多年来,我一直将斯诺克台球视为一项运动。 它具有一切:智力游戏的迷人魅力,紧键的优美感和竞争的心理张力。 但是我不喜欢一件事-它的评分系统 。
它的主要缺点是,它仅考虑比赛成绩,而不考虑比赛的“复杂性”。 Elo模型没有这个缺点,它可以监视玩家的“力量”并根据比赛结果和对手的“力量”对其进行更新。 但是,它并不完美:人们认为所有比赛都在相同的条件下进行,而在斯诺克台球中,他们最多可以打赢一定数量的获胜帧(当事方)。 考虑到这一事实,我考虑了另一个模型,称为EloBeta 。
本文根据斯诺克比赛的结果研究Elo和EloBet模型的质量。 重要的是要注意 ,主要目标是评估参与者的“实力”并创建“公平”的评级,而不是建立获取利润的预测模型。

当前的斯诺克台球评分基于玩家在不同“体重”下的
比赛成绩 。 从前,只有世界锦标赛才考虑在内。 在出现了许多其他比赛之后,便建立了一个积分表,玩家可以在达到比赛的某个阶段时获得该积分。 现在,评分的形式为玩家在过去两个日历年中(大约)获得的“移动”奖金。
该系统有两个主要优点: 简单 (赢得很多钱-排名上升)和可预测的 (如果您想上升到某个地方-赢得一定数量的钱,所有其他条件都相同)。 问题在于, 使用这种方法时,没有考虑到对手的力量(技能,形式) 。 通常的反驳是:“如果一个球员已经达到比赛的后期,那么根据定义,他/她就是当前的强者”(“弱者不会赢得比赛”)。 听起来很令人信服。 但是,在斯诺克台球中,就像在任何运动中一样,都应考虑到这种情况的作用:如果球员“较弱”,这并不意味着他/她永远不可能在与球员的比赛中赢得“更强”。 它的发生频率比反向情况要少。 这是Elo模型出现的地方。
Elo模型的思想是,每个玩家都与一个数字评分相关联。 引入了一个假设,即可以根据两个玩家之间的评分差异来预测他们的比赛结果:较高的值表示赢得“强”(评分较高)玩家的可能性较高。 Elo等级基于当前的“力量” ,是根据与其他玩家的比赛结果得出的。 这避免了当前官方评级系统中的重大缺陷。 这种方法还可以让您在锦标赛中更新玩家的评分,以便对他的出色表现做出数字反应。
拥有Elo评分的实践经验,在我看来他应该在斯诺克中表现出色。 但是,这里有一个障碍: 它是为单一比赛类型的比赛而设计的 。 当然,存在一些变化来考虑足球本垒打和国际象棋的第一步的优势(均以为球员增加固定数量的评分点的形式)。 在斯诺克台球中,比赛以“ N之最佳”的形式进行:获胜的玩家赢得第一场胜利 Ñ = ˚F ř 一个ç Ñ + 1 2 相框(派对)。 我们还将这种格式称为“直到 ñ 胜利。”
凭直觉,“弱”玩家要赢得10场比赛(一场严肃的锦标赛的决赛)比赢得4场比赛(本国比赛的第一轮)要困难得多。 我的EloBet模型考虑了这一点 。
在斯诺克台球赛中使用Elo评分的想法绝非新鲜事。 例如,有以下作品:
- 斯诺克分析师使用“ Elo like”(更像Bradley – Terry模型 )评级系统。 想法是根据赢得的“实际”和“预期”帧数之间的差异来更新评级。 这种方法引起了疑问。 当然,帧数上的较大差异最有可能证明力量上的较大差异,但最初,玩家没有这项任务。 在斯诺克中,目标是赢得比赛的“公正”,即 在对手面前赢得一定数量的帧。
- 基本Elo模型的实现将在论坛上进行讨论 。
- 这 是业余斯诺克台球的真实用途。
- 也许我错过了其他作品。 我将非常感谢您提供有关此主题的任何信息。
复习
本文面向有兴趣研究Elo等级的R语言用户以及斯诺克爱好者。 所有实验均以可复制的想法编写。 该代码隐藏在“扰流板”下,具有注释并使用tidyverse程序包,因此对于用户而言,自己阅读R可能会很有趣。假定呈现的所有代码都是按顺序执行的。 在这里可以找到一个文件。
本文的组织方式如下:
- “ 模型”部分描述了Elo和EloBet的方法以及在R中的实现。
- 实验部分描述了计算的细节和动机:使用了哪些数据和方法 (以及为什么)以及获得了什么结果 。
- “ EloBet排名研究”部分包含将EloBet模型应用于实际斯诺克数据的结果。 他将对斯诺克台球爱好者更加感兴趣。
我们将需要以下初始化。
初始化代码# suppressPackageStartupMessages(library(dplyr)) library(tidyr) library(purrr) # library(ggplot2) # suppressPackageStartupMessages(library(comperank)) theme_set(theme_bw()) # . . set.seed(20180703)
型号
两种模型均基于以下假设:
- 有一组固定的玩家必须从“最强”(第一名)到“最弱”(最后一位)排名。
- 玩家协会排名 我 带有数字等级 [R 我 :代表玩家“力量”的数字(数值越高表示玩家越强大)。
- 比赛前的评分差异越大,“弱”玩家获胜的可能性就越小(评分较低)。
- 每次匹配后,评分都会根据其结果和之前的评分进行更新。
- 胜过对手“更强”时, 其评级应比胜过对手“较弱”时更大。 如果失败,则相反。
埃洛
Elo型号代码 #' @details . #' `...` . #' #' @return , 1 ( `rating1`) #' 2 ( `rating2`). #' . elo_win_prob <- function(rating1, rating2, ksi = 400, ...) { norm_rating_diff <- (rating2 - rating1) / ksi 1 / (1 + 10^norm_rating_diff) } #' @return , #' `comperank::add_iterative_ratings()`. elo_fun_gen <- function(K, ksi = 400) { function(rating1, score1, rating2, score2) { comperank::elo(rating1, score1, rating2, score2, K = K, ksi = ksi)[1, ] } }
Elo Model通过以下过程更新评级:
计算某个球员赢得比赛的概率(比赛开始之前)。 具有标识符的一个玩家获胜(我们称其为“第一”)的概率 我 并评分 [R 我 在另一个具有标识符的播放器(“第二个”)上 Ĵ 并评分 [R Ĵ 等于
P r (r i ,r j ) = f r a c 1 1 + 10 (r j - r i )/ 400
使用这种方法,概率计算服从第三个假设。
将差异标准化为400是一种数学方法,可以说出哪个差异被认为是“大”。 该数字可以用模型参数代替。 X 我 但是,这仅影响未来收视率的范围,通常是多余的。 值400是相当标准的。
在一般情况下,获胜的可能性等于 L (r j - r i ) 在哪里 L ( x ) 一些严格增加的函数,其值从0到1。我们将使用逻辑曲线。 可以在本文中找到更完整的研究。
比赛结果计算 小号 。 在基本模型中,如果第一个玩家获胜(第二个失败),则等于1;如果平局,则等于0.5;如果失败,则等于0(第二个胜利)。
评分更新 :
- delta=K cdot(S−Pr(ri,rj)) 。 这是评级将改变的量。 她使用系数 K (模型的唯一参数)。 少一点 K (具有相等的概率)表示收视率变化较小-该模型较为保守,即 为了“证明”力量的改变,需要更多的胜利。 另一方面,更多 K 意味着最新结果比当前评级更具可信度。 选择“最佳” K 是创建“良好”评级系统的一种方法 。
- r_i ^ {{(new)} = r_i + \ delta , r(新)j=rj− delta 。
备注 :
当然,Elo模型具有自己的(相当高级的) 实用功能 。 但是,对于我们的研究而言,最重要的是以下几点:假定所有比赛都处于平等地位。 这意味着不考虑比赛的距离:最多获得4场比赛的胜利与获得最多10场比赛的胜利相同。 舞台模型EloBeta来了。
埃洛贝塔
EloBet模型代码 #' @details . #' #' @return , 1 ( `rating1`) #' 2 ( `rating2`). `frames_to_win` #' . #' . elobeta_win_prob <- function(rating1, rating2, frames_to_win, ksi = 400, ...) { prob_frame <- elo_win_prob(rating1 = rating1, rating2 = rating2, ksi = ksi) # , `frames_to_win` # # (`prob_frame`). . pbeta(prob_frame, frames_to_win, frames_to_win) } #' @return : 1 / #' (), 0.5 0 / (). get_match_result <- function(score1, score2) { # () , . near_score <- dplyr::near(score1, score2) dplyr::if_else(near_score, 0.5, as.numeric(score1 > score2)) } #' @return , #' `add_iterative_ratings()`. elobeta_fun_gen <- function(K, ksi = 400) { function(rating1, score1, rating2, score2) { prob_win <- elobeta_win_prob( rating1 = rating1, rating2 = rating2, frames_to_win = pmax(score1, score2), ksi = ksi ) match_result <- get_match_result(score1, score2) delta <- K * (match_result - prob_win) c(rating1 + delta, rating2 - delta) } }
在Elo模型中,收视率的差异直接影响赢得整个比赛的概率。 EloBet模型的主要思想是评级差异对一帧获胜概率的直接影响以及对 玩家获胜概率的显式计算 n 对手前的帧 。
问题仍然存在:如何计算这种可能性? 事实证明,这是概率论历史上最古老的问题之一,并且有自己的名字- 下注问题(积分问题)。 在本文中可以找到一个很好的演示。 使用其表示法,期望的概率为:
P(n,n)= sum limits2n−1j=n2n−1\选择jpj(1−p)2n−1−j
在这里 P(n,n) -之前第一个赢得比赛的玩家的概率 n 胜利 p -他/她在一帧中获胜的概率(对手有概率 1−p ) 通过这种方法,假定匹配内的帧结果彼此独立 。 这可能令人怀疑,但这是此模型的必要假设。
有没有更快的计算方法? 事实证明答案是肯定的。 经过数小时的公式转换,实际实验和Internet搜索,我发现以下关于正则化不完整beta函数的 属性 Ix(a,b) 。 替代 m=k,〜n=2k−1 进入该属性并替换 k 在 n 原来 P(n,n)=Ip(n,n) 。
对于R用户来说,这也是个好消息,因为 Ip(n,n) 可以计算为pbeta(p, n, n) 。 注意 :一般情况下获胜的概率 n 对手获胜之前的帧数 m 也可以计算为 Ip(n,m) 和pbeta(p, n, m)分别。 这为更新比赛中获胜的可能性提供了巨大的机会。
EloBet模型框架内的评级更新过程具有以下形式(已知评级) ri 和 rj 获胜所需的帧数 n 和比赛的结果 S ,如Elo模型中所示):
- 计算第一帧中第一名玩家获胜的概率 : p=Pr(ri,rj)= frac11+10(rj−ri)/400 。
- 计算该球员在比赛中获胜的概率 : PrBeta(ri,rj)=Ip(n,n) 。 例如,如果 p 等于0.4,则在赢得4场胜利之前赢得比赛的概率降至0.29,而在“达到18场胜利”中降至0.11。
- 评分更新 :
- delta=K cdot(S−PrBeta(ri,rj)) 。
- r_i ^ {{(new)} = r_i + \ delta , r(新)j=rj− delta 。
注意 :因为 评级差异直接影响一帧获胜的可能性,而不是整个比赛,应该期望较低的最佳系数值 K :部分价值 delta 来自增强作用 PrBeta(ri,rj) 。
基于在一帧中获胜的概率来计算比赛结果的想法并不是很新。 在FrançoisLabelle的网站上 ,您可以在线计算赢得“最佳 N “比对,以及其他功能。我很高兴看到我们的计算结果是一致的。但是,我找不到任何来源将这种方法引入Elo评级的更新过程。像以前一样,我将非常感谢您提供有关此主题的任何信息。
我只能在步步高游戏服务器(FIBS)上找到本文和Elo系统的说明 。 还有一个俄语类似物 。 在此,通过将等级差异乘以比赛距离的平方根来考虑不同的比赛持续时间。 但是,它似乎没有任何理论上的依据。
实验
实验有几个目标。 根据斯诺克比赛的结果:
- 确定最佳系数值 K 对于两种型号。
- 从预测概率的准确性方面研究模型的稳定性。
- 研究使用“邀请”锦标赛对等级的影响。
- 为所有职业球员创建2017/18赛季的公平评分历史。
资料
实验数据生成代码 # "train", "validation" "test" split_cases <- function(n, props = c(0.5, 0.25, 0.25)) { breaks <- n * cumsum(head(props, -1)) / sum(props) id_vec <- findInterval(seq_len(n), breaks, left.open = TRUE) + 1 c("train", "validation", "test")[id_vec] } pro_players <- snooker_players %>% filter(status == "pro") # pro_matches_all <- snooker_matches %>% # filter(!walkover1, !walkover2) %>% # semi_join(y = pro_players, by = c(player1Id = "id")) %>% semi_join(y = pro_players, by = c(player2Id = "id")) %>% # 'season' left_join( y = snooker_events %>% select(id, season), by = c(eventId = "id") ) %>% # arrange(endDate) %>% # widecr transmute( game = seq_len(n()), player1 = player1Id, score1, player2 = player2Id, score2, matchId = id, endDate, eventId, season, # ("train", "validation" "test") # 50/25/25 matchType = split_cases(n()) ) %>% # widecr as_widecr() # (, # , Championship League). pro_matches_off <- pro_matches_all %>% anti_join( y = snooker_events %>% filter(type == "Invitational"), by = c(eventId = "id") ) # get_split <- . %>% count(matchType) %>% mutate(share = n / sum(n)) # 50/25/25 (train/validation/test) pro_matches_all %>% get_split() ## # A tibble: 3 x 3 ## matchType n share ## <chr> <int> <dbl> ## 1 test 1030 0.250 ## 2 train 2059 0.5 ## 3 validation 1029 0.250 # , # . , # __ __, `pro_matches_all`. # , __ # __. pro_matches_off %>% get_split() ## # A tibble: 3 x 3 ## matchType n share ## <chr> <int> <dbl> ## 1 test 820 0.225 ## 2 train 1810 0.497 ## 3 validation 1014 0.278 # K k_grid <- 1:100
我们将使用comperank数据包中的斯诺克数据。 原始来源是snooker.org 。 结果来自以下比赛:
- 这场比赛是在2016/17或2017/18赛季进行的 。
- 这场比赛是“专业”斯诺克比赛的一部分 ,即:
- 类型为“激励”,“合格”或“排名”。 我们还将区分两组比赛:“所有比赛”(从所有锦标赛数据中)和“官方比赛”(不包括邀请赛)。 这有两个原因:
- 在邀请赛中,并非所有玩家都有机会更改其评分。 在Elo和EloBet模型的框架内,这不一定是不好的,但它具有“不公正的色彩”。
- 人们认为,球员只在正式比赛中“认真”对待。 注意 :大多数邀请赛是冠军联赛的一部分,我认为大多数选手都接受。
不是很认真 具有赚钱能力的实践形式。 这些锦标赛的存在可能会影响排名。 除“冠军联赛”外,还有其他邀请赛:“ 2016年中国冠军赛”,“冠军冠军”,“大师赛”,“ 2017年香港大师赛”,“ 2017年世界运动会”,“ 2017年罗马尼亚大师赛”。
- 描述单个玩家(而非团队)之间的传统斯诺克台球(不是6个红色或Power Snooker)。
- 男女均可参与(不仅限于男性或女性)。
- 所有年龄段的玩家都可以参加(不仅是老年人或“ 21岁以下”)。
- 这不是“淘汰”,因为 这些锦标赛将另外存储在snooker.org数据库中。
- 比赛真正开始了 :其结果是两名玩家参与的真实比赛的结果。
- 比赛在两名专业人士之间举行 。 2017/18赛季的专业人员列表(131名球员)。 这个决定似乎是最有争议的,因为 在业余爱好者的参与下取消比赛“视而不见”,使专业人员从业余爱好者中失败。 这导致这些参与者的不公平优势。 在我看来,这样的决定对于减少考虑到与业余选手的比赛时将出现的等级膨胀是必要的。 另一种方法是一起研究专业人员和业余人员,但这在本研究的框架内似乎是不合理的。 专业业余选手的失败被认为是失去提高评分的机会。
最终的比赛数是“所有比赛”为4118,“正式比赛”为3644(每人分别为62.9和55.6)。
方法论
实验功能代码 #' @param matches `longcr` `widecr` `matchType` #' ( : "train", "validation" "test"). #' @param test_type . #' #' ("") . , #' `game`. #' @param k_vec K . #' @param rate_fun_gen , K #' `add_iterative_ratings()`. #' @param get_win_prob #' (`rating1`, `rating2`) , #' (`frames_to_win`). ____: #' . #' @param initial_ratings #' `add_iterative_ratings()`. #' #' @details : #' - `matches` #' `game`. #' - `test_type`: #' - 1. #' - : 1 / #' (), 0.5 0 / (). #' - RMSE: , #' "" - . #' #' @return Tibble 'k' K 'goodness' #' RMSE. compute_goodness <- function(matches, test_type, k_vec, rate_fun_gen, get_win_prob, initial_ratings = 0) { cat("\n") map_dfr(k_vec, function(cur_k) { # cat(cur_k, " ") matches %>% arrange(game) %>% add_iterative_ratings( rate_fun = rate_fun_gen(cur_k), initial_ratings = initial_ratings ) %>% left_join(y = matches %>% select(game, matchType), by = "game") %>% filter(matchType %in% test_type) %>% mutate( # framesToWin = pmax(score1, score2), # 1 `framesToWin` winProb = get_win_prob( rating1 = rating1Before, rating2 = rating2Before, frames_to_win = framesToWin ), result = get_match_result(score1, score2), squareError = (result - winProb)^2 ) %>% summarise(goodness = sqrt(mean(squareError))) }) %>% mutate(k = k_vec) %>% select(k, goodness) } #' `compute_goodness()` compute_goodness_wrap <- function(matches_name, test_type, k_vec, rate_fun_gen_name, win_prob_fun_name, initial_ratings = 0) { matches_tbl <- get(matches_name) rate_fun_gen <- get(rate_fun_gen_name) get_win_prob <- get(win_prob_fun_name) compute_goodness( matches_tbl, test_type, k_vec, rate_fun_gen, get_win_prob, initial_ratings ) } #' #' #' @param test_type `test_type` ( ) #' `compute_goodness()`. #' @param rating_type ( ). #' @param data_type . #' @param k_vec,initial_ratings `compute_goodness()`. #' #' @details #' . #' , , #' : #' - "pro_matches_" + `< >` + `< >` . #' - `< >` + "_fun_gen" . #' - `< >` + "_win_prob" , #' . #' #' @return Tibble : #' - __testType__ <chr> : . #' - __ratingType__ <chr> : . #' - __dataType__ <chr> : . #' - __k__ <dbl/int> : K. #' - __goodness__ <dbl> : . do_experiment <- function(test_type = c("validation", "test"), rating_type = c("elo", "elobeta"), data_type = c("all", "off"), k_vec = k_grid, initial_ratings = 0) { crossing( testType = test_type, ratingType = rating_type, dataType = data_type ) %>% mutate( dataName = paste0("pro_matches_", testType, "_", dataType), kVec = rep(list(k_vec), n()), rateFunGenName = paste0(ratingType, "_fun_gen"), winProbFunName = paste0(ratingType, "_win_prob"), initialRatings = rep(list(initial_ratings), n()), experimentData = pmap( list(dataName, testType, kVec, rateFunGenName, winProbFunName, initialRatings), compute_goodness_wrap ) ) %>% unnest(experimentData) %>% select(testType, ratingType, dataType, k, goodness) }
"" K K=1,2,...,100 。 , . :
- K :
- . , .
add_iterative_ratings() comperank . " ", .. . - , ( ) , . RMSE ( ) ( ). , RMSE=√1|T|∑t∈T(St−Pt)2 在哪里 T — , |T| — , St — , Pt — ( ). , " " .
- K RMSE . "" , RMSE K ( ). 0.5 ( "" 0.5) .
, : "train" (), "validation" () "test" (). , .. "train"/"validation" , "validation"/"test". 50/25/25 " ". " " " " . : 49.7/27.8/22.5. , , .
:
- : .
- : " " " " ( ". ").
- : "" ( "validation" RMSE "" "train" ) "" ( "test" RMSE "" "train" "validation" ).
结果
pro_matches_validation_all <- pro_matches_all %>% filter(matchType != "test") pro_matches_validation_off <- pro_matches_off %>% filter(matchType != "test") pro_matches_test_all <- pro_matches_all pro_matches_test_off <- pro_matches_off
# experiment_tbl <- do_experiment()
plot_data <- experiment_tbl %>% unite(group, ratingType, dataType) %>% mutate( testType = recode( testType, validation = "", test = "" ), groupName = recode( group, elo_all = ", ", elo_off = ", . ", elobeta_all = ", ", elobeta_off = ", . " ), # groupName = factor(groupName, levels = unique(groupName)) ) compute_optimal_k <- . %>% group_by(testType, groupName) %>% slice(which.min(goodness)) %>% ungroup() compute_k_labels <- . %>% compute_optimal_k() %>% mutate(label = paste0("K = ", k)) %>% group_by(groupName) %>% # K , # . - # . mutate(hjust = - (k == max(k)) * 1.1 + 1.05) %>% ungroup() plot_experiment_results <- function(results_tbl) { ggplot(results_tbl) + geom_hline( yintercept = 0.5, colour = "#AA5555", size = 0.5, linetype = "dotted" ) + geom_line(aes(k, goodness, colour = testType)) + geom_vline( data = compute_optimal_k, mapping = aes(xintercept = k, colour = testType), linetype = "dashed", show.legend = FALSE ) + geom_text( data = compute_k_labels, mapping = aes(k, Inf, label = label, hjust = hjust), vjust = 1.2 ) + facet_wrap(~ groupName) + scale_colour_manual( values = c(`` = "#377EB8", `` = "#FF7F00"), guide = guide_legend(title = "", override.aes = list(size = 4)) ) + labs( x = " K", y = " (RMSE)", title = " ", subtitle = paste0( ' ( ) ', ' .\n', ' K ( ', '"") , .' ) ) + theme(title = element_text(size = 13), strip.text = element_text(size = 12)) } plot_experiment_results(plot_data)
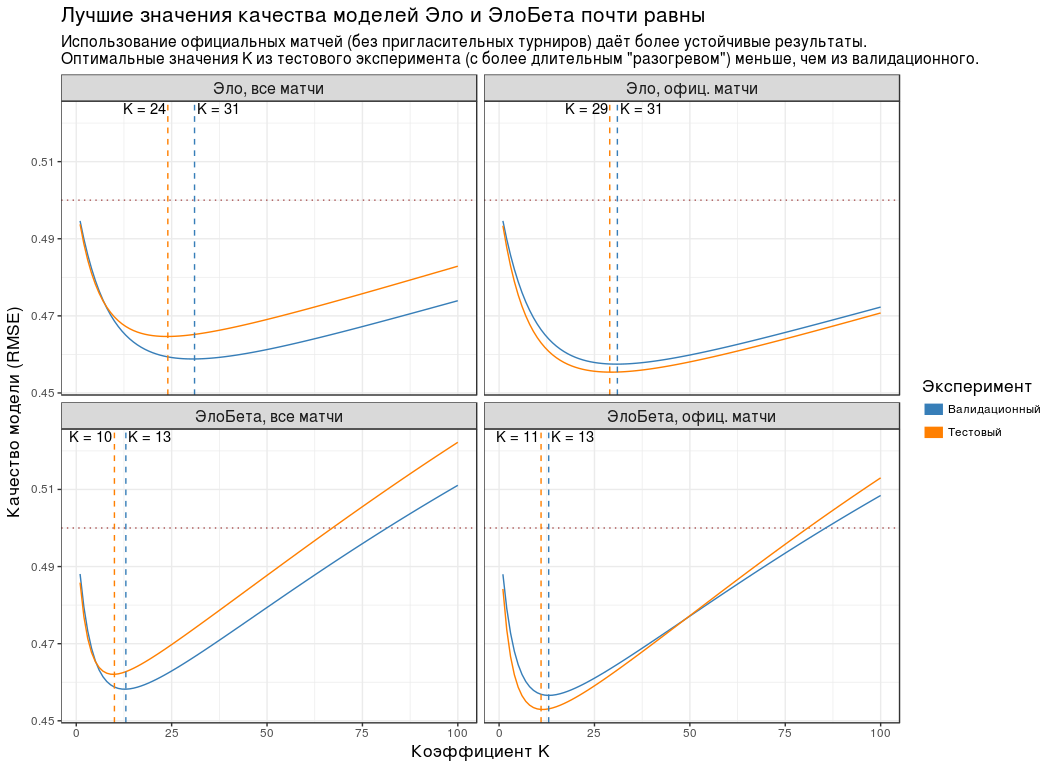
:
- , K , .
- ( "" "" ). , . - "Championship League": 3 .
- RMSE K . , RMSE K "" "". , " " .
- K ( "") , . "", .
- RMSE . 0.5. .
| K | RMSE |
|---|
| , | 24 | 0.465 |
| , . | 29日 | 0.455 |
| , | 10 | 0.462 |
| , . | 11 | 0.453 |
因为 , K " " ( ) 5: 30, — 10.
, K=30 K=10 . , n , .
" " ( K=10 ) - .
-16 2017/18
-16 2017/18 # gather_to_longcr <- function(tbl) { bind_rows( tbl %>% select(-matches("2")) %>% rename_all(funs(gsub("1", "", .))), tbl %>% select(-matches("1")) %>% rename_all(funs(gsub("2", "", .))) ) %>% arrange(game) } # K best_k <- experiment_tbl %>% filter(testType == "test", ratingType == "elobeta", dataType == "off") %>% slice(which.min(goodness)) %>% pull(k) #!!! "" , .. !!! best_k <- round(best_k / 5) * 5 # elobeta_ratings <- rate_iterative( pro_matches_test_off, elobeta_fun_gen(best_k), initial_ratings = 0 ) %>% rename(ratingEloBeta = rating_iterative) %>% arrange(desc(ratingEloBeta)) %>% left_join( y = snooker_players %>% select(id, playerName = name), by = c(player = "id") ) %>% mutate(rankEloBeta = order(ratingEloBeta, decreasing = TRUE)) %>% select(player, playerName, ratingEloBeta, rankEloBeta) elobeta_top16 <- elobeta_ratings %>% filter(rankEloBeta <= 16) %>% mutate( rankChr = formatC(rankEloBeta, width = 2, format = "d", flag = "0"), ratingEloBeta = round(ratingEloBeta, 1) ) official_ratings <- tibble( player = c( 5, 1, 237, 17, 12, 16, 224, 30, 68, 154, 97, 39, 85, 2, 202, 1260 ), rankOff = c( 2, 3, 4, 1, 5, 7, 6, 13, 16, 10, 8, 9, 26, 17, 12, 23 ), ratingOff = c( 905750, 878750, 751525, 1315275, 660250, 543225, 590525, 324587, 303862, 356125, 453875, 416250, 180862, 291025, 332450, 215125 ) )
-16 2017/18 ( snooker.org):
| | | . 地方 | . | |
|---|
| Ronnie O'Sullivan | 1个 | 128.8 | 2 | 905 750 | 1个 |
| Mark J Williams | 2 | 123.4 | 3 | 878 750 | 1个 |
| John Higgins | 3 | 112.5 | 4 | 751 525 | 1个 |
| Mark Selby | 4 | 102.4 | 1个 | 1 315 275 | -3 |
| Judd Trump | 5 | 92.2 | 5 | 660 250 | 0 |
| Barry Hawkins | 6 | 83.1 | 7 | 543 225 | 1个 |
| Ding Junhui | 7 | 82.8 | 6 | 590 525 | -1 |
| Stuart Bingham | 8 | 74.3 | 13 | 324 587 | 5 |
| Ryan Day | 9 | 71.9 | 16 | 303 862 | 7 |
| Neil Robertson | 10 | 70.6 | 10 | 356 125 | 0 |
| Shaun Murphy | 11 | 70.1 | 8 | 453 875 | -3 |
| Kyren Wilson | 12 | 70.1 | 9 | 416 250 | -3 |
| Jack Lisowski | 13 | 68.8 | 26 | 180 862 | 13 |
| Stephen Maguire | 14 | 63.7 | 17 | 291 025 | 3 |
| Mark Allen | 15 | 63.7 | 12 | 332 450 | -3 |
| Yan Bingtao | 16 | 61.6 | 23 | 215 125 | 7 |
:
- №1 3 . , , ( ).
- "" ( 13 ), ( 7 ).
- 5 . , 6 - WPBSA. , - "" . : , — .
- .
- ( №11), (№14) (№15) -16. "" (№26), (№23) (№17).
. , №16 (Yan Bingtao) №1 (Ronnie O'Sullivan) 0.404. 4 0.299, " 10 " — 0.197 18 — 0.125. , .
# seasons_break <- ISOdatetime(2017, 5, 2, 0, 0, 0, tz = "UTC") # elobeta_history <- pro_matches_test_off %>% add_iterative_ratings(elobeta_fun_gen(best_k), initial_ratings = 0) %>% gather_to_longcr() %>% left_join(y = pro_matches_test_off %>% select(game, endDate), by = "game") # plot_all_elobeta_history <- function(history_tbl) { history_tbl %>% mutate(isTop16 = player %in% elobeta_top16$player) %>% ggplot(aes(endDate, ratingAfter, group = player)) + geom_step(data = . %>% filter(!isTop16), colour = "#C2DF9A") + geom_step(data = . %>% filter(isTop16), colour = "#22A01C") + geom_hline(yintercept = 0, colour = "#AAAAAA") + geom_vline( xintercept = seasons_break, linetype = "dotted", colour = "#E41A1C", size = 1 ) + geom_text( x = seasons_break, y = Inf, label = " 2016/17", colour = "#E41A1C", hjust = 1.05, vjust = 1.2 ) + scale_x_datetime(date_labels = "%Y-%m") + labs( x = NULL, y = " ", title = paste0( " -16 2016/17" ), subtitle = paste0( " ", " ." ) ) + theme(title = element_text(size = 13)) } plot_all_elobeta_history(elobeta_history)
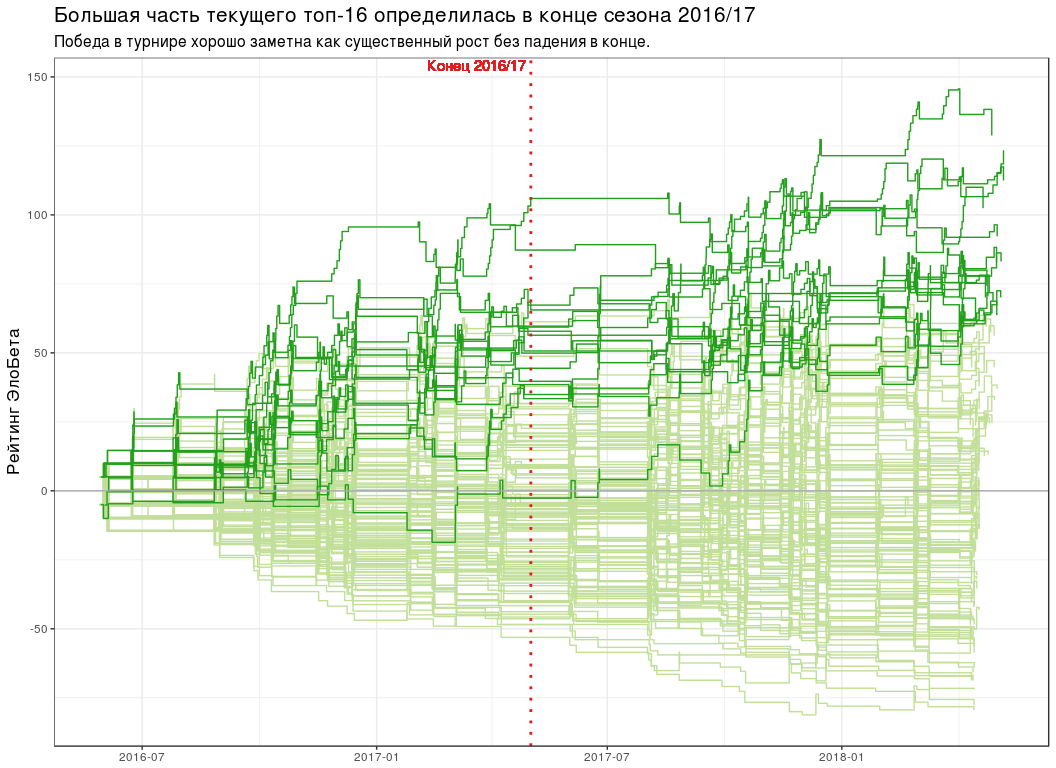
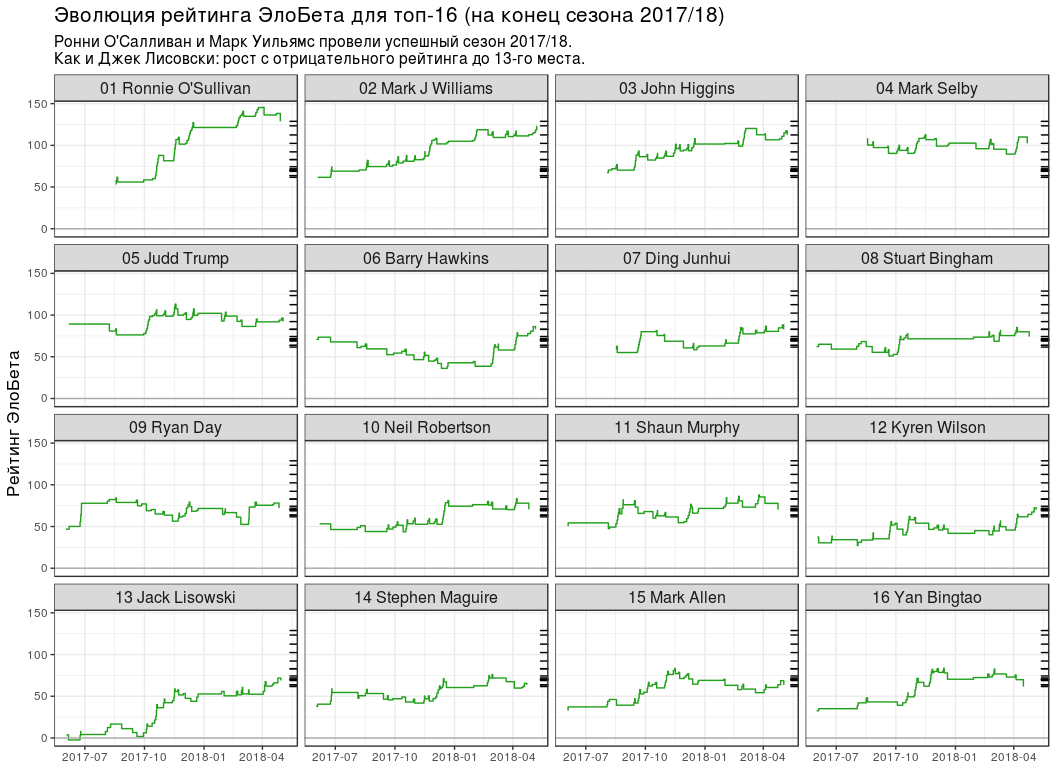
-16
-16 # top16_rating_evolution <- elobeta_history %>% # `inner_join` `elobeta_top16` inner_join(y = elobeta_top16 %>% select(-ratingEloBeta), by = "player") %>% # 2017/18 semi_join( y = pro_matches_test_off %>% filter(season == 2017), by = "game" ) %>% mutate(playerLabel = paste(rankChr, playerName)) # plot_top16_elobeta_history <- function(elobeta_history) { ggplot(elobeta_history) + geom_step(aes(endDate, ratingAfter, group = player), colour = "#22A01C") + geom_hline(yintercept = 0, colour = "#AAAAAA") + geom_rug( data = elobeta_top16, mapping = aes(y = ratingEloBeta), sides = "r" ) + facet_wrap(~ playerLabel, nrow = 4, ncol = 4) + scale_x_datetime(date_labels = "%Y-%m") + labs( x = NULL, y = " ", title = " -16 ( 2017/18)", subtitle = paste0( " ' 2017/18.\n", " : 13- ." ) ) + theme(title = element_text(size = 13), strip.text = element_text(size = 12)) } plot_top16_elobeta_history(top16_rating_evolution)
结论
- " " R :
pbeta(p, n, m) . - — "best of N " ( n ). .
- K=30 K=10 .
- :
sessionInfo() ## R version 3.4.4 (2018-03-15) ## Platform: x86_64-pc-linux-gnu (64-bit) ## Running under: Ubuntu 16.04.4 LTS ## ## Matrix products: default ## BLAS: /usr/lib/openblas-base/libblas.so.3 ## LAPACK: /usr/lib/libopenblasp-r0.2.18.so ## ## locale: ## [1] LC_CTYPE=ru_UA.UTF-8 LC_NUMERIC=C ## [3] LC_TIME=ru_UA.UTF-8 LC_COLLATE=ru_UA.UTF-8 ## [5] LC_MONETARY=ru_UA.UTF-8 LC_MESSAGES=ru_UA.UTF-8 ## [7] LC_PAPER=ru_UA.UTF-8 LC_NAME=C ## [9] LC_ADDRESS=C LC_TELEPHONE=C ## [11] LC_MEASUREMENT=ru_UA.UTF-8 LC_IDENTIFICATION=C ## ## attached base packages: ## [1] stats graphics grDevices utils datasets methods base ## ## other attached packages: ## [1] bindrcpp_0.2.2 comperank_0.1.0 comperes_0.2.0 ggplot2_2.2.1 ## [5] purrr_0.2.5 tidyr_0.8.1 dplyr_0.7.6 ## ## loaded via a namespace (and not attached): ## [1] Rcpp_0.12.17 knitr_1.20 bindr_0.1.1 magrittr_1.5 ## [5] munsell_0.5.0 tidyselect_0.2.4 colorspace_1.3-2 R6_2.2.2 ## [9] rlang_0.2.1 highr_0.7 plyr_1.8.4 stringr_1.3.1 ## [13] tools_3.4.4 grid_3.4.4 gtable_0.2.0 utf8_1.1.4 ## [17] cli_1.0.0 htmltools_0.3.6 lazyeval_0.2.1 yaml_2.1.19 ## [21] assertthat_0.2.0 rprojroot_1.3-2 digest_0.6.15 tibble_1.4.2 ## [25] crayon_1.3.4 glue_1.2.0 evaluate_0.10.1 rmarkdown_1.10 ## [29] labeling_0.3 stringi_1.2.3 compiler_3.4.4 pillar_1.2.3 ## [33] scales_0.5.0 backports_1.1.2 pkgconfig_2.0.1