
以kaggle InClass格式进行的DataScienceGame2018
排位赛阶段最近结束。
DataScienceGame是
一年一度的国际学生比赛。 我们的团队在100多个团队中名列第三,同时请勿进入最后阶段。
团队互动

在大型kaggle比赛中,团队通常是由排行榜上处于领先地位的人(
团队的
典型示例 )组成的,因此代表着不同的城市,通常是不同的国家。 立即根据竞赛的条款,每个团队应由来自一所教育机构(我们代表MIPT)的4个人组成。 在我看来,这意味着大多数参与者都在线下进行了所有讨论。 例如,我们整个团队都住在旅馆的一层,所以晚上我们只和一个人在房间里聚会。
我们没有任务,计划或团队建设的分离。 在比赛开始时,我们只是围成一圈坐下来,讨论了将来可以做的事情,没有做。 该代码是由一个人编写的,当时的其他人只是看了一下就给出了建议。 我不太喜欢编写代码,因此尽管很显然这不是最好的,但我还是喜欢这种交互。 但是由于排位赛正好是在大学期间,所以团队的一部分不能花很多时间,我仍然必须自己编写代码。
任务说明
根据BNP提供的历史记录,有必要预测用户下周是否会对某种安全性(Isin)感兴趣。 同时,TradeStatus列确定了“利息”,该列描述了交易的状态并具有以下唯一值:
- 交易已完成(即用户购买/出售的纸张)
- 用户查看了文件,但未完成交易
- 用户预留纸张以供将来购买/销售
- 由于技术原因,该交易未完成。
- 控股
因此,如果TradeStatus的值为1)-4),则认为用户对本文感兴趣,而对其他所有情况都不感兴趣。 同时,第4)段指出,与该交易有关的行是虚构的,是为了方便报告。 即,在每个月的月末,将每个用户投资组合的状态与其一个月前的状态进行比较,例如,如果用户以某种方式在投资组合中,某个证券的数量增加了1万,则该行标记为“购买” ”而且面值为10k。 标记为“持有”的行的目标变量为0(用户不感兴趣)。
如果您考虑一下,您可以理解数据集的运行情况:用户在银行的网站上处于活动状态-他们查看/购买了文件,所有这些操作都记录在数据库中。 例如,id = 15的用户决定将id = 7的纸张推迟以后的购买。 立即在数据库中出现与目标1对应的行(用户开始感兴趣)
| 用户名 | 安全ID | 交易类型 | 交易状态 | 其他领域 | 目标 |
|---|
| 15 | 7 | 采购 | 留给未来 | ... | 1个 |
此外,此记录还添加了状态为“持有”且目标为0的月度记录。例如,用户15由于某种原因(也许是在其他网站上购买了)而增加了93股的数量,而他本人并没有在BNP网站上使用此文件互动(不感兴趣)。
| 用户名 | 安全ID | 交易类型 | 交易状态 | 其他领域 | 目标 |
|---|
| 15 | 93 | 采购 | 控股 | ... | 0 |
但是,显然,对于法国巴黎银行而言,预测这些持股量没有任何意义,因为可以从基础上明确地恢复它们。 这意味着培训表中没有另一种令牌,即数据库中未出现的任何三元组“用户-纸-交易类型”。 也就是说,用户对某项操作不感兴趣,这意味着他没有在BNP系统中与之交互,因此相应的行没有出现在数据库中,这意味着它的目标应该为0。这意味着您需要生成这样的行来进行自我训练(请参阅“编制训练样本”一节。 所有这些都可能导致混乱,因为许多参与者可能认为-您可以预测-有一个数据集,有零和一。 但不是那么简单。
因此,在火车上有一张表格,上面有交易的历史记录(即“用户-纸张-交易类型”的交互作用以及一些其他信息),以及一堆其他具有用户,股票,全球市场状况特征的板块。 在测试中,只有“用户-纸张-交易类型”三元组,对于每个此类三元组,您都需要预测下周是否会出现。 例如,您需要预测用户ID = 8是否对交易类型为“ sale”的操作id = 46感兴趣?
建立资料集的功能
正如我已经说过的,由于在实际的BNP数据库中没有“非持有”零的行,因此组织者以某种方式为测试自己生成了这样的行。 在人工数据生成的地方,经常会有人脸和其他隐式信息,它们可以在不更改模型/功能的情况下显着改善结果。 本节介绍了构建我们设法理解的数据集的一些功能,但不幸的是,这些功能没有任何帮助。

如果您从测试表中查看“用户-纸张-交易类型”三倍,则很容易注意到,具有“购买”和“销售”类型的交易数量完全相同,并且该表严格按此属性排序:首先是所有购买,然后是所有销售。 显然,这不是偶然的,而是出现了一个问题:这怎么可能发生? 例如,以这种方式:组织者从数据库中获取了我们需要对其进行预测的一周中的所有真实记录(此类行的目标为1),以某种方式生成了新行(其目标为0),这与上述描述不一致。 因此,得出了一个表格,其中以随机顺序排列了交易类型(购买/出售):
| 用户名 | 安全ID | 交易类型 | 目标 |
|---|
| 8 | 46 | 待售 | 1个 |
| 2 | 6 | 采购 | 1个 |
| 158 | 73 | 采购 | 1个 |
| 3 | 29日 | 待售 | 0 |
| 67 | 9 | 采购 | 0 |
| 17 | 465 | 待售 | 0 |
现在可以将购买类型设置为所有交易类型为“销售”的行,如果目标是一个,则它将变为零(在大多数情况下,用户只对某种状态的纸张感兴趣,即购买或出售)。 这将产生下表:
| 用户名 | 安全ID | 交易类型 | 目标 |
|---|
| 8 | 46 | 采购 | 0 |
| 2 | 6 | 采购 | 1个 |
| 158 | 73 | 采购 | 1个 |
| 3 | 29日 | 采购 | 0 |
| 67 | 9 | 采购 | 0 |
| 17 | 465 | 采购 | 0 |
最后一步仍然是:执行相同的操作,但替换“购买销售”并安排正确的目标:
| 用户名 | 安全ID | 交易类型 | 目标 |
|---|
| 8 | 46 | 待售 | 1个 |
| 2 | 6 | 待售 | 0 |
| 158 | 73 | 待售 | 0 |
| 3 | 29日 | 待售 | 0 |
| 67 | 9 | 待售 | 0 |
| 17 | 465 | 待售 | 0 |
将表与“购买”连接起来,并将表与“销售”连接起来,我们得到(如果我们是组织者)一张测试中提供给我们的表。 容易理解,以这种方式构造的表的前半部分和后半部分具有相同的用户纸对顺序,实际上在测试表中是如此。
另一个功能是,训练数据集中有很多行,其中用户索引连续重复了几次,尽管事实上该数据集没有按任何符号排序:
| 用户名 | 安全ID | 交易类型 | 目标 |
|---|
| 8 | 46 | 待售 | ? |
| 8 | 152 | 待售 | ? |
| 8 | 73 | 采购 | ? |
队友认为这是正常的,并且最初按用户ID对数据集进行了排序,组织者只是将其弄乱了(例如,如果将随机排列安排在随机排列上,并且这种排列不够用)。 为了确保这一点,他经历了来自不同库的四次混洗,但没有如此频繁的重复出现。 该测试也具有此功能。 有一种想法认为组织者不会产生零,而只是从火车上拿走旧的对。 为了进行检查,我决定执行以下操作:对于测试对中的每对“用户-纸”,比较这对首次碰面时火车的线号,并从中进行绘图。 也就是说,例如,我们看一下测试的第一行,让它有一个用户id = 8,id = paper =15。现在我们从上到下浏览训练表,寻找这对何时出现,例如,第51行。 我们进行了比较:测试的第一条线在第51列,因此我们在图表上绘制了坐标为(1,51)的点。 我们在整个测试中都这样做,并得到下图:
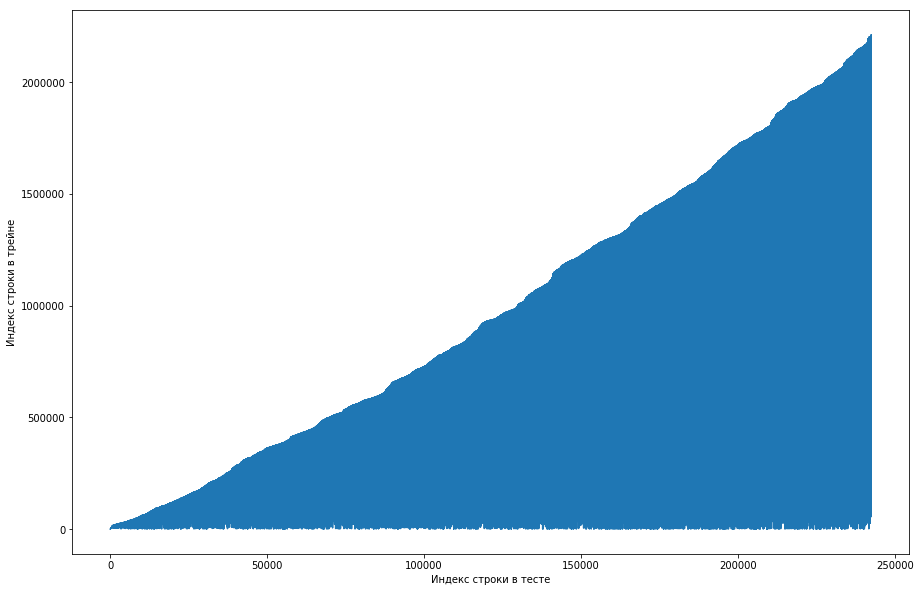
从中可以看出,基本上,如果一对夫妇以前在火车上见过面,那么在测试台上它的位置会更高。 但是同时,图表上出现了一些激增现象(实际上并没有那么多,但是由于屏幕的分辨率,似乎有一个实心的三角形)。 此外,排放数量与测试中预期的单位数量大致重合。 当然,我们尝试将排放标记为单位并将其发送到排行榜,但不幸的是,它没有用。 但是在我看来,仍然可能有某种面孔(),作为车队队长,我建议花更多的时间来了解这种情况如何发生,而且我们还有时间训练模型并生成信号。 免责声明:我们在此上花了很多时间,但是比赛结束前一周,组织者在论坛上写道,过去6个月中只有三倍进入测试数据集,而并非全部。 好吧,如果您执行上述操作,但在过去的6个月中,而不仅仅是数据集,您将获得一条平坦的单调曲线:
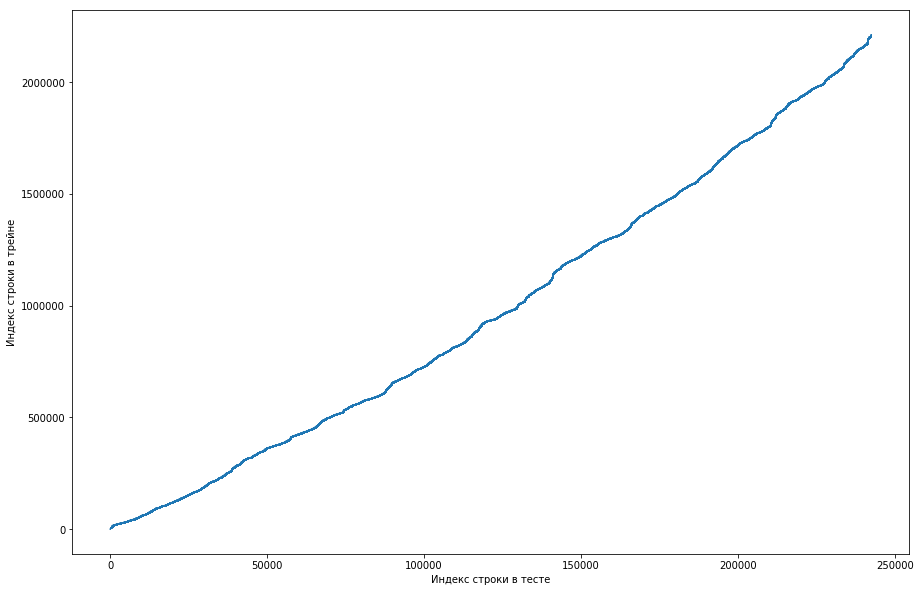
这意味着这里没有面孔,也没有面孔。
培训设置
由于在测试中您需要预测一个星期的三元组,因此我们将训练数据集分为几周(同时,每周平均有2万个三元组“用户-纸张-交易类型”)。 现在,对于任何三个人,我们都可以说她是否在特定的一周见过面。 同时,我们已经有了正三元组(所有这些都是本周火车表中的条目),而负数则需要以某种方式生成。 有关如何执行此操作的选项很多。 例如,您可以对训练数据集中某个星期没有出现的所有三元组进行绝对排序。 显然,样本将高度不平衡,这是不好的。 您可以首先根据用户在数据集中出现的频率生成用户,然后以某种方式向他们添加促销。 但是,采用这种方法,将有很多行无法计算合理的统计数据,这也是不好的。 就像我们做的那样:我们采用了火车上先前遇到的所有三元组,将其复制,用相对的三元组代替买/卖,然后将这两个表串联起来。 显然,可以通过这种方式发生重复(例如,如果用户曾经买卖过股票),但是数量很少,删除后便获得了500k个唯一三元组的表。 仅此而已,现在每周您可以为每个这样的三人组说出她是否见过(多少次?)。
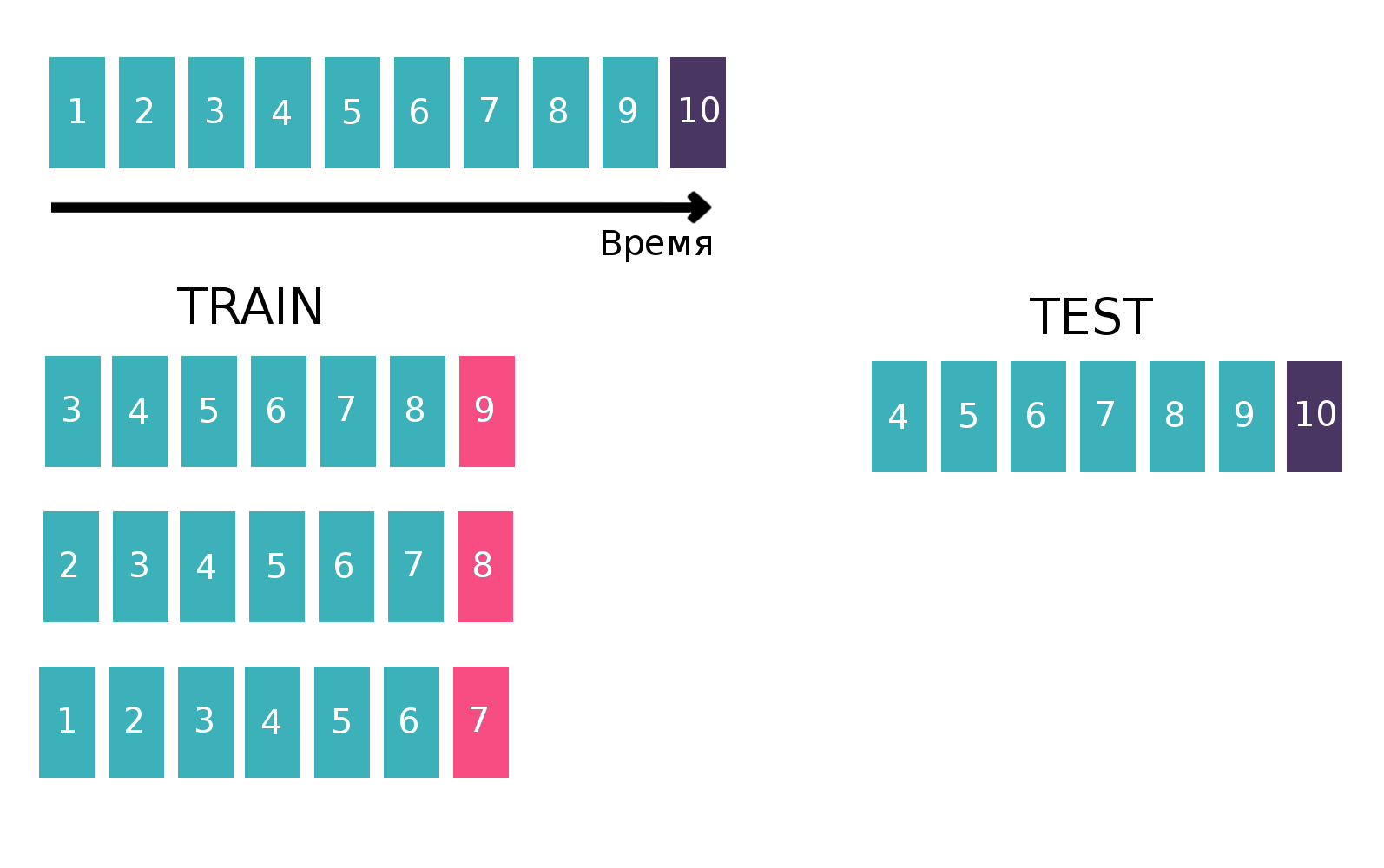
由于从本质上讲,我们正在处理时间序列-用户每周观看一次特定的广告几次,因此我们将建立一个表格,以经典的方式对时间序列进行分类。 即,我们将乘坐火车的最后一个星期,看看本周是否每三个“客户-isin-买卖”相遇。 这将是一个目标。 而且,例如,过去6周内,我们会将各种统计信息都算作一项功能(“标志”部分中的统计信息更多)。 现在,让我们忘记上周的存在,并执行相同的操作,但是倒数第二周并连接表格。 这可以执行几次,从而增加“高度”训练,但同时,我们认为统计数据的间隔自然会减少。 我们重复此操作10次,因为如果做得更多,则将以新年假期和相关问题为目标,这将使模型的最终质量变差。 解释图片:
有关时间序列和时间序列验证的更多信息,请参见
此处 。
迹象
正如我所说,有许多表格以某种方式描述了用户,股票或全球市场状况(主要货币和一些指标)。 但是它们几乎都没有改善质量,主要标志是针对“客户-isin”对和“客户-isin-买卖”三对进行计算的统计数据,例如:
- 在过去的1、2、5、20、100周中,一对夫妇/三对夫妇见面的频率是多少?
- 数据集中一对/三联两次会议之间的时间间隔统计(平均值,标准,最大值,最小值)
- 到第一次/最后一次夫妻/三人相遇的时间距离
- 一对/三对每个TradeStatus值的比例
- 一对夫妇每周发生几次/三次的统计数据(平均值,标准,最大值,最小值)
另外,在比赛的最后一天,我在表格上看到,要出售股票,必须先购买股票。 这些知识可以使您提出更多有用的迹象,但是由于某种原因,对我而言这并不明显。
在代码中,这全部由200行长度的函数表示,它为十列火车中的每一列产生相似的符号(对于目标的部分,例如第7周,我们不应使用第8和第9列的信息)。 考虑到额外的桌子,招募了大约300个标志。 正如我已经说过的,我们生成了500k唯一三元组,并以最近10周为目标,因此“高级”训练表为500k * 10 = 5kk行。
在
第二名的裁决中描述了更多的自白。 这些家伙建立了一个用户/纸张表,如果用户对本文感兴趣,则在每个单元格中都有一个单位,否则为零。 通过计算此表中用户之间的余弦距离,可以使用户彼此之间收敛。 如果将PCA应用于结果相似度表,则会获得一组以某种方式表征用户的功能。
模特还是争取千分之一
值得注意的是,近三周没有人能超过BNP的基线,后者在排行榜上的速度为0.794(ROC AUC),尽管事实上“决定简单地计算这对夫妻较早见面的次数”的决定在排行榜上达到了0.71,参与者在不使用机器学习的情况下获得了0.74的评分。
但是,此外,我们在比赛的最后一天(恰好是本节的最后一天)使用了机器学习,因此,
如果您知道我的意思 ,我们决定停止
,并在不同星期的不同时间里,对经过不同符号训练的不同模型进行大量混合火车。 正如我已经说过的,我们的训练样本包括1.5k行,其中一个目标大约为15万行。 测试的大小为400k,而估计的单元数为20k(实际上,平均而言,有很多独特的三元组)。 也就是说,测试中的单位比例显着高于火车中的比例。 因此,在所有模型中,我们都调整了scale_pos_weight参数,该参数将权重置于类上。 有关此参数的更多信息,请参见去年DataScienceGame
的最佳解决方案
分析 。 图中显示了我们模型的预测的相关矩阵:
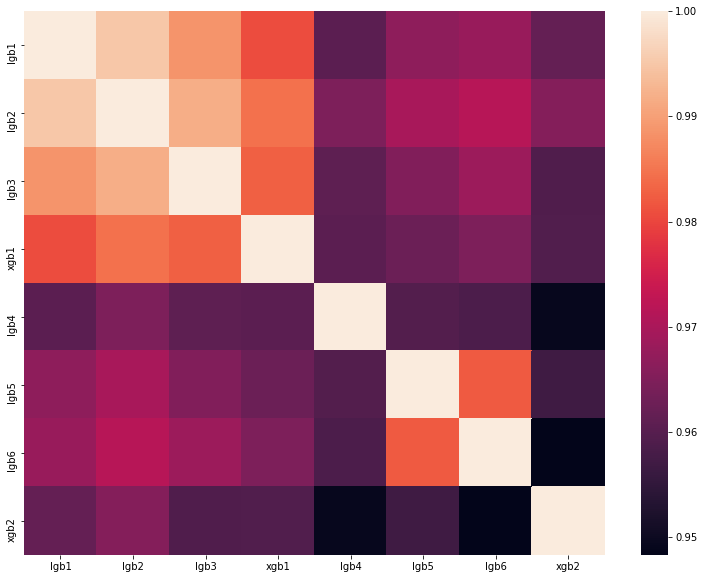
如您所见,我们拥有许多完全不同的模型,这使我们能够在排行榜上获得0.80204的速度。
我们为什么不去法国进行最后阶段
结果,我们显示出了不错的成绩,并在排行榜女贞上排名第三。 但是组织者为入围决赛选手设定了以下规则:
- 最好的团队不超过20个
- 来自该国的最佳团队不超过5个
- 来自教育机构的团队不超过1个
如果莫斯科物理技术学院的另一个团队以0.80272的速度排在第二位,那么一切都会很好。 也就是说,我们仅落后0.00068。 真可惜,但无可奈何。 组织者很可能制定了这样的规则,以使一所大学的人们不会以任何方式互相帮助,但就我们而言,我们对附近的团队一无所知,也没有以任何方式与之联系。
总结
今年9月,在巴黎,来自俄罗斯的5名来自俄罗斯的学生组成的团队,其中一支来自乌克兰,一支来自德国和芬兰的2名团队将竞争第一名。 ru社区共有8个团队,这再次证明了datasaens ru段的主导地位。 而且我将被
调到Sharaga,进行自我训练和工作,以便明年我仍然可以
超越排位赛的阶段。