插入排序的一般本质如下:
- 遍历数组未排序部分中的元素。
- 每个元素都应在应放置的位置插入数组的排序部分。
原则上,这就是您需要了解的有关按插入排序的全部信息。 也就是说,插入排序始终将数组分为两部分-排序和未排序。 从未排序的部分检索任何项目。 由于数组的另一部分已排序,因此您可以快速为此提取的元素在此数组中找到您的位置。 必要时将元素插入,结果是数组的排序部分增加,而未排序部分减少。 仅此而已。 各种插入件均以此原理工作。
这种方法的最弱点是将元素插入数组的排序部分。 实际上,这并不容易,完成该步骤无需您花什么技巧。
简单的插入排序

我们从左到右遍历数组,然后依次处理每个元素。 在下一个元素的左侧,随着过程的进行,我们增加了数组的排序部分,在右侧,增加了未排序部分的缓慢蒸发。 在数组的排序部分中,搜索下一个元素的插入点。 元素本身被发送到缓冲区,结果是一个空单元格出现在数组中-这使您可以移动元素并释放插入点。
def insertion(data): for i in range(len(data)): j = i - 1 key = data[i] while data[j] > key and j >= 0: data[j + 1] = data[j] j -= 1 data[j + 1] = key return data
以简单的插入为例,大多数(但不是全部!)按插入进行排序的主要优势都具有示范性,即对几乎有序数组的快速处理:

在这种情况下,即使是最原始的排序插入实现,也可能会在某些快速排序上(包括在大型数组上)超过超优化算法。
此类的主要思想使此操作变得容易-将元素从数组的未排序部分转移到已排序部分。 当相似大小的数据非常接近时,插入点通常位于已排序部分的边缘附近,这使您可以以最小的开销进行插入。
没有什么比插入排序更好地处理几乎有序的数组了。 当您在某个地方遇到信息时,按插入进行排序的最佳时间复杂度是
O( n ) ,那么您很可能是指具有几乎有序数组的情况。
按简单的二进制搜索插入排序

由于插入位置是在数组的排序部分中搜索的,因此使用二进制搜索的想法很明显。 另一件事是,对插入位置的搜索对于算法的时间复杂度不是至关重要的(主要的资源消耗者是将元素插入到找到的位置本身的阶段),因此此优化几乎没有作用。
在几乎排序的数组的情况下,二进制搜索可能会更慢,因为它从已排序部分的中间开始,这很可能会离插入点太远(并且如果数据存在,从元素位置到插入点执行常规搜索的步骤将更少在整个数组中排序)。
def insertion_binary(data): for i in range(len(data)): key = data[i] lo, hi = 0, i - 1 while lo < hi: mid = lo + (hi - lo) // 2 if key < data[mid]: hi = mid else: lo = mid + 1 for j in range(i, lo + 1, -1): data[j] = data[j - 1] data[lo] = key return data
为了辩护二进制搜索,我注意到他可以说其他单词通过插入进行排序的有效性中的最后一个单词。 特别是由于他,诸如图书管理员排序和纸牌排序之类的算法达到了平均时间复杂度
O( n log n ) 。 但是稍后。
通过简单插入对进行排序
简单插入的修改,由Oracle Corporation的秘密实验室开发。 这种排序是JDK的一部分,也是Dual-Pivot Quicksort的一部分。 它用于对小数组(最多47个元素)进行排序,并对大数组的小区域进行排序。

不会立即将两个相邻元素发送到缓冲区。 首先,插入该对中较大的元素,然后紧接着将简单的插入方法应用于该对中较小的元素。
它有什么作用? 节省处理一对较小物品的费用。 对他而言,仅在数组的排序部分上执行对插入点和插入本身的搜索,该部分不包括用于处理该对中较大元素的排序区域。 这之所以成为可能,是因为在外循环的一次遍历中,一个又一个立即处理较大和较小的元素。
这不会影响平均时间复杂度(它仍然保持等于
O( n 2 )),但是,成对的插入要比普通插入快一点。
我举例说明了Python中的算法,但在这里给出了Java的原始源(为了可读性而修改):
for (int k = left; ++left <= right; k = ++left) {
贝壳排序

该算法在确定阵列的哪一部分被视为已排序方面具有非常机智的方法。 在简单插入中,所有内容都很简单:从当前元素开始,左侧的所有内容都已排序,右侧的所有内容尚未排序。 与简单插入不同,Shell排序不会尝试立即在元素左侧形成数组的严格排序部分。 它在元素左侧创建数组的
几乎排序的部分,并且足够快地完成它。
Shell排序将当前元素扔到缓冲区中,并将其与数组的左侧进行比较。 如果在左侧找到较大的元素,则会将其向右移动,为插入留出空间。 但是同时,它并不占据整个左侧部分,而只是占据其中的一部分元素,这些元素之间彼此隔开一定的距离。 这样的系统使您可以将元素快速插入到应放置元素的数组区域中。
随着主循环的每次迭代,此距离逐渐减小,并且当它等于1时,此时Shell排序将变成具有简单插入的经典排序,并提供给几乎已排序的数组处理。 几乎排序的数组排序可快速插入到完全排序的转换中。
def shell(data): inc = len(data) // 2 while inc: for i, el in enumerate(data): while i >= inc and data[i - inc] > el: data[i] = data[i - inc] i -= inc data[i] = el inc = 1 if inc == 2 else int(inc * 5.0 / 11) return data
按照类似原理进行梳状排序可改善气泡排序,因此
O( n 2 )的算法的时间复杂度立即上升到
O( n log n ) 。 Shell,壳牌没有设法重复这一壮举-最佳时间复杂度达到
O( n log 2 n ) 。
关于分类Shell的文章已经写了好几篇,所以我们不会因信息过多而继续前进。
树分类
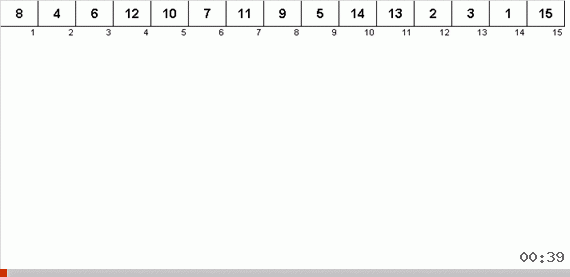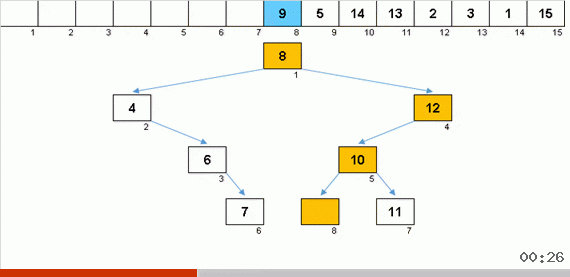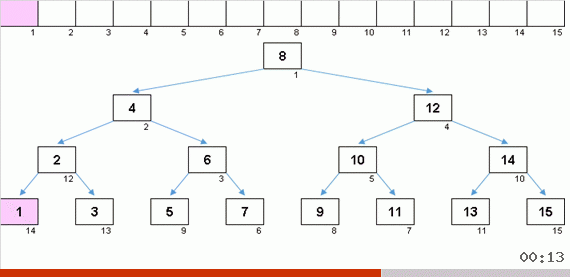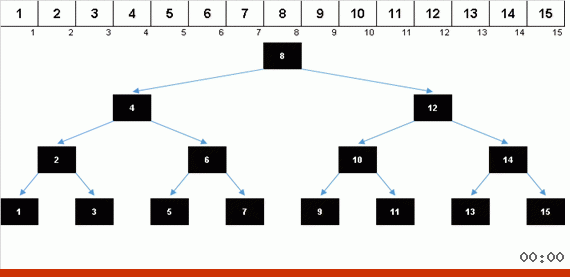
由于增加了内存,使用树进行排序可以快速解决将另一个元素添加到数组的排序部分的问题。 此外,二叉树充当数组的排序部分。 遍历元素时,实际上是在动态地形成一棵树。
首先将元素与根进行比较,然后根据以下原理将其与更多的嵌套节点进行比较:如果元素小于节点,则我们沿着左边的分支向下移动,如果不小于,则沿着右边的分支。 然后可以轻松地规避通过这样的规则构造的树,以便从具有较低值的节点移动到具有较大值的节点(从而使所有元素按升序排列)。
此处解决了通过插入进行排序的主要障碍(将元素插入到数组排序部分中的位置中的成本),构造工作非常迅速。 无论如何,要释放插入点,就不必像先前的算法那样缓慢移动元素的商队。 看来这里是最好的分类插入。 但是有一个问题。
如上面的动画三段所示,当您获得一棵美丽的对称圣诞树(所谓的完美平衡树)时,插入会很快发生,因为在这种情况下,该树的嵌套级别最低。 但是很少从随机数组中获得平衡的(或至少接近该结构)结构。 而且这棵树很可能会是不完美且不平衡的-会出现扭曲,地平线上乱七八糟和水平过多的情况。
值从1到10的随机数组。按此顺序的元素将生成不平衡的二叉树: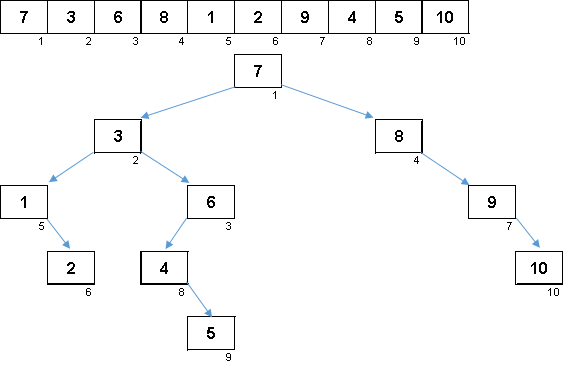
一棵树不足以建造,它仍然需要被规避。 失衡越多-树遍历算法越容易滑动。 正如星星所说,随机阵列既可以产生丑陋的障碍(更有可能),又可以产生树状的分形。
元素的值相同,但是顺序不同。 生成一个平衡的二叉树: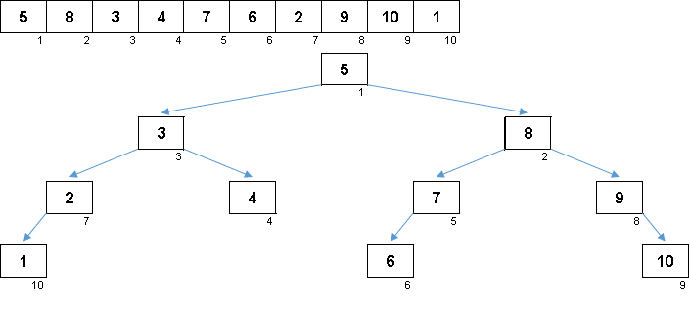
 在美丽的樱花上
在美丽的樱花上
花瓣不足:
一棵几十个的二叉树。不平衡树的问题通过倒排排序解决,倒排排序使用一种特殊的二叉搜索树-展开树。 这是一棵奇妙的变压器树,它在每次操作后都以平衡状态重建。 关于它,将另作文章。 到那时,我将为Tree Sort和Splay sort准备Python实现。
好吧,好吧,我们简要地介绍了最受欢迎的排序插件。 我们都从学校知道简单的插入,shell和二叉树。 现在考虑这个类别的其他代表,但没有那么广为人知。
Wiki / Wiki- 插入 , Shell / Shell , 树 / 树系列文章:
谁使用AlgoLab-我建议更新文件。 我向该应用程序添加了简单的二进制搜索插入和成对插入。 他还完全重写了Shell的可视化效果(在以前的版本中没有什么需要理解的),并且在将元素插入二叉树时向父分支添加了突出显示。