 照片: Alexander Korolkov / WG
照片: Alexander Korolkov / WG6月3日,在红场莫斯科图书节的最后一天,语言学家
亚历山大·派珀斯基谈到了计算机语言学。 他谈到了机器翻译,神经网络,单词向量映射,并提出了有关人工智能边界的问题。
不同的人听了演讲。 例如在我右边,一位中国游客啄她的鼻子。 当然,亚历山大也理解-有关算法的几个额外数字,公式和单词,人们会逃到下一个帐篷听科幻小说家的话。
我请亚历山大为哈勃(Habr)的演讲做“入门版”的准备,在那儿,没有什么可以吸引随意游客的。 毕竟,大多数演讲缺少听众,他们都提出了一些明智的问题,而且讨论也很不错。 我认为我们可以在这里进行开发。
AI从哪里开始?
从最近开始,我们就一直通过语音与计算机进行通信,各种各样的Alice,Alexa和Siri语音都在回答我们。 如果从侧面看,计算机似乎可以理解我们,给出相关站点列表,报告最近的餐馆地址,并指示如何到达。
看起来我们正在处理一款非常智能的设备。 您甚至可以说该设备具有所谓的人工智能(AI)。 尽管没有人真正了解这意味着什么以及边界在哪里。
当我们被告知“人工智能执行被认为是人类的特权的创新功能”时,这是什么意思? 什么是创意功能? 哪个功能是有创意的,哪个不是? 选择最近的中餐厅是有创意的吗? 现在看来很可能不会。
我们一直倾向于拒绝对计算机使用人工智能。 一旦我们习惯了计算机的智力表现,我们就会说:“这不是AI,这是完全的废话,模板任务,没什么有趣的。”
一个简单的例子-从我们的角度来看,没有什么比袖珍计算器笨拙了。 它可以在任何档位以50卢布的价格出售。 使用通常的八位计算器,按一下按钮,并在几秒钟内得到结果。 好吧,你认为,他认为有些事情。 这不是智力。
想象一下十八世纪的这种机器。 这似乎是一个奇迹,因为计算是人的特权。
计算机语言学也发生同样的事情。 我们倾向于鄙视她的所有成就。 我进入Google查询“普希金的诗句”,他发现一个页面,上面写着“ A.S. 普希金-诗。” 看来这吗? 绝对正常的行为。 但是计算机语言学家不得不花费数十年的时间才能在诗词中找到诗歌一词,在普希金这个词中找到普希金这个词,而在普希金中却找不到这个词。
电脑象棋与机器翻译
计算机语言学是与计算机象棋同时诞生的,而象棋也曾经是人类的特权。 计算机科学的创始人之一克劳德·香农(Claude Shannon)在1950
年写
了一篇文章 ,
介绍如何对计算机编程以下象棋。 据他介绍,我们可以制定两种类型的策略。
A-详尽搜索续集。 有必要在每个阶段测试所有可能的动作。
B-仅对那些被评估为有前途的扩展进行迭代。
很明显,该人使用策略B。宗师很可能仅通过他认为合理的选择,并且在相当短的时间内给出了一个好的举动。
策略A难以实施。 根据Shannon的计算,要计算3个动作,您需要整理出10个
9个选项,并且如果估计位置为1微秒(在20世纪中叶是超级乐观的),则需要17分钟才能做出一个动作。 向前迈出的三步是微不足道的预测深度。
国际象棋的整个后续历史都在于技术的发展,这些技术将使我们不必整理所有内容,而是了解需要整理的内容和不需要的内容。 最终,而且不可逆转,已经战胜了人类。 大约20年前,该计算机绕过了世界象棋冠军,此后才有所改善。
最好的程序被认为是鳕鱼。 去年,AlphaZero与她玩了100场比赛。
| 白人 | 黑色的 | 白色胜利 | 抽奖 | 布莱克的胜利 |
|---|
| 零度 | fish鱼 | 25 | 25 | 0 |
| fish鱼 | 零度 | 0 | 47 | 3 |
AlphaZero是一个人工神经网络,它自身仅下棋了四个小时。 她学会了比之前的所有程序都更好的演奏。
现在,计算机语言学正在发生类似的事情-神经网络建模的浪潮。 他们在上世纪中叶开始与自动翻译同时进行自动国际象棋的工作。 从那以后,发展分为三个阶段。
-基于规则的机器翻译它的设计非常简单-就像在语法课上一样,计算机选择主题,谓语,加法。 他了解将所有这些内容用什么词翻译成另一种语言,并学习如何在其中表达主语,谓语,加法及所有内容。
这种翻译发展了30多年,没有取得太大的成功。
-统计(短语)翻译该计算机依赖于人类翻译文本的大型数据库。 它选择其中与原始单词和短语相对应的单词和短语,将它们收集为目标语言的句子并给出结果。
在互联网上,他们撰写有关下一个“ 20种最愚蠢的机器翻译”的文章-最有可能的是,它与短语翻译有关。 尽管他取得了一些成功。
-神经网络翻译我们将更多地谈论他。 它进入了我们眼前的大规模使用:Google于2016年底启用了神经网络翻译。 对于俄罗斯人来说,它出现在2017年3月。Yandex在2017年底推出了基于神经网络和统计数据的混合系统。
神经网络
神经网络翻译基于以下思想:如果在数学上模拟并复制人脑中神经元的工作,则可以假定计算机将像人一样学习如何使用某种语言。
为此,请看一下人脑中的细胞。
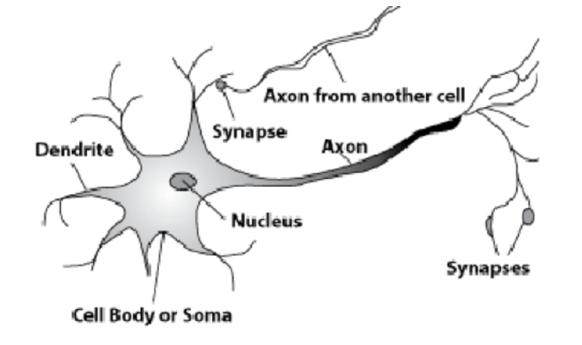
这是自然神经元。 轴突离开了一个漫长的过程,即轴突。 它附着于其他细胞的过程-突触。 根据轴突,有关某些电化学过程的信息被传递到细胞的突触。 每个细胞仅出现一个轴突,许多突触可进入。 信号传播,这就是信息的传输方式。
一些单元连接到外部世界。 它们接收由神经网络进一步处理的信号。
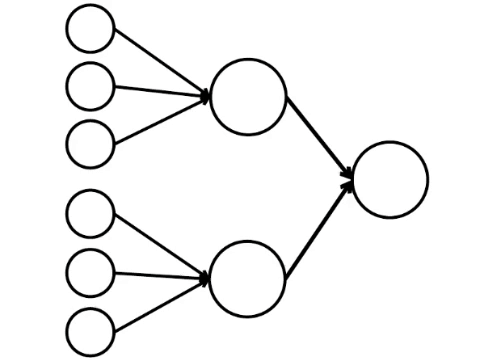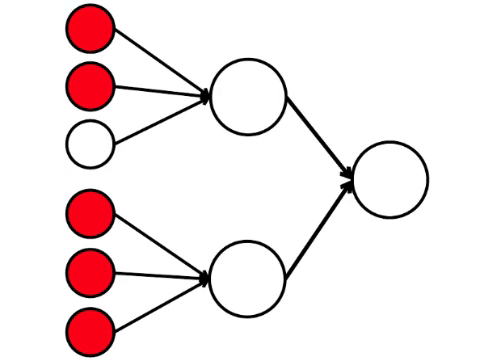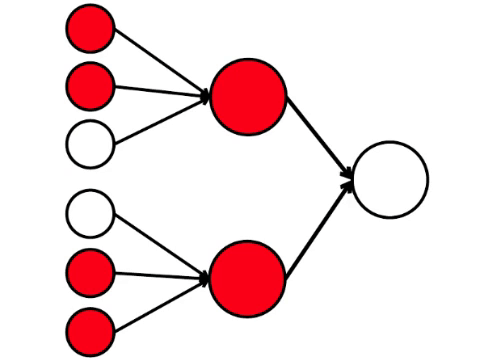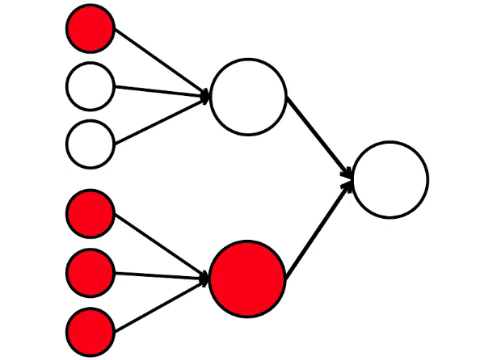
这是我们在这里可以做的最简单的数学模型。 我画了九个相连的圈子。 这些是神经元。

左侧的六个神经元是输入层,它接收来自外部环境的信号。 第二和第三层的神经元不接触环境,而仅与其他神经元接触。 我们引入规则-如果激活的神经元中至少有两个箭头进入神经元,则该神经元也会被激活。
神经网络处理输入端接收到的信号,最终,右侧-输出端-神经元点亮或不点亮。 使用此架构,要激活右神经元,左行至少需要四个激活的神经元。 如果6或5点亮,则肯定会点亮;如果是0到3,则肯定不会点亮。 但是,如果有四个燃烧,则只有均匀分布时才会亮起:上半部分为2,下半部分为2。
事实证明,最简单的九个圆的方案会导致相当多的争论。
人工神经网络的工作方式几乎相同,但通常不会使用“点亮/未点亮”(即1或0)之类的简单事物,而是使用实数。
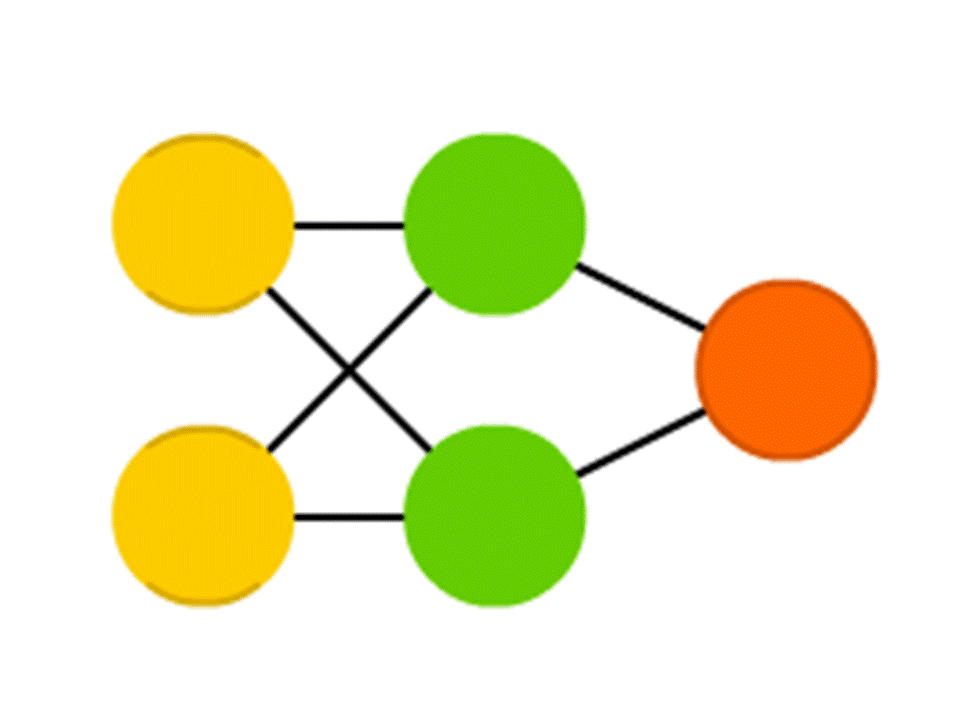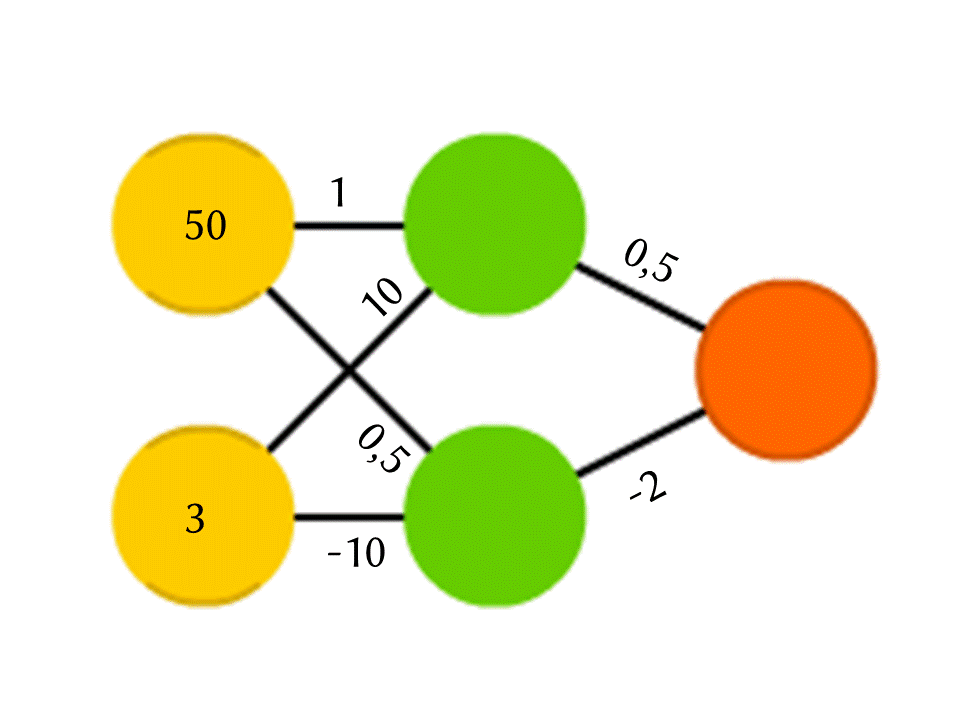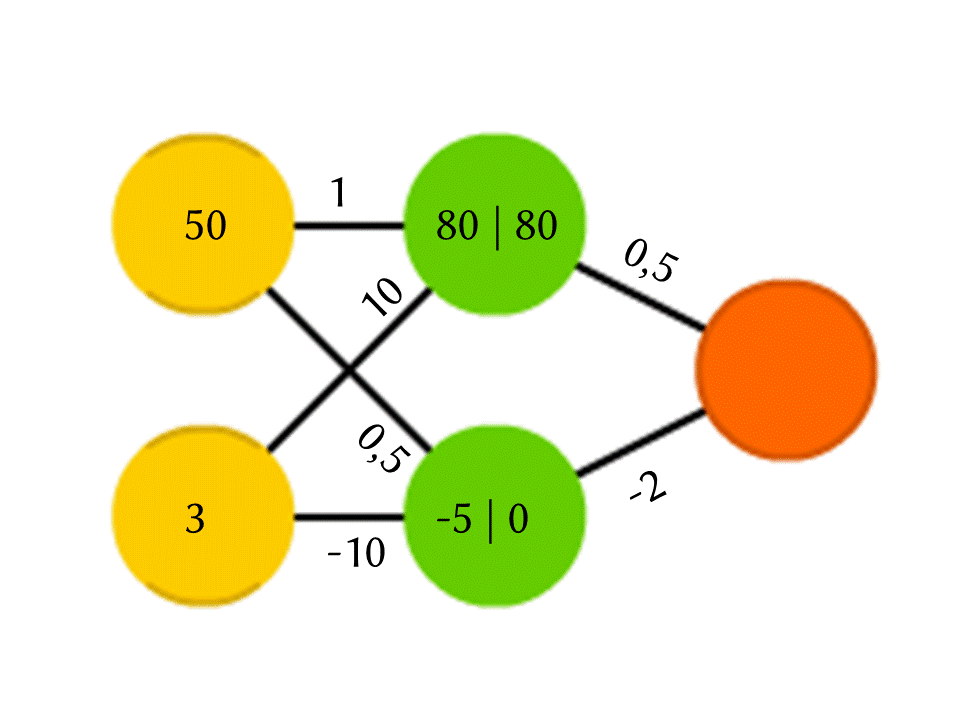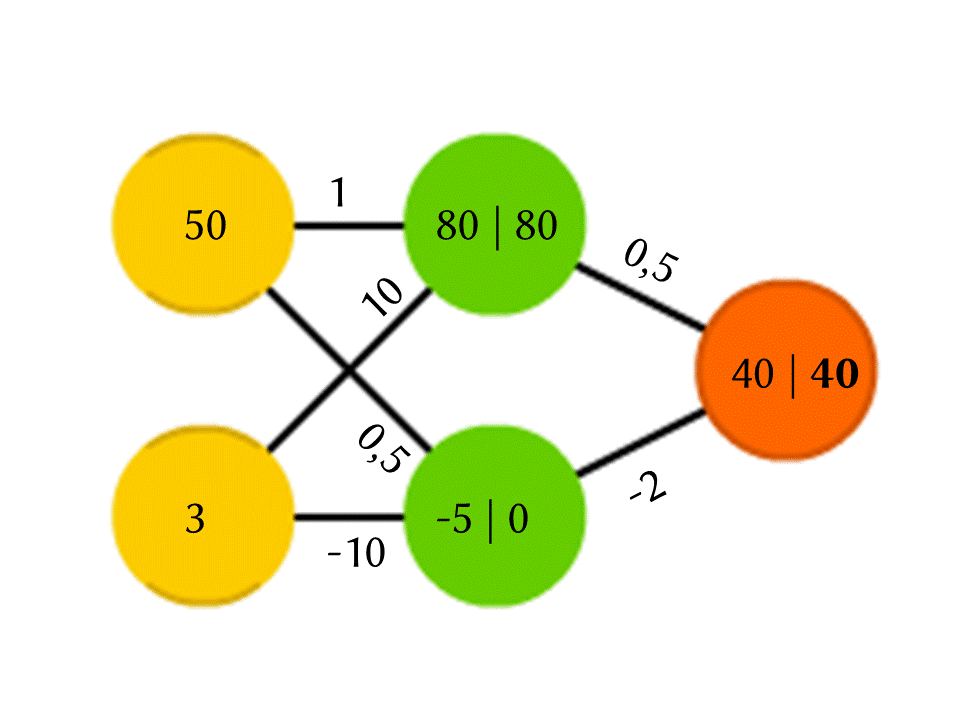
例如,由5个神经元组成的网络-两个在输入层,两个在中间(隐藏),一个在输出。 在相邻层的所有神经元之间,存在分配了权重的连接。 为了找出在一个空的神经元中发生的事情,让我们做一个非常简单的事情:让我们看一下是什么连接导致的,将每个连接的权重乘以该连接来自的上一层神经元中写入的数字,然后我们将所有这些相加。 在该图的上方绿色神经元中,获得50×1 + 3×10 = 80,而在下方-50×0.5-3×10 = -5。
没错,如果您只是这样做,那么输出将仅仅是计算输入值的线性函数的结果(在我们的示例中,将得出25 Y-0.5 X,其中X是上部黄色神经元中的数字,Y是下部神经元中的数字),因此我们同意神经元内部正在发生其他事情。 最简单且同时提供良好结果的功能是ReLU(整流线性单位):如果在神经元中获得负数,则输出0,如果非负数,则输出不变。
因此,在我们的方案中,下部绿色神经元出口处的-5变为0,并且此数字用于进一步的计算。 当然,实际中使用的真实神经网络的体系结构比我们的玩具示例要复杂得多,权重不是从天花板上取下来的,而是通过训练来选择的,但是原理本身很重要。
这和语言有什么关系?
最直接的条件是,我们以数字形式表示语言。 我们对每个单词进行编码,并遇到这样的神经网络。
这里是计算机语言学的一个非常重要的成就,它的出现是在50年前的思想方面,而在实现方面,最近10年一直在积极发展:单词的矢量表示。
 这和接下来的两张图片来自Stefan Evert的演讲
这和接下来的两张图片来自Stefan Evert的演讲这是基于非常简单的考虑,将单词表示为数字数组。 为了找出单词的含义,我们不查看字典,而是查看大量文本,然后考虑更常见的单词。
例如,您知道消声器吗? 如果不是这样,请尝试通过查看单词含糊不清的文字来猜测。
-黑色外套和白色帽子。 好吧,还有一些必不可少的消声器...
在他旁边是衣物,外套和帽子,还可能是其中的围巾。 它几乎不是食物,几乎不是建筑元素。
-由于某种原因,在闷热的夜晚,他的脖子上洒了一条旧的条纹消声器。
在脖子上-这意味着它们不是袜子。 您可以抓住它-显然,它是柔性的,是用织物制成的,而不是用木头或石头制成的。
-一条湿的库特西华夫饼干毛巾Nerzhin像围巾一样垂在脖子上。
我们补充和补充大量示例,看着它们,我们将逐渐了解被遮盖的内容-像围巾。 计算机执行完全相同的操作,即查看文本并执行简单的操作-它捕获附近的单词。
这是埃及象形文字。
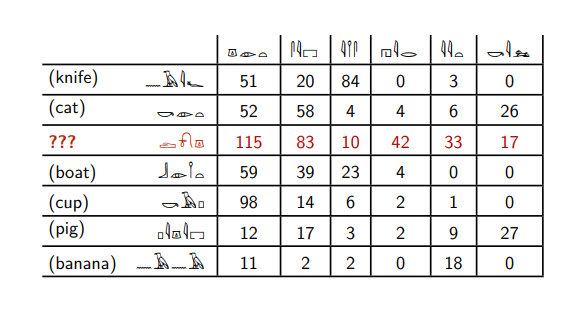
假设您知道其中六个的含义,并且想了解以红色突出显示哪种单词。 这张桌子说这些单词在其他埃及象形文字旁边被发现了多少次。
红色词与第六个词并存-就像
猫和
猪 。 他没有其他话发生。
与
刀和
香蕉一词相反,在第二个单词中发现红色单词的频率要比第三个单词高。
猫,船,猪和
杯子这两个词的行为相同。
基于这种推理,我们可以说红色单词与
猫和
猪单词最相似-只有它们与第六个单词相遇,第二个和第三个单词的比率相似。
而且我们不会弄错,因为红色的单词是
dog一词。

实际上,这些不是埃及象形文字,而是英语名词和动词,对于这些名词和动词,它们在大量英语文本中共同出现了多少次。 第六个词是动词
kill 。
通常在
kill一词的右边找到
cat,dog和
pig 。 刀,船和香蕉很少被杀死。 尽管用俄语,如果您愿意,您可以说“我杀了我的船”,但这是一件罕见的事情。
计算机在处理文本时的确切功能。 他只是相信自己会遇到一些东西,而不再是理解的杰作。
此外,计算机以一组特定的数字形式显示单词:在上面的示例中,单词
dog对应于数字(115; 83; 10; 42; 33; 17)。 实际上,我们必须计算它出现的次数不是用六个单词,而是用文本中的所有单词来计算的:如果我们都拥有100,000个不同的单词,那么我们将
dog单词与一个100,000个数字数组相关联。 在实践中这不是很方便,因此,通常使用减小维度的方法将每个单词的结果转换为长度为数百个元素的数组(有关更多信息,请参见
此处 )。
有现成的用于编程语言的库可让您执行此操作:例如
gensim for Python。 通过向它提交大约一百万个单词的
布朗英语语料库 ,我可以在几秒钟内建立一个模型,其中
猫这个词看起来像这样:

我们代表一种动物,它的头发,尾巴,猫叫声。 我教英语的计算机以
猫旁边的一百个数字的形式表示
猫这个词。
这是
RusVectōres网站上的俄语材料示例。 我拿了
raven一词,并要求计算机告诉我哪些单词与它最相似-换句话说,就是与该单词
raven最为相似的一组数字。

每10个单词中就有8个是鸟名。 一无所知,计算机产生了出色的结果-我意识到鸟类看起来像乌鸦。 但是,炽热和ruchenka这两个词是从哪里来的呢?
你可以猜在这三个词中,白色一词经常被用完:在白色手柄下,白乌鸦变成白热。
接收数字数组并将其传递给自己,神经网络给出了惊人的好结果。 这是安德烈·扎里兹尼亚克院士关于科学在现代世界中的地位的演讲中颇为复杂的哲学文本。 一个月前,一位翻译将其翻译成英文,并且几乎不需要编辑干预。

这就提出了一个全球性的哲学问题
这就是所谓的中国房间的问题-关于人工智能边界的思想实验。 它是由哲学家约翰·塞尔(John Searle)在1980年提出的。
在房间里坐着一个不懂中文的男人。 他得到了指示,他有书,字典和两个窗口。 在一个窗口中,他以中文提供注释,在另一个窗口中,他也以中文给出答案,并且仅根据指示行事。
例如,说明可能会说:“这里有注释,请在字典中找到该字符。 如果是518号象形文字,请在右侧窗口中输入409号象形文字;如果已经到达711号象形文字,则在右侧窗口中输入35号象形文字,依此类推。” 如果房间里的人很好地遵循了这些说明,并且如果这些说明写得很好,那么在街道上做笔记和接收笔记的人就可以认为房间或房间里的人会中文。 毕竟,从外面看不到内部正在发生什么。
大家都知道,这只是一个愚蠢的指示。 他对它们做了一些操作,但一点也不懂中文。 尽管从观察者的角度来看,这是语言的知识。
哲学问题-我们如何与之联系? 房间会说中文吗? 这些说明的作者也许知道中文? 也许不是,因为您可以根据一系列现成的问题和答案发布说明。
另一方面,中国人知道什么? 在这里您会说俄语。 你能做什么? 你脑子里怎么了 某种生化反应。 耳朵或眼睛收到一定的信号,它会引起某种反应,您便会有所了解。 但是“理解”是什么意思? 当您了解时会做什么?
还有一个更复杂的问题-您是否以最佳方式进行此操作? 您使用该语言的工作确实比任何机器都能使用该语言的工作好吗? 您能想象自己会说俄语比任何计算机都差吗? 我们总是将Siri,Alice和我们自己的说话方式进行比较,如果从我们的角度来看他们说话不正确,我们会大笑。 另一方面,您和我给了计算机很多以前认为是人类的特权。 现在,汽车在数数和下象棋方面要好得多,但以前却做不到。 说话的计算机可能也会发生类似的事情:在100年,10年甚至5年中,我们认识到机器已经熟练掌握了该语言,理解得更多,并且总的说来的母语比我们要好得多。
那么一个人被用来通过语言来定义自己的事实又该怎么办呢? 毕竟,他们说只有一个人会说这种语言。 如果我们认识到计算机在该领域的胜利,将会发生什么?
将您的问题留在评论中。 也许稍后,我们可以接受亚历山大的采访。 也许他本人将对我们的邀请发表评论,并与所有感兴趣的人交谈。