 你好 我叫Marco,我在Platform部门的Badoo工作。 我们有很多用Go语言编写的东西,而这些东西通常对系统性能至关重要。 因此,今天我向您提供我真的很喜欢的文章的翻译,我相信它将对您非常有用。 作者逐步展示了他如何解决性能问题以及如何解决它们。 包括您在内,您将熟悉Go中提供的用于此类工作的丰富工具。 祝您阅读愉快!
你好 我叫Marco,我在Platform部门的Badoo工作。 我们有很多用Go语言编写的东西,而这些东西通常对系统性能至关重要。 因此,今天我向您提供我真的很喜欢的文章的翻译,我相信它将对您非常有用。 作者逐步展示了他如何解决性能问题以及如何解决它们。 包括您在内,您将熟悉Go中提供的用于此类工作的丰富工具。 祝您阅读愉快!几周前,我阅读了文章“
Go中的良好代码与不良代码 ”,作者逐步演示了重构可解决实际业务问题的实际应用程序的过程。 它着重于将“不良代码”转变为“良好代码”:更加惯用,更易理解,并充分利用Go的细节。 但是作者还指出了有关应用程序性能的重要性。 好奇心跳进了我:让我们尝试加快速度!
粗略地说,该程序读取输入文件,逐行对其进行解析,然后将对象填充到内存中。
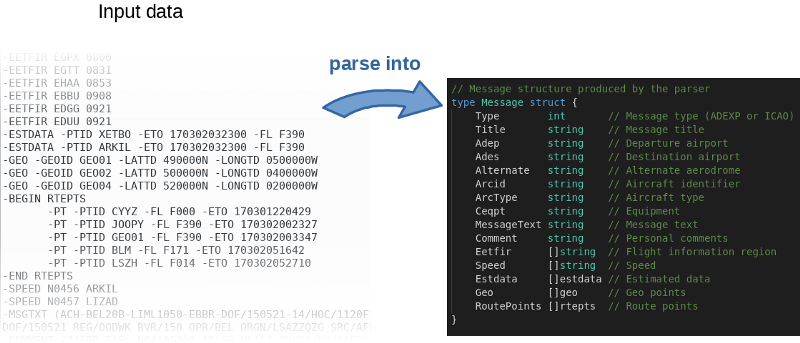
作者不仅
在GitHub上发布了
源代码 ,还编写了一个基准。 这是一个好主意。 实际上,作者邀请所有人一起使用该代码,并尝试对其进行加速。 要重现作者的结果,请使用以下命令:
$ go test -bench=.
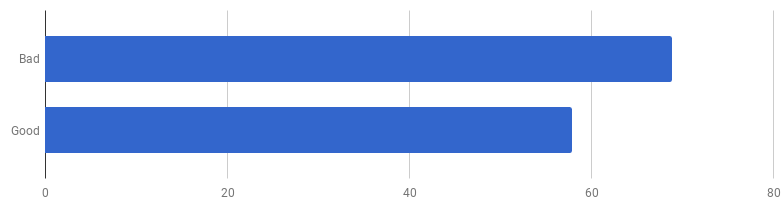 每次通话μs(越少越好)
每次通话μs(越少越好)事实证明,在我的计算机上,“良好代码”的速度提高了16%。 我们可以加快速度吗?
以我的经验,代码质量和性能之间存在关联。 如果您成功地重构了代码,使代码更简洁,连接更少,那么您很有可能会使其变得更快,因为它变得更加混乱(并且不再有以前徒劳地执行的不必要指令)。 也许在重构过程中您注意到了一些优化机会,或者现在您只是有机会进行优化。 但是另一方面,如果您想提高代码的生产力,则可能必须摆脱简单性并添加各种技巧。 您确实节省了几毫秒,但是代码的质量会受到影响:阅读和谈论它会变得更加困难,它将变得更加脆弱和灵活。
 我们爬上朴素的山峰,然后从它下去
我们爬上朴素的山峰,然后从它下去这是一个折衷:您愿意走多远?
为了适当地优先进行加速工作,最佳策略是找到瓶颈并集中精力解决它们。 为此,请使用性能分析工具。
pprof和
trace是您的朋友:
$ go test -bench=. -cpuprofile cpu.prof $ go tool pprof -svg cpu.prof > cpu.svg
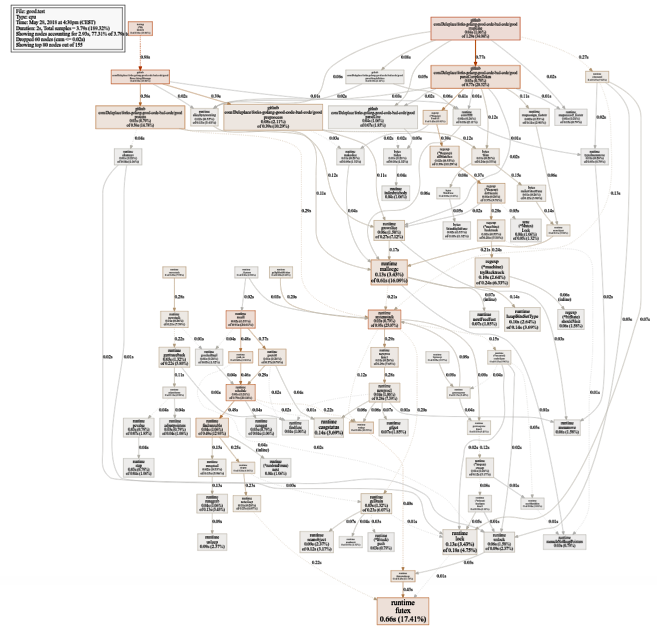 相当大的CPU使用率图表(单击以查看SVG)
相当大的CPU使用率图表(单击以查看SVG) $ go test -bench=. -trace trace.out $ go tool trace trace.out
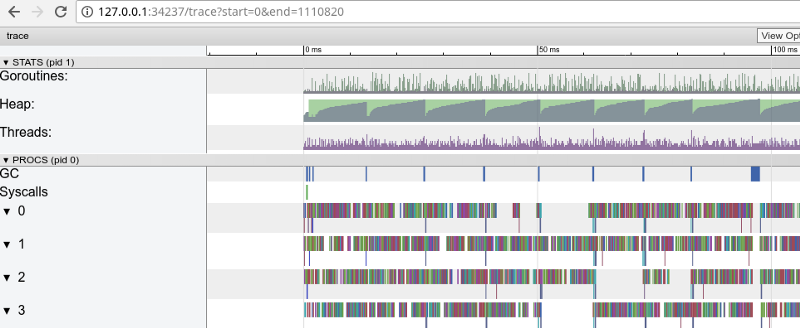 彩虹跟踪:许多小任务(单击以打开,仅在Google Chrome中有效)
彩虹跟踪:许多小任务(单击以打开,仅在Google Chrome中有效)跟踪确认所有处理器内核都处于繁忙状态(0、1以下的行等),乍一看,这很好。 但是她还显示了成千上万个小的颜色“计算”和几个闲置的核心区域。 让我们放大:
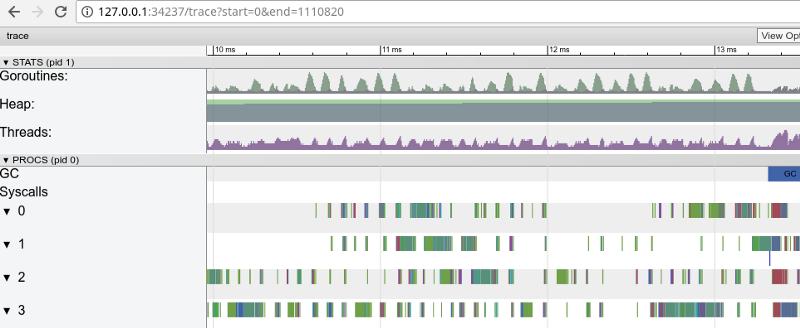 3毫秒内显示“窗口”(单击以打开,仅在Google Chrome中有效)
3毫秒内显示“窗口”(单击以打开,仅在Google Chrome中有效)每个内核都空闲了相当长的一段时间,并且它始终都在微任务之间“跳转”。 这些任务的粒度似乎不是很理想,这导致大量
上下文切换,并且由于同步而导致竞争。
让我们看看
飞行探测器会告诉我们什么。 在同步访问数据时是否有任何问题(如果有的话,那么我们的问题要比性能大得多)?
$ go test -race PASS
太好了! 一切都正确。 找不到航班。 测试函数和基准函数是不同的函数(
请参阅文档 ),但是这里它们调用相同的
ParseAdexpMessage函数,因此我们可以通过测试检查数据传输是否正常。
“好”版本中的竞争模型包括在单独的goroutine中处理输入文件中的每一行(以使用所有内核)。 作者的直觉在这里效果很好,因为goroutine以简单易用的功能而闻名。 但是我们通过并行执行赢了多少钱? 让我们与相同的代码进行比较,但不使用goroutines(只需删除函数调用之前的go词):

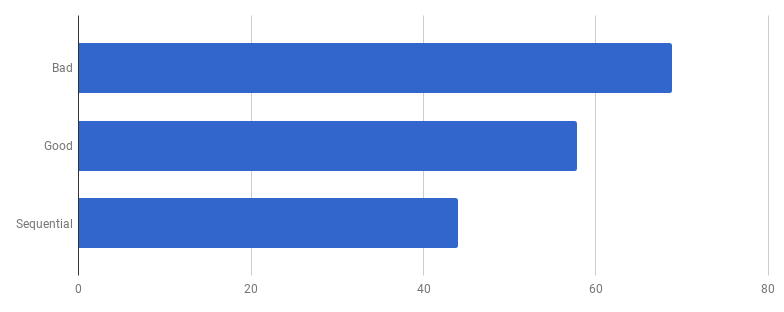
糟糕,似乎在不使用并发的情况下,代码变得更快。 这意味着启动goroutine的(非零)开销超过了我们同时使用多个内核所赢得的时间。 自然而然的下一步应该是消除使用通道发送结果的(非零)开销。 让我们用常规切片替换它:
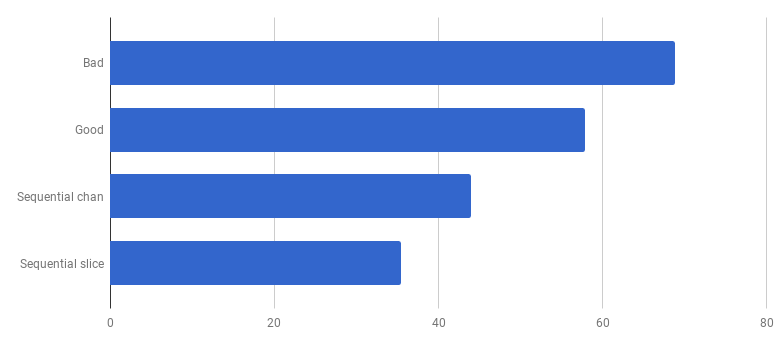 每次通话μs(越少越好)
每次通话μs(越少越好)与“良好”版本相比,我们获得了大约40%的加速,从而简化了代码并消除了竞争(
diff )。
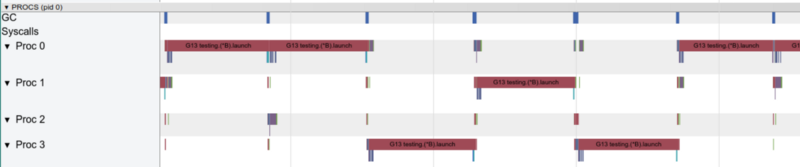 使用一个goroutine,一次只能工作一个核心
使用一个goroutine,一次只能工作一个核心现在让我们看一下pprof图中的热门功能:
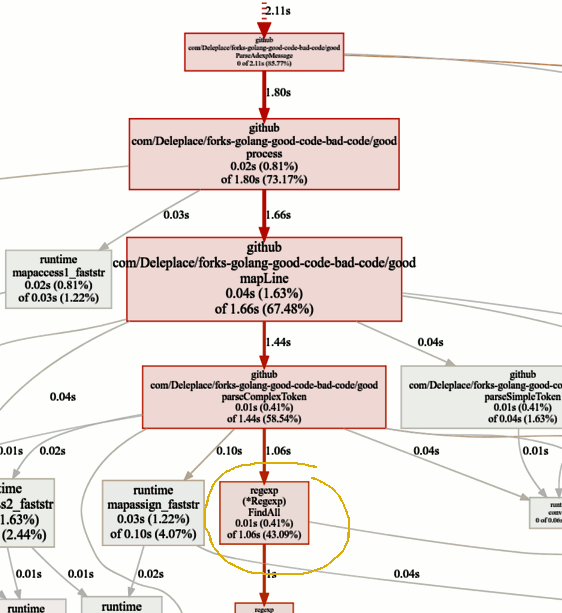 寻找瓶颈
寻找瓶颈当前版本的基准测试(顺序操作,片)花费了86%的时间来解析消息,这是正常的。 但是我们很快就会注意到,有43%的时间花在使用正则表达式和函数
(* Regexp).FindAll上 。
尽管正则表达式是从纯文本获取数据的方便且灵活的方式,但它们仍存在缺点,包括使用大量资源,处理器和内存。 它们是强大的工具,但通常不需要使用它们。
在我们的程序中,有一个模板
patternSubfield = "-.[^-]*"
它主要用于突出显示以连字符(-)开头的命令,并且该行中可以有多个。 只需编写一些代码,就可以使用
bytes.Split完成此操作。 让我们修改代码(
commit ,
commit )以将正则表达式更改为Split:
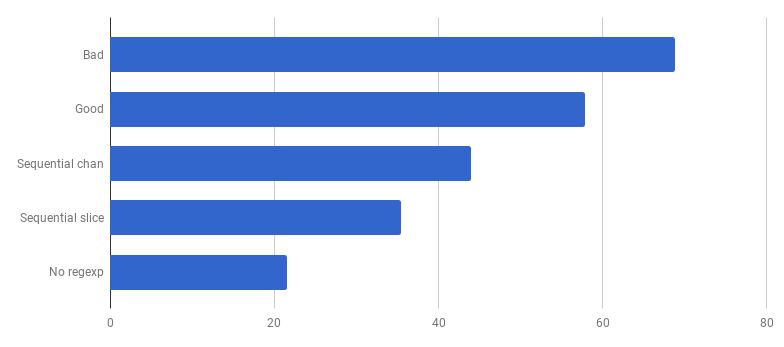 每次通话μs( 越少越好)
每次通话μs( 越少越好)哇! 生产代码提高40%! 现在,CPU消耗图如下所示:
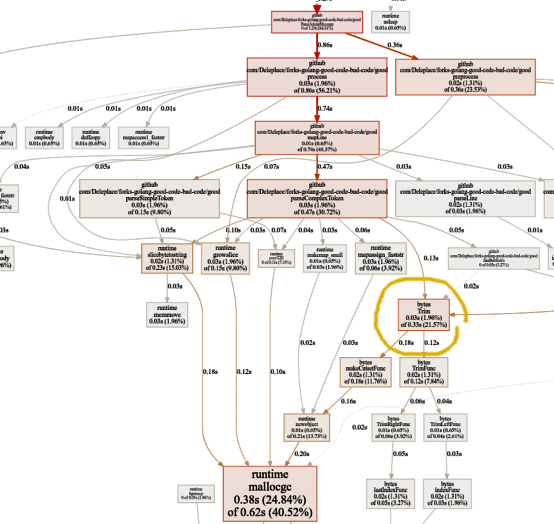
正则表达式不再浪费时间。 其中很大一部分(40%)用于五个不同功能的内存分配。 有趣的是,现在21%的时间都花在了
字节上
.Trim函数:
 此功能令我着迷。 我们在这里可以做什么?
此功能令我着迷。 我们在这里可以做什么?
bytes.Trim需要一个带有“截断”字符的字符串作为参数,但是作为该字符串,我们传递的字符串只有一个字符-一个空格。 这只是由于复杂性如何获得加速度的一个示例:让我们创建修剪函数而不是标准函数。 我们的自定义
修整函数将使用单个字节而不是整个行:

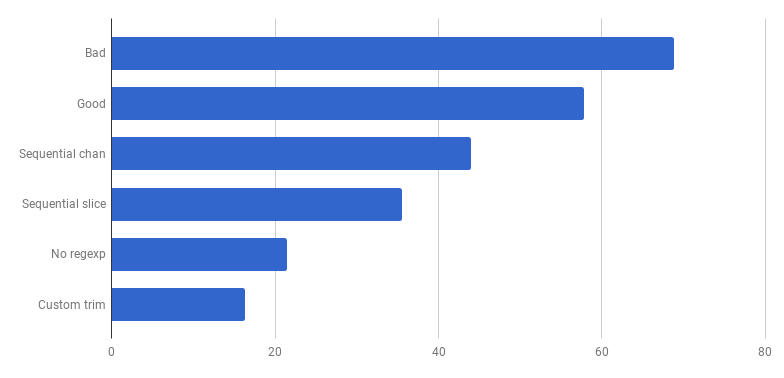 每次通话μs(越少越好)
每次通话μs(越少越好)万岁,又有20%的损失! 当前版本比原来的“坏”版本快四倍,同时仅使用一个内核。 还不错!
早些时候,我们放弃了在线处理水平上的竞争力,但我认为可以通过更高水平的竞争力来实现加速。 例如,如果每个文件都在自己的goroutine中进行处理,则在我的计算机上处理6,000个文件(6,000条消息)的速度更快:
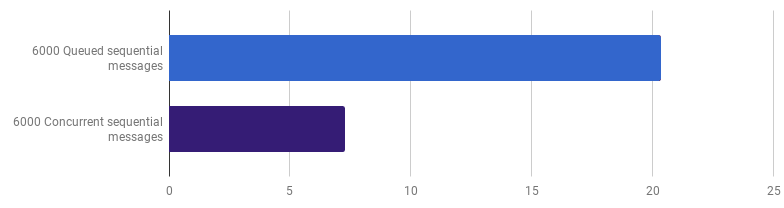 每次通话μs(越少越好;紫色是一种有竞争力的解决方案)
每次通话μs(越少越好;紫色是一种有竞争力的解决方案)增益为66%(即加速三倍)。 考虑到我使用的所有12个处理器内核都很好,但这不是很好。 这可能意味着处理整个文件的新的优化代码仍然是“小任务”,为此,创建goroutine的开销和同步的成本并不微不足道。 有趣的是,将消息数量从6,000增加到120,000对单线程版本没有任何影响,并且降低了“每条消息一个goroutine”版本的性能。 这是因为,尽管事实是有可能创建并且有时有用的大量goroutine,但它却在运行时
Sheduler领域带来了自己的开销。
通过创建几个工作线程,我们可以进一步减少执行时间(不是减少12倍,而是仍然)。 例如,12个长寿的goroutines,每个goroutines将处理部分消息:
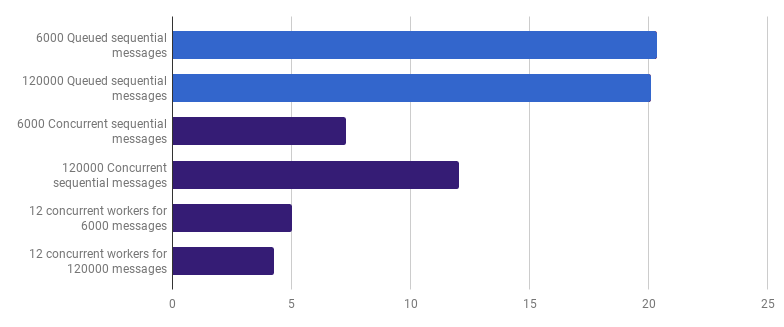 每次通话μs(越少越好;紫色是一种有竞争力的解决方案)
每次通话μs(越少越好;紫色是一种有竞争力的解决方案)与单线程版本相比,此选项将执行时间减少了79%。 请注意,仅当您要处理许多文件时,此策略才有意义。
所有处理器内核的最佳使用方式是使用多个goroutine,每个goroutine在完成工作之前都可以处理大量数据,而无需任何交互或同步。
通常,它们采用与处理器核心一样多的进程(goroutine),但这并不总是最好的选择:这全都取决于特定的任务。 例如,如果您正在从文件系统中读取内容或进行大量网络调用,则为了获得更高的性能,应使用比核心更多的goroutine。
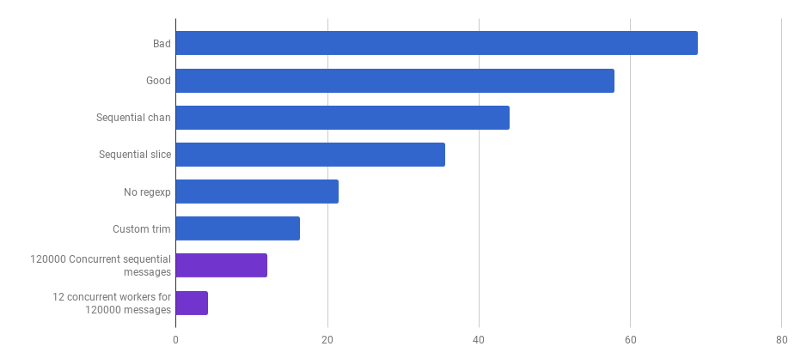 每次通话μs(越少越好;紫色是一种有竞争力的解决方案)
每次通话μs(越少越好;紫色是一种有竞争力的解决方案)我们已经到了这样的地步,随着局部化的变化,解析性能很难提高。 运行时受内存分配和垃圾回收的时间支配。 这听起来合乎逻辑,因为内存管理功能相当慢。 与分配相关联的流程的进一步优化仍然是读者的一项家庭作业。
使用其他算法也会导致很大的性能提升。
在这里,我受到了Rob Pike的Lexical Scanning in Go演讲的启发,
创建一个自定义词法分析器(
source )和一个自定义解析器(
source )。 该代码尚未准备好(我不处理很多极端情况),它比原始算法不清楚,有时很难编写正确的错误处理。 但是它很小,比最优化的版本快30%。
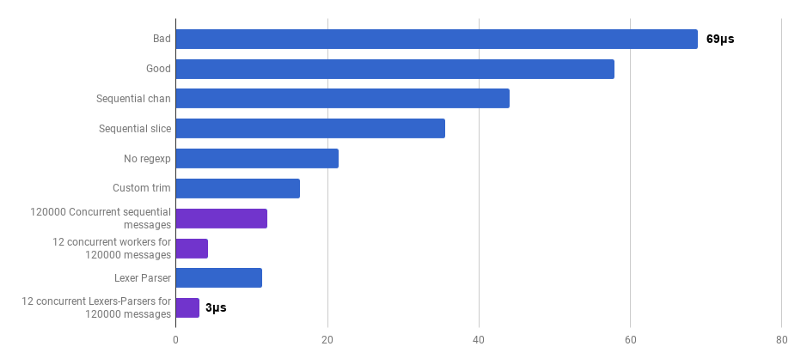 每次通话μs(越少越好;紫色是一种有竞争力的解决方案)
每次通话μs(越少越好;紫色是一种有竞争力的解决方案)是的 结果,与源代码相比,我们获得了23倍的加速。
今天就这些了。 希望您喜欢这次冒险。 以下是一些注释和结论:
- 使用不同的技术,可以在各种抽象级别上提高生产力,并且通常会增加收益。
- 调优需要从高级抽象开始:数据结构,算法,模块的正确去耦。 稍后处理低层抽象:I / O,批处理,竞争力,使用标准库,处理内存,分配内存。
- 大O分析非常重要,但通常不是最适合用来加速程序的工具。
- 编写基准是艰苦的工作。 使用性能分析和基准测试来查找瓶颈并获得对该程序中正在发生的事情的更广泛的了解。 请记住,基准测试结果与您的用户在实际工作中会遇到的结果不同。
- 幸运的是,一套工具( Bench , pprof , trace , Race Detector , Cover )使对代码性能的研究既经济又有趣。
- 编写良好且相关的测试并非易事。 但是他们非常重要,不要野蛮。 您可以重构代码,确保代码正确无误。
- 停下来,问问自己“足够快”有多快。 不要浪费时间优化一些一次性脚本。 不要忘记优化不是免费的:工程师的时间,复杂性,错误和技术负担。
- 在使代码复杂化之前,请三思。
- 复杂度为Ω (n²)及以上的算法通常过于昂贵。
- 复杂度为O(n)或O(n log n)及以下的算法通常是可以的。
- 各种隐藏因素不容忽视。 例如,本文中的所有改进都是通过减少这些因素而不是通过更改算法的复杂性类别来进行的。
- I / O通常是一个瓶颈:网络查询,数据库查询,文件系统。
- 正则表达式通常过于昂贵且不必要。
- 内存分配比计算昂贵。
- 分配在堆栈上的对象比分配在堆上的对象便宜。
- 切片可用作替代昂贵的内存移动的替代方法。
- 字符串在只读(包括重新分片)时有效。 在所有其他情况下,[]字节更有效。
- 处理的数据必须靠近(处理器缓存),这一点非常重要。
- 竞争力和并行性非常有用,但很难准备。
- 当您深入研究时,请记住您不想闯入Go的“玻璃地板”。 如果您不愿尝试汇编程序指令(SIMD指令),则可能只需要使用Go进行原型制作,然后切换到较低级别的语言即可完全控制硬件,每纳秒!