征。
随着时间的流逝,人们注意到,大多数用于生成特征的技术都可以使用内核(过滤器)-小矩阵(通常为5×5)(它们是原始图像的卷积)来推广。 卷积可以看作是一个连续的两阶段过程:
- 在整个源图像中传递相同的固定核心。
- 在每个步骤中,计算内核和内核当前位置的原始图像的标量积。
图像和内核卷积的结果称为特征图。
I. Goodfellow,I。Benjio和A.Courville
在最近出版的《深度学习》一书的
相关章节中给出了更严格的数学解释。
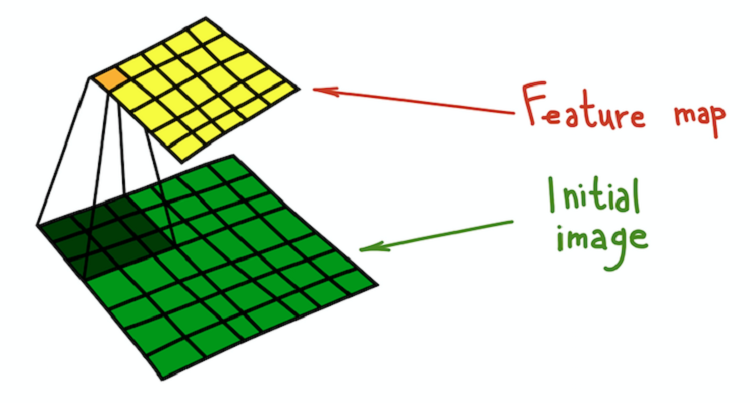 核心(深绿色)与原始图像(绿色)的卷积过程,结果获得了特征图(黄色)。
核心(深绿色)与原始图像(绿色)的卷积过程,结果获得了特征图(黄色)。可以使用滤镜进行转换的一个简单示例就是模糊图像。 采取包含所有单位的过滤器。 它计算由滤波器确定的邻域的平均值。 在这种情况下,邻域是正方形,但可以是十字形或其他形状。 平均会导致丢失有关对象确切位置的信息,从而使整个图像模糊。 对于任何手动创建的过滤器,都可以给出类似的直观解释。
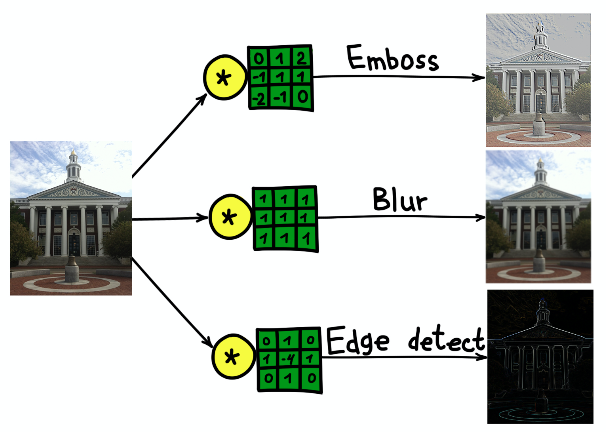 哈佛大学大楼图像具有三个不同核心的卷积结果。
哈佛大学大楼图像具有三个不同核心的卷积结果。卷积神经网络
卷积图像分类方法有许多明显的缺点:
- 一个多步骤的过程,而不是端到端的序列。
- 过滤器是一个很好的泛化工具,但它们是固定矩阵。 如何在过滤器中选择权重?
幸运的是,已经发明了可学习的过滤器,这是CNN的基本原理。 原理很简单:我们将训练应用于图像描述的过滤器,以最好地完成其任务。
CNN没有一位发明家,但I. LeCun等人在
“基于梯度的学习应用于文档识别”一书中,LeNet-5 *是其最早应用的案例之一作者。
CNN用一块石头杀死了两只鸟:不需要预先定义过滤器,学习过程将是端到端的。 典型的CNN架构包括以下部分:
让我们更详细地考虑每个部分。
卷积层
卷积层是CNN的主要结构元素。 卷积层具有一组特征:
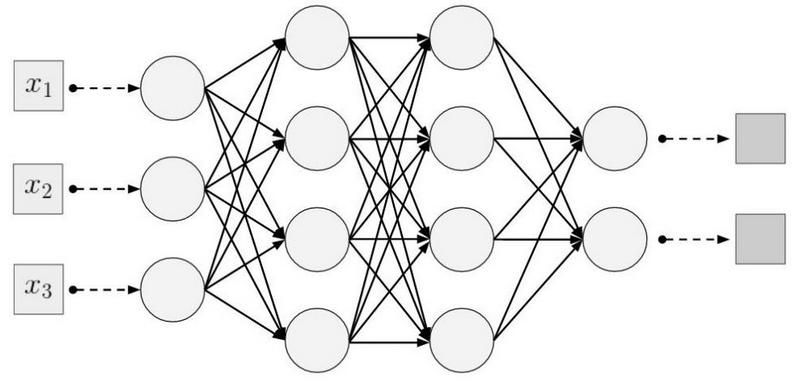
本地(稀疏)连接 。 在密集层中,每个神经元都连接到上一层的每个神经元(因此被称为密集)。 在卷积层中,每个神经元仅连接到前一层的一小部分神经元。
 一维神经网络的示例。 (左)典型密集网络中神经元的连接,(右)卷积层固有的局部连接的特征。 深度学习从I.Goodfellow和其他人那里拍摄的图像神经元所连接的区域
一维神经网络的示例。 (左)典型密集网络中神经元的连接,(右)卷积层固有的局部连接的特征。 深度学习从I.Goodfellow和其他人那里拍摄的图像神经元所连接的区域的大小称为过滤器的大小(对于一维数据,例如时间序列,过滤器的长度;对于二维数据,例如图像,宽度/高度的过滤器)。 在右图中,滤波器的大小为3。
建立连接的
权重称为滤波器(在一维数据的情况下为矢量,而在二维数据的矩阵中)。
步进是过滤器在数据上移动的距离 (在右图中,步进为1)。 本地连接的想法无非是一个迈出一步的内核。 每个卷积级神经元代表并实现沿原始图像滑动的原子核的一个特定位置。
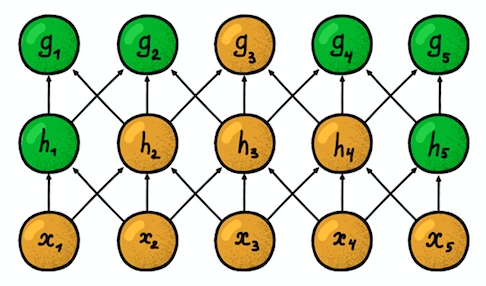 两个相邻的一维卷积层
两个相邻的一维卷积层另一个重要特性是所谓的
磁化率带 。 它反映了当前神经元可以“看到”的原始信号的位置数量。 例如,由于每个神经元仅连接到原始信号的三个神经元,因此如图所示,第一网络层的敏感区等于滤波器3的大小。 但是,在第二层上,敏感性区域已经是5,因为第二层的神经元聚集了第一层的三个神经元,每个神经元都有一个敏感性区域3。随着深度的增加,敏感性区域呈线性增长。
共享参数 。 回想一下,在经典图像处理中,同一核心在整个图像上都滑动。 同样的想法在这里适用。 我们仅固定一层权重过滤器的大小,并将这些权重应用于该层中的所有神经元。 这等效于在整个图像中滑动相同的核心。 但是可能会出现一个问题:我们如何才能学习到这么少的参数?
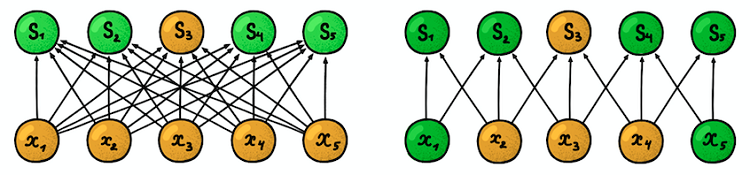
 黑色箭头表示相同的权重。 (左)常规MLP,其中每个加权因子是一个单独的参数,(右)参数分离的示例,其中多个加权因子表示相同的训练参数空间结构
黑色箭头表示相同的权重。 (左)常规MLP,其中每个加权因子是一个单独的参数,(右)参数分离的示例,其中多个加权因子表示相同的训练参数空间结构 。 这个问题的答案很简单:我们将在一层中训练多个过滤器! 它们彼此平行放置,从而形成新的尺寸。
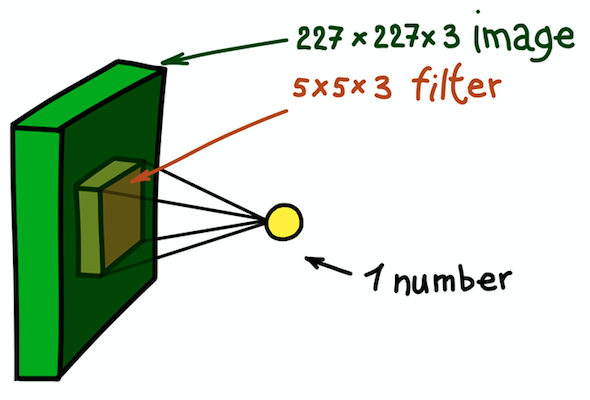
我们稍停片刻,并解释一下以227×227的二维RGB图像为例的想法。请注意,这里我们处理的是三通道输入图像,从本质上讲,这意味着我们有三个输入图像或三维输入数据。
 输入图像的空间结构
输入图像的空间结构我们将通道的尺寸视为图像深度(请注意,这与神经网络的深度不同,后者等于网络层的数量)。 问题是如何确定这种情况的内核。
 二维核的一个示例,它实质上是带有附加深度测量的三维矩阵。 这个过滤器使图像卷积; 也就是说,滑过空间中的图像,计算标量积
二维核的一个示例,它实质上是带有附加深度测量的三维矩阵。 这个过滤器使图像卷积; 也就是说,滑过空间中的图像,计算标量积答案很简单,尽管仍然不很明显:我们将内核也设为三维。 前两个维将保持不变(核心宽度和高度),第三个维始终等于输入数据的深度。
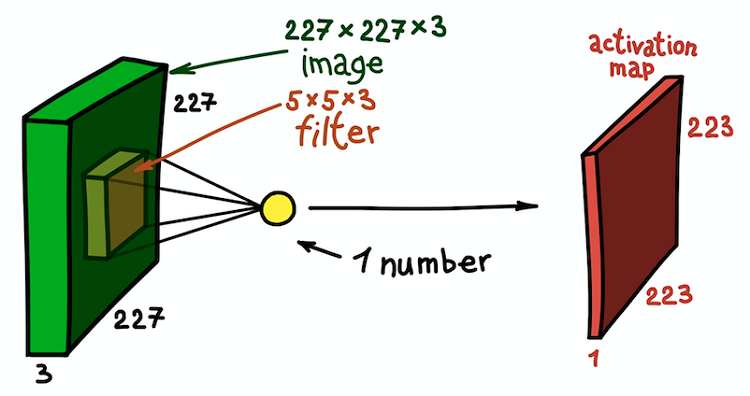
 空间卷积步骤的示例。 滤波器的标量积与一小部分图像5×5×3的结果(即5×5×5 +1 = 76,标量积的尺寸+位移)为一个数
空间卷积步骤的示例。 滤波器的标量积与一小部分图像5×5×3的结果(即5×5×5 +1 = 76,标量积的尺寸+位移)为一个数在这种情况下,原始图像的整个5×5×3截面将转换为一个数字,而三维图像本身将转换为
特征图 (
激活图 )。 特征图是一组神经元,每个神经元都计算了自己的功能,同时考虑了上面讨论的两个基本原理:
局部连接 (每个神经元仅与输入数据的一小部分相关)和
参数分离 (所有神经元都使用相同的过滤器)。 理想情况下,此特征图将与普遍接受的网络示例中已经遇到的特征图相同-它存储输入图像和滤波器的卷积结果。
 核心与所有空间位置卷积的结果导致的特征图
核心与所有空间位置卷积的结果导致的特征图请注意,要素地图的深度为1,因为我们仅使用了一个过滤器。 但是没有什么可以阻止我们使用更多的过滤器。 例如,6。所有这些都将与相同的输入数据进行交互,并且将彼此独立地工作。 让我们更进一步,将这些功能卡组合在一起。 由于过滤器的尺寸相同,因此它们的空间尺寸相同。 因此,可以将收集在一起的特征图视为新的三维矩阵,其深度尺寸由来自不同核心的特征图表示。 从这个意义上说,输入图像的RGB通道就是三个原始特征图。
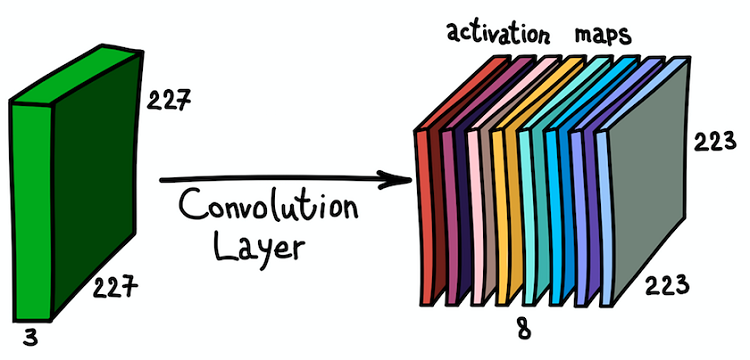 将多个滤镜并行应用到输入图像和激活卡的结果集
将多个滤镜并行应用到输入图像和激活卡的结果集对特征图及其组合的这种理解非常重要,因为认识到这一点后,我们可以扩展网络体系结构,并在另一层之上安装卷积层,从而增加敏感区并丰富我们的分类器。
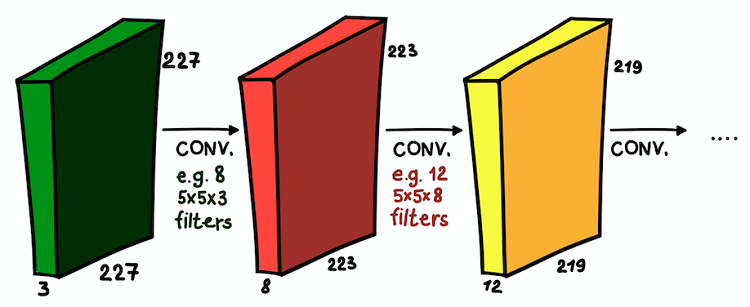 卷积层安装在彼此的顶部。 在每一层中,过滤器的大小及其数量可能会有所不同
卷积层安装在彼此的顶部。 在每一层中,过滤器的大小及其数量可能会有所不同现在我们了解了卷积网络。 这些层的主要目标与普遍接受的方法相同-检测图像的明显征兆。 并且,如果在第一层中这些符号可能非常简单(垂直/水平线的存在),则网络的深度会增加其抽象程度(狗/猫/人的存在)。
二次采样层
卷积层是CNN的主要构建块。 但是还有另一个重要且经常使用的部分-这些是子样本层。 在常规图像处理中,没有直接的模拟,但是可以将子样本视为另一种内核。 这是什么
 二次采样的例子。 (左)子样本如何改变数据数组的空间大小(但不改变通道!),(右)子样本工作原理的基本方案
二次采样的例子。 (左)子样本如何改变数据数组的空间大小(但不改变通道!),(右)子样本工作原理的基本方案子样本使用特定的聚合函数(例如,最大值,平均值等)对输入数据的每个像素的邻域的一部分进行过滤。子样本本质上与卷积相同,但是像素合并函数不限于标量积。 另一个重要区别是子采样仅在空间维度上有效。 二次采样层的一个特征是,
节距通常等于滤波器的大小 (典型值为2)。
子样本具有三个主要目标:
- 减少空间尺寸或子采样。 这样做是为了减少参数的数量。
- 易感区的增长。 由于后续层中的子样本神经元,输入信号的更多步被累加
- 输入信号中图案位置的微小异质性的平移不变性。 通过计算输入信号小邻域的聚合统计量,子样本可以忽略其中的小空间位移。
厚层
卷积层和子样本层具有相同的目的-生成图像属性。 最后一步是根据检测到的特征对输入图像进行分类。 在CNN,网络顶部的密集层可以做到这一点。 网络的这一部分称为
分类 。 它可以包含彼此完全连通的几层,但通常以
softmax类层结束,该层由多变量逻辑激活函数激活,其中块数等于类数。 在该层的输出处是输入对象按类别的概率分布。 现在,可以通过选择最可能的类别来对图像进行分类。