你好 以下是6月20日在圣彼得堡的Apache Ignite社区集会上的演讲视频的转录本。 您可以在此处下载幻灯片。
新手用户会遇到一整类问题。 他们只是下载了Apache Ignite,运行了前两,三,十次,然后向我们提出了以类似方式解决的问题。 因此,我建议创建一个清单,以在您制作第一个Apache Ignite应用程序时节省大量时间和精力。 我们将讨论发布准备; 如何使集群组装; 如何在Compute Grid中开始一些计算; 如何准备数据模型和代码,以便可以将数据写入Ignite,然后成功读取。 最重要的是:如何从一开始就不破坏任何内容。
启动准备-配置日志记录
我们需要日志。 如果您曾经在Apache Ignite邮件列表或StackOverflow上问过一个问题,例如“为什么一切都挂了”,则很可能要求您发送的第一件事是来自所有节点的所有日志。
自然,默认情况下会启用Apache Ignite日志记录。 但是有细微差别。 首先,Apache Ignite在stdout编写了一些内容。 默认情况下,它以所谓的安静模式启动。 在stdout您只会看到最可怕的错误,其他所有内容都将保存在文件中,Apache Ignite最初显示的路径(默认情况下- ${IGNITE_HOME}/work/log )。 您无需擦除它并使日志保留更长的时间,这将非常有用。
默认启动时stdout点燃
为了使查找问题更容易而又无需进入单独的文件并为Apache Ignite设置单独的监视,可以使用以下命令以详细模式运行它
ignite.sh -v
然后系统将开始在stdout记录所有事件,以及其余的应用程序日志记录。
检查日志! 很多时候,您可以找到解决问题的方法。 如果群集已崩溃,则通常会在日志中看到诸如“在这种配置中增加此类超时”这样的消息。 我们因为他摔倒了。 他太小了。 网络不够好。”
集群组装
不速之客
许多人面临的第一个问题是集群中不速之客。 或您自己却成为不速之客:启动一个新集群,突然您发现在第一个拓扑快照中,而不是从一个节点开始就拥有两个服务器。 怎么会这样 您只启动了一个。
一条消息,指示集群有两个节点

事实是,默认情况下,Apache Ignite使用多播,并且在启动时它将查找位于同一子网,同一多播组中的所有其他Apache Ignite。 如果可以,它将尝试连接。 如果连接不成功,它将根本无法启动。 因此,在我的工作笔记本电脑上的群集中,同事的笔记本电脑上的群集中的其他节点经常有规律地出现,这当然不是很方便。
如何保护自己呢? 配置静态IP的最简单方法。 代替了默认情况下使用的TcpDiscoveryMulticastIpFinder ,而是提供了TcpDiscoveryVmIpFinder 。 在此处,记下要连接的所有IP和端口。 这更加方便,可以保护您免受许多问题的困扰,尤其是在开发和测试环境中。
地址太多
下一个问题。 禁用多播,启动群集,在一个配置中,您从不同环境中设置了相当数量的IP。 碰巧您会在一个新群集中启动第一个节点5-10分钟,尽管所有后续节点都将在5-10秒内连接到该节点。
列出三个IP地址。 对于每个端口,我们规定10个端口的范围。 总共获得30个TCP地址。 由于Apache Ignite必须在创建新集群之前尝试连接到现有集群,所以它将依次检查每个IP。 它可能不会对您的笔记本电脑造成伤害,但是在某些多云的环境中通常包括端口扫描保护。 也就是说,当访问某个IP地址上的专用端口时,直到超时之前您都不会收到任何响应。 默认情况下为10秒。 如果您有10个端口的3个地址,那么您将获得3 * 10 * 10 = 300秒的等待时间-同样是5分钟的连接时间。
解决方案显而易见:不要注册不必要的端口。 如果您具有三个IP,则几乎不需要真正的默认范围10个端口。 当您在本地计算机上测试某些东西并运行10个节点时,这很方便。 但是在实际系统中,单个端口通常就足够了。 或有机会在内部网络上禁用端口扫描防护。
第三个常见问题是IPv6。 您会看到奇怪的网络错误消息:无法连接,无法发送消息,节点已分段。 这意味着您已脱离集群。 通常,此类问题是由IPv4和IPv6的混合环境引起的。 这并不是说Apache Ignite不支持IPv6,但是目前存在某些问题。
最简单的解决方案是将选项传递给Java机器
-Djava.net.preferIPv4Stack=true
然后,Java和Apache Ignite将不会使用IPv6。 这解决了群集崩溃的大部分问题。
准备代码库-我们正确序列化
集群已经聚集,有必要在其中启动一些东西。 在代码与Apache Ignite代码交互中,最重要的元素之一是Marshaller或序列化。 为了将某些内容写入内存,实现持久性并通过网络发送,Apache Ignite首先对您的对象进行序列化。 您会看到以以下单词开头的消息:“无法以二进制格式编写”或“无法使用BinaryMarshaller进行序列化”。 日志中只会出现一个这样的警告,但是很明显。 这意味着您需要多调整一些代码才能与Apache Ignite成为朋友。
Apache Ignite使用三种机制进行序列化:
JdkMarshaller常规Java序列化;OptimizedMarshaller稍微优化了Java序列化,但是机制是相同的;BinaryMarshaller是专门为Apache Ignite编写的序列化,在其内部广泛使用。 她有很多优点。 在某个地方我们可以避免额外的序列化和反序列化,在某个地方我们甚至可以在API中获得一个非反序列化的对象,可以像JSON之类的二进制格式直接使用它。
BinaryMarshaller将能够序列化和反序列化您的POJO,这些POJO除了字段和简单方法外什么都没有。 但是,如果您通过readObject()和writeObject()进行了自定义序列化,则如果使用Externalizable ,那么BinaryMarshaller将无法应对。 他将看到您的对象无法通过非瞬态字段的常规记录进行序列化,并且会放弃-它会回滚到OptimizedMarshaller 。
为了使用Apache Ignite成为此类对象的朋友,您需要实现Binarylizable接口。 他很简单。
例如,有一个来自Java的标准TreeMap 。 它具有通过读写对象的自定义序列化和反序列化功能。 它首先描述了一些字段,然后将长度和数据本身写入到OutputStream 。
TreeMap.writeObject()
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException {
writeBinary()和readBinary()工作方式完全相同: BinaryTreeMap将自身包装在常规TreeMap并将其写入OutputStream 。 此方法易于编写,将大大提高生产率。
BinaryTreeMap.writeBinary()实现
public void writeBinary(BinaryWriter writer) throws BinaryObjectException { BinaryRawWriter rewriter = writer. rewrite (); rawWriter.writeObject(map.comparator()); int size = map.size(); rawWriter.writeInt(size); for (Map.Entry<Object, Object> entry : ((TreeMap<Object, Object>)map).entrySet()) { rawWriter.writeObject(entry.getKey()); rawWriter.writeObject(entry.getValue()); } }
在Compute Grid中启动
Ignite不仅允许您存储数据,还可以运行分布式计算。 我们如何运行某种lambda,以使其分散所有服务器并运行?
首先,这些代码示例有什么问题?
怎么了
Foo foo = …; Bar bar = ...; ignite.compute().broadcast( () -> doStuffWithFooAndBar(foo, bar) );
如果是这样?
Foo foo = …; Bar bar = ...; ignite.compute().broadcast(new IgniteRunnable() { @Override public void run() { doStuffWithFooAndBar(foo, bar); } });
您可能会猜到,许多人熟悉lambda和匿名类的陷阱,问题在于从外部捕获变量。 例如,我们运送lambda。 它使用了在lambda之外声明的几个变量。 这意味着这些变量将随她一起传播,并通过网络飞向所有服务器。 然后出现所有相同的问题:这些对象是否与BinaryMarshaller友好? 他们是什么尺寸? 我们通常是希望将它们转移到某个地方,还是这些对象太大,以至于最好传递某种ID并在另一侧的lambda内部重新创建对象?
匿名班更糟。 如果lambda不能随身携带,请将其丢弃,如果不使用它,那么匿名类肯定会使用它,这通常不会带来任何好处。
下面的例子。 再次使用Lambda,但是使用了Apache Ignite API。
在计算闭包内部使用ignite是错误的
ignite.compute().broadcast(() -> { IgniteCache foo = ignite.cache("foo"); String sql = "where id = 42"; SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true); return foo.query(qry); });
在原始版本中,它需要缓存并在其中本地进行某种SQL查询。 当您需要发送仅适用于远程节点上的本地数据的任务时,将采用这种模式。
这是什么问题? Lambda再次捕获链接,但现在不是到对象的链接,而是到我们发送它的节点上的本地Ignite的链接。 它甚至可以工作,因为Ignite对象具有readResolve()方法,该方法允许反序列化将通过网络发送的Ignite替换为我们发送它的节点上的本地Ignite。 但这有时也会导致不良后果。
基本上,您只是通过网络传输了比您想要的更多的数据。 如果需要从某些代码中获得不受控制的Apache Ignite或其某些接口启动的代码,那么最简单的方法是使用Ignintion.localIgnite()方法。 您可以从Apache Ignite创建的任何线程中调用它,并获得指向本地对象的链接。 如果您有lambda,服务或其他任何东西,并且您知道这里需要Ignite,则建议使用此方法。
我们正确地在计算闭包内部使用了localIgnite()通过localIgnite()
ignite.compute().broadcast(() -> { IgniteCache foo = Ignition.localIgnite().cache("foo"); String sql = "where id = 42"; SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true); return foo.query(qry); });
还有这部分的最后一个例子。 Apache Ignite有一个服务网格,可用于直接在集群中部署微服务,而Apache Ignite将帮助保持正确数量的实例在线。 假设在此服务中,我们还需要指向Apache Ignite的链接。 如何获得? 我们可以使用localIgnite() ,但是此链接必须手动保存在字段中。
服务将Ignite 错误地存储在字段中-将其作为构造函数的参数
MyService s = new MyService(ignite) ignite.services().deployClusterSingleton("svc", s); ... public class MyService implements Service { private Ignite ignite; public MyService(Ignite ignite) { this.ignite = ignite; } ... }
有一种更简单的方法。 我们仍然有完整的类,而不是lambda,因此我们可以将字段注释为@IgniteInstanceResource 。 创建服务后,Apache Ignite会将其放置在那里,您可以安全地使用它。 我强烈建议您这样做,不要尝试将Apache Ignite及其子级传递给构造函数。
服务使用@IgniteInstanceResource
public class MyService implements Service { @IgniteInstanceResource private Ignite ignite; public MyService() { } ... }
写入和读取数据
注意基线
现在,我们有了一个Apache Ignite集群并准备了代码。
让我们想象一下这种情况:
- 一个已
REPLICATED缓存-所有节点上都有数据副本; - 本机持久性已启用-写入磁盘。
我们开始一个节点。 由于启用了本机持久性,因此我们需要在使用集群之前先激活它。 激活。 然后,我们启动更多节点。
一切似乎都正常:写作和阅读都很好。 所有节点都有数据的副本;您可以安全地停止一个节点。 但是,如果停止从其启动启动的第一个节点,则一切都将中断:数据消失,并且操作停止传递。
其原因是基准拓扑-在其上存储持久性数据的许多节点。 所有其他节点将没有持久性数据。
第一次设置此节点集是在激活时确定的。 随后添加的那些节点不再包含在基准节点数中。 也就是说,许多基准拓扑仅由一个,第一个节点组成,当它停止时,一切都会中断。 为防止这种情况发生,请先启动所有节点,然后再激活集群。 如果需要使用以下命令添加或删除节点
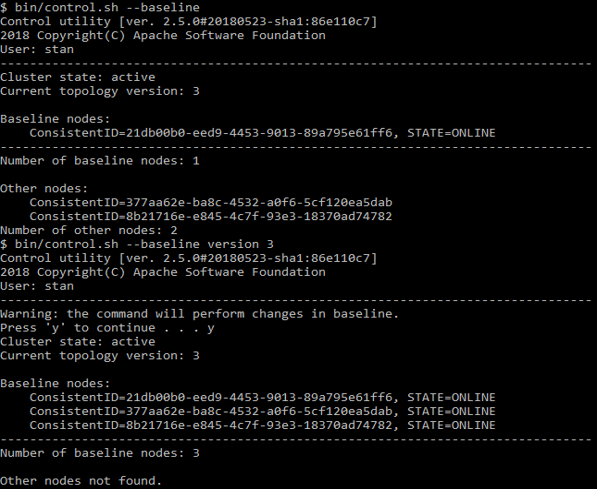
control.sh --baseline
您可以看到其中列出了哪些节点。 相同的脚本可以将基准更新为当前状态。
control.sh示例
数据托管
现在我们知道数据已保存,请尝试读取它。 我们有SQL支持,您可以执行SELECT就像在Oracle中一样。 但是同时,我们可以在任意数量的节点上扩展和运行,数据以分布式方式存储。 让我们看一个这样的模型:
public class Person { @QuerySqlField public Long id; @QuerySqlField public Long orgId; } public class Organization { @QuerySqlField private Long id; }
索取
SELECT * FROM Person as p JOIN Organization as o ON p.orgId = o.id
不会返回所有数据。 怎么了
人员( Person )通过ID表示组织( Organization )。 这是经典的外键。 但是,如果我们尝试合并两个表并发送这样的SQL查询,则在群集中有几个节点时,我们将不会接收所有数据。
事实是,默认情况下,SQL JOIN仅在单个节点内工作。 如果SQL不断遍历整个群集以收集数据并返回完整结果,那将非常慢。 我们将失去分布式系统的所有好处。 因此,Apache Ignite只会查看本地数据。
为了获得正确的结果,我们需要将数据放在一起(托管)。 也就是说,为了正确组合“个人”和“组织”,两个表的数据必须存储在同一节点上。
怎么做? 最简单的解决方案是声明一个相似性密钥。 这是一个值,用于确定此值或该值将位于哪个节点,哪个分区,哪个记录组中。 如果我们在“ Person中将组织ID声明为相似性键,这意味着具有此组织ID的人员必须与具有相同ID的组织位于同一节点上。
如果由于某种原因您不能执行此操作,则还有另一种效果较差的解决方案-启用分布式联接。 这是通过API完成的,过程取决于您使用的内容-Java,JDBC或其他内容。 然后, JOIN将执行得更慢,但是它们将返回正确的结果。
让我们考虑如何使用相似性键。 我们如何理解某某ID,某某字段适合确定亲和力? 如果我们说所有具有相同orgId都将被存储在一起,那么orgId是一个不可分割的组。 我们无法在几个节点之间分配它。 如果数据库包含10个组织,则可以将10个不可分割的组放在10个节点上。 如果群集中有更多节点,则所有“额外”节点将保持没有组的状态。 这在运行时很难定义,因此请事先考虑一下。
如果您有一个大型组织,而有9个小型组织,则组的大小将有所不同。 但是,Apache Ignite在将它们分布在节点之间时不会查看相似性组中的记录数。 因此,他不会将一个组放在一个节点上,而是将9个其他组放在另一个节点上,以便以某种方式平衡分布。 相反,他会将它们设置为5和5(或6和4,甚至7和3)。
如何使数据均匀分布? 可以有
- K键;
- 各种相似性密钥;
- P分区,即Apache Ignite将在节点之间分发的大量数据;
- N个节点。
那么有必要条件
K >> A >> P >> N
>> “更多”,数据将相对均匀地分布。
顺便说一句,默认值为P = 1024。
您很可能不会成功进行统一分发。 在Apache Ignite 1.x到1.9中就是这种情况。 这称为FairAffinityFunction ,但效果不佳-导致节点之间的流量过多。 现在,该算法称为RendezvousAffinityFunction 。 它没有给出绝对诚实的分布,节点之间的误差为正负5-10%。
新Apache Ignite用户的清单
- 设置,读取,存储日志
- 关闭多播,仅写下您使用的那些地址和端口
- 禁用IPv6
- 准备
BinaryMarshaller - 跟踪基线
- 设置亲和力搭配