 这是一个真实的故事。 帖子中描述的事件发生在21世纪的一个温暖的国家。 以防万一,字符名称已更改。 出于对专业的尊重,一切都被告知了。
这是一个真实的故事。 帖子中描述的事件发生在21世纪的一个温暖的国家。 以防万一,字符名称已更改。 出于对专业的尊重,一切都被告知了。
哈Ha 在这篇文章中,我们将谈论臭名昭著的A / B测试,不幸的是,即使在21世纪,它也是无法避免的。 替代测试选项已经存在并在网上繁荣了很长时间,而离线测试选项必须根据情况进行调整。 我们将讨论大规模离线零售中的一种此类调整,以体验通常与一家顶级咨询公司合作的经验。
挑战赛
 过去,我曾在一家大型公司的一个项目中工作,该公司拥有杂货店网络(超过500家商店)。 恐怕我不应该给公司起名,我们将这个组织称为公司。 底线是商店的大小不同,大小可以相差数十倍; 商店可以位于不同的城市,村庄和村庄; 商店可以根据自己的人口统计分布在城市的不同区域。 通常,在这里,我倾向于这样一个事实:如果您需要检验任何假设,那么在A / B检验范式中,几乎不可能做到这一点而不会对业务造成重大损害。 让我们以啤酒为例来考虑这件事。 一旦咨询办公室来到公司,您就会知道,这些都是从最顶层说的:“但是,亲爱的,您在这里喝的啤酒不是窗户上正确的品牌,而且通常不是您需要的顺序,请给我们发送一些Kamaz黄金根据我们的估计,我们将告诉您您需要哪些品牌,以及如何将它们分解出来。这将在试点后的第一年为您带来10亿加元的收入。” 办公室受到尊重,因此毫无疑问是十亿。 另外,由于这些方法不能说谎,因此不能质疑其方法。 只是不是我们。 通常,这些行的作者得出的任务是“好吧,看看那里他们是如何进行试验的,并在需要时提供帮助”。
过去,我曾在一家大型公司的一个项目中工作,该公司拥有杂货店网络(超过500家商店)。 恐怕我不应该给公司起名,我们将这个组织称为公司。 底线是商店的大小不同,大小可以相差数十倍; 商店可以位于不同的城市,村庄和村庄; 商店可以根据自己的人口统计分布在城市的不同区域。 通常,在这里,我倾向于这样一个事实:如果您需要检验任何假设,那么在A / B检验范式中,几乎不可能做到这一点而不会对业务造成重大损害。 让我们以啤酒为例来考虑这件事。 一旦咨询办公室来到公司,您就会知道,这些都是从最顶层说的:“但是,亲爱的,您在这里喝的啤酒不是窗户上正确的品牌,而且通常不是您需要的顺序,请给我们发送一些Kamaz黄金根据我们的估计,我们将告诉您您需要哪些品牌,以及如何将它们分解出来。这将在试点后的第一年为您带来10亿加元的收入。” 办公室受到尊重,因此毫无疑问是十亿。 另外,由于这些方法不能说谎,因此不能质疑其方法。 只是不是我们。 通常,这些行的作者得出的任务是“好吧,看看那里他们是如何进行试验的,并在需要时提供帮助”。
在听了关于他们的用于在显示窗口上生成商品显示的方法如何工作的简短演讲之后,进入算法细节的愿望完全消失了。 我决定专注于衡量质量,从理论的角度来看,这更有趣。 这也使公司不能投资于故意无利可图的项目。 可以访问并行的Universe,可以进行A / B测试,其中Universe A中的一切都像以前一样进行,而Universe B中的商品布局已更改。 A / B测试是一种受控实验,其中用户被随机分为对照组和测试组。 在测试组中进行干预,等待一段时间,然后测量该干预对目标指标的影响,最后比较两组的指标。 希望使对照组和测试组之间相对于彼此的偏差最小。 例如,没有这样的事情,在A组中只有城市,而B组中只有村庄。 对于网站,似乎可以轻松解决偏移问题:向用户显示一个ID为偶数的版本,而向另一个ID为奇数的用户显示该站点的另一个版本。 在拥有连锁商店的情况下,一切都不是那么简单,无论您如何破坏用户或商店,总会发现A组和B组并不相同。 小组A白天到商店,晚上B到商店。 调整时间,事实证明A的周末比B出现的频率更高。对所有这些细节进行调整,事实证明,要取得具有统计意义的结果,您将不得不等待半年并取消所有营销公司。 如果您到了城市,事实证明莫斯科是一个团体,而另一个团体却不在。 通常,一个组相对于另一组总是存在转移。 各种全球和本地营销活动,节假日和不可预见的情况以停车维修的形式叠加在此上。
您还记得Office来自世界各地的顶级办事处,并且自然可以为测试问题提供解决方案。 考虑一下他们的方法论,并使用响亮的营销名称-三重差异方法论。
三重差异方法
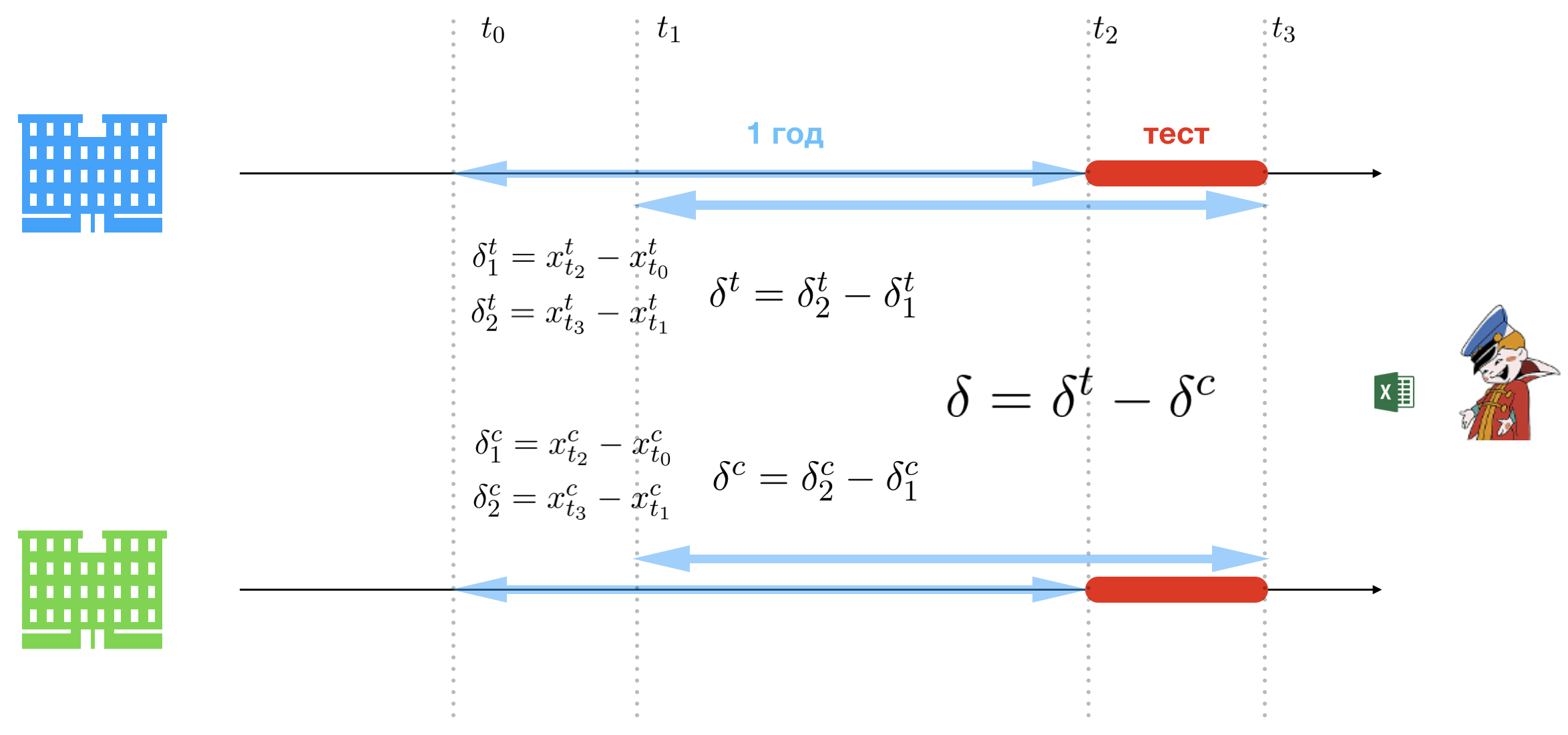
三重差异方法的本质是简单性。 为了使公司的高层在听演讲时不会紧张,此次演讲将由一位身材不错的女士主持。 通过放宽A / B测试的局限性可以实现简单性。 监察办的唯一困难仍然是控制组和测试组的选择,但我们将省略该过程的这一部分,因为除了一大堆可疑的假设外,没有其他有趣的事情了。 因此,由于对现有的连锁商店进行了全面分析,该办公室选择了两个:一个用于对照组(绿色),一个用于测试组(蓝色)。
我们引入以下符号:
- t2 :试点开始日期;
- t3 :试点结束日期;
- t0=t2−一年 :日期对应于飞行员去年开始的日期;
- t1=t3−一年 :对应于飞行员最后一年的日期。
因此,我们有两个时间段:
- \左[t2,t3\右] :试验期(试验期);
- \左[t0,t1\右] :与去年试点时期相对应的时期。
建议比较试点和一年前测试店的收入和控制期。 为此,您需要计算三组差异。 表示每天的销售额 t 在测试商店中 xTt 和 xCt -在控制中。 第一组设定基准,从该基准可以测量试点期内的销售增长或下降:
- deltaT1=xTt2−xTt0 :试点开始与一年前同一天在测试商店中的销售差异;
- deltaT2=xTt3−xTt1 :试点期结束与一年前的同一天在测试商店中的销售差异;
- deltaC1=xCt2−xCt0 :试点开始与一年前的同一天在控制商店中的销售差异;
- deltaC2=xCt3−xCt1 :试点期结束与一年前在控制商店中的同一天之间的销售额差异。
第二组差异决定了试行期内销售额的增长或下降:
- deltaT= deltaT2− deltaT1 :试点结束和试点在试点商店之间的销售差异(已调整至一年前的日期);
- deltaC= deltaC2− deltaC1 :控制商店中试点结束与试点开始之间的销售差异(已调整至一年前的日期)。
最后,决定性的差异决定了哪个商店在试点期间效果更好:
好吧,如果要实施一个以卡玛斯金币为代价的项目的决定很简单 delta>0 -这意味着测试店销售了更多的啤酒,因此办公室的方法有效并产生了积极的效果,因此需要引入。 仅此而已。
用ML基线进行A / B测试
在研究了三重差的方法后,发现当局已经批准了这种测量方法,并且飞行员开始计划,我的手痛苦地打了我一下。 事实证明,即使方法论行不通,办公室也为我们提供了在项目中投资KAMAZ黄金的机会,并且销售差额为1卢布。 迫切需要开发出一种至少可以使人们对货架上啤酒新方法的有效性充满信心的东西。 您还记得,进行离线诚实A / B测试的一种方法是存在并行Universe,然后在其中我们可以介绍啤酒计算方法,在第二种方法中,我们将一切保持原样,稍等片刻并比较结果。 但是,如果我们使用机器学习来模拟并行宇宙呢?

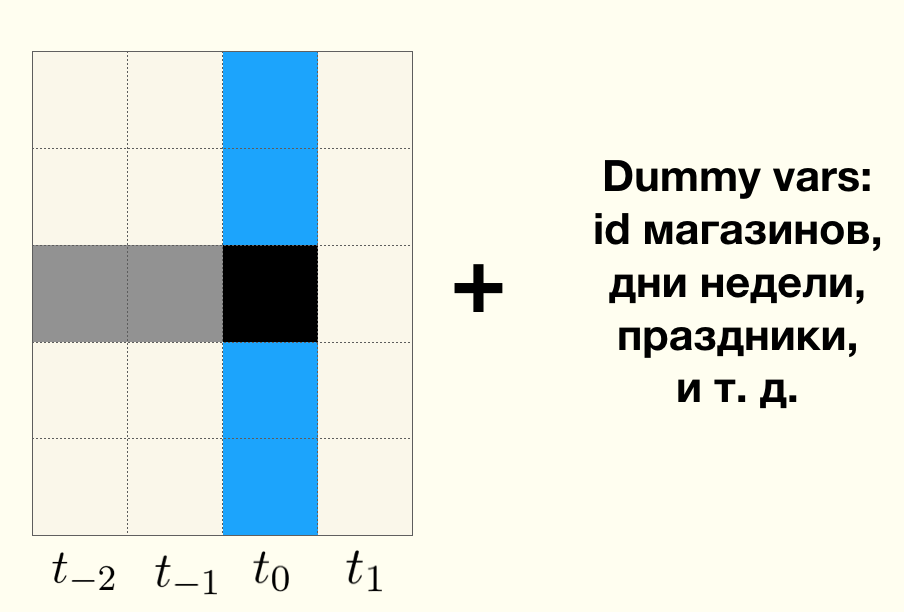
假设我们有每个商店的每日销售时间序列。 灰色实线划分了
飞行员之前和
之后的时间段。 实灰线和虚线之间的区域是购买者适应新产品组合和新品牌的时期,在此期间,销售数据不会影响测试结果,因此将被忽略。 红色常亮表示试点之前任何商店的实际销售额。 右侧是测试存储和控制的组合。 绿色虚线是任何商店的销售预测,仅使用试点开始之前的可用数据。
- 红线是试点启动后该时期控制商店的实际销售额。 对于对照组的商店,在试点开始后的一段时间内,我们仅观察销售预测(绿色间歇)和实际销售(红色间歇)。
- 稳定的蓝色是试点启动后一段时间内测试组商店的实际销售额。 在测试商店中,我们仅观察到销售预测(绿色间歇)和实际销售(持续蓝色)。
绿色虚线是机器学习的基准线。
如果飞行员成功,即 由于以更新的分类和新的布局形式进行的测试干预会对日销售额产生积极影响,因此,测试商店中的实际销售额(蓝色)将平均高于对照商店中的实际销售额(红色间歇)。
让我们看看平均而言。 为此,我们必须做一个假设,我们假设模型的预测误差具有正态分布:
\大 epsiloni sim\数学N\左(0, sigma2\右)
 我们再增加一个大胆的假设,即我们今天感兴趣的类别中的销售额线性依赖于今天相关类别中的销售额以及昨天和近期中我们感兴趣的类别中的销售额,我们还可以将各种商店元数据归因于此,以考虑偏差在受众特征和其他属性中。
我们再增加一个大胆的假设,即我们今天感兴趣的类别中的销售额线性依赖于今天相关类别中的销售额以及昨天和近期中我们感兴趣的类别中的销售额,我们还可以将各种商店元数据归因于此,以考虑偏差在受众特征和其他属性中。
\大yi= vecwT vecxi+ epsiloni
事实证明这是一个非常熟悉的模型 。 值得注意的是,这里模型的选择不是特别重要,重要的是误差具有正态分布或另一已知分布,以便对平均值的均等性进行统计检验。 有了这样的问题陈述,就可以始终在模型构建阶段进行正态性检验,并且根据规范测试的版本,几乎可以对所有模型上的分布进行正态检验。
因此,尽管这不是强制性要求,但我使用线性回归作为预测模型,但我以模型的简单性和可解释性为指导。 值得注意的是,该模型是可预测的,但我将其称为解释性的。 由于我们不预测未来,而是在同一天使用相关类别的销售额,因此这本质上是一种数据。 相反,我们试图通过整个商店的销售额来解释今天的啤酒销售。 这给我们带来了一个新问题-必须仔细选择模型中使用的功能。 与相关产品类别相关的功能可以分为三类:
- 我们感兴趣的一组商品(淡啤酒,黑啤酒,零啤酒,俄国啤酒,甚至是黄鲸),其中一些标志构成目标变量,而某些标志则完全排除在模型之外;
- 与目标群体最可能相关的商品组,例如,手风琴的故事是尿布和啤酒的销售具有较高的正相关系数;
- 产品组,这些产品组当然与目标组没有显着相关性,即使在模型建立之前,这也是一种正则化方法,并且为了以防万一,很可能将所有内容添加到第二组中。
作为解释变量,我们将第二组的特征添加到模型中。 我们的想法是,我们假设第二组整体的销售变化对第一组产生重大影响,而第一组的销售变化对第二组整体没有特殊影响(第二组更大且变化更大)。
在介绍此方法时,一个普遍的问题是:如果在测试/控制存储中进行停车维修,测试会失败吗? 答案是否定的。 停车将影响整个商店的销售,而不是特别影响啤酒的销售,而我国的啤酒销售取决于其他类别的销售,因此将与所有人一起消费。 您可以令人信服地对Retrodat进行一些模拟。
还值得注意的是,我们没有针对方法B的计算来测试方法A的计算,而是针对旧的来测试新的行为 。 这意味着商店和整个集团不应取消任何先前使用的计划内营销活动。 例如,如果您在过去6个月(甚至几周)内将烈性啤酒的价格降低了2倍,则继续这样做,如果您停止这样做,其行为将有所不同。 请勿在选定的商店中进行新的实验。
建立模型的阶段也离不开陷阱。 测试组和对照组可能包括完全不同的商店,我们模型的任务是对齐所有商店,以便对于任何商店,随机预测误差都以零为中心(或相等于零的偏移量)。 首先,我希望我必须在验证时整理出所有超参数,直到获得所需的结果。 但是事实证明,有了足够的功能集,这是第一次实现,这很有趣,而且不同商店之间随机误差的差异也没有太大差异。 这可能是该方法的弱点之一,因为无法保证将满足这些条件。  对文献的回顾也没有给出任何结果,似乎很多人在机器学习中使用基线,但是理论上没有任何保证。 通常,在所有此类欺诈行为发生之后,我们得到的模型将对所有数据进行完整的训练,并且我们可以为任何选定的商店做出每日销售预测。 而且,我们并不特别担心准确性,只有在所有存储的错误分布均受到相同偏差时(当然,如果相对于零没有偏差,当然会更令人愉悦)。 而且方差可能很大,这只会影响测试结果的统计显着性所需的数据集的大小(这意味着对于给定的先验统计显着性和测试的统计能力,观察数。获得此类结果所需的条件取决于方差)
对文献的回顾也没有给出任何结果,似乎很多人在机器学习中使用基线,但是理论上没有任何保证。 通常,在所有此类欺诈行为发生之后,我们得到的模型将对所有数据进行完整的训练,并且我们可以为任何选定的商店做出每日销售预测。 而且,我们并不特别担心准确性,只有在所有存储的错误分布均受到相同偏差时(当然,如果相对于零没有偏差,当然会更令人愉悦)。 而且方差可能很大,这只会影响测试结果的统计显着性所需的数据集的大小(这意味着对于给定的先验统计显着性和测试的统计能力,观察数。获得此类结果所需的条件取决于方差)
让我们回到上面的图表中,用红色,绿色和蓝色线条表示,最后介绍平均较高或较低的概念。 对于控制商店,我们可以从实际的日销售量(红色虚线)中减去模型预测的日销售量(绿色虚线)。 结果,我们得到了一个以零为中心的正态分布的误差,因此它们中的任何东西都没有改变,并且该模型平均将与实际情况一致。 对于测试组中的商店,我们还从实际每日销售额(蓝色实线),每日销售额模型销售额(绿色间歇性)中减去,也得到了正态分布。 然后,如果没有任何变化,则中心将在零附近。 如果销售有所改善,它将向右移动;如果销售恶化,则将向左移动。 这就是它在模拟数据上的外观。

在这里,我们发现自己处于通常的统计检验条件下,即两个分布的均值相等,并且没有什么可以阻止我们进行该检验。 对于统计测试,我们需要了解以下内容:
- alpha 和 beta :选择自己,或者如果您是幸运的,受过良好教育的人坐在行销中,那么我们将与他们一起选择;
- 分散度:取自回溯期;
- 电梯:不仅需要测试平等性,还需要测试组中的销售增长不少于一定数量的有条件加元; 我们不想实施一个价值不菲的项目,但要使其具有成本效益并且在一百年内不收回成本,我们并没有在克里米亚建立桥梁。
此数据足以计算飞行员所需的天数。 这种方法的另一个好处是可伸缩性。 在我们的案例中,测试进行了60天,即 我们需要60天的观察时间进行测试,而对照组则需要60天的观察时间,以获取具有统计学意义的测试结果。 我们可以在每个组中选择一个商店并等待2个月,或者在每个组中选择两个商店并等待1个月,依此类推。 当然,实验的预算取决于在测试组中增加新商店的数量,但这是您如何选择这种平衡的任务。 我建议您学习此材料 ,以了解计算所需观察数的方法。
真实数据
考虑两个具有实际销售额的图像,该模型经过几年的追溯销售训练。 第一商店:
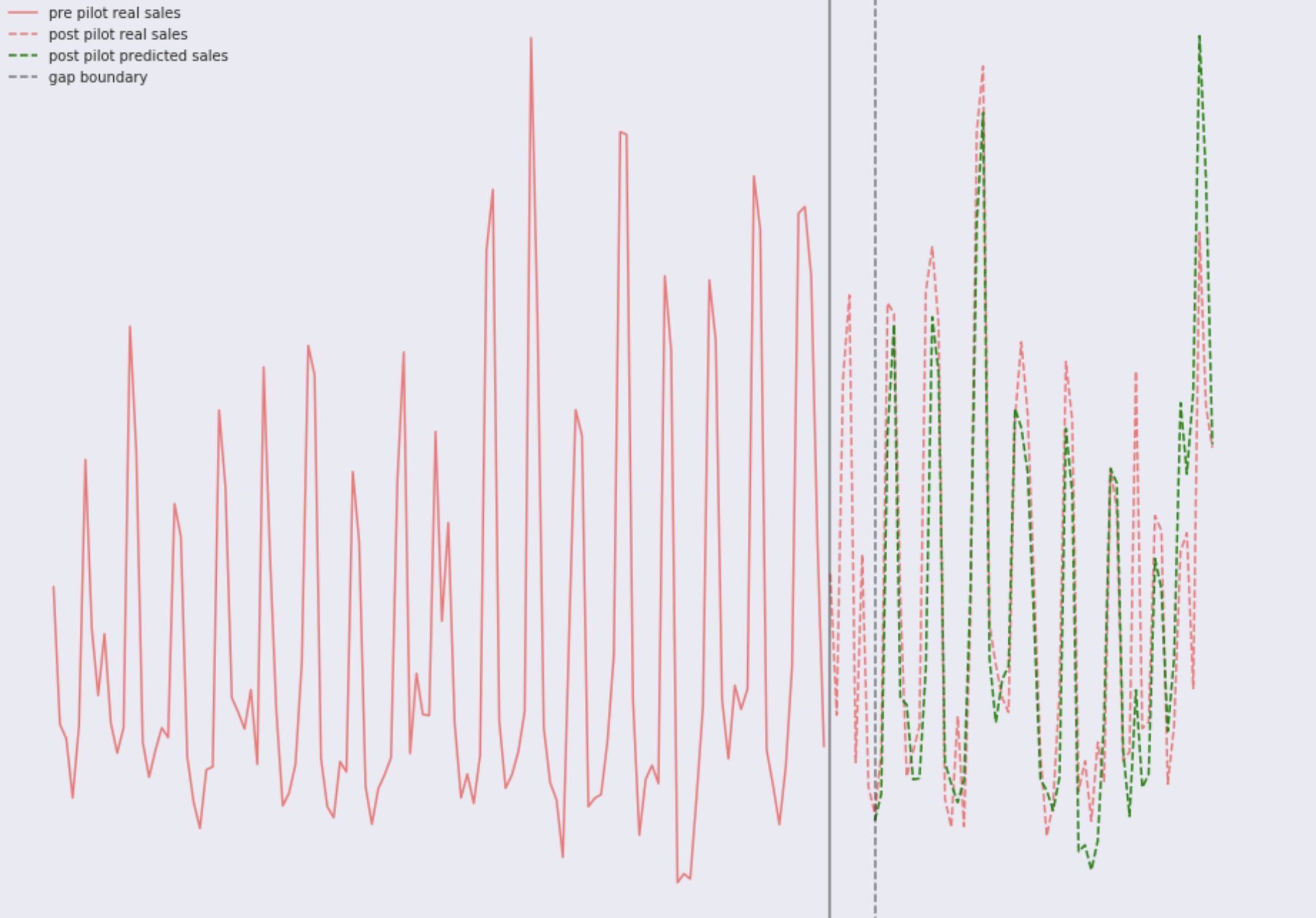
并存储第二个:

如您所见
,一切都很好。 您会很容易注意到每周的模式,以及其中一家商店最近发生的明显变化,这种情况已经发生了变化。 如果仔细观察,您会发现两个存储中的模型都多次犯错。 在这种情况下,有两种选择:
:
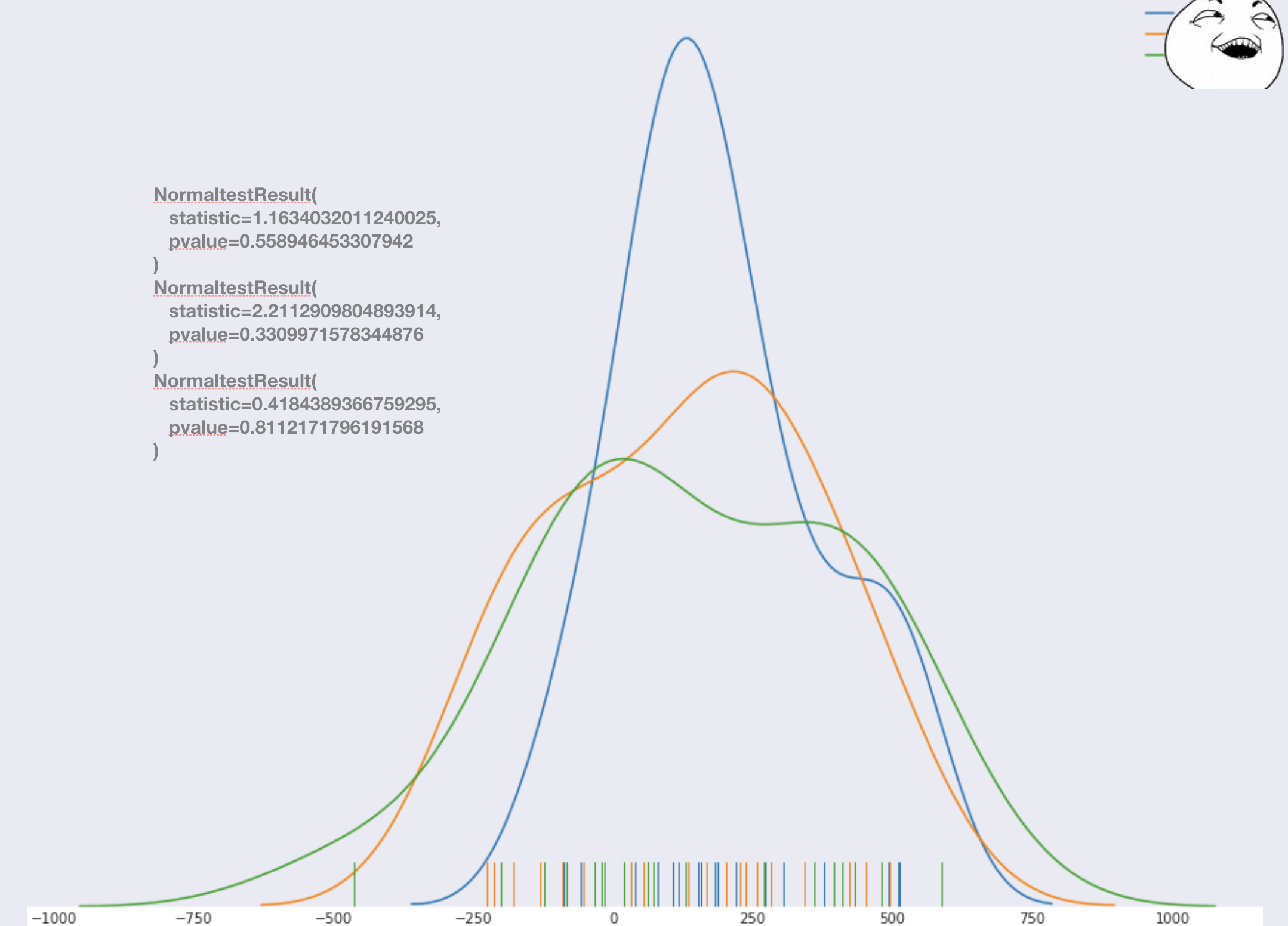 看起来还不错。为了获得信誉,您可以进行正常性测试,并确保一切正常。如果某些测试产生异常结果,则得分或回滚到特征选择点。在这种情况下,我们不需要重新启动试用版,而只需重建模型并重新编号(因此,您可能需要考虑在测试期内包含比第一版模型更多的试用天数)。在我们的情况下,一切都按原样进行。
看起来还不错。为了获得信誉,您可以进行正常性测试,并确保一切正常。如果某些测试产生异常结果,则得分或回滚到特征选择点。在这种情况下,我们不需要重新启动试用版,而只需重建模型并重新编号(因此,您可能需要考虑在测试期内包含比第一版模型更多的试用天数)。在我们的情况下,一切都按原样进行。接下来,我们将测试组中的所有存储与一组控件中的所有存储合并在一起,因此我们可以做到这一点,因此我们在上面假设对于任何存储,模型误差均具有相同的偏见。我们得到两个分布并进行统计测试。
 就像您可能已经猜到的那样,根据我一开始的怀疑,新的独特的产品展示和品牌选择方法对销售没有统计学上的显着影响。从原则上讲,这是意料之中的,因为我看到了选择新品牌的方法和展示方式。恐怕我无法谈论这些独特的技术,但是其中一位去竞争对手为商店橱窗里的啤酒拍照的摄影师...被粗暴地开除。
就像您可能已经猜到的那样,根据我一开始的怀疑,新的独特的产品展示和品牌选择方法对销售没有统计学上的显着影响。从原则上讲,这是意料之中的,因为我看到了选择新品牌的方法和展示方式。恐怕我无法谈论这些独特的技术,但是其中一位去竞争对手为商店橱窗里的啤酒拍照的摄影师...被粗暴地开除。结论
— ? , , 1-2 . - , — . , , , , . :
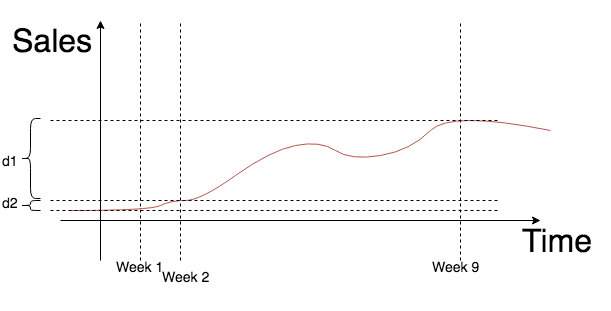
, - , . d2 , , , , d2 . d1+d2 , , , , .
但是飞行员怎么了?一切都好,它正在兴旺发展,他们正在等待十亿美元作为回报给卡玛斯的黄金。该项目的最后一项任务只是实施测试促销的方法,但是当我离开该项目时,备受尊敬的Office很快就因三重差异的相似性而返回了测试。也许同样的命运落在了这场考验上,但我不知道。
顺便说一下,它现在正在另一家零售店中成功实施,另一家咨询办公室(而不是本办公室)建议对分类优化进行测试。结果满足了客户和办公室的期望,并且客户计划根据此类测试的结果引入新的分类优化。