前言
到目前为止,这里描述的PHP trie实现使字典太胖了,因此需要相当长的时间才能加载到内存中,这使它的工作速度相当不错。 搜索速度为每秒8万个单词。 该词典由opencorpora.org词典的词条清单组成,包含389844个单词。 在未压缩形式下,字典的大小约为150mb,而压缩后的gzip约为6mb。 但是,相当不错的性能结果证明,在纯PHP中,您可以创建功能齐全的trie前缀树。
我事先要求程序员与文学评论家联系,不要写恶意评论。 像我本人一样,这篇文章应该对初学者很有趣。 懒得阅读,您可以立即在
github上查看代码。
一切如何开始
一段时间以来,我一直在构思为PHP项目编写形态分析器的想法,该分析器将能够快速对给定单词进行形态分析,并将单词转换为所需的形态。
PHP已经有一个类似的名为phpmorhy的库。 它的工作速度非常快,我会使用它并且不会发明任何东西,但是其中的字典编译器是作为独立的非PHP应用程序制作的,这使我无法使用此库。 该库本身是在期待已久的AOT词典的基础上构建的,这进一步降低了其实用性。
几周又几个月后,我读
了 Khabrovchanin
的一篇文章 ,然后阅读
了 I. Segalovich
的一篇关于搜索引擎的快速形态算法
的文章 ,然后读
了许多不同的文章。
一点一点地,我已经成熟了,
用二十一点和形态分析仪
的骨头来编写自己的
lunapark 。 我认为:“
好吧,进步已经向前发展,在PHP中您已经可以解析人类基因组! ”
我使用了opencorpora.org字典,将其放在mysql中,并获得了每秒2千个单词的搜索速度。 我认为有必要将字典加载到内存中。 事实证明,要使PHP中的常规数据结构(如数组或对象)可用,您需要存储约3 GB的RAM和300万个字典。 我遇到的所有php trie实现都仅适合作为演示工作逻辑的教程,因为它们本身是基于本机PHP数据存储结构构建的。
词典存储装置及其工作原理
无论我在哪里可以阅读,收听或查看trie前缀树,都无法确切解释数据将如何存储在内存中。 这里有个结,这里是它的继承人,这里是单词结尾的标志,没有在引擎盖下显示。 因此,我不得不自己发明一种存储方法。
如您所知,特里前缀树由节点组成。 节点存储一个前缀,到后续节点(后代)的链接以及一个指向该前缀是链中最后一个事实的指针。 印第安人对特里说得很清楚。
我的trie实现中的节点是固定长度154字节的数据块。 前6个字节(48位)包含继承人的位掩码。 前46位是俄语字母,数字,引号,连字符和撇号。 添加了撇号是因为在opencorpora.org词典中有一个单词“ cote d'ivoire”,使用了撇号。 第47位用于存储单词结束标志。 位掩码后的以下148个字节用于存储对节点继承人的引用。 每个字符3个字节(46 * 3 = 148)。
节点以二进制数据形式存储在字符串中。 使用substr()函数以及随后的unpack()拆包访问所需的部分。
使用固定长度的节点可简化寻址过程。 要切换到所需的节点,只需知道其序列号(id)和节点的长度即可。 我们将序列号乘以长度,然后找出相对于行首的偏移量-一切都很简单。
无花果 1个存储方案
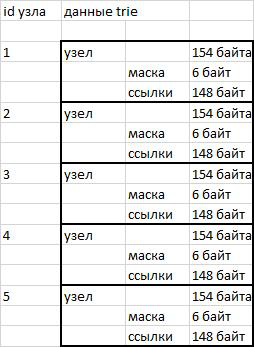
缺点
使用的存储方案可以简化寻址,但是会占用空间。 存储38万个单词需要超过一百万个节点。 154字节* 1,000,000节点= 146.86兆字节 即 每个字大约400个字节。 如果将单词写在以utf8编码的简单文本文件中,则这些相同的38万个单词可以容纳16兆字节。
计划
为了更合理地使用内存,我想切换到可变长度的节点,然后作为链接,我必须记录节点ID,而不是字节数。 到期望节点的链接的位置将如下确定。 以单词“ abv”为例。
字母“ a”是字母表中的第一个字母,因此,它的节点也分别是第一个偏移量为0的节点。从0开始读取6个字节。
$str = substr($dic, 0, 6);
打开包装线:
$mask = (ord($str[5]) << 40) + (ord($str[4]) << 32) + (ord($str[3]) << 24) + (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
我们看一下第二位的掩码(字母“ b”)
bit_get($mask, 2);
设置该位后,现在我们将掩码中的提升位的数量计数为2。假设在我们的节点上字母“ a”的位也被提升,因此字母“ b”的位将是第二个提升的位。 计算偏移量以读取链接
$offset = 6 + 3;
第一个链接占用6个字节的掩码+ 3个字节,结果是9个字节。 我们读取了所需的字符串。
$str = substr($dic, $offset, 3);
解压缩链接:
$ref = (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
转到下一个节点,然后再次重复所有操作。 在最后一个字母中,我们检查掩码中是否存在47位,如果设置了该位,则在trie中有一个搜索词。
我希望可以保持每秒至少5万个单词的速度。
致谢
我要感谢nulled.cc和php.ru论坛的参与者对按位函数的帮助。