麻省理工学院。 讲座课程#6.858。 “计算机系统的安全性。” Nikolai Zeldovich,James Mickens。 2014年
计算机系统安全是一门有关开发和实施安全计算机系统的课程。 讲座涵盖了威胁模型,危害安全性的攻击以及基于最新科学研究的安全技术。 主题包括操作系统(OS)安全性,功能,信息流管理,语言安全性,网络协议,硬件安全性和Web应用程序安全性。
第1课:“简介:威胁模型”
第1 部分 /
第2 部分 /
第3部分第2课:“控制黑客攻击”,
第1 部分 /
第2 部分 /
第3部分 您能告诉我缺乏使用
保护页面的安全方法的原因吗?
观众:需要更长的时间!
教授:完全是! 因此,想象一下这个堆非常非常小,但是我选择了整个页面来确保这个小小的东西不会被指针攻击。 这是一个非常占用空间的过程,人们实际上并没有在工作环境中部署类似的东西。 这对于测试“错误”可能很有用,但是对于真正的程序,您永远不会这样做。 我想现在您了解什么是
Electric fence内存调试器。
观众:为什么
保护页面这么大?
教授:原因是他们通常依靠硬件(例如页面级保护)来确定页面大小。 对于大多数计算机,每个分配的缓冲区分配2页大小为4 KB的页面,总计8 KB。 由于堆由对象组成,因此将为每个
malloc函数分配一个单独的页面。 在某些模式下,该调试器不会将保留的空间返回给程序,因此,
Electric fence在内存方面非常繁琐,因此不应使用工作代码进行编译。
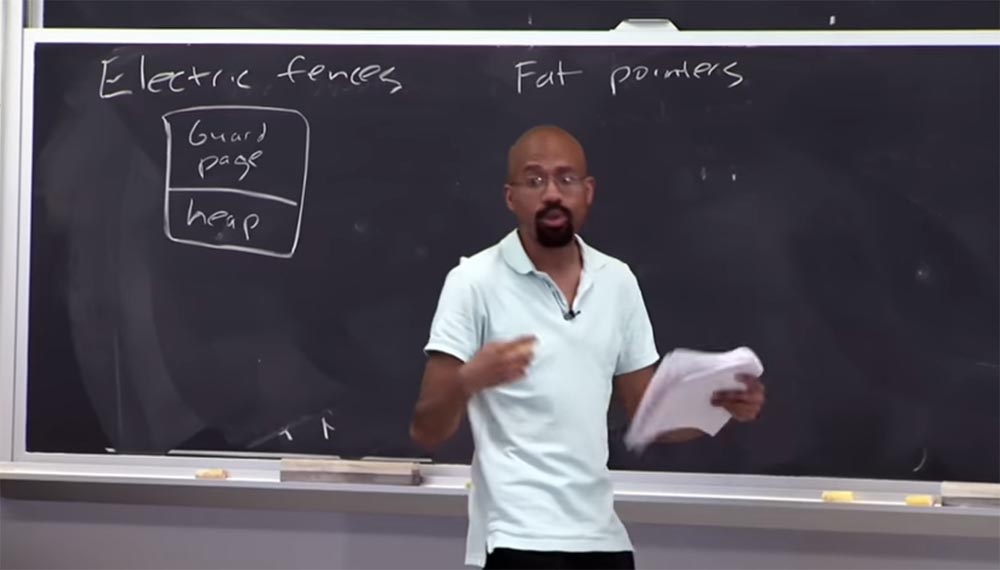
值得一看的另一种安全方法称为“胖指针”或“粗指针”。 在这种情况下,术语“厚”是指将大量数据附加到指针。 在这种情况下,我们的想法是我们要更改指针的表示形式,以便在其组成中包含有关边界的信息。
常规的32位指针由32位组成,地址位于其中。 如果我们考虑“粗指针”,则它由3部分组成。 第一部分是一个4字节的基数,还附加了4字节的结尾。 在第一部分中,对象开始,在第二部分中,对象结束,在第三个(也是4个字节)中,地址
cur被封闭。 在这些共同的界限内是一个指针。

因此,当编译器为该“粗指针”生成访问代码时,它将更新
cur地址的最后一部分的内容,并同时检查前两部分的内容,以确保在更新过程中指针没有发生任何不良情况。
想象一下我有以下代码:
int * ptr = malloc(8) ,这是分配了8个字节的指针。 接下来,我有一些
while循环 ,即将为指针分配一些值,然后是
ptr ++指针增量。 每次在
cur地址指针的当前地址上执行此代码时,它都会检查指针是否在第一部分和第二部分指定的边界内。
编译器生成的新代码就是这种情况。 在线小组经常提出什么是“工具代码”的问题。 这是编译器生成的代码。 作为程序员,您只能看到右侧显示的内容-这4行。 但是在执行此操作之前,编译器会在
cur地址中插入一些新的C代码,为指针分配一个值,并每次检查边界。

并且,如果在使用新代码时该值超出范围,则该函数将被中断。 这称为“工具代码”。 这意味着您使用C程序获取源代码,然后添加新的C源代码,然后编译新程序。 因此,
胖指针背后的基本思想非常简单。
这种方法有一些缺点。 最大的缺点是指针很大。 这意味着您不能只使用“粗细指针”并将其不变地传递到shell库之外。 因为可能期望指针具有标准大小,并且程序将为其提供该大小,因此它“不适合”该大小,因此所有内容都会爆炸。 如果您想在
结构或类似
结构中包含这种类型的指针,也会有问题,因为它们可以调整
结构的大小。
因此,在C代码中非常流行的事情是采用
struct大小的东西,然后根据此大小执行某些操作-为该大小的结构保留磁盘空间,依此类推。
而且,更为微妙的是,这些指针通常无法以原子方式进行更新。 对于32位体系结构,通常编写一个原子的32位变量。 但是“粗指针”包含3个
整数大小,因此,如果您的代码期望该指针具有原子值,则可能会遇到麻烦。 因为要进行其中的某些检查,您必须先查看当前地址,然后再查看大小,然后可能必须增加它们的大小,依此类推。 因此,如果您使用试图在常规指针和粗指针之间绘制相似的代码,则可能会导致非常细微的错误。 因此,您可以在某些情况下使用
Fat指针 ,例如
Electroc fences ,但是使用它们的副作用非常大,以至于在正常实践中这些方法都没有使用。
现在,我们将讨论有关阴影数据结构的边界检查。 该结构的主要思想是,您知道要放置的每个对象的大小,即,您需要为此对象保留的大小。 因此,例如,如果您有一个使用
malloc函数调用的指针,则需要指定对象的大小:
char xp = malloc(size) 。

如果您有类似
char p [256]这样的静态变量,则编译器可以自动确定放置位置的边界。
因此,对于这些指针中的每一个,您都需要以某种方式插入两个操作。 这主要是算术运算,例如
q = p + 7或类似的东西。 通过取消引用类型为
deref * q ='q'的链接来完成此插入。 您可能想知道为什么粘贴时不能依靠链接? 为什么我们需要做这些算术? 事实是,在使用C和c ++时,您有一个指针指向右侧对象的有效端的一遍,然后将其用作停止条件。 因此,您转到对象,并在到达此尾随指针后立即停止循环或中止操作。
因此,如果我们忽略算术,我们总是会导致严重的错误,其中指针超出了边界,这实际上会破坏许多应用程序的工作。 因此,我们不能只插入链接,因为您怎么知道这发生在既定范围之外? 算术允许我们说是否这样,在这里一切都将是合法和正确的。 因为使用算术进行的楔入允许您跟踪指针相对于其原始基线的位置。
因此,下一个问题是:我们如何真正实现边界验证? 因为我们需要以某种方式将指针的特定地址与该指针的某种类型的边界信息进行匹配。 因此,您以前的许多决定都使用诸如哈希表或树之类的东西,这些东西使您能够执行正确的搜索。 因此,给定指针的地址,我在此数据结构中进行了一些搜索,并找出了它的边界。 考虑到这些边界,我决定是否可以执行该操作。 问题在于这是一个缓慢的搜索,因为这些数据结构正在分支,并且在检查树时,您需要检查一堆这样的分支,直到找到正确的值为止。 即使它是一个哈希表,您也必须遵循代码链等。 因此,我们需要定义一个非常有效的数据结构,以跟踪其边界,这将使此验证非常简单明了。 现在让我们开始吧。
但是在我们这样做之前,让我简要地告诉您有关
伙伴内存分配方法是如何工作的。 因为这是经常被问到的事情之一。
伙伴内存分配将内存划分为2的幂的倍数的分区,并尝试在其中分配内存请求。 让我们看看它是如何工作的。 最初,
伙伴分配将未分配的内存视为一个大块-这是较高的128位矩形。 然后,当您请求较小的块进行动态分配时,它将尝试将该地址空间以2为增量拆分为多个部分,直到找到足以满足您需要的块。
假设到达类型为
a = malloc(28)的请求,即分配28个字节的请求。 我们有一个128字节的块,太浪费了,无法分配给该请求。 因此,我们的块分为两个64字节的块-从0到64字节和从64字节到128字节。 而且此大小对于我们的请求也很大,因此
伙伴再次将64字节的块分为2部分,并接收2个32字节的块。

减少是不可能的,因为不能容纳28个字节,而32是最合适的最小大小。 所以现在这32个字节的块将分配给我们的地址a。 假设我们还有一个查询
b = malloc(50) 。
Buddy检查选定的块,由于50大于64的一半,但小于64,因此将值b放在最右边的块中。
最后,我们还有一个20字节的请求:
c = malloc(20) ,该值放在中间块中。
 Buddy
Buddy有一个有趣的属性:当您释放一个块中的内存,并且在它旁边是一个相同大小的块时,释放两个块后,
buddy将两个空的相邻块合并为一个。

例如,当我们给出
free©命令时,我们将
释放中间的块,但并不会发生并集,因此它旁边的块仍然很忙。 但是使用
free(a)命令释放第一个块后,两个块将合并为一个。 然后,如果释放b的值,则相邻的块将再次合并,并且将得到一个大小为128字节的整个块,就像开始时一样。 这种方法的优点是,您可以通过简单的算术轻松找到伙伴的位置,并确定内存边界。 这就是内存分配与
伙伴内存分配方法一起工作的方式。
我所有的讲座都经常被问到这个问题,这样的方法难道不是浪费吗? 想象一下,一开始我有65个字节的请求,我将不得不为它分配整个128字节的块。 是的,这很浪费,实际上您没有动态内存,无法再在同一块中分配资源。 但是再说一次,这是一个折衷方案,因为它很容易进行计算,如何进行合并等。 因此,如果您想要更准确的内存分配,则需要使用其他方法。
那么
Buggy弹跳检查(BBC)系统有什么作用?

她执行了许多技巧,其中之一是将内存块分为两部分,其中一个包含一个对象,第二个是对其的补充。 因此,我们有2种类型的边界-对象的边界和内存分布的边界。 优点是不需要存储基址,并且可以使用线表进行快速搜索。
我们所有的分布大小都是
n的 2的幂,其中
n是整数。 这个
2n原理称为2的
幂 。 因此,我们不需要太多的位来想象特定分布的大小。 例如,如果群集大小为16,则只需选择4位-这是对数的概念,即4是
n的指数,您需要将数字2增大为16。
这是一种非常经济的内存分配方法,因为使用了最小字节数,但是它必须是2的倍数,即可以有16或32个字节,但不能是33个字节。 此外,
Buggy跳动检查使您可以将边界值的信息存储在线性数组中(每条记录1个字节),并允许您在1个插槽中分配大小为16字节的内存。 用插槽粒度分配内存。 这是什么意思?

如果我们有一个16字节的插槽,将在其中放置值
p = malloc(16) ,则表中的值将类似于
表[p / slot.size] = 4 。

假设我们现在需要将大小为
p = malloc(32)的值设置为32个字节。 我们需要更新边界表以匹配新的大小。 这完成了两次:首先作为
表[p / slot.size] = 5 ,然后作为
表[[p / slot.size] + 1] = 5-第一次分配给该内存的第一个时隙,第二次次-第二个广告位。 因此,我们分配了32个字节的内存。 这就是大小分布日志的样子。 因此,对于两个内存分配插槽,边界表将更新两次。 清楚吗? 本示例供那些怀疑日志和表格是否有意义的人使用。 因为表是在每次分配内存时都会相乘。
让我们看看边界表会发生什么。 假设我们有一个看起来像这样的代码C:
p'= p + i ,也就是说,指针
p'是 通过添加一些变量
i从
p获得的。 那么我们如何获得分配给
p的内存大小? 为此,请使用以下逻辑条件查看表:
size = 1 << table [p >> slot_size的日志]
在右侧,我们为
p分配了数据大小,应该为1。然后将其向左移动并查看表,获取指针大小,然后向右移动,即插槽大小表的日志所在的位置。 如果算术有效,则我们将指针正确绑定到边界表。 即,指针的大小必须大于1,但小于插槽的大小。 左边是值,右边是插槽的大小,指针值位于它们之间。
假设指针的大小为32个字节,那么在表格的方括号内,我们将得到数字5。
假设我们要找到此指针的基本关键字:
base = p&n(size-1) 。 我们将要做的事情给了我们一定的质量,这个质量将使我们能够恢复这里的
基地 。 假设我们的大小为16,二进制形式为16 = ... 0010000。 省略号表示仍然有很多零,但是我们对这个单位及其后面的零感兴趣。 如果我们考虑(16 -1),则看起来像这样:(16-1)= ... 0001111。 在二进制代码中,其反函数如下所示:〜(16-1)... 1110000。
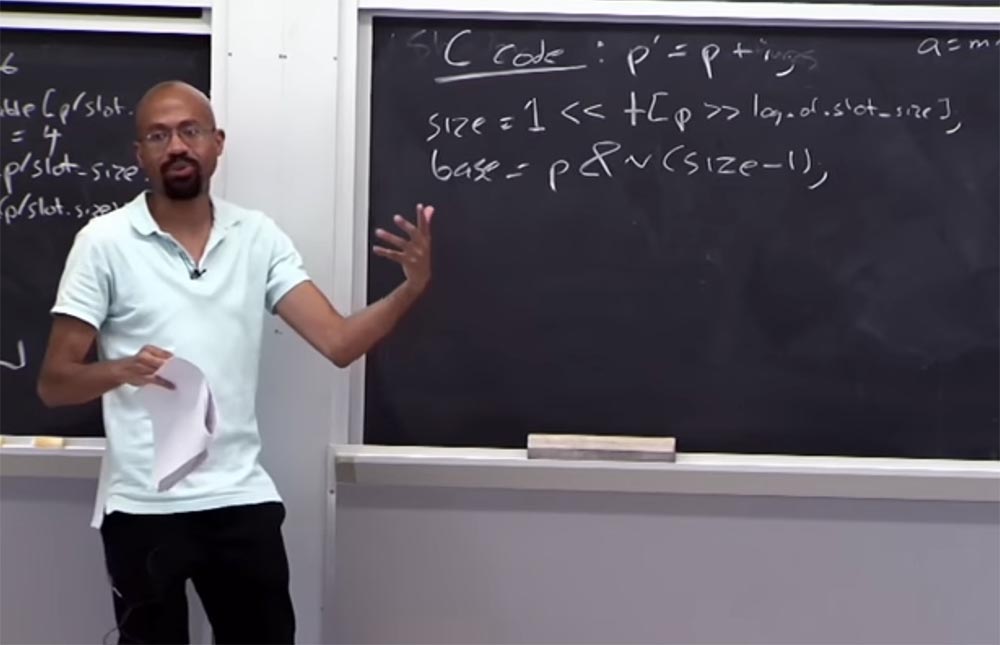

因此,该对象使我们能够基本清除该位,该位实际上将从当前指针进行渲染,并为其指定
基数 。 因此,对于我们来说检查该指针是否在边界内将非常简单。 因此,我们可以简单地检查
(p')> = base以及值(
p' -base)是否小于所选大小。

要找出指针是否在内存限制内,这是一件相当简单的事情。 我将不赘述;足以说明所有二进制算术都以相同的方式解析。 这些技巧使您可以避免更复杂的计算。
Buggy弹跳检查还有第五个属性-它使用虚拟内存系统来防止超出为指针设置的边界。 主要思想是,如果我们对指针具有这样的算法来确定出路,那么我们可以为指针设置一个高阶位。

这样,我们保证取消引用指针不会导致硬件问题。 单独将
高位设置为
高不会导致问题;指针的取消引用可能会导致问题。
该课程的完整版本可
在此处获得 。
感谢您与我们在一起。 你喜欢我们的文章吗? 想看更多有趣的资料吗? 通过下订单或将其推荐给您的朋友来支持我们,为我们为您开发
的入门级服务器的独特模拟,为Habr用户提供
30%的折扣: 关于VPS(KVM)E5-2650 v4(6核)的全部真相10GB DDR4 240GB SSD 1Gbps从$ 20还是如何划分服务器? (RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。
戴尔R730xd便宜2倍? 仅
在荷兰和美国,我们有
2台Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100电视(249美元起) ! 阅读有关
如何构建基础架构大厦的信息。 使用价格为9000欧元的Dell R730xd E5-2650 v4服务器的上等课程?