
在C ++上下文中,“模式”通常是指非常特定的语言构造。 有一些简单的模板可简化使用相同类型的代码的工作-这些是类和函数模板。 如果模板本身具有参数之一,则可以说是二阶模板,并且模板会根据其参数生成其他模板。 但是,如果他们的能力不足且更容易立即生成源文本,该怎么办? 很多源代码?
Python和HTML布局的迷们熟悉用于处理名为
Jinja2的文本模板的工具(引擎,库)。 在输入端,此引擎接收一个模板文件,在该文件中可以将文本与控制结构混合,输出是纯文本,其中所有控件结构均根据外部(或内部)指定的参数替换为文本。 粗略地说,这类似于ASP页面(或C ++-预处理程序),只是标记语言不同。
到目前为止,该引擎的实现仅适用于Python。 现在适用于C ++。 关于它发生的方式和原因,并将在本文中进行讨论。
我为什么还要拿这个
确实,为什么呢? 毕竟,有了Python,它是一个出色的实现,一系列功能以及该语言的完整规范。 随身携带! 我不喜欢Python-在C ++中可以使用
Jinja2CppLight或
inja (部分Jinja2端口)。 最后,您可以使用C ++端口{{
Mustache }}。 像往常一样,细节决定成败。 所以,比方说,我需要Jinja2中的过滤器功能和extends结构的功能,这使您可以创建可扩展的模板(以及宏和包含,但稍后再介绍)。 所提到的实现均不支持此功能。 我能不用所有这些吗? 也是一个很好的问题。 自己判断。 我有一个
项目,其目标是创建C ++-to-C ++样板代码生成器。 例如,此自动生成器接收带有结构或枚举的手动编写的头文件,并基于该自动生成器生成序列化/反序列化的功能,或者将枚举元素转换为字符串(反之亦然)。 您可以在我的报告(eng)或
这里 (rus)中收听有关此实用程序的更多详细信息。
因此,在使用该实用程序的过程中解决的典型任务是创建头文件,每个头文件都有一个头文件(包含ifdefs和include),一个包含主要内容的主体和一个页脚。 此外,主要内容是名称空间塞满的生成的声明。 在C ++执行中,用于创建此类头文件的代码如下(并非全部):
很多C ++代码void Enum2StringGenerator::WriteHeaderContent(CppSourceStream &hdrOs) { std::vector<reflection::EnumInfoPtr> enums; WriteNamespaceContents(hdrOs, m_namespaces.GetRootNamespace(), [this, &enums](CppSourceStream &os, reflection::NamespaceInfoPtr ns) { for (auto& enumInfo : ns->enums) { WriteEnumToStringConversion(os, enumInfo); WriteEnumFromStringConversion(os, enumInfo); enums.push_back(enumInfo); } }); hdrOs << "\n\n"; { out::BracedStreamScope flNs("\nnamespace flex_lib", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline const char* Enum2String($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline $enumFullQualifiedName$ String2Enum<$enumFullQualifiedName$>(const char* itemName)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::StringTo$enumName$(itemName);"; } } } { out::BracedStreamScope flNs("\nnamespace std", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); out::BracedStreamScope body("inline std::string to_string($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } } }
从这里 。
而且,此代码在文件之间几乎没有变化。 当然,您可以使用clang-format进行格式化。 但这并不会取消其余有关生成源文本的手动工作。
然后一个美好的时刻,我意识到应该简化我的生活。 由于支持最终结果的复杂性,我不考虑使用成熟的脚本语言。 但是要找到合适的模板引擎-为什么不呢? 我发现它对搜索很有用,发现了它,然后我发现了Jinja2规范,并意识到这正是我所需要的。 按照此规范,用于生成标头的模板如下所示:
{% extends "header_skeleton.j2tpl" %} {% block generator_headers %} #include <flex_lib/stringized_enum.h> #include <algorithm> #include <utility> {% endblock %} {% block namespaced_decls %}{{super()}}{% endblock %} {% block namespace_content %} {% for enum in ns.enums | sort(attribute="name") %} {% set enumName = enum.name %} {% set scopeSpec = enum.scopeSpecifier %} {% set scopedName = scopeSpec ~ ('::' if scopeSpec) ~ enumName %} {% set prefix = (scopedName + '::') if not enumInfo.isScoped else (scopedName ~ '::' ~ scopeSpec ~ ('::' if scopeSpec)) %} inline const char* {{enumName}}ToString({{scopedName}} e) { switch (e) { {% for itemName in enum.items | map(attribute="itemName") | sort%} case {{prefix}}{{itemName}}: return "{{itemName}}"; {% endfor %} } return "Unknown Item"; } inline {{scopedName}} StringTo{{enumName}}(const char* itemName) { static std::pair<const char*, {{scopedName}}> items[] = { {% for itemName in enum.items | map(attribute="itemName") | sort %} {"{{itemName}}", {{prefix}}{{itemName}} } {{',' if not loop.last }} {% endfor %} }; {{scopedName}} result; if (!flex_lib::detail::String2Enum(itemName, items, result)) flex_lib::bad_enum_name::Throw(itemName, "{{enumName}}"); return result; } {% endfor %}{% endblock %} {% block global_decls %} {% for ns in [rootNamespace] recursive %} {% for enum in ns.enums %} template<> inline const char* flex_lib::Enum2String({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } template<> inline {{enum.fullQualifiedName}} flex_lib::String2Enum<{{enum.fullQualifiedName}}>(const char* itemName) { return {{enum.namespaceQualifier}}::StringTo{{enum.name}}(itemName); } inline std::string to_string({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } {% endfor %} {{loop(ns.namespaces)}} {% endfor %} {% endblock %}
从这里 。

只有一个问题:我发现没有一个引擎支持我所需的全部功能。 好吧,当然,每个人都有一个
致命的标准
缺陷 。 我稍微想了一下,并决定另一个世界不会因为模板引擎的另一个实现而变得更糟。 而且,据估计,基本功能并不是很难实现。 毕竟,现在在C ++中有正则表达式!
这样
Jinja2Cpp项目
就诞生了 。 我几乎猜到是以实现基本(非常基础)功能的复杂性为代价的。 总体而言,我确实错过了Pi系数的平方:我花了不到三个月的时间来编写所需的所有内容。 但是,当一切完成,完成并插入“自动编程器”后,我意识到自己没有白费。 实际上,代码生成实用程序收到了功能强大的脚本语言和模板的组合,从而为其打开了全新的开发机会。
注意:我有个主意要紧固Python(或Lua)。 但是,现有的成熟脚本引擎都无法解决从模板生成文本时的“开箱即用”问题。 也就是说,Python仍然必须拧紧相同的Jinja2,但对于Lua,则需要寻找不同的东西。 为什么我需要这个额外的链接?
解析器实现
Jinja2模板的结构背后的想法非常简单。 如果一对“ {{” /“}}”中包含的文本中有某些内容,则为“某物”-必须对其求值,将其转换为文本表示形式并插入最终结果中的表达式。 在“ {%” /“%}”对中,有for,if,set等运算符。好吧,在“ {#” /“#}”中有注释。 在研究了Jinja2CppLight的实现之后,我认为尝试在模板文本中手动找到所有这些控制结构并不是一个好主意。 因此,我用一个相当简单的正则表达式武装自己:(((\\\\\)|(\ {%)|(%\})|(\ {#)|(#\})|(\ n)),在此帮助下,他将文本分成了必要的片段。 并将其称为解析的粗略阶段。 在工作的最初阶段,这个想法显示了它的有效性(是的,实际上,它仍然显示出来),但是,以一种很好的方式,将来需要对其进行重构,因为现在对模板文本施加了较小的限制:转义对“ {{”和文本中的“}}”也被“额头”处理。
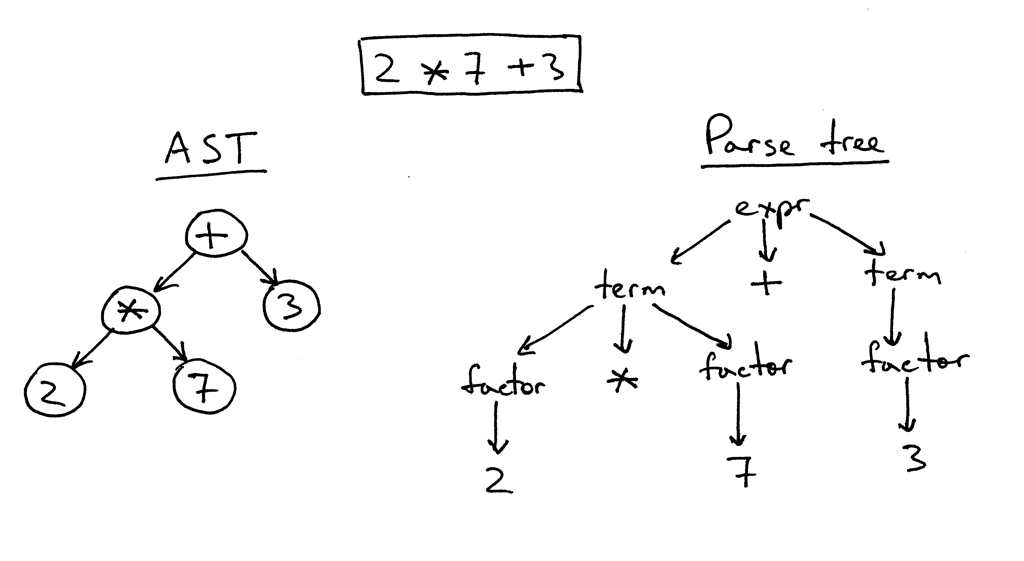
在第二阶段,仅详细解析“括号”内的内容。 在这里,我不得不修补。 使用inja和Jinja2CppLight,表达式解析器非常简单。 在第一种情况下-在同一个regexp'ah上,在第二种情况下-手写,但是仅支持非常简单的设计。 对过滤器,测试器,复杂的算术或索引的支持是不可能的。 而我最想要的就是Jinja2的这些功能。 因此,我别无选择,只能重新整理一个完整的LL(1)解析器(在某些地方-上下文相关),以实现必要的语法。 大约十到十五年前,我可能会选择Bison或ANTLR并在他们的帮助下实现解析器。 大约七年前,我会尝试Boost.Spirit。 现在,我通过递归下降方法实现了我所需的解析器,而不会产生不必要的依赖关系,并且不会显着增加编译时间,就像使用外部实用程序或Boost.Spirit那样。 在解析器的输出中,我得到了一个AST(用于表达式或运算符),该AST被保存为模板,准备用于后续渲染。
解析逻辑的一个例子 ExpressionEvaluatorPtr<FullExpressionEvaluator> ExpressionParser::ParseFullExpression(LexScanner &lexer, bool includeIfPart) { ExpressionEvaluatorPtr<FullExpressionEvaluator> result; LexScanner::StateSaver saver(lexer); ExpressionEvaluatorPtr<FullExpressionEvaluator> evaluator = std::make_shared<FullExpressionEvaluator>(); auto value = ParseLogicalOr(lexer); if (!value) return result; evaluator->SetExpression(value); ExpressionEvaluatorPtr<ExpressionFilter> filter; if (lexer.PeekNextToken() == '|') { lexer.EatToken(); filter = ParseFilterExpression(lexer); if (!filter) return result; evaluator->SetFilter(filter); } ExpressionEvaluatorPtr<IfExpression> ifExpr; if (lexer.PeekNextToken() == Token::If) { if (includeIfPart) { lexer.EatToken(); ifExpr = ParseIfExpression(lexer); if (!ifExpr) return result; evaluator->SetTester(ifExpr); } } saver.Commit(); return evaluator; } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalOr(LexScanner& lexer) { auto left = ParseLogicalAnd(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalOr) { lexer.ReturnToken(); return left; } auto right = ParseLogicalOr(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalOr, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalAnd(LexScanner& lexer) { auto left = ParseLogicalCompare(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalAnd) { lexer.ReturnToken(); return left; } auto right = ParseLogicalAnd(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalAnd, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalCompare(LexScanner& lexer) { auto left = ParseStringConcat(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); auto tok = lexer.NextToken(); BinaryExpression::Operation operation; switch (tok.type) { case Token::Equal: operation = BinaryExpression::LogicalEq; break; case Token::NotEqual: operation = BinaryExpression::LogicalNe; break; case '<': operation = BinaryExpression::LogicalLt; break; case '>': operation = BinaryExpression::LogicalGt; break; case Token::GreaterEqual: operation = BinaryExpression::LogicalGe; break; case Token::LessEqual: operation = BinaryExpression::LogicalLe; break; case Token::In: operation = BinaryExpression::In; break; case Token::Is: { Token nextTok = lexer.NextToken(); if (nextTok != Token::Identifier) return ExpressionEvaluatorPtr<Expression>(); std::string name = AsString(nextTok.value); bool valid = true; CallParams params; if (lexer.NextToken() == '(') params = ParseCallParams(lexer, valid); else lexer.ReturnToken(); if (!valid) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<IsExpression>(left, std::move(name), std::move(params)); } default: lexer.ReturnToken(); return left; } auto right = ParseStringConcat(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(operation, left, right); }
从这里 。
AST表达式树类的片段 class ExpressionFilter; class IfExpression; class FullExpressionEvaluator : public ExpressionEvaluatorBase { public: void SetExpression(ExpressionEvaluatorPtr<Expression> expr) { m_expression = expr; } void SetFilter(ExpressionEvaluatorPtr<ExpressionFilter> expr) { m_filter = expr; } void SetTester(ExpressionEvaluatorPtr<IfExpression> expr) { m_tester = expr; } InternalValue Evaluate(RenderContext& values) override; void Render(OutStream &stream, RenderContext &values) override; private: ExpressionEvaluatorPtr<Expression> m_expression; ExpressionEvaluatorPtr<ExpressionFilter> m_filter; ExpressionEvaluatorPtr<IfExpression> m_tester; }; class ValueRefExpression : public Expression { public: ValueRefExpression(std::string valueName) : m_valueName(valueName) { } InternalValue Evaluate(RenderContext& values) override; private: std::string m_valueName; }; class SubscriptExpression : public Expression { public: SubscriptExpression(ExpressionEvaluatorPtr<Expression> value, ExpressionEvaluatorPtr<Expression> subscriptExpr) : m_value(value) , m_subscriptExpr(subscriptExpr) { } InternalValue Evaluate(RenderContext& values) override; private: ExpressionEvaluatorPtr<Expression> m_value; ExpressionEvaluatorPtr<Expression> m_subscriptExpr; }; class ConstantExpression : public Expression { public: ConstantExpression(InternalValue constant) : m_constant(constant) {} InternalValue Evaluate(RenderContext&) override { return m_constant; } private: InternalValue m_constant; }; class TupleCreator : public Expression { public: TupleCreator(std::vector<ExpressionEvaluatorPtr<>> exprs) : m_exprs(std::move(exprs)) { } InternalValue Evaluate(RenderContext&) override; private: std::vector<ExpressionEvaluatorPtr<>> m_exprs; };
从这里 。
AST树运算符的示例类 struct Statement : public RendererBase { }; template<typename T = Statement> using StatementPtr = std::shared_ptr<T>; template<typename CharT> class TemplateImpl; class ForStatement : public Statement { public: ForStatement(std::vector<std::string> vars, ExpressionEvaluatorPtr<> expr, ExpressionEvaluatorPtr<> ifExpr, bool isRecursive) : m_vars(std::move(vars)) , m_value(expr) , m_ifExpr(ifExpr) , m_isRecursive(isRecursive) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void SetElseBody(RendererPtr renderer) { m_elseBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: void RenderLoop(const InternalValue& val, OutStream& os, RenderContext& values); private: std::vector<std::string> m_vars; ExpressionEvaluatorPtr<> m_value; ExpressionEvaluatorPtr<> m_ifExpr; bool m_isRecursive; RendererPtr m_mainBody; RendererPtr m_elseBody; }; class ElseBranchStatement; class IfStatement : public Statement { public: IfStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void AddElseBranch(StatementPtr<ElseBranchStatement> branch) { m_elseBranches.push_back(branch); } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; std::vector<StatementPtr<ElseBranchStatement>> m_elseBranches; }; class ElseBranchStatement : public Statement { public: ElseBranchStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } bool ShouldRender(RenderContext& values) const; void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; };
从这里 。
AST节点仅与模板的文本相关联,并在渲染时转换为总值,同时考虑到当前渲染上下文及其参数。 这使我们能够创建线程安全模式。 但是关于实际渲染的更多信息。
作为主要标记器,我选择了
lexertk库。 它具有我需要的许可证和仅标头。 没错,我不得不中断所有计算方括号平衡的麻烦,只剩下了分词器本身,后者(在对文件稍加整理之后)学会了不仅适用于char,而且适用于wchar_t字符。 在此标记程序生成器的顶部,我包装了另一个类,该类执行三个主要功能:a)从我们正在使用的字符类型中提取解析器代码,b)识别特定于Jinja2的关键字,以及c)它提供了一个方便的接口来使用令牌流:
LexScanner class LexScanner { public: struct State { Lexer::TokensList::const_iterator m_begin; Lexer::TokensList::const_iterator m_end; Lexer::TokensList::const_iterator m_cur; }; struct StateSaver { StateSaver(LexScanner& scanner) : m_state(scanner.m_state) , m_scanner(scanner) { } ~StateSaver() { if (!m_commited) m_scanner.m_state = m_state; } void Commit() { m_commited = true; } State m_state; LexScanner& m_scanner; bool m_commited = false; }; LexScanner(const Lexer& lexer) { m_state.m_begin = lexer.GetTokens().begin(); m_state.m_end = lexer.GetTokens().end(); Reset(); } void Reset() { m_state.m_cur = m_state.m_begin; } auto GetState() const { return m_state; } void RestoreState(const State& state) { m_state = state; } const Token& NextToken() { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur ++; } void EatToken() { if (m_state.m_cur != m_state.m_end) ++ m_state.m_cur; } void ReturnToken() { if (m_state.m_cur != m_state.m_begin) -- m_state.m_cur; } const Token& PeekNextToken() const { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur; } bool EatIfEqual(char type, Token* tok = nullptr) { return EatIfEqual(static_cast<Token::Type>(type), tok); } bool EatIfEqual(Token::Type type, Token* tok = nullptr) { if (m_state.m_cur == m_state.m_end) { if(type == Token::Type::Eof && tok) *tok = EofToken(); return type == Token::Type::Eof; } if (m_state.m_cur->type == type) { if (tok) *tok = *m_state.m_cur; ++ m_state.m_cur; return true; } return false; } private: State m_state; static const Token& EofToken() { static Token eof; eof.type = Token::Eof; return eof; } };
从这里 。
因此,尽管引擎可以同时使用char和wchar_t模板,但主要的解析代码并不取决于字符的类型。 但是,在有关角色类型的冒险的部分中,有关此内容的更多信息。
另外,我不得不修改控制结构。 在Jinja2中,其中许多是配对的。 例如,对于/ endfor,if / endif,block / endblock等。该对中的每个元素都位于其自己的“括号”中,并且在这些元素之间可以有一堆所有内容:仅是纯文本和其他控制块。 因此,解析模板的算法必须在堆栈的基础上完成,所有新发现的构造和指令以及它们之间的简单文本片段“ cling”都以堆栈为基础。 使用相同的堆栈,检查if-for-endif-endfor类型是否不平衡。 由于所有这些,结果证明该代码不像Jinja2CppLight(或inja)那样“紧凑”,其中整个实现都在一个源(或标头)中。 但是解析逻辑和代码中的语法(实际上是语法)更加清晰可见,从而简化了其支持和扩展。 至少那是我的目标。 仍无法最大限度地减少依赖项数量或代码数量,因此您需要使其更易于理解。
在下一部分中,我们将讨论渲染模板的过程,但现在-链接:
Jinja2规范:
http :
//jinja.pocoo.org/docs/2.10/templates/Jinja2Cpp实现:
https :
//github.com/flexferrum/Jinja2CppJinja2CppLight实现:
https :
//github.com/hughperkins/Jinja2CppLight受伤的实现:
https :
//github.com/pantor/inja用于基于Jinja2模板生成代码的实用程序:
https :
//github.com/flexferrum/autoprogrammer/tree/jinja2cpp_refactor