前段时间,我的一位同事说,DC中的位置已用完,没有地方可以放置服务器,并且负载在增加,不清楚要做什么,您可能必须将所有可用的服务器更改为功能更强大的服务器。
当时我从事编译最佳计划的任务,我想-但是如果我们应用优化算法来提高DC中服务器的利用率呢? 我要编写的项目从这里诞生。
对于高级用户,我将立即说在本文中,我们将讨论垃圾箱打包,对于其他想学习如何使用相对简单的计算来节省多达30%的服务器资源的用户,欢迎使用。
因此,我们的DC具有大约100台服务器,其中托管了大约7,000个虚拟机。 虚拟机内部是什么-我们不知道也不应该知道。 必须将虚拟机放置在服务器上以执行SLA,同时使用最少数量的服务器。
我们知道:
- 服务器清单
- 每个服务器上的资源量(CPU时间,CPU内核,RAM,磁盘,磁盘io,网络io)。
- 虚拟机列表(VM)
- 每个虚拟机消耗的资源量(CPU时间,CPU内核,RAM,磁盘,磁盘io,网络io)。
- 服务器上的主机系统消耗的资源。
我们需要在服务器之间分配虚拟机,以使每个服务器上的每个资源都不会超过可用资源量,同时使用最少数量的服务器。
科学文献中的这项任务称为箱装箱问题(俄语中的情况如何?)。 简而言之,这是一个如何将任意大小的小盒子推入大盒子中,同时使用最少数量的大盒子的任务。 仅通过穷举搜索即可精确解决数学中众所周知的问题NP完全,而穷举搜索的成本正在不断增加。
下图说明了针对一维情况的装箱算法的本质:
 图 1.说明垃圾箱包装问题,非最佳放置
图 1.说明垃圾箱包装问题,非最佳放置在第一个图中,物品以某种方式分布在篮子中,并使用3个篮子放置它们。
 图 2.说明垃圾箱包装问题,最佳放置
图 2.说明垃圾箱包装问题,最佳放置第二张图显示了最佳分配,您只需要2个篮子。
装箱算法的标准公式还假设所有篮子都是相同的。 我们的服务器不一样,因为它们是在不同时间购买的,并且它们的配置也不同-处理器核心数量,内存,磁盘和处理器功率不同。
可以使用启发式,遗传算法,蒙特卡洛树搜索和深度神经网络来获得次优解决方案。 我们选择了BestFit启发式算法,该算法收敛到最优解的1.7倍以下,而不是遗传算法的某些变体。 下面我将给出其应用的结果。
但是首先,让我们讨论如何使用随时间变化的指标,例如CPU使用率,磁盘io,网络io。 最简单的方法是用一个常数替换变量度量。 但是如何选择该常数的值呢? 我们在某个特征周期内采用了指标的最大值(以前是平滑值的异常值)。 由于负载的主要季节性与工作日和休息日有关,因此在我们的案例中,一周是一个典型的时期。
在此模型中,为每个虚拟机分配了一个资源条,其大小为最大消耗的资源值,并且每个VM均由常量max CPU使用率,RAM,磁盘,最大磁盘io,最大网络io来描述。
接下来,我们使用该算法来计算最佳打包,并获得VM在物理服务器上的位置图。
实践表明,如果不为服务器上的每个资源留出一定的余量,那么当VM密集分配时,服务器就会过载。 因此,对于CPU使用率,我们留出30%的余量,对于RAM 20%,对于磁盘io-20%,对于网络io-20%,这些限制是根据经验选择的。
我们也有几种类型的磁盘(快速SSD和慢速廉价HDD),对于每种类型的磁盘,我们分别采用磁盘和磁盘io指标,因此最终模型变得更加复杂并且具有更大的尺寸。
图中显示了优化VM放置的结果:
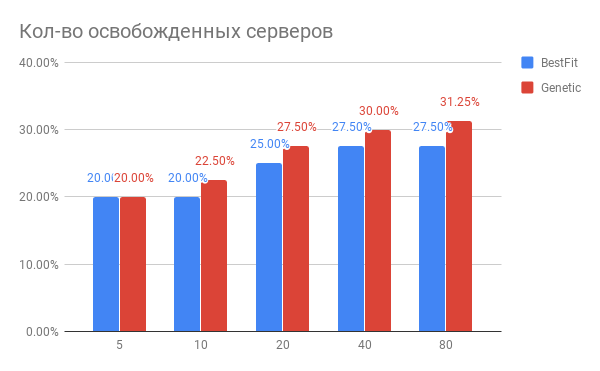 图 3.优化VM在服务器上的放置的结果
图 3.优化VM在服务器上的放置的结果水平-已优化的服务器数量,垂直-用于BestFit启发式算法和遗传算法的已释放服务器数量。
从图中可以得出什么结论?
- 对于当前任务,您可以减少20-30%的服务器使用。
- 一次优化的服务器越多,则服务器数量达到40或更多时,您赢得的百分比就越高,就会发生饱和。
- 遗传算法略优于启发式BestFit。 如果我们想进一步改善结果,我们将朝这个方向进行挖掘。
在实践中还出现了什么其他问题?
- 如果您要用7,000个虚拟机来摇动大约100台服务器,那么迁移的数量将非常可观,因此整个想法将无法实现。 但是,如果按顺序使用20至40个服务器组,则将获得几乎相同的效果,但是迁移次数将减少很多倍。 您可以优化零件的DC。
- 如果必须进行实时迁移,则可能会遇到迁移无法结束的情况。 这意味着在VM内需要对磁盘进行大量写入和/或更改内存状态,并且在旧副本和新副本之间的VM状态直到旧副本的状态更改之前没有时间进行同步。 在这种情况下,您需要预定义此类VM机器并将其标记为不可移动。 反过来,这需要修改优化算法。 令人高兴的是,如果虚拟机总数不超过10-15%,则总收益实际上与此类机器的数量无关。
优化虚拟机放置后服务器负载如何变化?
好的,我们优化了VM的放置。 相对于负载增加,可能导致的新状态非常脆弱? 也许服务器正在运行到极限,负载的增加会杀死它们吗?
我们比较了优化前和优化后1周的服务器资源利用率。 发生的情况如图2所示:
 图 4.优化虚拟机分配后CPU负载的变化
图 4.优化虚拟机分配后CPU负载的变化根据CPU使用率:平均CPU使用率已从10%增长到仅18%。 即 我们的CPU性能提高了三倍,而服务器将保持在所谓的“绿色”区域。
这是如何在软件中完成的?
我们以30秒的频率在Yandex.ClickHouse(我们尝试了InfluxDB,但在我们的数据量中,对其进行聚合的查询执行得太慢)中收集所需的指标。 从那里,计算最佳状态的任务会读取指标,从指标中计算最大消耗量,并生成放入队列中的计算任务。 一旦计算任务完成,就会运行测试以验证结果没有超出指定的限制。
有人做过吗?
据我们所知,类似的算法在VMware vSphere和Nutanix中,并出现在OpenStack(OpenStack Watcher项目)中。
有可能做得更好吗?
是的,你可以。 在下一篇文章中,我将告诉您如何在不违反SLA的情况下打包更密集的虚拟机,以及为什么需要神经元。