最近的出版物中的评论“ R的开源生态系统在解决业务问题方面有多好?” 至于在Excel中的下载,他们提出了这样的想法,那就是花时间并描述一种无需离开R就可以实现的行之有效的方法。
这种情况很典型。 公司始终有N种方法,经理可以通过这些方法手动尝试在Excel中构建报告。 即使它们是自动化的,也总是存在紧急情况,迫切需要进行一些新的裁员或以特定形式为某个经理进行演示。
并且有许多手动支持的excel词典可以用正确的术语来转换报告和样本中数据的表示形式。
由于找不到合适的工具(额外细微差别的数量会减少),我不得不在Shiny + R上堆砌“通用构造函数”。 由于设置的通用性和可参数化性,因此此类构造函数可以轻松地植入到任何主题区域中的几乎任何系统上。
它是以前出版物的延续。
问题简要说明
- 作为技术数据的来源,有一个主要的OLAP类型存储(我们重点放在Clickhouse),几个其他存储(Postgre,MS SQL,REST API)和手册xml,json,xlsx参考。 由于需要临时分析,包括唯一值的计算,因此仅需要处理源数据,而不需要处理汇总。
- 数据库中的记录-每几百个列(时间事件)成千上万的行,建议以不超过数十秒的模式进行分析,查询可能是完全不可预测的,数据以技术形式存储(英文缩写,字典条目数等)。 ) 在目标状态下,预计原始数据约为200Tb。
- 累积的事件具有版本详细信息,即 作为系统功能,来自各种版本和来源发行版的信息会以各种方式积累,这些信息以各种方式进行报告。
- 管理人员在excel中工作良好,但不应该知道(并且实际上不知道)系统的技术组件。
如何解决问题
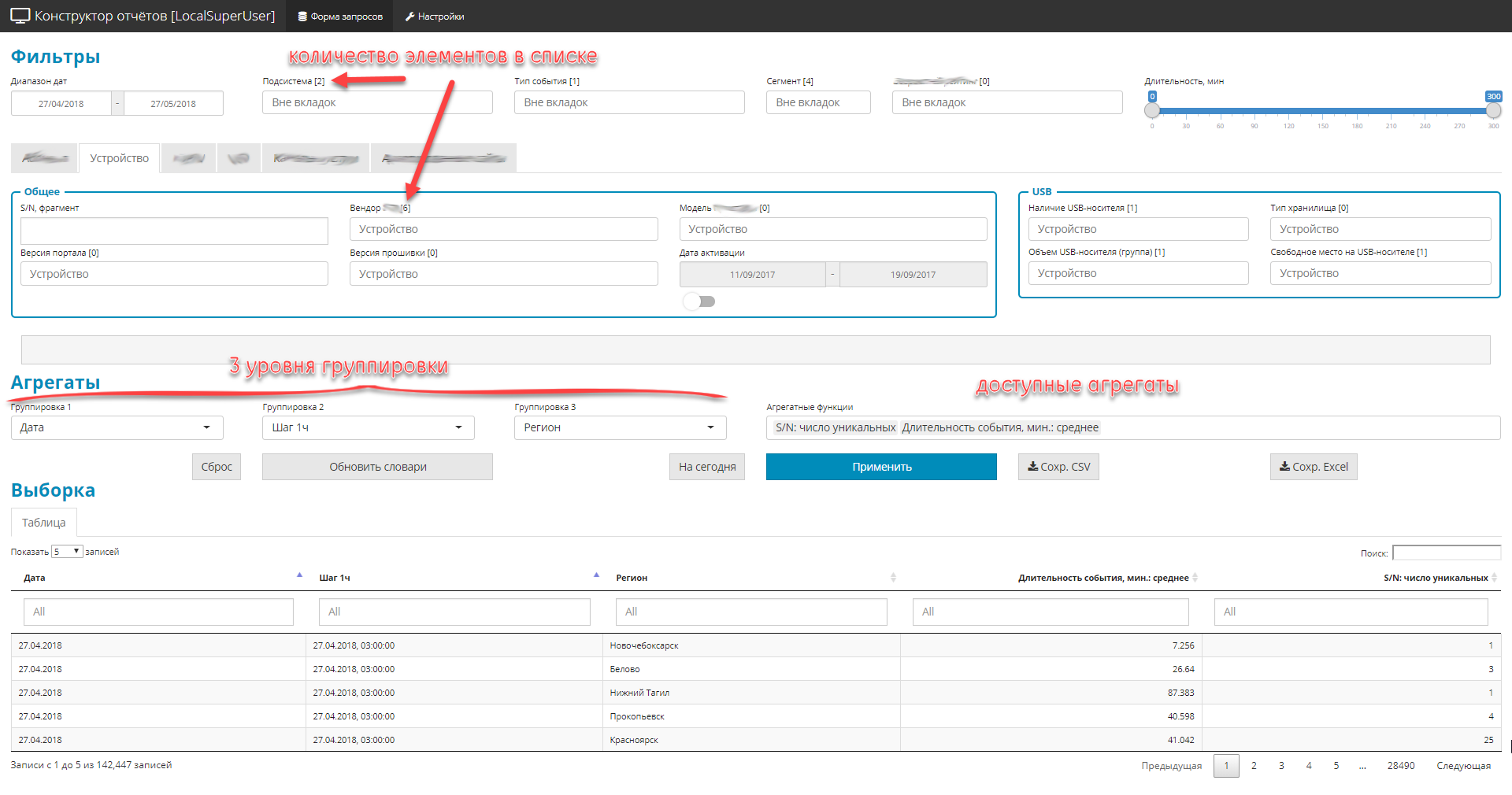
这项工作的一般情况非常简单。 经理收到了分析部门的紧急任务-经理打开应用程序,就主题领域形成任意样本-查找并扭曲表格结果-以excel格式卸载已安排的结果-为管理画一幅画。 用户界面的方便性和简单性被选择为零。
- 一切都被设计为具有导航菜单和书签的单屏幕Shiny应用程序。
- 所有控件均分为3部分:
- 过滤器(全局和专用)。 限制选择区域,有4种类型:下拉列表字典,日期,文本片段,数字范围。
- 3组查询组嵌套
- 总数量(即数量)列表。
- 由于原始源中有很多字段(大约250个),但是您需要显示所有内容,因此控制元素被分组为主题块。
接口实例
带有元信息的示例文件
幕后有用的“筹码”:
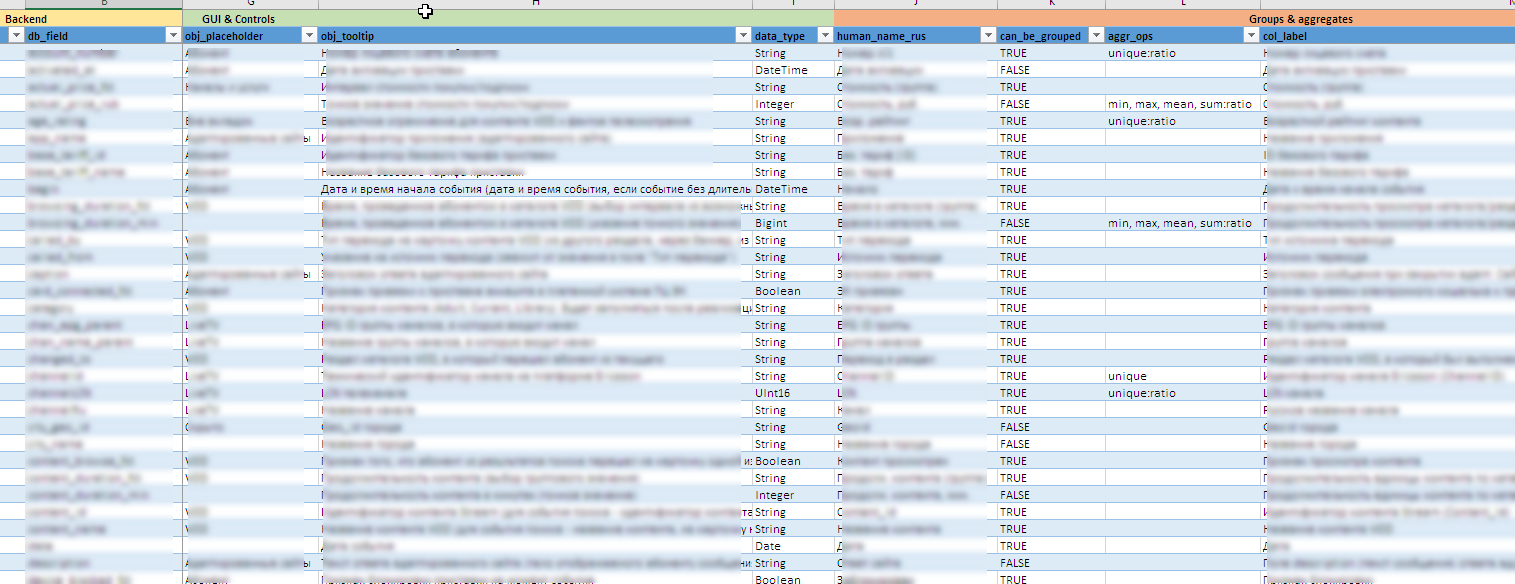
- 随着数据源的发展,整个界面配置,包括控件的创建,工具提示,可用分组和聚合的内容,excel中的导出规则等。 以excel文件形式修饰为元模型。 这使您可以快速修改新字段或计算单位的“设计器”,而无需对源代码进行重大更改(或完全不更改)。
- 很难事先说出在特定领域中可能出现的价值,而要找到一个我不知道的价值则更加困难。 手动维护所有90个动态控件几乎是不可能的。 在某些列表中,词汇表包含数百种含义。 因此,控件的字典条目将根据后端中累积的数据在后台更新。
- 管理人员需要查看所有俄语字段和内容。 并且在源中,这些数据可以以正式形式存储。 因此,结合使用Clickhouse词典技术和Shiny级别的字段值的双向后处理。 它立即提供对字段内容的规则和版本细微差别的各种例外的处理。
- 为了防止选择不正确,在列表之间进行了交叉连接以进行分组。 仅当设置了Level 1时才可以选择Level 2,而只有在设置Level 2时才可以选择Level 3,并且考虑到已经选择的值,动态减少可用值的列表。
- 一个重要的元素是控制选择内容在屏幕上以及随后上传到excel期间的控制。 在此,后处理中也有许多功能,旨在为管理人员提供便利的工具:
- 以excel文件的形式有组织地支持“可见性矩阵”。 此矩阵确定显示或隐藏选择中的某些字段,具体取决于安装的过滤器。
- 逐行动态修改样本内容。 根据各个字段的内容,可能会更改另一个字段的内容(例如,如果在“订单数量”字段中指定了0,则在“订单类型”字段中将显示一个空行。
- 个人数据显示的管理。 取决于配置的角色访问权限。 数据可以显示,也可以用
*部分遮盖。 - 精确管理。 提一下。 显示10位小数-Moveton,但是在某些情况下2位小数的精度不够。 例如,80%的对象的百分比为
0.00% -舍入时需要增加有效字符,以使两行之间的差异可见。 并且excel中的卸载量应收敛(合理地期望小数列中所有行的量在100%左右)。 - 在可用内容控件级别提供角色访问。 访问权限由json配置文件控制。
- 动态控制请求深度。 如果未指定任何分组和聚合(正在进行研究,您只需要返回属于已安装过滤器的原始数据),则会启用防止后端过载的保护。 用户可以设置1年内的搜索时间范围,但实际上需要选择中的最后1000条记录。 知道每天有数百万条记录到达,因此首先执行了减少深度的试用请求(3-7天前)。 如果收到的行数不够(严格的过滤条件),则会在整个时间段内启动完整查询。
- 以excel格式卸载收到的样本。 一切都已格式化,所有俄语内容都带有单独的表格,其中固定了所有样本参数,因此您可以轻松地了解如何获得此结果。
- 在应用程序中维护了详细的日志,因此您可以了解用户的操作以及引擎室机械师的操作。
预计可能会有关于“自行车”的评论,如果会有100%的评论,我建议立即写出带有您所知道的开源产品的标识。 我会对新发现感到高兴。
自然,必须考虑到所有高级要求,才能提供产品链接。 好吧,最好立即评估所需的基础架构。 对于此选项,两台或三台中等容量的服务器(64-128Gb; 12-20 CPU内核,基于数据量的磁盘)足以满足整个企业的需求。 ELK不适合,因为主要任务是数值分析,不适用于文本。
详细要求集
下面,作为参考,在机器-人机界面和人机界面的一部分中给出了分析单元要求的详细列表(“报告设计器”只是一部分)。
导入\导出\环境
- 日志文件仅在时间戳,模块和子系统方面进行了标准化和结构化。 系统应处理具有消息内容(记录的日志主体)中任意内容的日志文件,同时支持记录的结构化和非结构化日志主体。
- 要充实数据,系统必须至少具有用于以下类型数据源的导入适配器:
- 平面文件(csv,txt)
- 结构化文件xml,json,xlsx
- odbc兼容源,尤其是MS SQL,MySQL,PostgreSQL
- 通过REST API提供的数据。
- 系统应支持自动导入和应用户要求的导入。 导入用户数据时,系统应提供:
- 导入数据的技术验证的可能性(字段数,字段类型,完整性,值的存在的正确性)
- 逻辑验证的可能性(字段内容,验证,交叉验证等)
- 根据导入过程的逻辑配置验证参数(以任何形式)的能力;
- 有关检测到的技术和逻辑错误的详细报告,使操作员可以快速定位并消除导入数据中的故障。
- 系统至少应支持以下格式的结果导出:
- 数据导出到平面文件csv,txt
- 将数据导出到结构化xml,json,xlsx文件
- 数据导出到odbc兼容源,尤其是MS SQL,MySQL,PostgreSQL
- 通过REST API协议提供对数据的访问
- 系统应具有生成打印报告的功能:
- 根据预先形成的模板(故事讲述)将文本,表格表示形式和图形表示形式紧密结合在一起形成单个文档;
- 生成印刷表格时所有计算元素(表格,图表)的形成;
- 根据上面提到的任何协议,以即时模式使用报表准备报告时所需的外部源和目录的使用,而没有数据的集成和重复
- 以html,docx,pdf格式导出生成的报告
- 根据时间表,应按需和在后台支持打印表示的形成。
- 系统应保留有关计算,活动的用户操作或与外部系统的交互的详细日志。
- 该系统必须在现场安装。
- 安装和后续操作应在系统与Internet完全隔离的情况下进行。
计算方式
- 系统应支持在接近实时的模式下以任意时间间隔计算汇总度量(最小值,最大值,平均值,中位数,四分位数)。
- 系统必须支持在接近实时的任意时间间隔内计算基本指标(值的数量,唯一值的数量)。
- 计算聚合数据时,用户应从预定义的范围内确定聚合时间:5分钟,10分钟,15分钟,20分钟,30分钟,1小时,2小时,24小时,1周,1个月
- 系统应包括一个构造函数以形成任意样本。 可能的操作的组成应由预定义的数据元模型确定。 构造函数必须支持以下最低设置:
- 过滤日期支持:[报告期初-报告期末]
- 筛选器支持(下拉列表),可对枚举字段(例如,城市:莫斯科,圣彼得堡,...)进行多选
- 基于动态外部目录或累积数据自动形成可枚举字段过滤器的下拉列表内容。
- 支持所请求的样本中至少三个级别的数据顺序分组; 用户自行分组的参数是从元模型级别的可用数据集列表中设置的。
- 考虑到在较高分组级别中选择的字段(例如,如果在第一级选择了“城市”,则该参数在第二级或第三级不可用)限制在一个或另一个级别上可用于分组的字段的限制m个分组级别)
- 通过扩展时间参数进行分组的可能性:星期几,小时组(11-12; 12-13),星期
- 支持基本的总计:(最小值,最大值,平均值,中位数,数量,唯一数量);
- 支持测试过滤器以在选择中提供全文搜索;
- 支持根据外部目录或源数据显示根据请求获得的数据的丰富和转换的阶段。
- 该系统应具有用于计算空间坐标(sp =空间点)中的度量的机制,以支持地理分析。
- 对于时间量度(事务,操作,查询等),系统必须计算并显示查询执行时间分布的密度。
- 应该对所有对象整体以及用户使用过滤器设置的子样本执行所有计算出的指标
- 系统必须在内存中执行所有计算。
- 所有事件都有时间戳,因此系统必须支持等距和任意时间序列的工作。
- 该系统应支持配置和启用用于恢复时间序列(各种算法)中丢失的数据,确定异常,预测时间序列,分类/聚类的机制的能力。
接口部分
- 整个用户界面(包括图形和表格元素的内容)必须本地化。
- 对于表格表示形式的控件和列,应支持以静态和动态方式(例如,在工具提示中可能是用于计算的参数)形成带有详细说明的工具提示(悬停提示)的可能性。
- 只能使用HTML,CSS,JS技术构建工作场所界面,而不能使用过时的,依赖平台的或不可移植的技术,例如Adobe Flash,MS Silverlight等。
- 图表上的时间应以24小时格式显示。
- 用于在轴上显示数据的参数应支持自动缩放(标签的频率和显示格式),具体取决于值的范围。 一个典型的示例是显示一天内具有测量范围的小时数,显示一周内具有测量范围的天数。
- 系统至少应支持以下原子图形显示格式:
- 系统必须支持智能地自动放置点的某些子集的标记(例如值)的功能,这些标记的重叠最少。
- 该系统应支持将从不同数据源获得的数据的图形表示相结合的可能性。 只要坐标轴和坐标系的类型匹配,就应该支持为每个数据源指定不同的原子图形显示格式的能力。
- 对于给定的参数化变量,系统应支持原子图的构面(图划分在M x N上)。 在构面显示中,对于每个图形,X轴和Y轴都必须独立缩放。
- 图形必须支持以下特征的参数化:
- 对于数据的地理分析任务,系统必须支持使用shapefile,包括导入,显示,区域参数化的着色,并确保将各种图形元素和计算出的指示符叠加在生成的geopod上。
- 用户界面控件(列表,字段,面板等)必须根据其他元素的状态支持其内容的动态更改。 例如,当选择某个区域时,城市选择元素的内容应限于该区域包括的城市列表。
- 应支持访问报告应用程序的角色模型:
- 支持数据元模型以提供url级别的角色访问(可能/不可能)
- 支持数据元模型以在控件元素的内容级别提供基于角色的访问(例如,下拉列表中的可用对象列表由管理者的区域责任确定)
- 支持数据元模型,以确保在个人数据可视化级别上进行基于角色的访问(例如,对电子邮件号码或其他字段的特定部分进行屏蔽“ *”)
结论
该出版物的主要目的是表明R的可能性大大超出了经典统计的范围。 实际上进行了检查,没有必要牺牲质量或功能。
以前的文章- “ R的开源生态系统在解决业务问题方面有多好?” 。