 AI翻译如何学习生成猫的图片
AI翻译如何学习生成猫的图片 。
生成对抗网络 (GAN)于2014年发布,是生成模型领域的一项突破。 首席研究员Yann Lekun称对抗网络为“过去20年来机器学习的最佳构想”。 今天,借助这种架构,我们可以创建可生成逼真的猫图像的AI。 好酷!
 培训期间的DCGAN
培训期间的DCGAN所有工作代码都在
Github存储库中 。 如果您具有Python编程,深度学习,使用Tensorflow和卷积神经网络的经验,这将对您很有用。
如果您是深度学习的新手,我建议您熟悉
机器学习很有趣的出色文章系列
!什么是DCGAN?
深度卷积生成对抗网络(DCGAN)是一种深度学习架构,其生成的数据类似于训练集中的数据。
该模型用卷积层代替了生成对抗网络的完全连接层。 为了了解DCGAN的工作原理,我们使用专家艺术评论家和伪造者之间对抗的隐喻。
伪造者(“发电机”)正在尝试创建假梵高图片并将其作为真实图片传递。
一位艺术评论家(“歧视者”)试图利用对梵高真实画布的了解,对伪造者定罪。
随着时间的流逝,艺术评论家越来越多地定义假货,而伪造者则使它们更加完美。
 如您所见,DCGAN由相互竞争的两个单独的深度学习神经网络组成。
如您所见,DCGAN由相互竞争的两个单独的深度学习神经网络组成。- 生成器正在尝试创建可信的数据。 他不知道真实的数据是什么,但是他从敌人的神经网络的响应中学习,每次迭代都会改变他的工作结果。
- 鉴别器试图确定假数据(与真实数据比较),从而尽可能避免相对于真实数据的误报。 该模型的结果是生成器的反馈。
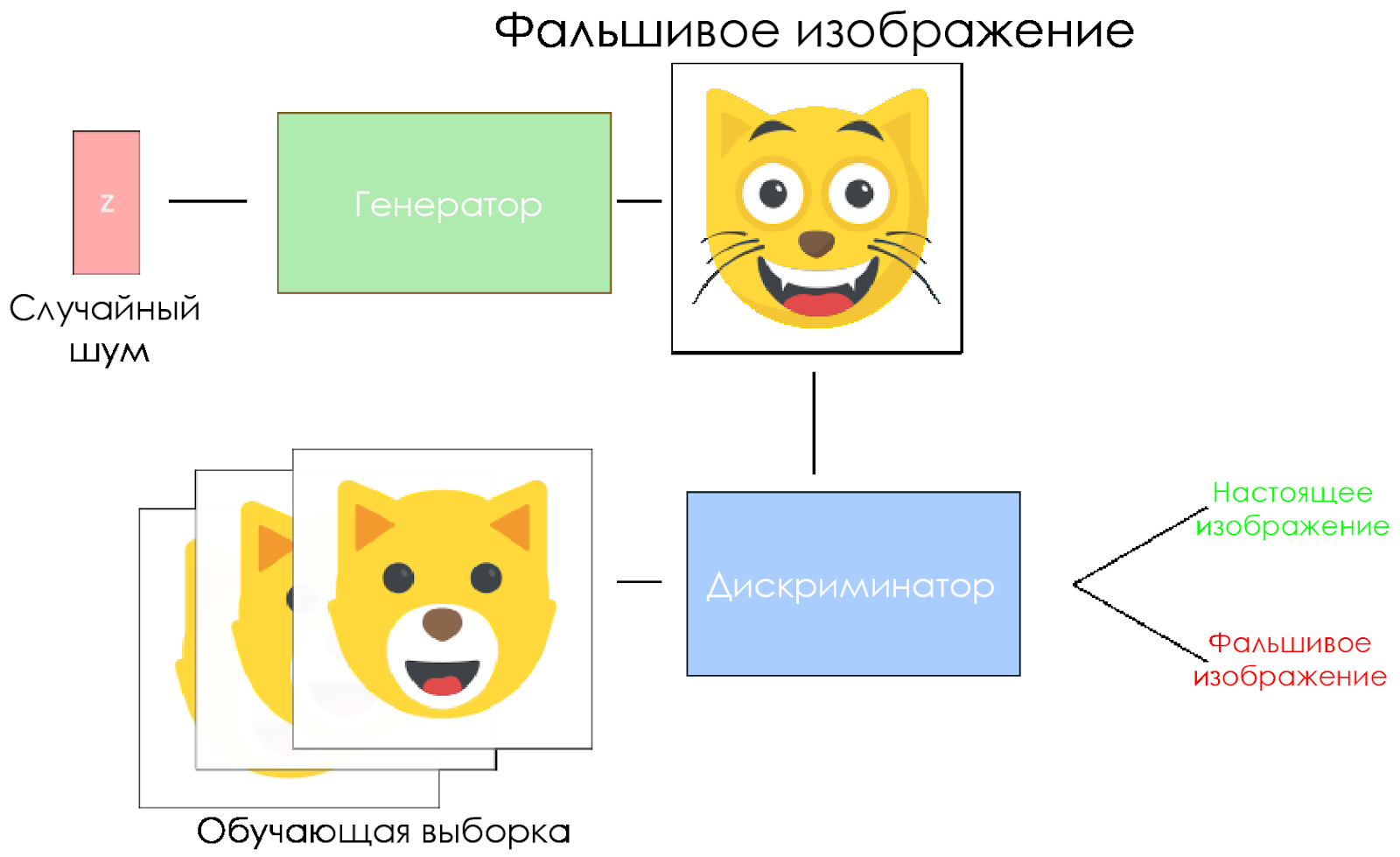 DCGAN模式。
DCGAN模式。- 生成器获取随机噪声矢量并生成图像。
- 将图像提供给鉴别器,他将其与训练样本进行比较。
- 鉴别符返回一个数字-0(伪)或1(真实图像)。
让我们创建一个DCGAN!
现在我们准备创建自己的AI。
在这一部分中,我们将专注于模型的主要组成部分。 如果您想查看整个代码,请转到
此处 。
输入数据
为输入创建存根:对于鉴别
inputs_z为
inputs_z ,对于生成器为
inputs_z 。 请注意,我们将有两种学习率,分别用于生成器和鉴别器。
DCGAN对超参数非常敏感,因此微调它们非常重要。
def model_inputs(real_dim, z_dim): """ Create the model inputs :param real_dim: tuple containing width, height and channels :param z_dim: The dimension of Z :return: Tuple of (tensor of real input images, tensor of z data, learning rate G, learning rate D) """
鉴别器和发生器
我们使用
tf.variable_scope有两个原因。
首先,确保所有变量名都以generator / discriminator开头。 稍后这将帮助我们训练两个神经网络。
其次,我们将使用不同的输入数据重用这些网络:
- 我们将训练生成器,然后对它生成的图像进行采样。
- 在鉴别器中,我们将共享伪造和真实输入图像的变量。

让我们创建一个鉴别器。 请记住,作为输入,它会拍摄真实或伪造的图像并作为响应返回0或1。
一些注意事项:
- 我们需要在每个卷积层中将滤波器大小加倍。
- 不建议使用下采样。 相反,仅剥离的卷积层适用。
- 在每一层中,我们使用批处理归一化(输入层除外),因为这会减少协方差漂移。 在这篇精彩的文章中阅读更多内容 。
- 我们将使用Leaky ReLU作为激活函数,这将有助于避免“消失”梯度的影响。
def discriminator(x, is_reuse=False, alpha = 0.2): ''' Build the discriminator network. Arguments --------- x : Input tensor for the discriminator n_units: Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out, logits: ''' with tf.variable_scope("discriminator", reuse = is_reuse):
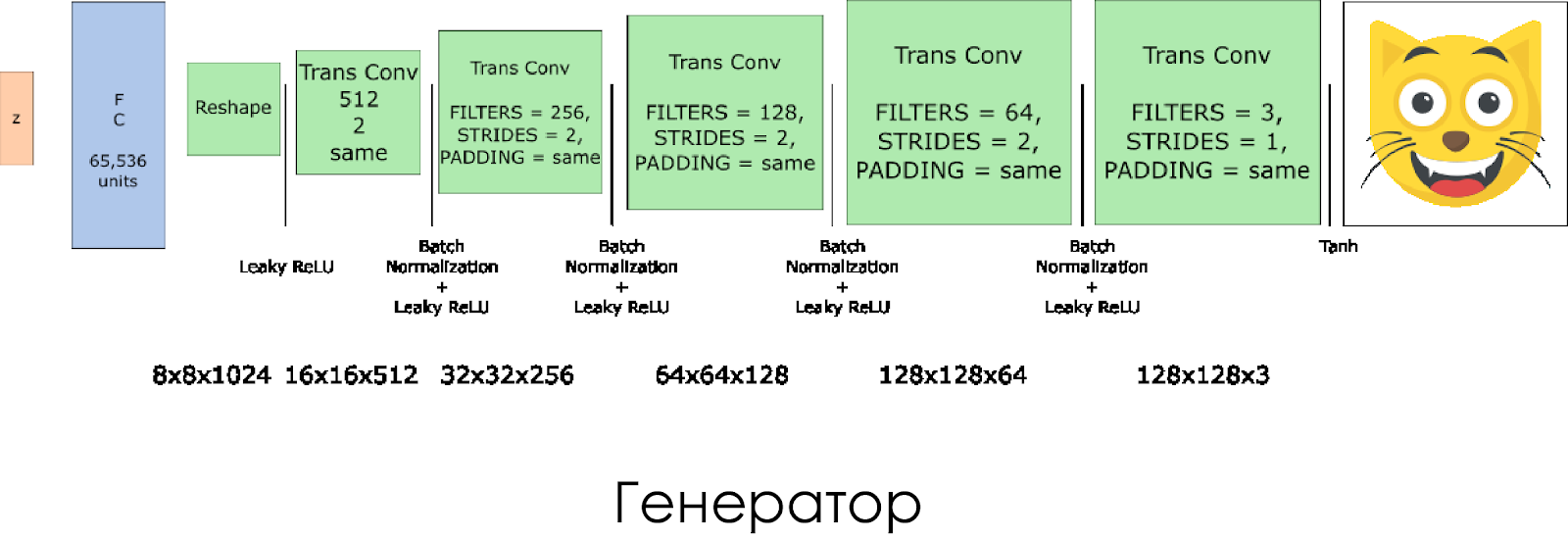
我们创建了一个生成器。 请记住,它以噪声矢量(z)作为输入,并且由于转置了卷积层,因此创建了伪图像。
在每一层上,我们将滤镜的尺寸减半,并且将图像的尺寸加倍。
当使用
tanh作为输出激活功能时,发生器工作得最好。
def generator(z, output_channel_dim, is_train=True): ''' Build the generator network. Arguments --------- z : Input tensor for the generator output_channel_dim : Shape of the generator output n_units : Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out: ''' with tf.variable_scope("generator", reuse= not is_train):
鉴别器和发生器的损失
由于我们同时训练了生成器和鉴别器,因此我们需要计算两个神经网络的损耗。 辨别器在“认为”图像为真实图像时应给出1,而在图像为假图像时应给出0。 按照这一点,您需要配置损失。 辨别器损耗计算为真实和伪造图像的损耗之和:
d_loss = d_loss_real + d_loss_fake其中
d_loss_real是鉴别器认为图像为假的损失,但实际上它是真实的。 计算公式如下:
- 我们使用
d_logits_real ,所有标签都等于1(因为所有数据都是真实的)。 labels = tf.ones_like(tensor) * (1 - smooth) 。 让我们使用标签平滑处理:将标签值从1.0降低到0.9,以帮助区分器更好地泛化。
当鉴别器认为图像是真实的时,
d_loss_fake是一种损失,但实际上它是伪造的。
- 我们使用
d_logits_fake ,所有标签均为0。
要丢失生成器,
d_logits_fake使用鉴别器中的
d_logits_fake 。 这次,所有标签均为1,因为生成器要欺骗鉴别器。
def model_loss(input_real, input_z, output_channel_dim, alpha): """ Get the loss for the discriminator and generator :param input_real: Images from the real dataset :param input_z: Z input :param out_channel_dim: The number of channels in the output image :return: A tuple of (discriminator loss, generator loss) """
优化器
计算损失后,必须分别更新生成器和鉴别器。 为此,请使用
tf.trainable_variables()创建一个图表中定义的所有变量的列表。
def model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1): """ Get optimization operations :param d_loss: Discriminator loss Tensor :param g_loss: Generator loss Tensor :param learning_rate: Learning Rate Placeholder :param beta1: The exponential decay rate for the 1st moment in the optimizer :return: A tuple of (discriminator training operation, generator training operation) """
培训课程
现在我们执行训练功能。 这个想法很简单:
- 我们每五个周期(时代)保存一次模型。
- 我们每10个经过训练的批次将图片保存在包含图像的文件夹中。
- 每15个周期我们显示
g_loss , d_loss和生成的图像。 这是因为Jupyter笔记本电脑在显示太多图片时可能会崩溃。 - 或者我们可以通过加载保存的模型直接生成真实图像(这将节省20个小时的训练)。
def train(epoch_count, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, get_batches, data_shape, data_image_mode, alpha): """ Train the GAN :param epoch_count: Number of epochs :param batch_size: Batch Size :param z_dim: Z dimension :param learning_rate: Learning Rate :param beta1: The exponential decay rate for the 1st moment in the optimizer :param get_batches: Function to get batches :param data_shape: Shape of the data :param data_image_mode: The image mode to use for images ("RGB" or "L") """
怎么跑
如果您准备等待10年,那么所有这些操作都可以在您的计算机上运行,因此最好使用基于云的GPU服务,例如AWS或FloydHub。 我个人在Microsoft Azure及其
深度学习虚拟机上对DCGAN进行了20小时的培训。 我与Azure没有业务关系,就像他们的客户服务一样。
如果您在虚拟机上运行有任何困难,请参阅这篇精彩的
文章 。
如果您改进模型,请随时提出请求。
