
在情绪识别领域,语音是仅次于面部的第二重要的情绪数据来源。 语音可以通过几个参数来表征。 音调是主要的此类特征之一,但是,在声学技术领域,将此参数称为基本频率更为正确。
基本音调的频率与我们所谓的语调直接相关。 例如,语调与语音的情感表达特征相关。
然而,确定基调的频率并不是一件容易的事,需要细微的细微差别。 在本文中,我们将讨论确定算法的功能,并将现有解决方案与特定音频记录的示例进行比较。
引言首先,让我们回顾一下本质上什么是基调的频率以及可能需要执行的任务。
基频 ,也称为CHOT,基本频率或F0,是声带发声时的频率。 当发出非音调声音时(例如,以低声说话)或发出嘶嘶声和啸叫声时,韧带不会犹豫,这意味着此特性与他们无关。
*请注意,分为音调和非音调的声音并不等同于分为元音和辅音。
基音频率的变化很大,不仅人与人之间的变化很大(对于较低的平均男性声音,频率为70-200 Hz,对于女性声音,频率可以达到400 Hz),而且对于一个人,尤其是在情感语音中, 。
确定基音的频率可用于解决各种问题:
- 如上所述,对情绪的识别;
- 性别决定;
- 解决将声音分割成多个声音或将语音分为短语时的问题;
- 在医学中,确定声音的病理特征(例如,使用声学参数Jitter和Shimmer)。 例如,帕金森氏病迹象的鉴定[ 1 ]。 抖动和微光也可以用来识别情绪[ 2 ]。
然而,确定F0存在许多困难。 例如,通常可能将F0与谐波混淆,这可能会导致所谓的音调加倍/音调减半效果[
3 ]。 在低质量的音频记录中,F0很难计算,因为低频所需的峰值几乎消失了。
顺便说一句,还记得
劳雷尔和亚尼的故事吗? 人们在收听相同音频记录时听到的单词的差异恰恰是由于感知F0的差异而引起的,该差异受许多因素的影响:收听者的年龄,疲劳程度和播放设备。 因此,在以高质量的低频再现扬声器收听录音时,您会听到Laurel的声音,而在低频再现较差的音频系统中,您会听到的声音是Yanny。 例如,可以在一个设备上看到过渡效果。 在
本文中 ,神经网络充当了侦听器。 在另
一篇文章中,您可以阅读如何通过语音形成来解释Yanny / Laurel现象。
由于对确定F0的所有方法的详细分析将过于繁琐,因此,本文具有概述性质,可以帮助您快速浏览主题。
确定F0的方法确定F0的方法可分为三类:基于信号的时间动态或时域; 基于频率结构或频域以及组合方法。 我们建议您熟悉该主题的评论
文章 ,在该
文章中详细分析了指示的提取F0的方法。
请注意,任何讨论的算法都包含3个主要步骤:
预处理(过滤信号,将其分成帧)
搜索F0的可能值(候选)
跟踪是最可能的轨迹F0的选择(由于每时每刻我们都有几个竞争的候选者,因此我们需要在其中找到最可能的轨迹)
时域我们概述了一些要点。 在应用时域方法之前,对信号进行预滤波,仅保留低频。 设置了阈值-最小和最大频率,例如75至500 Hz。 F0的确定仅针对具有谐调语音的区域,因为对于暂停或杂音,这不仅没有意义,而且在应用插值和/或平滑处理时还会在相邻帧中引入误差。 选择帧长,使其至少包含三个周期。
自相关是随后出现整个算法家族的主要方法。 该方法非常简单-必须计算自相关函数并取其第一个最大值。 它将显示信号中最明显的频率分量。 在使用自相关的情况下,可能会有什么困难?为什么第一个最大值与所需的频率相对应并不总是那么遥远? 即使在接近高质量记录的理想条件下,由于信号的复杂结构,该方法也可能会出错。 在接近真实的条件下,除其他外,在嘈杂的录音或最初质量较低的录音中,我们可能会遇到所需峰值的消失,错误的数量急剧增加。
尽管存在错误,但是自相关方法由于其基本的简单性和逻辑性而非常方便且具有吸引力,这就是为什么将其用作包括YIN在内的许多算法的基础。 甚至算法的名称也使我们想到了自相关方法的便利性和不准确性之间的平衡:“东方哲学中“ yin”和“ yang”的名称YIN暗示了它涉及的自相关和抵消之间的相互作用。” [
4 ]
YIN的创造者试图解决自相关方法的弱点。 第一个变化是使用“累积均值归一化差”函数,该函数应降低对幅度调制的敏感性,使峰值更明显:
\开始{equation}
d'_t(\ tau)=
\开始{cases}
1,&\ tau = 0 \\
d_t(\ tau)\ bigg / \ bigg [\ frac {1} {\ tau} \ sum \ limits_ {j = 1} ^ {\ tau} d_t(j)\ bigg],和\ text {否则}
\结尾{cases}
\结束{equation}
YIN还尝试避免在窗口函数的长度未完全除以振荡周期的情况下发生的错误。 为此,使用抛物线最小内插法。 在音频信号处理的最后一步,将执行“最佳局部估计”功能,以防止值急剧跳变(无论好坏,这都是有争议的点)。
频域如果我们谈论频域,那么信号的谐波结构便是最重要的,即在F0倍数的频率处存在频谱峰值。 您可以使用倒谱分析将此周期性模式“折叠”为一个清晰的峰。 倒谱-功率谱对数的傅立叶变换; 倒谱峰对应于频谱中最周期性的分量(
在这里和
这里都可以阅读)。
确定F0的混合方法值得进一步详细研究的下一个算法的名称是YAAPT(音调跟踪的另一种算法),并且实际上是混合的,因为它同时使用了频率和时间信息。 文章中有完整描述,在这里我们仅描述主要阶段。
 图1. YAAPTalgo算法图( 链接 )
图1. YAAPTalgo算法图( 链接 ) 。
YAAPT包含几个主要步骤,第一步是预处理。 在这一阶段,原始信号的值被平方,并获得信号的第二种形式。 此步骤追求的目标与YIN中的累积平均归一化差分函数相同-放大和恢复自相关的“干扰”峰。 两种版本的信号都经过滤波-通常它们的范围是50-1500 Hz,有时是50-900 Hz。
然后,从转换后的信号的频谱计算出基本轨迹F0。 使用频谱谐波相关(SHC)功能确定F0的候选对象。
\开始{equation}
SHC(t,f)= \和\极限_ {f'=-WL / 2} ^ {WL / 2} \ prod \极限_ {r = 1} ^ {NH + 1} S(t,rf + f')
\结束{equation}
其中S(t,f)是帧t和频率f的幅度谱,WL是窗口长度(以Hz为单位),NH是谐波数(作者建议使用前三个谐波)。 频谱功率还用于确定浊音帧,然后搜索最佳轨迹,并考虑音高加倍/音高减半的可能性[
3 ,第二节,C]。
此外,针对初始信号和转换后的信号都确定了F0的候选,并且在这里使用归一化互相关(NCCF)代替自相关函数。
\开始{equation}
NCCF(m)= \ frac {\ sum \ limits_ {n = 0} ^ {Nm-1} x(n)* x(n + m)} {\ sqrt {\ sum \ limits_ {n = 0} ^ { Nm-1} x ^ 2(n)* \ sum \ limits_ {n = 0} ^ {Nm-1} x ^ 2(n + m)}} \文字{,} \ hspace {0.3cm} 0 <m <M_ {0}
\结束{equation}
下一步是评估所有可能的候选者,并计算其重要性或权重(优点)。 从音频信号获得的候选对象的权重不仅取决于NCCF峰值的幅度,还取决于它们与从频谱确定的轨迹F0的接近程度。 也就是说,频域在准确性上被认为是粗糙的,但是稳定的[
3 ,第二节,D]。
然后,针对所有剩余的候选对,计算过渡成本矩阵-过渡价格,最终他们以该价格找到最佳轨迹[
3 ,第二节,E]。
例子现在,我们将上述所有算法应用于特定的音频记录。 首先,我们将使用
Praat ,这是许多语音学者
必不可少的工具。 然后在Python中,我们将研究YIN和YAAPT的实现,并将比较收到的结果。
作为音频资料,您可以使用任何可用的音频。 我们从
RAMAS数据库中摘录了一些片段-一个由VGIK参与者参与创建的多模式
数据集 。 您还可以使用来自其他开放数据库的资料,例如
LibriSpeech或
RAVDESS 。
举一个说明性的例子,我们从几张录音中摘录了中性和情感色彩的男性和女性声音,为清楚起见,我们将它们合并为一张
录音 。 让我们看一下信号,其频谱图,强度(橙色)和F0(蓝色)。 在Praat中,可以使用Ctrl + O(打开-从文件读取),然后使用“查看和编辑”按钮来完成此操作。
 图2.频谱图,强度(橙色),F0(蓝色),单位为Praat。
图2.频谱图,强度(橙色),F0(蓝色),单位为Praat。音频非常清楚地表明,在情感演讲中,男女音调都增加了。 同时,情感男性语音的F0可以与女性语音的F0进行比较。
追踪在Praat菜单中选择“分析周期-到音高(ac)”选项卡,即使用自相关的F0定义。 将出现一个用于设置参数的窗口,在其中可以设置3个参数来确定F0的候选者,并为路径查找器算法设置6个以上的参数,从而在所有候选者中建立最可能的路径F0。
许多参数(在Praat中,它们的描述也在“帮助”按钮上)- 静音阈值-确定静音的信号的相对幅度阈值,标准值为0.03。
- 发声阈值-未发声候选的权重,最大值为1。此参数越高,将被定义为发声的帧越多,即不包含音调。 在这些帧中,将不会确定F0。 此参数的值是自相关函数峰值的阈值。 默认值为0.45。
- 八度音阶成本-确定高频候选者相对于低频候选者的权重。 值越高,对高频候选的优先级越高。 默认值为每八度0.01。
- 八度跳动成本-随着该系数的增加,F0的连续值之间急剧跳变的跃迁次数减少。 默认值为0.35。
- 浊音/清音成本-增加此系数会减少浊音/清音转换的数量。 默认值为0.14。
- 音高上限(Hz)-不考虑高于此频率的候选者。 默认值为600 Hz。
该算法的详细说明可以在1993年的
一篇文章中找到。
单击确定,然后查看(查看和编辑)生成的Pitch文件,可以看到跟踪器(路径查找器)的结果。 可以看出,除了选定的轨迹之外,还有相当多的候选者具有较低的频率。
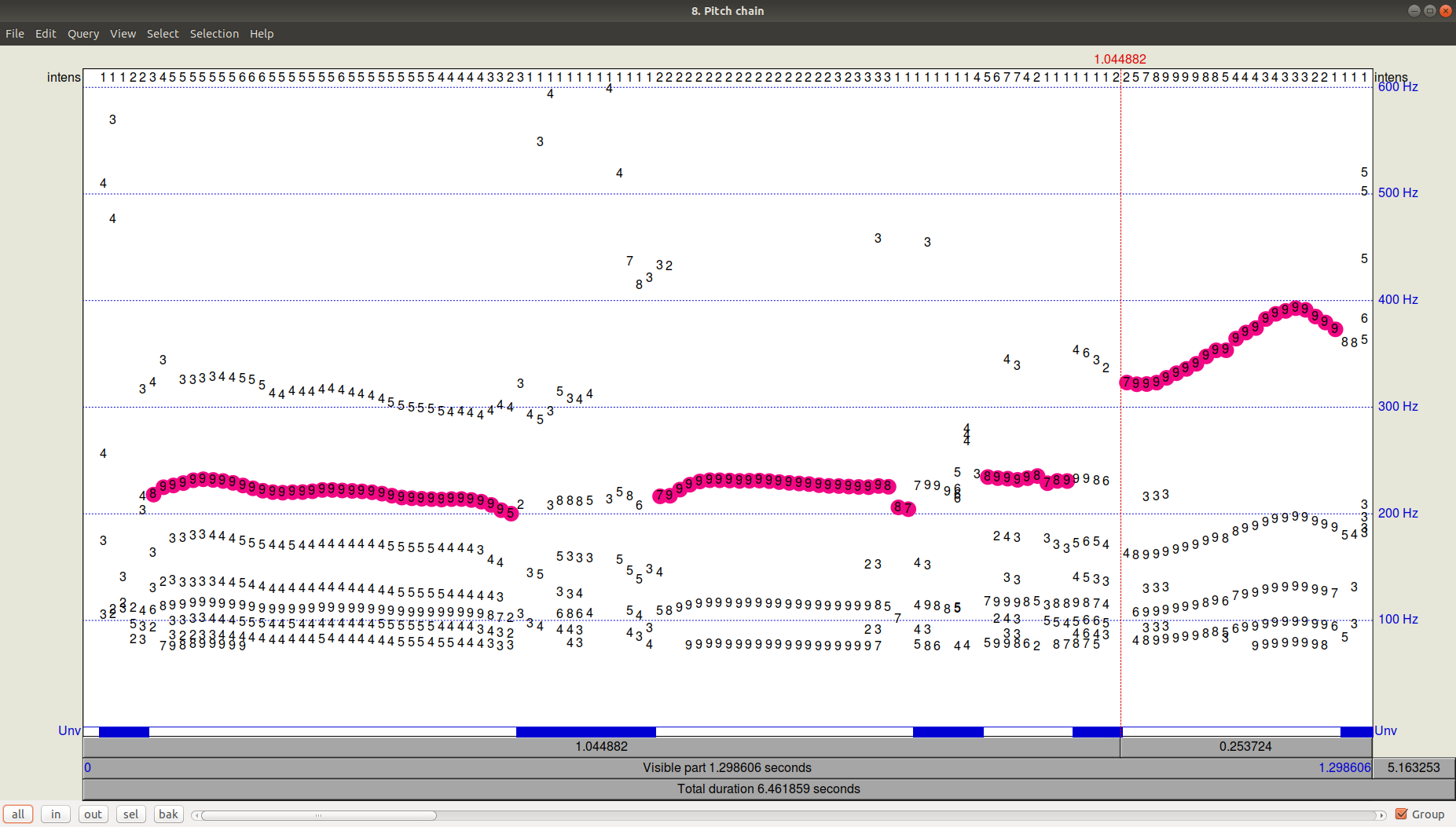 图3.录音的前1.3秒的PitchPath。但是Python呢?
图3.录音的前1.3秒的PitchPath。但是Python呢?让我们来看两个提供音高跟踪的库
-aubio (默认算法为YIN)和
AMFM_decompsition库,该库具有YAAPT算法的实现。 在单独的文件(文件
PraatPitch.txt )中,
插入 Praat中
的 F0值(可以手动完成:选择声音文件,单击“查看和编辑”,选择整个文件,然后在顶部菜单中选择“音高-音高”列表)。
现在比较所有三种算法(YIN,YAAPT,Praat)的结果。
很多代码import amfm_decompy.basic_tools as basic import amfm_decompy.pYAAPT as pYAAPT import matplotlib.pyplot as plt import numpy as np import sys from aubio import source, pitch
 图4. YIN,YAAPT和Praat算法的操作比较。
图4. YIN,YAAPT和Praat算法的操作比较。我们看到,使用默认参数,YIN被完全剔除,获得了一个非常平坦的轨迹,其值低于Praat,并且完全失去了男性和女性声音之间以及情感和非情感性语音之间的过渡。
YAAPT大幅降低了女性情感表达的语调,但总体而言显然效果更好。 由于其独特的功能,YAAPT的效果更好-当然不可能立即回答,但可以假设,该角色是通过从三个来源获得候选人并比YIN进行更精细的权重计算来发挥作用的。
结论由于确定基本音调(F0)以一种或另一种形式出现的频率的问题已经出现在几乎每个使用声音的人面前,因此有许多解决方法。 每种情况下音频材料的必要准确性和功能性问题决定了选择参数的谨慎程度,或者在另一种情况下,您可以将自己局限于基本解决方案,例如YAAPT。 以Praat作为语音处理的标准算法(尽管有很多研究人员使用它),我们可以得出结论,虽然我们的示例证明它很复杂,但YAAPT的近似值比YIN更可靠和准确。
由语音处理专家Neurodata实验室研究员
Eva Kazimirova发布。
Offtop :您喜欢这篇文章吗? 实际上,在ML,数学和程序设计方面,我们有许多有趣的任务,我们需要动脑筋。 您对此感兴趣吗? 来找我们 电子邮件:hr@neurodatalab.com
参考文献- Rusz,J.,Cmejla,R.,Ruzickova,H.,Ruzicka,E.定量声学测量,用于表征早期未经治疗的帕金森氏病的语音和语音障碍。 美国声学学会杂志,第一卷。 129,第1期(2011),第 350-367。 访问权限
- Farrús,M.,Hernando,J.,Ejarque,P.抖动和闪烁测量,用于说话人识别。 国际语音交流协会年会论文集,INTERSPEECH,第1卷。 2(2007),pp。 1153-1156。 访问权限
- Zahorian,S.,Hu,HA。 用于稳健的基本频率跟踪的频谱/时间方法。 美国声学学会杂志,第一卷。 123,第6期(2008),第 4559-4571。 访问权限
- DeCheveigné,A.,Kawahara,H。YIN,语音和音乐的基本频率估计器。 美国声学学会杂志,第一卷。 111,第4期(2002),pp。 1917-1930。 访问权限