你好 在本文中,我将讨论作为过滤垃圾邮件的选项之一的贝叶斯分类器。 让我们仔细研究一下理论,然后通过实践加以修正,最后,我将以我心爱的语言R给出代码草图。我将尝试使用表达式和公式尽可能地轻描淡写。 让我们开始吧!

到处都没有公式,好吧,简要的理论
贝叶斯分类器属于机器学习的类别。 底线是这样的:面对确定下一个字母是否为垃圾邮件的系统,已经预先通过一定数量的字母进行培训,这些字母准确地知道“垃圾邮件”的位置和“非垃圾邮件”的位置。 已经很清楚,这是在与老师一起教学,我们在其中扮演老师的角色。 贝叶斯分类器以一组词的形式呈现一个文档(在我们的例子中是一个字母),这些词据称彼此不依赖(这很幼稚)。
有必要计算每个类别(垃圾邮件/非垃圾邮件)的等级,然后选择最高等级。 为此,请使用以下公式:
-单词出现
进入课堂文件
(带有平滑)*
-课程文件中包含的单词数
M-训练集中的单词数
-单词出现的次数
进入课堂文件
-平滑参数
当文本的体积很大时,您必须使用非常小的数字。 为了避免这种情况,您可以根据对数属性**转换公式:
替代并获得:
*在计算过程中,您可能会遇到一个不在训练系统阶段的单词。 这可能导致评估等于零,并且文档无法分配到任何类别(垃圾邮件/非垃圾邮件)。 无论如何,都不会教您系统所有可能的单词。 为此,有必要进行平滑处理,或者更确切地说,是对单词进入文档的所有概率进行小的校正。 选择参数0 <α≤1(如果α= 1,则为拉普拉斯平滑)
**对数是单调递增的函数。 从第一个公式可以看出-我们正在寻找最大值。 函数的对数将在与函数本身相同的点(横坐标)达到峰值。 因为只改变数值,所以简化了计算。
从理论到实践
让我们的系统从以下字母中学习,这些字母预先称为“垃圾邮件”和“非垃圾邮件”(培训样本):
垃圾邮件- “低价券”
- “促销! 购买巧克力棒并获得电话作为礼物»
不是垃圾邮件:- “会议将于明天举行”
- “买一公斤苹果和一块巧克力棒”
作业:确定以下字母属于哪个类别:
解决方案:我们做一张桌子。 我们删除所有“停用词”,计算概率,将要平滑的参数作为一个。
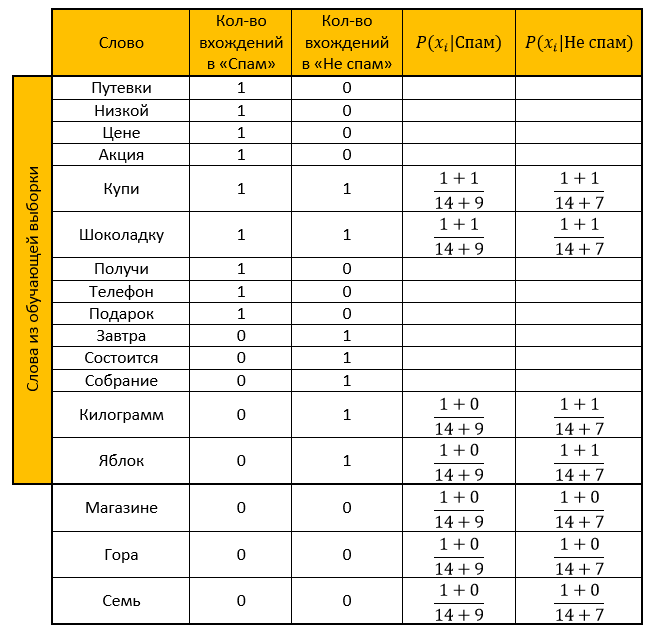
垃圾邮件类别的评分:
“非垃圾邮件”类别的评分:
答: “非垃圾邮件”等级大于“垃圾邮件”等级。 因此验证邮件不是垃圾邮件!
我们借助对数属性转换的函数来计算出相同的值:
垃圾邮件类别的评分:
“非垃圾邮件”类别的评分:
答案:与之前的答案相似。 验证电子邮件-没有垃圾邮件!
编程语言实现R
他评论了几乎所有操作,因为我知道我不想多久理解别人的代码,所以我希望阅读我的文章不会给您带来任何困难。 (哦,我多么希望)
实际上,代码本身library("tm") # stopwords library("stringr") # # : spam <- c( ' ', '! ' ) # : not_spam <- c( ' ', ' ' ) # test_letter <- " . " #---------------- -------------------- # spam <- str_replace_all(spam, "[[:punct:]]", "") # spam <- tolower(spam) # spam_words <- unlist(strsplit(spam, " ")) # , stopwords spam_words <- spam_words[! spam_words %in% stopwords("ru")] # unique_words <- table(spam_words) # data frame main_table <- data.frame(u_words=unique_words) # names(main_table) <- c("","") #--------------- ------------------ not_spam <- str_replace_all(not_spam, "[[:punct:]]", "") not_spam <- tolower(not_spam) not_spam_words <- unlist(strsplit(not_spam, " ")) not_spam_words <- not_spam_words[! not_spam_words %in% stopwords("ru")] #--------------- ------------------ test_letter <- str_replace_all(test_letter, "[[:punct:]]", "") test_letter <- tolower(test_letter) test_letter <- unlist(strsplit(test_letter, " ")) test_letter <- test_letter[! test_letter %in% stopwords("ru")] #--------------------------------------------- # main_table$_ <- 0 for(i in 1:length(not_spam_words)){ # need_word <- TRUE for(j in 1:(nrow(main_table))){ # " " , +1 if(not_spam_words[i]==main_table[j,1]) { main_table$_[j] <- main_table$_[j]+1 need_word <- FALSE } } # , data frame if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=not_spam_words[i],=0,_=1)) } } #------------- # , - main_table$_ <- NA # , - main_table$__ <- NA #------------- # Xi Qk formula_1 <- function(N_ik,M,N_k) { (1+N_ik)/(M+N_k) } #------------- # quantity <- nrow(main_table) for(i in 1:length(test_letter)) { # , need_word <- TRUE for(j in 1:nrow(main_table)) { # if(test_letter[i]==main_table$[j]) { main_table$_[j] <- formula_1(main_table$[j],quantity,sum(main_table$)) main_table$__[j] <- formula_1(main_table$_[j],quantity,sum(main_table$_)) need_word <- FALSE } } # , data frame, / if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=test_letter[i],=0,_=0,_=NA,__=NA)) main_table$_[nrow(main_table)] <- formula_1(main_table$[nrow(main_table)],quantity,sum(main_table$)) main_table$__[nrow(main_table)] <- formula_1(main_table$_[nrow(main_table)],quantity,sum(main_table$_)) } } # "" probability_spam <- 1 # " " probability_not_spam <- 1 for(i in 1:nrow(main_table)) { if(!is.na(main_table$_[i])) { # 1.1 , - probability_spam <- probability_spam * main_table$_[i] } if(!is.na(main_table$__[i])) { # 1.2 , - probability_not_spam <- probability_not_spam * main_table$__[i] } } # 2.1 , - probability_spam <- (length(spam)/(length(spam)+length(not_spam)))*probability_spam # 2.2 , - probability_not_spam <- (length(not_spam)/(length(spam)+length(not_spam)))*probability_not_spam # - ifelse(probability_spam>probability_not_spam," - !"," - !")
非常感谢您抽出宝贵的时间阅读我的文章。 我希望您为自己学到了一些新知识,或者只是希望您了解一些不清楚的时刻。 祝你好运
资料来源:- 关于朴素贝叶斯分类器的一篇很好的文章
- 从Wiki派生的知识: 此处 , 此处和此处
- 关于数据挖掘的讲座Chubukova I.A.