GAN思想最早由Jan Goodfellow
生成对抗网络(Goodfellow等人,2014年)发表 ,之后GAN是最好的生成模型之一。
与任何其他生成模型一样,GAN的任务是构建数据模型,更具体地说,学习如何从尽可能接近数据分布的分布中生成样本(通常,我们要在有限的数据集中对数据分布进行建模)。
GAN具有很多优点,但它们有一个重大缺点-很难训练。
最近,发布了许多有关GAN可持续性的作品:
受他们的想法启发,我做了一点研究。
我试图使文本尽可能简单,并且如果可能的话,仅使用最简单的数学。 不幸的是,为了证明为什么我们可以考虑二维矢量场的性质,我们必须在变化的演算方向上进行一些挖掘。 但是,如果有人不熟悉这些术语,则可以立即放心考虑不同类型GAN的2维矢量场。
现在,我们将尝试看一下培训过程的内容,并了解那里正在发生的事情。
GAN,主要问题
GAN由两个神经网络组成:鉴别器和生成器。 生成器-允许您从某些分布(通常称为生成器的分布)中采样。 鉴别器从原始数据集和生成器接收输入样本,并学习预测该样本的来源(数据集或生成器)。
GAN计划:
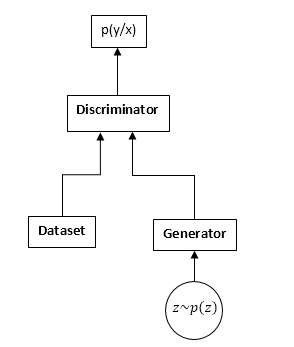
GAN培训过程如下:
- 我们从数据集中获取n个样本,从生成器获取m个样本。
- 我们固定发生器权重并更新鉴别器参数。 这是常见的分类任务。 我们只是不需要训练鉴别器,直到收敛为止。 而且更经常地,它也会干扰。
- 我们固定鉴别器权重并更新生成器权重,以便鉴别器开始认为我们的样本来自数据集而不是生成器。
- 我们重复1-3,直到鉴别器和生成器达到平衡(也就是说,其他任何人都不能“欺骗”对方)。
我们不会详细研究GAN学习过程。 在Internet上,尤其是在Hubr上,有许多文章详细解释了此过程。
我们会对完全不同的事物感兴趣。 也就是说,由于我们正在与两个神经网络竞争,因此该任务不再是寻找最小值(最大值),而是在特定情况下转变为寻找鞍点(即,在第2步和第3步中,我们尝试相同的功能通过区分参数最大化并通过生成器参数最小化),在更通用的步骤2和3中,我们可以优化完全不同的功能。 显然,极大极小问题是对不同功能进行优化的特例-一个功能采用了不同的符号。
让我们在公式中看一下。 我们假设pd(x)是从中采样数据集的分布,pg(x)是生成器的分布,D(x)是鉴别器的输出。
训练鉴别器时,我们通常会最大化此类功能:
J = intpd(x)日志(D(x))dx + intpg(x)日志(1\- D(x))dx
渐变向量:
v= nabla thetaJ = int fracpd(x)D(x) nabla thetaD(x) dx + int fracpg(x)1\- D(x) nabla thetaD(x)dx
在训练生成器时,我们将最大化:
I =\- intpg(x)日志(1\- D(x))dx
在这种情况下,梯度向量:
u = nabla varphiI =\- int nabla varphipg(x)log(1\- D(x))dx
将来,我们将看到这些功能可以分别替换为:
J = intpd(x)f1(D(x))dx +intpg(x)f2(D(x))dx
I = intpg(x)f3(D(x))dx
哪里
f1,f2,f3 是根据某些规则选择的。 顺便说一下,伊恩·古德费洛(Ian Goodfellow)在他的原始文章中使用了
f1和f2 就像训练常规鉴别器时一样,以及
f3 选择以便在训练初期改善梯度:
f1\左(x\右)=日志\左(x\右), f2\左(x\右)=日志\左(1\- x\右),f3\左(x\右)=日志\左(x\右)
乍一看,该任务似乎与使用梯度下降(上升)学习的通常任务非常相似。 那么,为什么参加GAN培训的每个人都同意这太难了?
答案在于矢量场的结构,我们可以使用它来更新神经网络的参数。 在通常的分类问题的情况下,我们仅使用梯度向量,即场为势(优化的函数本身就是此向量场的势)。 潜在的矢量场具有一些显着的特性,其中之一就是没有闭合曲线。 即,不可能在这个领域中转圈。 但是,当训练GAN时,尽管生成器和鉴别器的矢量场分别是势能(梯度相同),但总矢量场将不会是势能。 这意味着在该字段中可以存在闭合曲线,即我们可以绕圈行走。 这是非常非常糟糕的。
出现了一个问题:为什么,尽管如此,我们还是成功地成功训练了GAN,也许这个领域仍然没有发展(潜力)? 如果是这样,那为什么这么复杂?
不幸的是,我会继续前进,尽管该领域没有潜力,但是它具有许多良好的性能。 不幸的是,该领域对神经网络的参数化也非常敏感(激活函数的选择,DropOut的使用,BatchNormalization等)。 但是首先是第一件事。
“梯度” GAN域
我们将以最一般的形式考虑GAN学习功能:
J = intpd(x)f1(D(x))dx +intpg(x)f2(D(x))dx
I = intpg(x)f3(D(x))dx
我们需要同时优化两个功能。 假设D(x)和pg(x)是绝对灵活的函数,即 我们可以在任何点取任何数字,而与其他点无关。 从变化的演算来看,这是一个众所周知的事实-您需要在该函数的变分导数的方向上更改函数(通常是梯度上升的完全类似物)。
我们写变分导数:
frac\部分J\部分D(x)=pd(x)f′1(D(x)) + pg(x)f′2(D(x))
frac\部分I\部分pg(x)=f3(D(x))
我们将仅考虑第一个功能(用于区分器),第二个功能都相同。
但是考虑到实际上我们只能在神经网络可表示的一组函数中更改函数,因此我们将编写:
$$显示$$ ∆D(x)= \ frac {\部分D(x)} {\局部θ_j}Δθ_j$$显示$$
网络参数的变化,通常是通常的梯度下降(上升):
$$显示$$ ∆θj = \ frac {\部分J} {\部分θ_j}μ$$显示$$
µ是学习率。 好吧,关于网络参数的导数:
frac\部分J\部分 thetaj= int frac\部分J\部分D(y) frac\部分D(y)\部分 thetajdy
现在,我们将所有内容放在一起:
∆D(x)= \ sum_ {j} {\ frac {\部分D(x)} {\部分\ theta_j} \ int {\ frac {\部分J} {\部分D(y)} \ frac { \部分D(y)} {\部分\ theta_j} dy} \ mu \ = \ mu \ int \ frac {\部分J} {\部分D(y)}} \ sum_ {j} {\ frac {\部分D(x)} {\部分\ theta_j} \ frac {\部分D(x)} {\部分\ theta_j} dy \ = \} \ mu \ int {\ frac {\部分J} {\部分D(y )} K_ \ theta(x,y)dy}
其中:
K theta(x,y) = sumj frac\部分D(x)\部分 thetaj frac\部分D(x)\部分 thetaj 在有关机器学习的文献中我从未见过此功能,因此我将其称为系统的参数核心。
好吧,或者如果我们按时间进行连续的步骤(从差分方程到微分方程),我们将得到:
fracddtD(x) = int frac\部分J\部分D(y)K theta(x,y)dy
该方程式显示了原始场的内部关系(鉴别器为点向)和神经网络的参数化。 我们为发电机获得了一个完全相似的方程。
考虑到K(x,y)(参数核)是一个正定函数(嗯,如何将其表示为对应点处的梯度的标量积),我们可以得出结论,训练后的函数(判别器和生成器)的任何变化都属于希尔伯特空间由核心产生,即 K(x,y)。 我想知道是否有可能在这里获得任何有意义的结果。 但是我们不会朝那个方向看,但我们会朝另一个方向看。
如您所见,GAN的稳定性由两个部分决定:功能的变分导数和神经网络的参数化。 我们的任务是了解该字段的指向性,即我们的网络是否可以表示任何功能。 该任务变为对二维矢量场的分析。 我认为,这就是我们的力量。
可持续发展
因此,我们考虑以下向量字段:
fracddtD(x)= frac\部分J\部分D(x)
fracddtpg(x)= frac\部分I\部分pg(x)
显然,考虑到我们的变分导数是什么样的,这些方程只能考虑一个点x:
fracddtD= pdf\质1数(D) + pgf\质2数(D)
fracddtpg = f3(D)
此方程式系统的第一个要求是,在下列情况下,右侧必须变为0:
pd=pg否则,我们将尝试训练模型,这显然不会收敛到正确的解决方案。 即 D必须是以下方程式的解:
f\素1数(D) + f\素2数(D) = 0
我们将此解决方案表示为
D0 。
鉴于pg(x)是右边的概率密度,我们可以添加任意数量而不会违反导数。 为了在所需点处提供右侧的0,请减去t中的值。
D0 (如果我们要逐点考虑pg,则必须执行此操作-从通过概率密度参数化的字段到自由字段的过渡)。
结果,我们获得以下字段:
fracddtD= pdf\质1数(D) + pgf\质2数(D)
fracddtpg = f3(D)\- f(D0)
从现在开始,我们将研究这种场的静态点和稳定性。
我们可以研究两种类型的稳定性:局部(在静态点附近)和整体(使用Lyapunov函数方法)。
为了研究局部稳定性,有必要计算磁场的雅可比矩阵。
为了使场局部稳定,特征值必须具有负实部。
不同类型的GAN
经典GAN
在经典GAN中,我们使用常规logloss:
J = intpd(x)日志(D(x))dx + intpg(x)日志(1\- D(x))dx
为了训练鉴别器,有必要将其最大化;对于生成器,有必要将其最小化。 在这种情况下,该字段将如下所示:
fracddtD= fracpdD\- fracpg1−D
fracddtpg = −log(1−D) + log( frac12)
让我们看看参数(pg和D)在该字段中将如何演变。 为此,请使用以下简单的Python脚本:
剧本def get_v(d, pg, pd): vd = pd/d - pg/(1.-d) vpg = -np.log(1.-d) + np.log(0.5) return vd, vpg d = 0.75 pg = 0.9 pd = 0.2 d_hist = [] pg_hist = [] lr = 1e-3 n_iter = 100000 for i in range(n_iter): d_hist.append(d) pg_hist.append(pg) vd, vpg = get_v(d, pg, pd) d = d + lr*vd pg = pg + lr*vpg plt.plot(d_hist, pg_hist, '-') plt.show()
作为起点 pg=0.9,D=0.25 它看起来像这样:

该字段的其余点为:pg = pd和D = 0.5
可以很容易地验证Jacobi矩阵特征值的实部是否为负,即该场是局部稳定的。
我们不会处理全球可持续性的证明。 但是,如果它非常有趣,则可以使用Python脚本,并确保该字段对于任何有效的初始值都是稳定的。Jan Goodfellow修改
上面我们已经讨论过,原始文章中的Ian Goodfellow使用的是GAN的稍微修改后的版本。 对于其版本,功能如下:
f1\左(x\右)=日志\左(x\右), f2\左(x\右)=日志\左(1\- x\右),f3\左(x\右)=日志\左(x\右)
该字段将如下所示:
fracddtD= fracpdD\- fracpg1−D
fracddtpg = log(D)\- log( frac12)
python脚本将是相同的,只是字段函数不同:
剧本 def get_v(d, pg, pd): vd = pd/d - pg/(1.-d) vpg = np.log(d) - np.log(0.5) return vd, vpg d = 0.75 pg = 0.9 pd = 0.2 d_hist = [] pg_hist = [] lr = 1e-3 n_iter = 100000 for i in range(n_iter): d_hist.append(d) pg_hist.append(pg) vd, vpg = get_v(d, pg, pd) d = d + lr*vd pg = pg + lr*vpg plt.plot(d_hist, pg_hist, '-') plt.show()
并且使用相同的初始数据,图片如下所示:
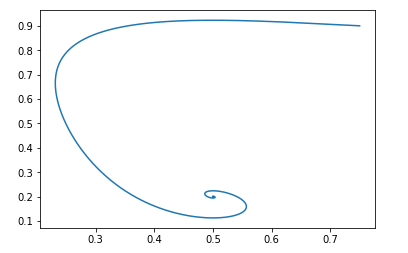
再次,很容易验证该场将是本地稳定的。
也就是说,从收敛的角度来看,这样的修改不会损害GAN的性能,但是在训练神经网络方面有其自身的优势。瓦瑟斯坦·甘
让我们看一下GAN的另一个流行观点。 优化的功能如下所示:
J \ = \ \ int {p_d(x)D(x)dx \-\} \ int {p_g(x)D(x)dx}
其中D相对于x属于1-Lipschitz函数的类。
我们希望通过D最大化它,通过pg最小化它。
显然,在这种情况下: f1\左(x\右)=x, f2\左(x\右)=−x, f3\左(x\右)=x
字段将如下所示:
fracddtD= pd\- pg
fracddtpg = D
在此字段中,很容易猜出一个以一点为中心的圆。 pg=pd,D=0 。
也就是说,如果我们沿着这个领域前进,我们将永远绕圈转。
这是此类字段中的轨迹的示例:
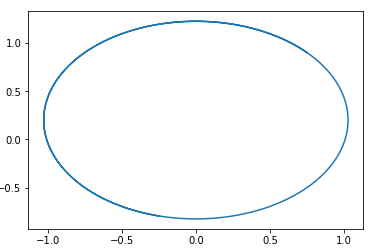
问题是,为什么然后要训练这种GAN? 答案很简单-此分析未考虑D的1-Lipschitz属性这一事实。也就是说,我们不能采用任意函数。 顺便说一句,这与本文作者的结果非常吻合。 为了避免走一圈,他们建议培训鉴别器以使其收敛: Wasserstein GAN新的GAN选项
功能选择 f1,f2和f3 您可以创建不同的GAN选项。 这些功能的主要要求是确保“正确的”休息点的存在和该点的稳定性(最好是全局的,但至少是局部的)。 我为读者提供了获得功能f1,f2和f3的限制的机会,这些限制对于局部稳定性是必需的。 很简单-只需考虑雅可比矩阵特征值的二次方程即可。
我将举一个这样的GAN的例子:
f1(x) = −0.5x2, f2(x) = x, f3(x) = −x
再次,我建议读者自己建立该GAN的领域并证明其稳定性。 (顺便说一下,这是全球稳定的基础证据很少的领域之一-只需选择Lyapunov函数,即到静止点的距离即可)。 只需考虑休息点为D = 1。
结论和进一步研究
从以上分析可以看出,所有经典GAN(Wassertein GAN除外,它都有自己的提高稳定性的方法)都具有“良好”的领域。 即 在这些字段之后的是单个静止点,在该静止点处,生成器的分布等于数据的分布。
那么,为什么培训GAN是如此艰巨的任务。 答案很简单-神经网络的参数化。 有了“错误的”参数设置,我们还可以兜圈子。 例如,我的实验表明,例如,在任何网络中使用BatchNormalization都会立即将该字段变成封闭的字段。 Relu激活效果最佳。
不幸的是,目前还没有一种方法可以从理论上检查神经网络的哪些元素如何改变磁场。 对我来说,研究该系统的参数内核的特性将很有前途-
K theta(x,y) 。
我还想讨论规范化GAN字段的方法,并从二维字段的角度对此进行探讨。 从这个角度考虑强化学习算法。 还有更多。 但不幸的是,这篇文章无论如何还是太大了,所以在其他时间可以找到更多。