斯坦福大学的科学家们有关模因发生器发明的
新闻 (+
研究 )促使我写了一篇文章。 在我的文章中,我将尝试表明,您无需成为斯坦福大学的科学家即可使用神经网络做有趣的事情。 在文章中,我描述了2017年我们如何在大约30,000文本的正文上训练神经网络,并迫使其产生新的互联网模因和单词的社会学意义上的模因(通信符号)。 我们描述了我们使用的机器学习算法,遇到的技术和管理困难。
关于我们如何想到神经书写器的概念及其确切构成的一些背景知识。 在2017年,我们为一个Vkontakte公共网站创建了一个项目,该名称和屏幕快照被Habrahabr主持人禁止发布,并被提及为“自我”公关。 自2013年以来,Public便成立了,它的统一思想是通过一条线分解幽默,并用“ @”符号分隔各行:
@
@
行数可以变化,图可以是任意的。 通常,这是关于现实的猖ramp事实的幽默或敏锐的社会注解。 通常,这种设计称为“ buhurt”。
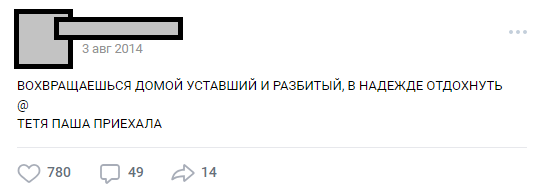 典型的buhurt之一
典型的buhurt之一多年来,公众已成长为内部角色(人物,地块,位置),职位数量已超过30,000。在为项目需求进行解析时,文本的源代码行数量已超过50万。
第0部分。想法和团队的出现
随着神经网络的广泛普及,在我们的文本中训练ANN的想法大约持续了六个月,但最终于2016年12月使用E7su提出。同时,这个名字也被发明出来(“ Neurobugurt”)。 当时,对该项目感兴趣的团队只有三个人。 我们都是没有算法和神经网络实践经验的学生。 更糟糕的是,我们甚至没有一个适合训练的GPU。 我们所拥有的只是热情和信心,这个故事可能很有趣。
第1部分。假设和任务的表述
我们的假设是这样的假设:如果您混合了三年半以上发布的所有文本并在该建筑物上训练神经网络,则可以得到:
a)比人更有创造力
b)好笑
即使buhurt中的单词或字母被机器弄乱并随机排列-我们相信这可以作为爱好者服务,并且仍将使读者满意。
由于Buhurts的格式实质上是文本的,因此大大简化了任务。 因此,我们无需沉迷于机器视觉和其他复杂的事物。 另一个好消息是,整个文本非常相似。 这使得至少在早期阶段不使用强化学习成为可能。 同时,我们清楚地了解到,创建一个具有多个可读输出的神经网络编写器并不是那么容易。 生下一个会随机扔字母的怪物的风险非常大。
第2部分。准备正文
据认为,准备阶段可能需要很长时间,因为它与数据的收集和清理相关。 在我们的案例中,结果非常短:编写了一个小型
解析器 ,从社区墙上抽出了约3万个帖子,并将它们放入
txt文件中 。
在第一次训练之前,我们没有清除数据。 将来,这与我们开了一个残酷的玩笑,因为在此阶段出现的错误使我们无法长时间将结果转化为可读的形式。 但是稍后会更多。
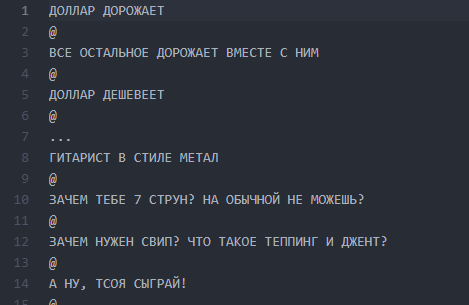 屏幕文件与汉堡
屏幕文件与汉堡第3部分。公告,假设的完善,算法的选择
我们使用了可访问的资源-大量的公共订户。 假设在300,000位读者中,有几位狂热者拥有足够水平的神经网络来填补我们团队知识的空白。 我们从广泛宣布比赛并吸引机器学习爱好者的想法开始,来讨论所提出的问题。 编写完文字后,我们向人们介绍了我们的想法,并希望得到答复。
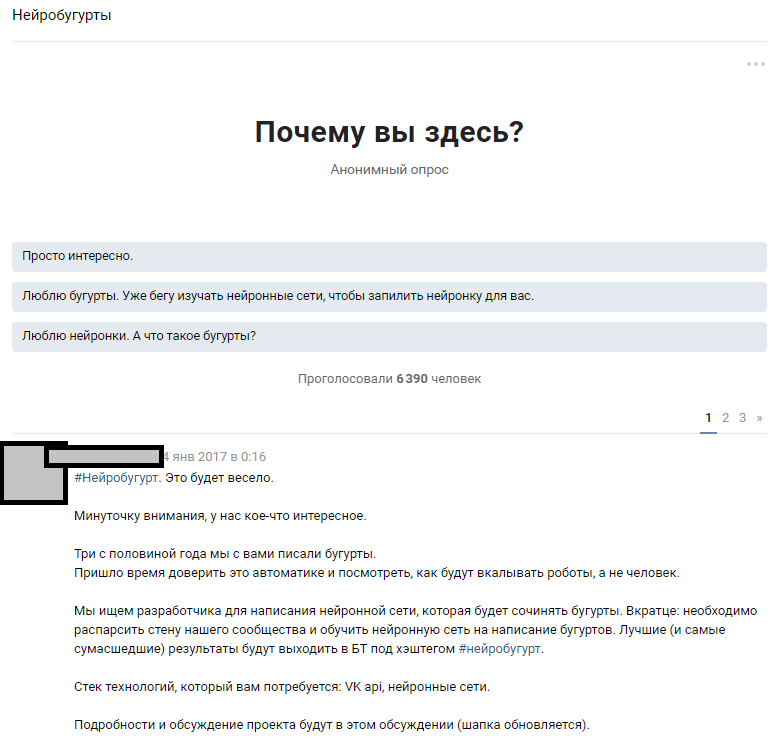 专题讨论公告
专题讨论公告人们的反应超出了我们最疯狂的期望。 关于我们将要训练神经网络这一事实的讨论,使holivar传播了近1000条评论。 大多数读者只是淡入淡出,试图想象结果会是什么样子。 大约有6,000人参加了主题讨论,有50多个感兴趣的业余爱好者发表了意见,我们为此提供了
814个布儒线的测试套件,用于进行初步测试和培训。 每个感兴趣的人都可以获取数据集并学习对他来说最有趣的算法,然后与我们和其他爱好者进行讨论。 我们事先宣布,我们将继续与那些结果最容易理解的参与者合作。
工作开始了:有人默默地在Markov链上组装了一个生成器,有人用github尝试了各种实现,而大多数人在讨论中发疯了,并以泡沫说服了我们一切都没有了。 这开始了项目的技术部分。
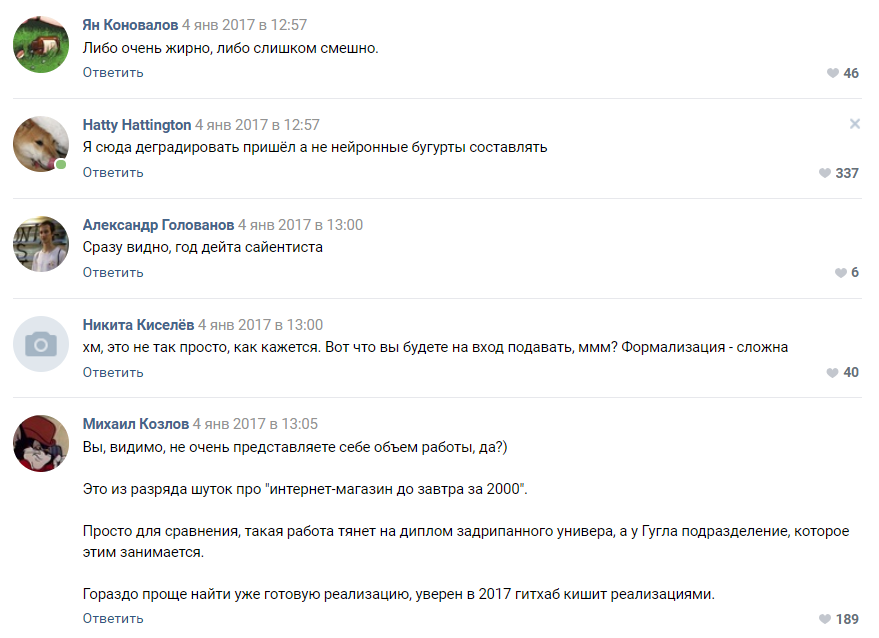
爱好者的一些建议
人们提供了许多实施方案:
- 马尔可夫链。
- 查找类似于GitHub的现成实现并对其进行培训。
- 用Pascal编写的随机短语生成器。
- 找一位会写随机废话的文学黑人,我们将把它作为神经网络输出传递出去。
 一位订户评估项目的复杂性
一位订户评估项目的复杂性大多数评论家都认为我们的项目注定要失败,我们甚至都不会达到原型阶段。 正如我们稍后所理解的,人们仍然倾向于将神经网络视为发生在“扎克伯格的头”和Google秘密部门中的某种黑魔法。
第4部分。算法选择,培训和团队扩展
一段时间后,我们发起的针对算法的众包想法的运动开始初见成效。 我们获得了大约30个可运行的原型,其中大多数都发出了完全不可读的废话。
在这个阶段,我们首先遇到了团队的动力不足。 所有结果都与Buhurts几乎没有相似之处,并且最经常代表字母和符号的圣像。 数十名发烧友的工作尘土飞扬,这使他们和我们都感到沮丧。
基于pyTorch的算法比其他算法表现得更好。 决定以这种实现方式和LSTM算法为基础。 我们认识到提出它的用户是获奖者,并开始与他一起改进算法。 我们的分布式团队已发展到四个人。 有趣的是,事实证明
比赛的
获胜者只有16岁。 胜利是他在数据科学领域的第一个真正的奖项。
第一次培训时,租用了8个GXT1080图形卡集群。
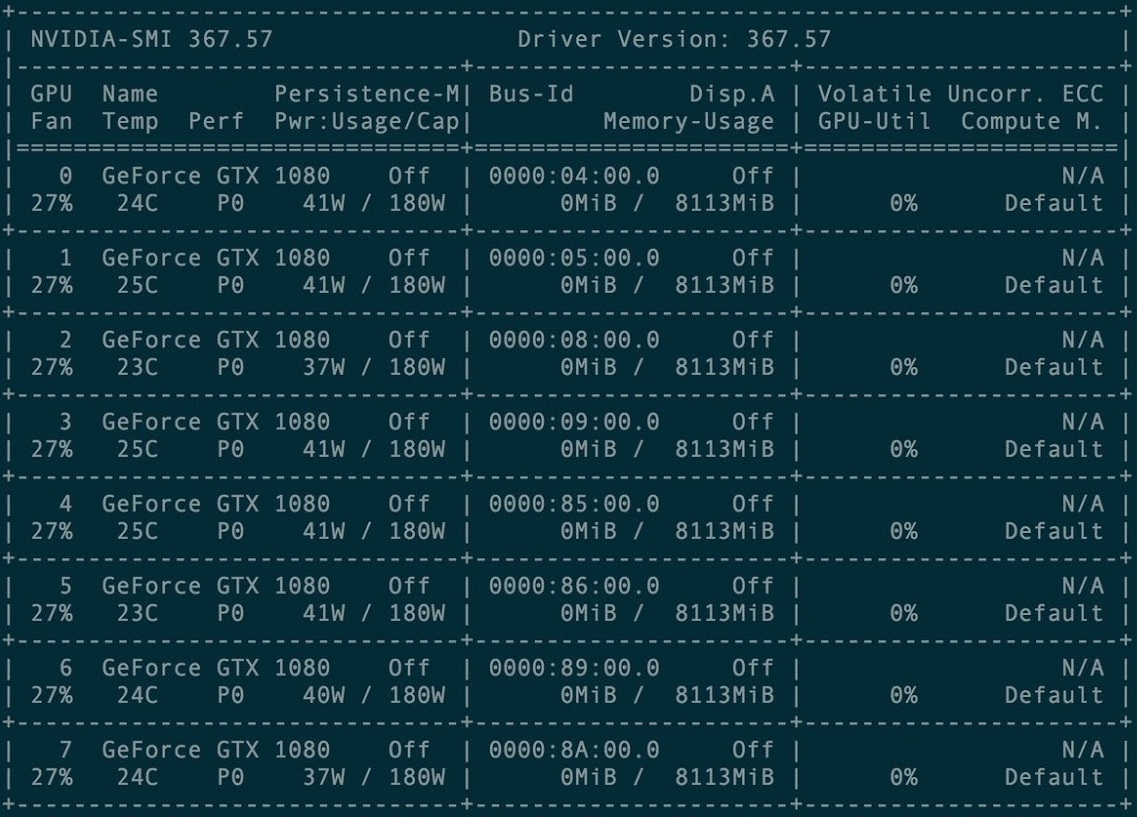 卡集群管理控制台
卡集群管理控制台原始存储库和所有Torch-rnn项目手册都在这里:
github.com/jcjohnson/torch-rnn 。 后来,在此基础上,我们发布
了存储库 ,其中包含我们的资源(用于安装的自述文件)以及完成的神经错误本身。
头几次,我们在付费的GPU集群上使用预配置的配置进行了培训。 设置它并不是一件容易的事-仅包含Torch开发人员的说明和托管管理人员的帮助(包括在付款中)就足够了。
但是,很快我们就遇到了困难:每次培训都花了GPU租赁时间-这意味着该项目根本没有钱。 因此,我们在2017年1月至2月对购买的设备进行了培训,并尝试在本地计算机上启动发电。
任何文本都适合模型训练。 在训练之前,您需要对其进行预处理,为此Torch具有特殊的preprocess.py算法,该算法会将my_data.txt转换为两个文件:HDF5和JSON:
预处理脚本的运行方式如下:
python scripts/preprocess.py \ --input_txt my_data.txt \ --output_h5 my_data.h5 \ --output_json my_data.json
 预处理后,将出现两个文件,将来将在该文件上训练神经网络这里
预处理后,将出现两个文件,将来将在该文件上训练神经网络这里描述
了可以在预处理阶段更改的各种标志。 也可以
从Docker运行
Torch ,但本文的作者未对其进行检查。
神经网络训练
预处理之后,您可以继续训练模型。 在带有HDF5和JSON的文件夹中,您需要运行th实用程序,如果正确安装了Torch,该实用程序将随您出现:
th train.lua -input_h5 my_data.h5 -input_json my_data.json
训练会花费大量时间,并会生成cv / checkpoint_1000.t7格式的文件,这些文件是神经网络的“权重”。 这些文件的兆字节数量惊人,包含原始数据集中特定字母之间的链接强度。
 通常将神经网络与人脑进行比较,但在我看来,数学函数的类比更为清晰,该数学函数在输入端(您的数据集)获取参数并在输出端给出结果(新数据)。
通常将神经网络与人脑进行比较,但在我看来,数学函数的类比更为清晰,该数学函数在输入端(您的数据集)获取参数并在输出端给出结果(新数据)。在我们的案例中,在500,000条数据集中的8 GTX 1080群集上进行的每次培训大约需要一两个小时,而在一种CPU i3-2120上进行的类似培训大约需要80-100个小时。 在更长的训练情况下,神经网络开始严格地重新训练-符号之间经常相互重复,陷入介词,连词和介绍性单词的长循环中。
您可以方便地选择检查点的频率,并且在一次培训中,您将立即获得许多模型:从训练最少的(checkpoint_1000)到重新训练的(checkpoint_1000000)。 仅足够的空间就足够了。
新文本生成
收到至少一个带有权重的现成文件(检查点_ *******)后,您可以进入下一个也是最有趣的阶段:开始生成文本。 对我们而言,这是真实的真实时刻,因为我们第一次获得了切实的成果-由机器编写的错误。
在这一点上,我们最终停止使用集群,并且所有世代都在我们的低功率机器上进行。 但是,当尝试在本地启动时,我们只是没有按照说明进行操作并安装Torch。 第一个障碍是虚拟机的使用。 在虚拟的Ubuntu 16上,摇杆不能起飞-算了。 StackOverflow通常可以帮助您解决问题,但是有些错误非常重要,以至于很难找到答案。
在本地计算机上安装Torch使项目停滞了好几个星期:我们在安装大量必需的软件包时遇到了种种错误,我们还为虚拟化(virtualenv .env)苦苦挣扎,最终没有使用它。 几次将支架拆除到sudo rm -rf的高度,然后再次简单安装。
使用具有权重的结果文件,我们能够开始在本地计算机上生成文本:
 初步结论之一
初步结论之一第5部分。清除文本
另一个明显的困难是帖子的主题非常不同,我们的算法不涉及任何划分,而是将所有500,000行视为单个文本。 我们考虑了对数据集进行聚类的不同选项,甚至准备好按主题或在数千个buhur中放置标签来破坏正文(为此有必要的人力资源),但是在学习LSTM时提交聚类时经常遇到技术难题。 就安排项目的时间和参与者的动机而言,改变算法并再次进行比赛似乎并不是最明智的想法。
似乎我们陷入了僵局-我们无法将Buhurts聚类,并且在单个巨大的数据集上进行训练产生了可疑的结果。 我不想退后一步,更改几乎飙升的算法和实现-该项目可能会陷入昏迷。 团队拼命地没有足够的知识来正常解决问题,但是好老的SME-KAL-OCHK-A获救了。
拐杖的最终解决方案非常简单:在原始数据集中,用空行将现有的Buhurt彼此分开,然后再次训练LSTM。
在每个Buhurt之后,我们将拍子排列在10个垂直空间中,重复训练,并且在生成过程中,我们限制了500个字符的输出量(原始数据集中一个“ plot” buhurt的平均长度)。
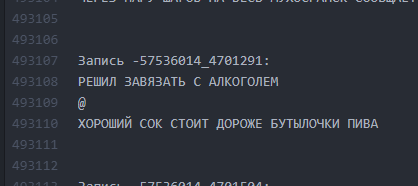 照原样。 文本之间的间隔很小。
照原样。 文本之间的间隔很小。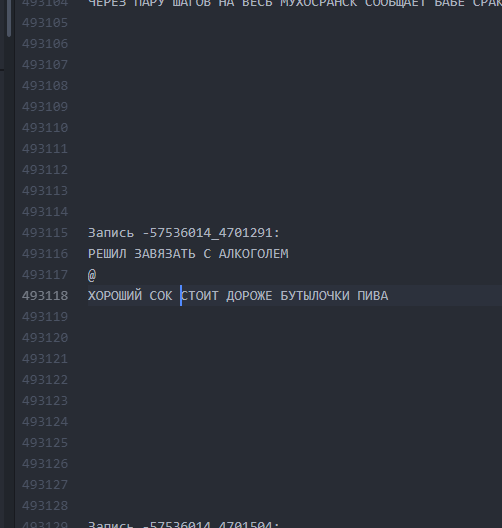 它是怎么变成的。 通过间隔10行,LSTM可以“了解”一个bogurt已经结束,另一个bogurt已经开始。
它是怎么变成的。 通过间隔10行,LSTM可以“了解”一个bogurt已经结束,另一个bogurt已经开始。因此,有可能实现,从开始到结束,大约60%的生成的Buhurt开始在Buhurt的整个长度上都具有可读的(虽然常常非常妄想)图。 一个地块的长度平均为9到13行。
第6部分。再培训
在估算了项目的经济性之后,我们决定不再花钱租集群,而是投资购买自己的卡。 学习时间会增加,但是一旦购买了卡,我们就可以不断产生新的话题。 同时,不再需要经常进行培训。
 本地计算机上的战斗设置
本地计算机上的战斗设置第7部分。平衡结果
在2017年3月至4月,我们重新训练了神经网络,并指定了温度参数和训练次数。 结果,输出质量略有提高。
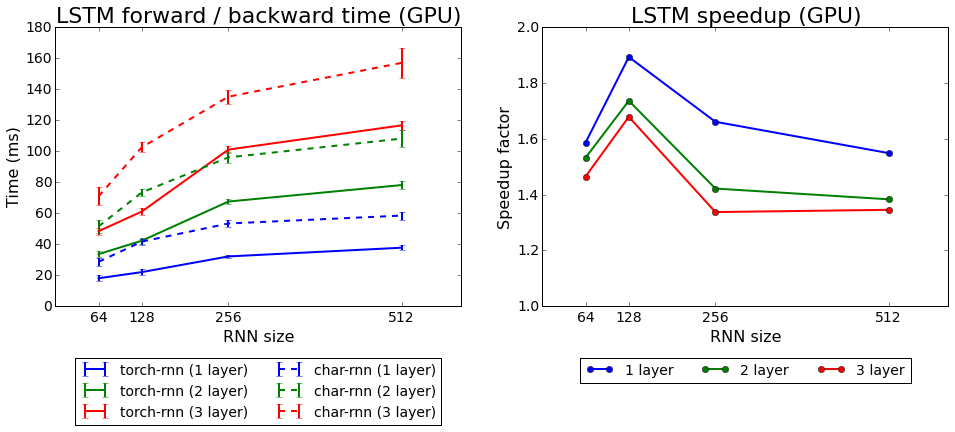 火炬学习速度与学习时间相比
火炬学习速度与学习时间相比我们测试了Torch附带的两种算法:rnn和LSTM。 第二个被证明是更好的。
第8部分。我们取得了什么成就?
第一个神经错误发布于2017年1月17日-在群集上进行训练后立即发布-并在第一天收集了1000多个评论。
 最早的神经错误之一
最早的神经错误之一Neurobugurt很好地吸引了听众,以至于它们成为了一个单独的部分,全年以#Neurobugurt的主题标签出现,并引起了很多用户的兴趣。 在2017年和2018年初,我们总共产生了超过
18,000个神经错误 ,平均每个错误500个字符。 此外,出现了一系列的公共模仿活动,其参与者描绘了神经虫,随机地在各个地方重新排列短语。

第9部分。不是结论
通过这篇文章,我想证明即使您没有神经网络方面的经验,这种悲伤也不是问题。 您无需在斯坦福大学工作即可使用神经网络完成简单但有趣的事情。 我们项目的所有参与者都是普通学生,具有当前的任务,文凭,工作,但是出于共同的原因,我们才得以将项目推向决赛。 得益于与会人员的周到想法,计划和精力,我们在最终确定想法后不到一个月的时间内就获得了第一个理智的结果(大部分技术和组织工作都落在了2017年的寒假中)。
 超过18,000个机器生成的Buhurt
超过18,000个机器生成的Buhurt我希望本文能帮助某人通过神经网络计划自己的雄心勃勃的项目。 我要求不要严格判断,因为这是我关于哈布雷的第一篇文章。 如果您像我一样是ML的狂热者,就让我们
成为朋友 。