在本文中,我们将讨论使用卷积神经网络来解决一项实际的业务任务,即从带有商品的货架照片上恢复实图。 使用Tensorflow对象检测API,我们将训练搜索/本地化模型。 我们将使用浮动窗口和非最大抑制算法来提高高分辨率照片中小产品的搜索质量。 在Keras,我们正在按品牌对商品进行分类。 同时,我们将比较方法和结果与4年前的决策。 本文中使用的所有数据都可以下载,并且完整的工作代码位于
GitHub上 ,并被设计为教程。

引言
什么是货架图? 在商店的具体交易设备上的商品展示的布局图。
什么是实线图? 在这里和现在的商店中存在的特定交易设备上布置货物。
平面图-应有的实图-我们所拥有的。

到目前为止,在许多商店中,货架,货架,柜台,货架上其余商品的管理完全是手工劳动。 数千名员工手动检查产品的可用性,计算余额,并根据要求检查位置。 这很昂贵,而且很容易出错。 不正确的显示或缺货会导致销售下降。
另外,许多制造商与零售商达成协议以展示其商品。 而且由于有很多制造商,因此在他们之间争夺货架上最好位置的斗争开始了。 每个人都希望他的产品位于购买者对面的中间,并占据最大的面积。 需要进行持续审核。
成千上万的采购员从一家商店搬到另一家商店,以确保其公司的产品在货架上并按照合同进行展示。 有时他们很懒惰:在不离开家的情况下编写报告比去销售点要愉快得多。 需要对审核员进行永久审核。
自然,这个过程的自动化和简化任务已经解决了很长时间。 最困难的部分之一是图像处理:查找和识别产品。 而且直到最近才对该任务进行了如此大的简化,以至于对于特定情况以简化形式而言,其完整解决方案只能在一篇文章中进行描述。 这就是我们要做的。
本文包含最少的代码(仅适用于代码比文本清晰的情况)。 完整的解决方案可在
jupyter笔记本中作为插图教程
获得 。 本文不包含对神经网络体系结构,神经元原理,数学公式的描述。 在本文中,我们将它们用作工程工具,而无需过多介绍其设备的细节。
数据与方法
与任何数据驱动方法一样,神经网络解决方案也需要数据。 您也可以手动组装它们:捕获数百个计数器并使用
LabelImg对其进行标记 。 您可以在Yandex.Tolok上订购标记。
我们无法透露实际项目的细节,因此我们将在开放数据上解释该技术。 购物和照相太懒惰了(在那儿我们不会被理解),在第一百个分类对象之后,我自己对在互联网上找到的照片进行标记的愿望就结束了。 幸运的是,我偶然发现了
Grocery Dataset档案。
2014年,土耳其伊斯坦布尔的Idea Teknoloji员工上传了使用4个相机拍摄的354张来自40个商店的354张照片。 在每张照片上,他们都用矩形突出显示了总共数千个对象,其中一些被分为10类。
这些是香烟包装的图片。 我们不提倡或提倡吸烟。 没有什么比这更中立了。 我们保证,在情况允许的情况下,本文中的所有地方都将使用猫的照片。

除了标有货架的照片外,他们还写了一篇文章
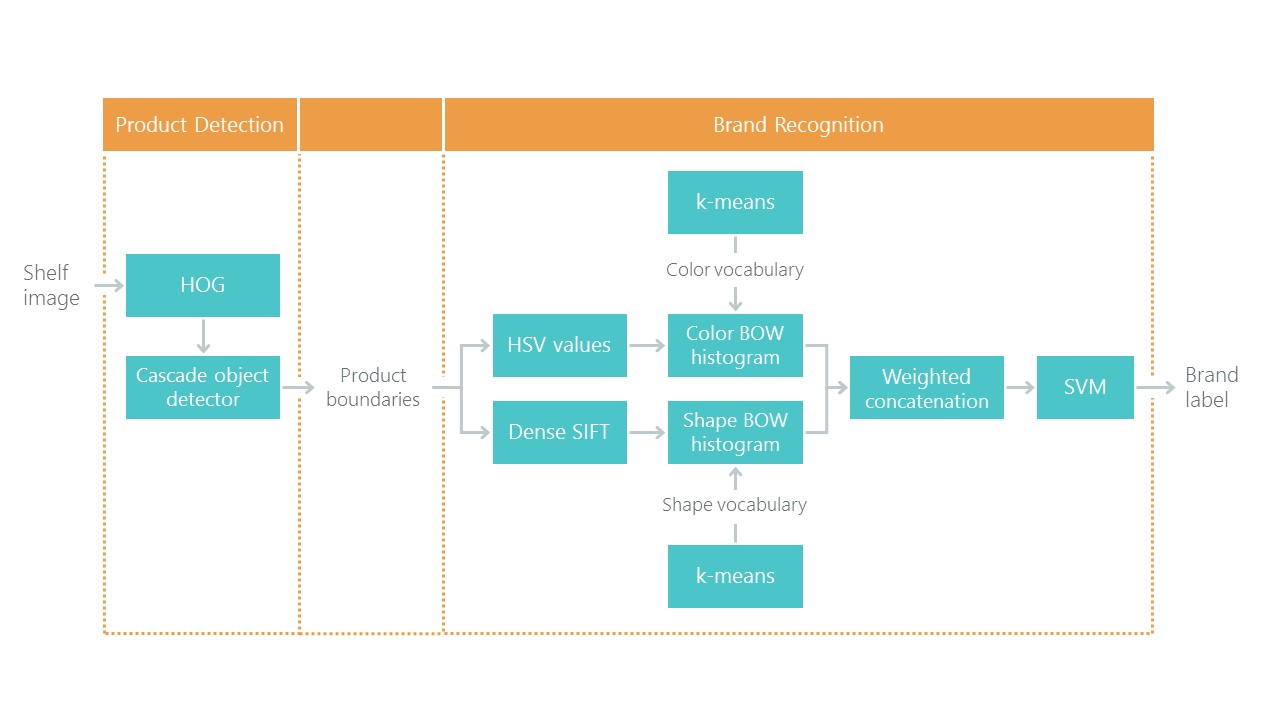
《在杂货货架上实现零售产品识别》 ,以解决本地化和分类问题。 这设置了一个参考点:我们使用新方法的解决方案应该变得更简单,更准确,否则就不会引起兴趣。 他们的方法由多种算法组成:
最近,卷积神经网络(CNN)彻底改变了计算机视觉领域,并彻底改变了解决此类问题的方法。 在过去的几年中,这些技术已为广泛的开发人员所采用,并且像Keras这样的高级API大大降低了其进入门槛。 现在,约会后几天,几乎所有开发人员都可以使用卷积神经网络的全部功能。 本文通过一个示例描述了这些技术的使用,展示了如何仅用两个神经网络就可以轻松替换整个算法级联而又不损失准确性。
我们将分步解决问题:
- 数据准备。 我们抽出档案并将其转换为方便工作的视图。
- 品牌分类。 我们使用神经网络解决分类问题。
- 在照片中搜索产品。 我们训练神经网络来搜索商品。
- 搜索实施。 我们将使用浮动窗口和用于抑制非最大值的算法来提高检测质量。
- 结论 简要解释为什么现实生活比这个例子要复杂得多。
技术领域
我们将使用的主要技术:Tensorflow,Keras,Tensorflow对象检测API,OpenCV。 尽管Windows和Mac OS均适用于Tensorflow,但我们仍然建议使用Ubuntu。 即使您以前从未使用过该操作系统,使用它也可以节省大量时间。 安装Tensorflow以与GPU一起使用是一个值得讨论的主题。 幸运的是,这些文章已经存在。 例如,
在具有Nvidia GPU的Ubuntu 16.04上安装TensorFlow 。 它的一些说明可能已过时。
步骤1.准备数据( github链接 )通常,此步骤比仿真本身要花费更长的时间。 幸运的是,我们使用现成的数据,将其转换为所需的形式。
您可以通过以下方式下载和解压缩:
wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part1.tar.gz wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part2.tar.gz tar -xvzf GroceryDataset_part1.tar.gz tar -xvzf GroceryDataset_part2.tar.gz
我们得到以下文件夹结构:
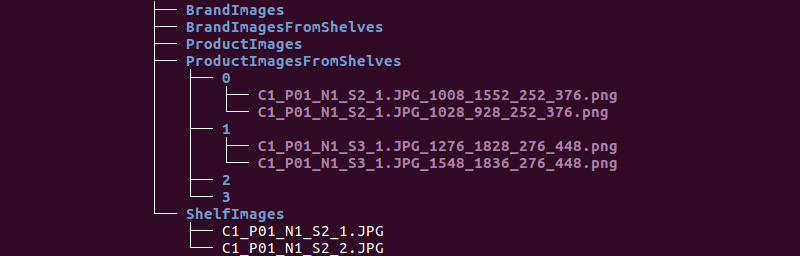
我们将使用ShelfImages和ProductImagesFromShelves目录中的信息。
ShelfImages包含货架本身的图片。 在名称中,使用图片的标识符对机架的标识符进行编码。 一个机架上可能有几张照片。 例如,一张完整的照片和五张带有交叉点的部分照片。
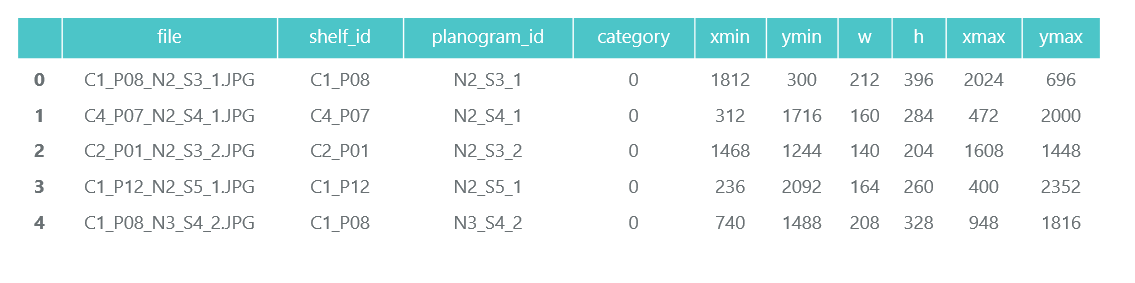
文件C1_P01_N1_S2_2.JPG(机架C1_P01,快照N1_S2_2):

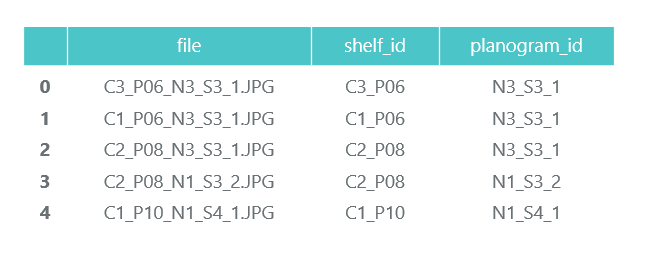
我们浏览所有文件,并在pandas数据帧photos_df中收集信息:
ProductImagesFromShelves包含11个子目录中货架上商品的剪裁照片:0-未分类,1-万宝路,2-肯特等。 为了不进行广告宣传,我们将仅使用类别编号而不指定名称。 名称中的文件包含有关机架,机架上包装的位置和大小的信息。
目录1中的文件C1_P01_N1_S3_1.JPG_1276_1828_276_448.png(类别1,机架C1_P01,图像N1_S3_1,左上角的坐标(1276,1828),宽度276,高度448):
我们不需要单独包装的照片(将它们从架子上的照片上剪下来),并且我们在熊猫数据框product_df中收集有关其类别和位置的信息:
在同一步骤中,我们将所有信息分为两个部分:培训培训和验证培训。 当然,在实际项目中不值得这样做。 也不要相信那些这样做的人。 您至少必须为最终测试分配另一个测试。 但是即使采用这种不太诚实的方法,对我们来说也不要自欺欺人很重要。
正如我们已经指出的,一个机架上可能有几张照片。 因此,同一包可能会分成几张图片。 因此,我们建议您不要按图片分类,更不要按包装分类,而应按架子分类。 这是必要的,这样就不会发生从不同角度截取的同一对象最终在训练和验证中都失败的情况。
我们进行70/30的分配(30%的机架用于验证,其余的用于培训):
我们将确保在拆分时,每个班级都有足够的代表进行培训和验证:

蓝色表示类别中的产品数量(用于验证),橙色表示培训中的产品数量。 对于类别3进行验证的情况不是很好,但是原则上很少有代表。
在数据准备阶段,重要的是不要犯错误,因为所有后续工作都基于其结果。 我们仍然犯了一个错误,并花了许多快乐的时光来尝试理解为什么模型的质量非常中等。 直到您不小心注意到一些原始照片被旋转了90度,而另一些却被倒置之后,它已经感觉像是“守旧派”技术的失败者。
同时,进行标记时就好像照片的方向正确一样。 快速修复后,事情变得更加有趣。
我们将数据保存在pkl文件中,以用于以下步骤。 总计,我们有:
- 带有捆绑物的机架及其零件的照片目录,
- 带有说明每个机架的数据框,并注明是否用于培训,
- 一个数据架,上面有货架上所有产品的信息,指示它们的位置,大小,类别并标记是否打算培训。
为了进行验证,我们根据我们的数据显示一个机架:
 步骤2.按品牌分类( github上的链接 )
步骤2.按品牌分类( github上的链接 )图像分类是计算机视觉领域的主要任务。 问题在于“语义鸿沟”:摄影只是数字[0,255]的大型矩阵。 例如800x600x3(3个RGB通道)。

为什么这个任务很困难:

正如我们已经说过的,我们使用的数据作者确定了10个品牌。 这是一个极其简化的任务,因为货架上有更多品牌的香烟。 但是所有未归入这10个类别的内容都被发送为0-未分类:

”
他们的文章提供了这样的分类算法,总准确性为92%:

我们将做什么:
- 我们将准备数据进行培训,
- 我们使用ResNet v1架构训练卷积神经网络,
- 检查照片以进行验证。
听起来“大声”,但是我们只是使用
了Keras的示例“
在CIFAR10数据集上训练ResNet ”,从中获得了创建ResNet v1的功能。
要开始训练过程,您需要准备两个阵列:x-具有尺寸(包装数量,高度,宽度,3)的包装照片和y-具有尺寸(包装数量10)的包装类别。 数组y包含所谓的1-hot向量。 如果一个训练包的类别具有数字2(从0到9),则它对应于矢量[0,0,1,0,0,0,0,0,0,0]。
一个重要的问题是如何处理宽度和高度,因为所有照片都是从不同距离以不同分辨率拍摄的。 我们需要选择一些固定的尺寸,以便将所有包装图片带到该尺寸上。 固定大小是确定我们的神经网络如何训练和工作的元参数。
一方面,我想使此尺寸尽可能大,以使图片的单个细节都不会被忽略。 另一方面,由于我们的训练数据量很少,这可能导致快速重新训练:该模型在训练数据上可以很好地工作,而在验证数据上效果不佳。 我们选择的尺寸为120x80,也许在其他尺寸上我们会得到更好的结果。 缩放功能:
缩放并显示一包以进行验证。 品牌名称很难让人理解,让我们看看神经网络将如何处理分类任务:

根据上一步获得的标志进行准备后,将x和y数组分解为x_train / x_validation和y_train / y_validation,我们得到:
x_train shape: (1969, 120, 80, 3) y_train shape: (1969, 10) 1969 train samples 775 validation samples
准备好数据后,我们从Keras示例中复制ResNet v1架构的神经网络构造函数的功能:
def resnet_v1(input_shape, depth, num_classes=10): …
我们构建一个模型:
model = resnet_v1(input_shape=x_train.shape[1:], depth=depth, num_classes=num_classes) model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=lr_schedule(0)), metrics=['accuracy'])
我们的数据集非常有限。 因此,为了防止模型在训练期间每次都看到同一张照片,我们使用增强:随机移动图片并稍微旋转一下。 Keras为此提供了以下选项集:
我们开始培训过程。
经过培训和评估,我们得出的准确度约为92%。 您可能会得到不同的精度:数据很少,因此精度在很大程度上取决于分区的成功程度。 在这个分区上,我们获得的准确度没有比本文中指出的要高得多,但实际上我们自己什么也不做,只写了很少的代码。 而且,我们可以轻松地添加一个新类别,并且,如果我们准备更多数据,则准确性(理论上)应该会大大提高。
感兴趣的话,比较混淆矩阵:
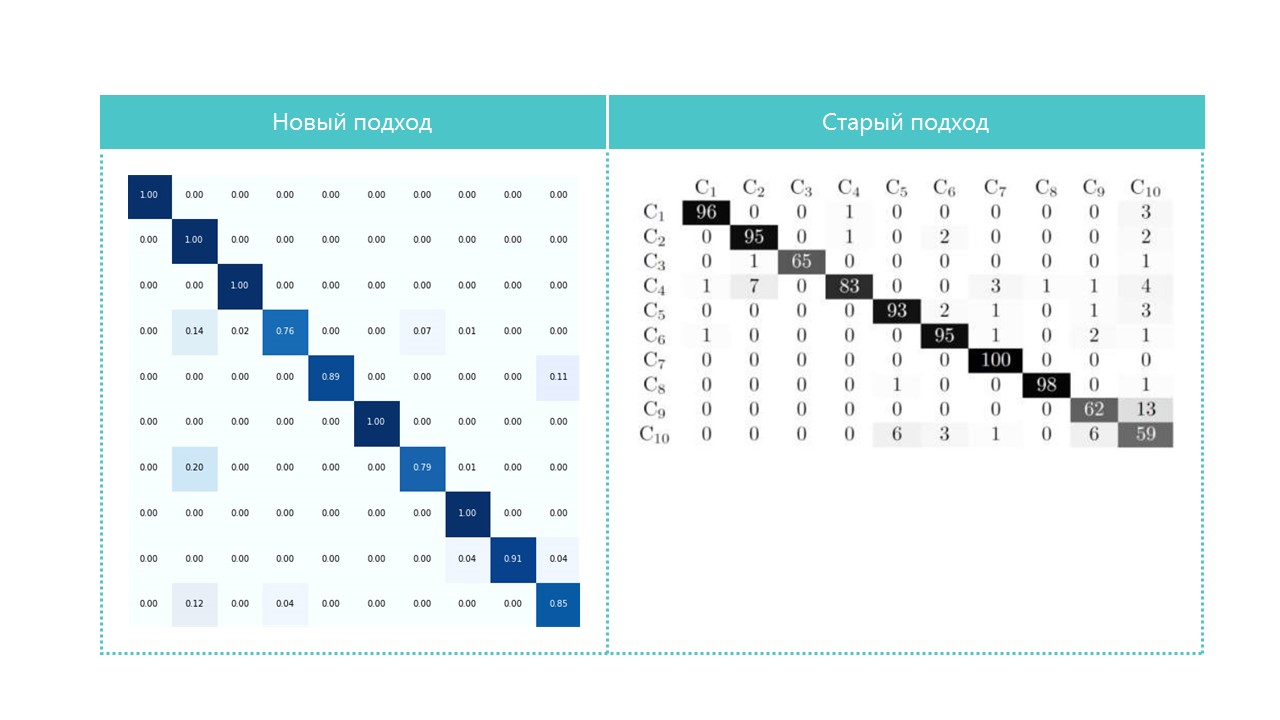
除了类别4和7,我们的神经网络几乎定义了所有类别。查看每个混淆矩阵单元的最亮代表也很有用:
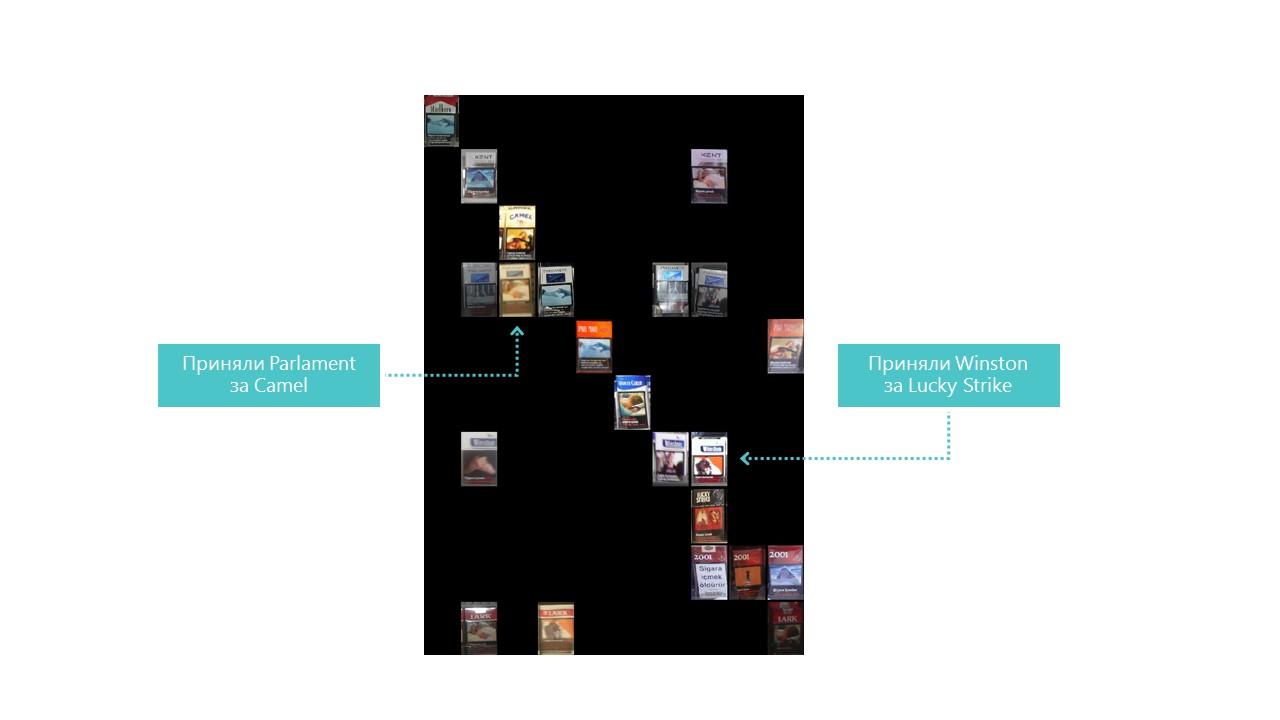
您也可以理解为什么国会误认为骆驼,但是为什么温斯顿误认为是幸运罢工,但这是完全不可理解的,但是它们之间没有任何共同点。 这是神经网络的主要问题-内部发生的事情完全不透明。 您当然可以可视化某些图层,但是对于我们来说,此可视化效果如下所示:

在我们的条件下提高识别质量的一个明显机会是添加更多照片。
因此,分类器已准备就绪。 转到检测器。
步骤3.在照片中搜索产品( github上的链接 )计算机视觉领域的以下重要任务是语义分割,本地化,对象搜索和实例分割。
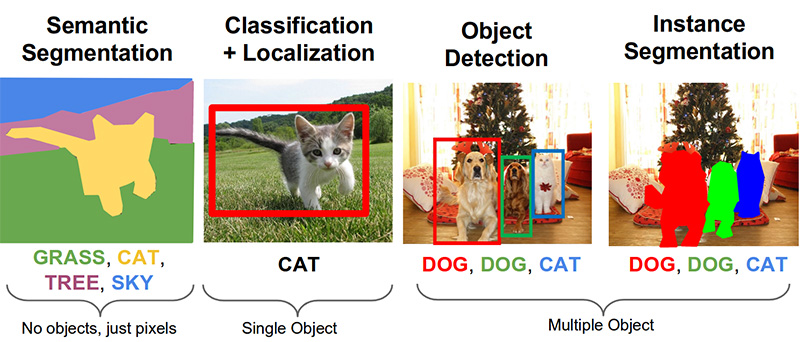
我们的任务需要对象检测。 2014年的文章提供了一种基于Viola-Jones和HOG方法且具有视觉准确性的方法:

由于使用了其他统计限制,因此它们的准确性非常好:

现在,借助神经网络成功地解决了对象识别的任务。 我们将使用Tensorflow对象检测API系统,并使用Mobilenet V1 SSD架构训练神经网络。 从头开始训练这样的模型需要大量数据,并且可能需要几天的时间,因此我们根据转移学习的原理使用了在COCO数据上训练的模型。
这种方法的关键概念是这样。 为什么孩子不需要展示数百万个物体,以便他学会从立方体中找到并区分一个球? 因为孩子有5亿年的视觉皮层发育。 进化使视觉成为最大的感觉系统。 人脑中几乎有50%(但这是不准确的)负责图像处理。 父母只能展示球和立方体,然后对孩子进行多次纠正,以使他能够完美地发现并区分彼此。
从哲学的角度(技术差异比一般差异大),神经网络中的转移学习以类似的方式工作。 卷积神经网络由多个层次组成,每个层次都定义了越来越复杂的形式:它识别关键点,将它们组合成线,然后组合成图形。 并且仅在找到的标记总数的最后一级确定对象。
现实世界中的对象有很多共同点。 在进行转移学习时,我们使用已经训练好的基本特征定义级别,并且仅训练负责识别对象的层。 为此,使用普通GPU的几百张照片和几个小时的操作就足够了。 该网络最初是在COCO(上下文中的Microsoft公共对象)数据集中进行训练的,该数据集包含91个类别和2,500,000个图像! 许多,尽管不是5亿年的演变。
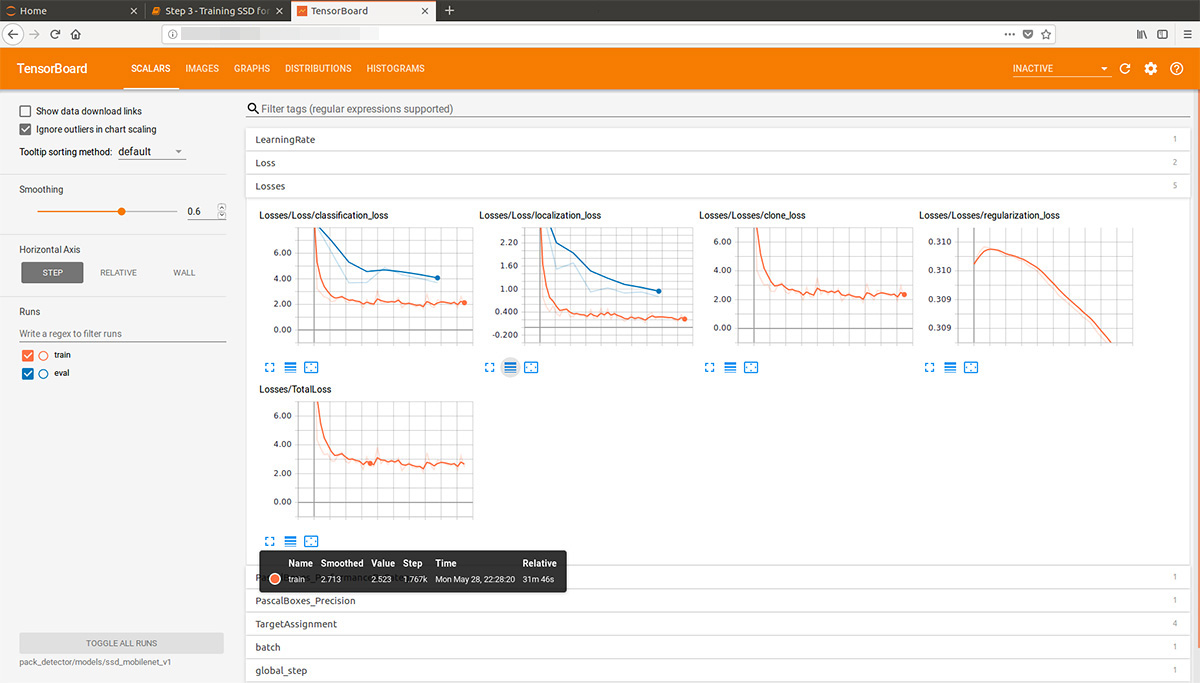
向前看,此张量板的gif动画(有点慢,不要立即滚动)使学习过程可视化。 如您所见,模型几乎立即开始产生完全高质量的结果,然后进行磨削:

Tensorflow对象检测API系统的“培训者”可以独立执行增强,裁剪图像的随机部分进行培训,并选择“阴性”示例(不含任何对象的照片部分)。 理论上,不需要照片预处理。 但是,在带有HDD和少量RAM的家用计算机上,他拒绝处理高分辨率图像:起初他挂了很长时间,用磁盘沙沙作响,然后飞了出去。
结果,我们将照片压缩为1000x1000像素,同时保持了宽高比。 但是由于压缩大照片时会丢失很多信号,因此先从机架的每张照片上切出随机大小的几个正方形,然后将其压缩为1000x1000。 结果,高分辨率(但不够)和小(但很多)的包装盒落入了训练数据。 我们重复一遍:此步骤是强制性的,很可能完全不必要,并且可能有害。
准备和压缩的照片分别保存在单独的目录(eval和train)中,其描述(包含捆绑包)以两个熊猫数据框(train_df和eval_df)的形式形成:
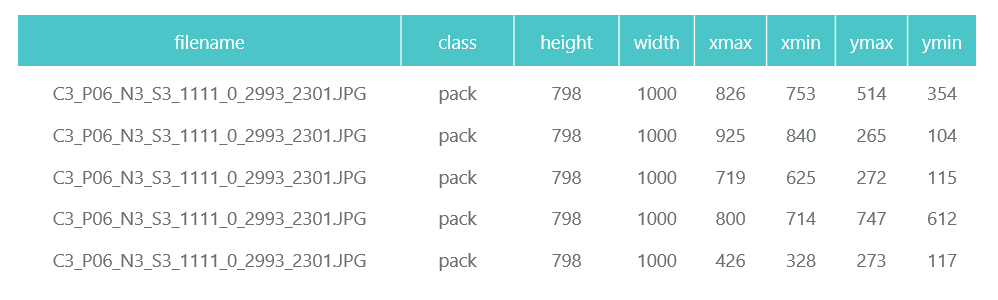
Tensorflow对象检测API系统需要将输入显示为tfrecord文件。 您可以使用实用程序来形成它们,但我们将其作为代码:
def class_text_to_int(row_label): if row_label == 'pack': return 1 else: None def split(df, group): data = namedtuple('data', ['filename', 'object']) gb = df.groupby(group) return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path): with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: encoded_jpg = fid.read() encoded_jpg_io = io.BytesIO(encoded_jpg) image = Image.open(encoded_jpg_io) width, height = image.size filename = group.filename.encode('utf8') image_format = b'jpg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] classes_text = [] classes = [] for index, row in group.object.iterrows(): xmins.append(row['xmin'] / width) xmaxs.append(row['xmax'] / width) ymins.append(row['ymin'] / height) ymaxs.append(row['ymax'] / height) classes_text.append(row['class'].encode('utf8')) classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': dataset_util.int64_feature(height), 'image/width': dataset_util.int64_feature(width), 'image/filename': dataset_util.bytes_feature(filename), 'image/source_id': dataset_util.bytes_feature(filename), 'image/encoded': dataset_util.bytes_feature(encoded_jpg), 'image/format': dataset_util.bytes_feature(image_format), 'image/object/bbox/xmin': dataset_util.float_list_feature(xmins), 'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs), 'image/object/bbox/ymin': dataset_util.float_list_feature(ymins), 'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs), 'image/object/class/text': dataset_util.bytes_list_feature(classes_text), 'image/object/class/label': dataset_util.int64_list_feature(classes), })) return tf_example def convert_to_tf_records(images_path, examples, dst_file): writer = tf.python_io.TFRecordWriter(dst_file) grouped = split(examples, 'filename') for group in grouped: tf_example = create_tf_example(group, images_path) writer.write(tf_example.SerializeToString()) writer.close() convert_to_tf_records(f'{cropped_path}train/', train_df, f'{detector_data_path}train.record') convert_to_tf_records(f'{cropped_path}eval/', eval_df, f'{detector_data_path}eval.record')
我们仍然需要准备一个特殊目录并启动流程:
结构可能有所不同,但我们发现它非常方便。
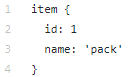
数据目录包含我们使用tfrecords(train.record和eval.record)创建的文件,以及带有我们将为其训练神经网络的对象类型的pack.pbtxt。 我们只有一种类型的对象要定义,因此文件很短:
ssd_mobilenet_v1子目录中的models目录(解决一个问题可以有许多模型)包含.config文件中用于训练的设置以及两个空目录:train和eval。 在训练中,“训练者”将保存模型控制点,“评估者”将其拾取,在数据上运行以进行评估,然后将其放入eval目录中。 Tensorboard将跟踪这两个目录并显示过程信息。
配置文件等的详细说明 可以在
这里和
这里找到。 Tensorflow对象检测API安装说明可在
此处找到。
我们进入models / research / object_detection目录,并缩小预先训练的模型:
wget http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2017_11_17.tar.gz tar -xvzf ssd_mobilenet_v1_coco_2017_11_17.tar.gz
我们在那里复制我们准备的pack_detector目录。
首先,开始培训过程:
python3 train.py --logtostderr \ --train_dir=pack_detector/models/ssd_mobilenet_v1/train/ \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config
我们开始评估过程。 我们没有第二张视频卡,因此我们在处理器上启动它(使用指令CUDA_VISIBLE_DEVICES =“”)。 因此,他在培训过程方面会很晚,但这还不错:
CUDA_VISIBLE_DEVICES="" python3 eval.py \ --logtostderr \ --checkpoint_dir=pack_detector/models/ssd_mobilenet_v1/train \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --eval_dir=pack_detector/models/ssd_mobilenet_v1/eval
我们开始张量板过程:
tensorboard --logdir=pack_detector/models/ssd_mobilenet_v1
之后,我们可以在估算数据上看到漂亮的图形以及模型的实际工作(开头是gif):
培训过程可以随时停止并恢复。 当我们认为模型足够好时,我们以推理图的形式保存检查点:
python3 export_inference_graph.py \ --input_type image_tensor \ --pipeline_config_path pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --trained_checkpoint_prefix pack_detector/models/ssd_mobilenet_v1/train/model.ckpt-13756 \ --output_directory pack_detector/models/ssd_mobilenet_v1/pack_detector_2018_06_03
因此,在此步骤中,我们获得了一个推理图,可用于搜索捆绑对象。 我们继续使用它。
步骤4.实现搜索( github链接 )推理图加载和初始化代码在上面的链接中。 关键搜索功能:
该功能不是在整个照片中而是在部分中找到包装的有界框。 该功能还可以过滤掉在cutoff参数中指定的检测得分较低的矩形。
事实证明这是一个难题。 一方面,在高截止值时,我们丢失了很多对象;另一方面,在低截止值时,我们开始发现很多非捆绑对象。 同时,我们仍然找不到所有内容,也不是理想情况:

但是,请注意,如果我们对一小张照片运行该功能,则截止值= 0.9时,识别效果几乎是完美的:

这是因为MobileNet V1 SSD型号接受300x300张照片作为输入。 自然地,通过这种压缩,许多信号消失了。
但是,如果我们切出一个包含几包的小方块,这些迹象仍然存在。 这暗示了使用浮动窗口的想法:我们在照片中穿过一个小矩形并记住我们发现的所有内容。
 出现一个问题:我们多次发现相同的包装,有时甚至是截短的包装。这个问题可以借助非最大抑制算法来解决。这个想法非常简单:第一步,我们找到一个具有最高检测得分的矩形,记住它,删除所有其他具有相交区域而不是overlayTresh的矩形(该实现在Internet上进行了很小的更改):
出现一个问题:我们多次发现相同的包装,有时甚至是截短的包装。这个问题可以借助非最大抑制算法来解决。这个想法非常简单:第一步,我们找到一个具有最高检测得分的矩形,记住它,删除所有其他具有相交区域而不是overlayTresh的矩形(该实现在Internet上进行了很小的更改):
结果在视觉上几乎是完美的: 处理大量包装的劣质照片的结果:
处理大量包装的劣质照片的结果: 如我们所见,物体的数量和照片的质量并不能阻止我们正确识别所有包装,这正是我们的目标。
如我们所见,物体的数量和照片的质量并不能阻止我们正确识别所有包装,这正是我们的目标。结论
在我们的文章中,这个例子很“玩具”:数据作者已经收集了它们,期望他们将不得不使用它们进行识别。因此,仅在正常照明下拍摄了好的照片,而不是在一定角度下等。现实生活更加丰富。我们无法透露实际项目的详细信息,但是这里有一些我们必须克服的困难:- 需要找到和分类的产品约有150种,以及标签,
- 这些类别几乎都有3-7种设计风格,
- 通常,一张图片中包含100多种产品,
- 有时,无法在一张照片中拍摄架子的照片,
- 照明不佳和背光卖家(霓虹灯)
- 玻璃后面的产品(眩光,摄影师的反光),
- 如果摄影师没有足够的空间来拍摄全脸照片,则可以从广角拍摄照片,
- 征收货物,以及货物接近交割的情况(SSD无法应付),
- 下层货架上的产品变形严重,光线不足,
- 定制货架。
所有这些都极大地改变了数据准备,训练和所用神经网络的架构并使之复杂化,但这并不会阻止我们。