
数据仓库的学术设计建议将所有内容保持规范化形式,并保持相互之间的联系。 然后,关系数学更改的回滚将提供具有事务支持的可靠存储库。 原子性,一致性,隔离性,耐久性-仅此而已。 换句话说,存储库是专门为安全更新数据而构建的。 但是对于搜索而言,它并不是最佳选择,尤其是在跨表和字段的情况下。 需要索引,很多索引。 音量增加,录制速度变慢。 未对SQL LIKE进行索引,并且JOIN GROUP BY将其发送到查询计划器以进行冥想。
一台机器上不断增加的负载迫使其向上或垂直扩展到天花板,或购买更多节点。 故障转移要求使数据分布在多个节点上。 故障后需要立即恢复且不拒绝服务的要求迫使您配置机器集群,以便它们在任何时候都可以执行写入和读取操作。 也就是说,已经是一个大师,或者立即自动成为他。
快速搜索的问题通过安装第二个为附近索引优化的存储库而得以解决。 全文搜索,多面,带有词干 和二十一点 。 第二个存储接受第一个存储的表中的条目作为输入,分析并建立索引。 因此,数据存储群集由另一个群集补充,以进行搜索。 具有类似的主配置以匹配整体SLA 。 一切都很好,生意兴高采烈,管理员晚上睡觉了……直到主-主集群中的机器超过三台。
有弹性
NoSQL运动极大地扩展了小型和大型数据的规模范围。 群集的NoSQL节点可以在它们之间分配数据,这样一个或多个NoSQL节点的故障不会导致整个群集的服务被拒绝。 分布式数据的高可用性的代价是无法确保它们在任何给定时间的记录完全一致。 相反,NoSQL谈到了最终的一致性 。 也就是说,据信一天之内所有数据将分散到群集的节点,并且从长远来看它们将变得一致。
因此,关系模型得到了非关系模型的补充,并催生了许多数据库引擎,这些引擎成功地解决了CAP三角形的问题。 开发人员可以使用各种时尚的工具来构建自己的理想持久层-针对每种口味,预算和负载情况。
ElasticSearch是NoSQL的代表,在Lucene引擎上以RESTful JSON API集群,该语言是Java的开源代码,不仅可以构建搜索索引,还可以存储原始文档。 这样的伪装有助于重新考虑使用单独的DBMS来存储原件甚至放弃原件的作用。 引言结束。
制图
ElasticSearch中的映射类似于架构(表结构,用SQL表示),可以告诉您确切地如何为传入文档建立索引(用SQL表示记录)。 映射可以是静态的,动态的或不存在的。 静态映射不允许自己更改。 动态允许您添加新字段。 如果未指定映射,ElasticSearch将在收到第一个要编写的文档后自行完成。 它将分析字段的结构,对其中的数据类型做出一些假设,跳过默认设置并将其写下来。 乍一看,这种无电路行为似乎非常方便。 但实际上,它比实验中的惊喜更适合进行实验。
因此,对数据建立索引,这是一个单向过程。 创建映射后,无法像SQL中的ALTER TABLE一样动态更改映射。 因为SQL表存储原始文档,您可以在其中固定搜索索引。 但是在ElasticSearch中则相反。 他本人是可以固定原始文档的搜索索引。 这就是索引架构为静态的原因。 从理论上讲,可以在映射中创建一个字段或将其删除。 实际上,ElasticSearch仅允许您添加字段。 尝试删除字段不会导致任何结果。
别名
别名-这是ElasticSearch索引的附加名称。 一个索引可以有多个别名。 或多个索引的一个别名。 然后,这些索引在逻辑上进行组合,就像从外面看起来一样。 Alias对于在整个生命周期内与索引进行通信的服务非常方便。 例如,别名产品可以隐藏products_v2和products_v25 ,而不必更改服务中的名称。 当别名已经从旧方案转移到新方案时,别名对于数据迁移是必不可少的,并且您需要切换应用程序以使用新索引。 将别名从索引切换到索引是一个原子操作。 即,它一步完成而没有损失。
重新索引API
数据布局,映射往往会不时发生变化。 添加新字段,删除不必要的字段。 如果ElasticSearch充当唯一存储库的角色,那么您需要某种工具来即时更改映射。 为此,有一个特殊的命令将数据从一个索引传输到另一个索引,即所谓的_reindex API 。 它与服务器端的收件人索引的现成或空映射一起工作,一次可以快速批量索引1000个文档。
重新索引可以执行简单的字段类型转换。 例如long in text和long in或boolean text and back boolean 。 但是布尔值 -9.99不再知道如何 对你来说不是PHP 。 另一方面,类型转换并不安全。 用这种动态类型的语言编写的服务可以免除这种罪过。 但是,如果reindex无法转换类型,那么该文档将不会被写入。 通常,数据迁移应分三个阶段进行:添加新字段,使用该字段释放服务,清理旧字段。
像这样添加一个字段。 采用源索引方案,输入新属性,创建空索引。 然后重新索引开始:
{ "source": { "index": "test" }, "dest": { "index": "test_clone" } }
该字段以类似的方式删除。 采用源索引方案,删除字段,创建空索引。 然后,重新索引从要复制的字段列表开始:
{ "source": { "index": "test", "_source": ["field1", "field3"] }, "dest": { "index": "test_clone" } }
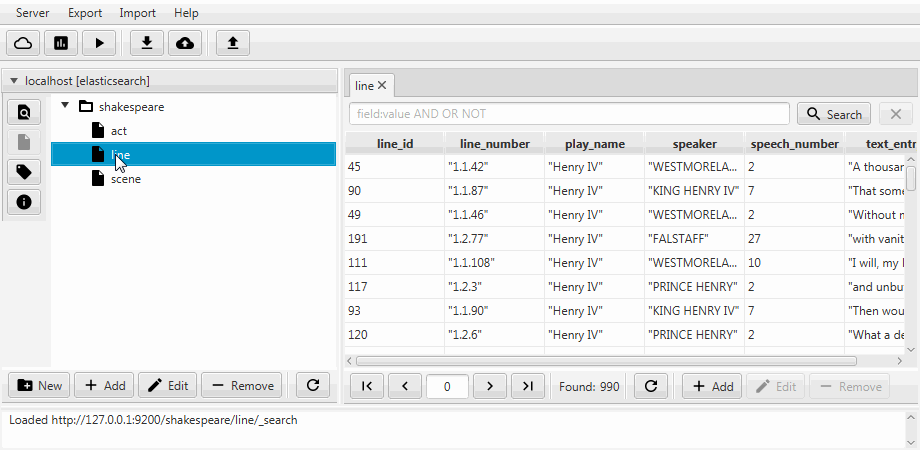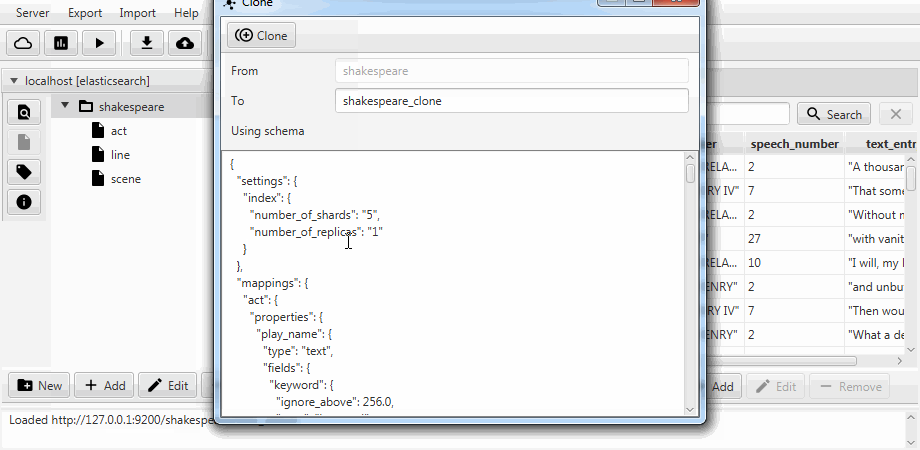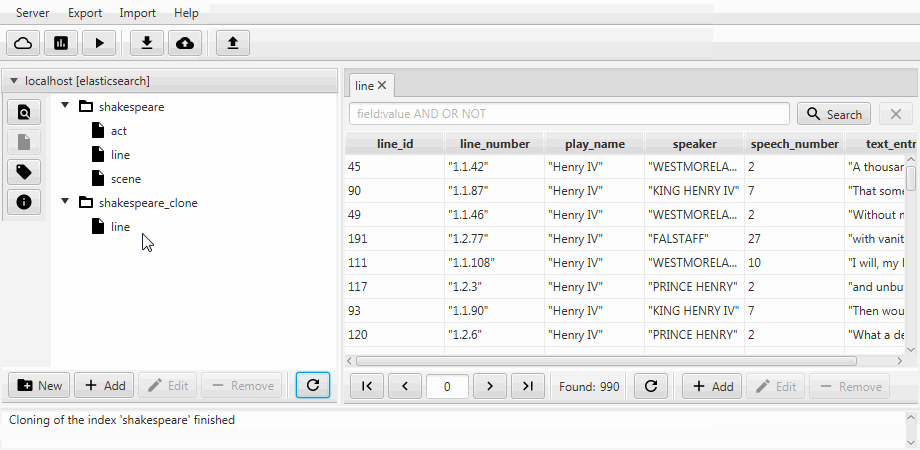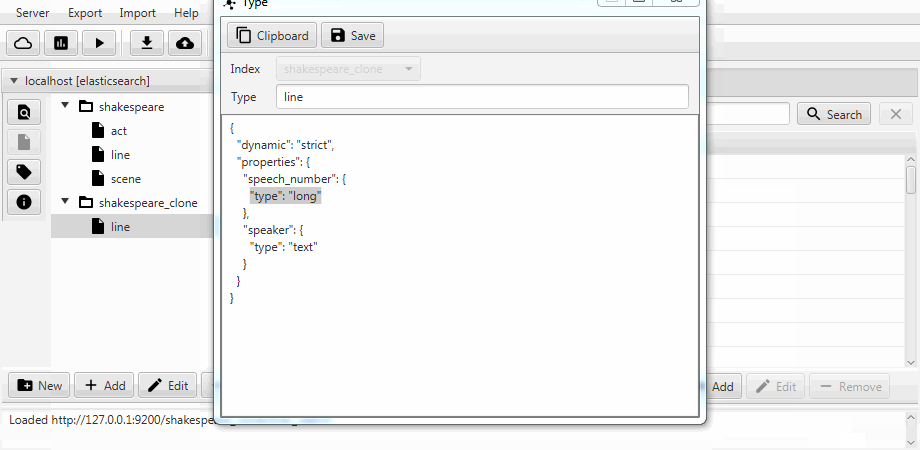
为方便起见,这两种情况都在Kaizen(ElasticSearch的桌面客户端)中合并为克隆功能。 克隆可以适应目标索引的映射。 下面的示例演示如何从具有三个集合(类型,用ElasticSearch表示) act , line和scene的索引中进行部分克隆。 仅保留具有两个字段的行 ,启用了静态映射,并且文本中的speech_number字段变长 。
迁移
重新索引API具有一项令人不愉快的功能-它不知道如何监视源索引中的更改。 如果在重新建立索引之后那里发生了某些更改,则这些更改不会反映在收件人索引中。 为了解决此问题,开发了ElasticSearch FollowUp插件,该插件添加了日志记录命令。 该插件可以监视索引,以JSON格式按时间顺序返回对文档执行的操作。 记住索引,类型,文档标识符以及对其的操作-INDEX或DELETE。 FollowUp插件在GitHub上发布,并针对几乎所有版本的ElasticSearch进行编译。
因此,为了进行无损数据迁移,您将需要在重新索引开始的节点上安装FollowUp。 假定索引已经具有别名,并且所有应用程序都可以通过该别名进行工作。 在重新编制索引之前,该插件已打开。 重新索引完成后,插件将关闭,别名将翻转到新索引。 然后,将记录的操作复制到接收者索引上,以赶上其状态。 尽管重新索引的速度很高,但是在播放过程中可能会发生两种冲突:
- 在新索引中不再有带有_id的文档。 在将别名切换到新索引之后,他们设法删除了文档。
- 在新索引中,有一个文档具有_id ,但版本号高于源索引。 在将别名切换到新索引之后,他们设法更新了文档。
在这些情况下,不应在目标索引中复制操作。 复制其他更改。
编码愉快!