本文不会介绍休眠的基础知识(如何定义实体或编写条件查询)。 在这里,我将尝试谈论在工作中真正有用的更多有趣的观点。 关于我在某个地方还没有遇到的信息。

我将立即预约。 对于Hibernate 5.2,以下所有内容均适用。 由于我误解了某些事实,因此也可能会出错。 如果找到-写。
将对象模型映射到关系模型时遇到问题
但是,让我们从ORM的基础开始。 ORM-对象关系映射-因此,我们有关系模型和对象模型。 当彼此展示时,我们需要自己解决一些问题。 让我们把它们分开。
为了说明这一点,让我们以以下示例为例:我们有一个“用户”实体,该实体可以是Jedi或攻击机。 绝地武士必须具备实力,并且要专攻攻击机。 下面是一个类图。
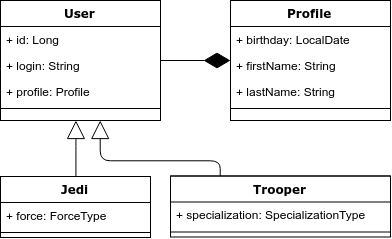
问题1.继承和多态查询。
对象模型中有继承,关系模型中没有继承。 因此,这是第一个问题-如何正确地将继承映射到关系模型。
Hibernate提供了3种显示此类对象模型的选项:
- 所有继承人都在同一张表中:
@Inheritance(策略= InheritanceType.SINGLE_TABLE)

在这种情况下,公共字段和继承人的字段位于一个表中。 使用这种策略,我们在选择实体时避免了联接。 在这些缺点中,值得注意的是,首先,我们不能为关系模型中的“力”列设置“非空”限制,其次,我们失去了第三种范式。 (出现非关键属性的传递依赖项:力和光盘)。
顺便说一下,出于这个原因,有两种方法可以指定非null字段约束-NotNull负责验证; @Column(nullable = true)-负责数据库中的非null约束。
我认为,这是将对象模型映射到关系模型的最佳方法。
- 特定于实体的字段位于单独的表中。
@Inheritance(策略= InheritanceType.JOINED)
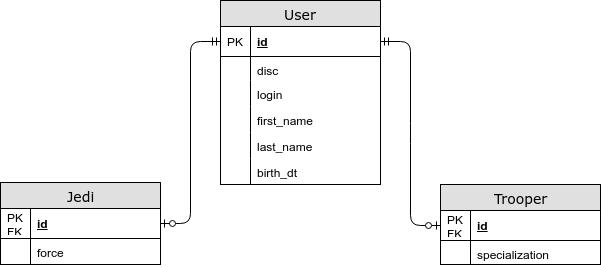
在这种情况下,公共字段存储在公共表中,而特定于子实体的存储在单独的表中。 使用这种策略,当选择一个实体时我们得到一个JOIN,但是现在我们保存了第三种形式,我们还可以在数据库中指定一个NOT NULL约束。 - 每个实体都有其自己的表。
@ InheritanceType.TABLE_PER_CLASS
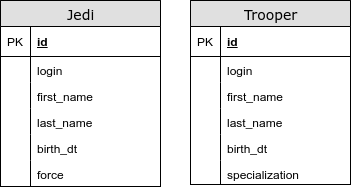
在这种情况下,我们没有公用表。 使用这种策略,我们将UNION用于多态查询。 我们在主键生成器和其他完整性约束方面遇到问题。 强烈建议不要使用此类继承映射。
以防万一,我会提到注释-@MappedSuperclass。 当您要“隐藏”对象模型的多个实体的公共字段时,可以使用它。 此外,带注释的类本身不被视为单独的实体。
问题2. OOP中的组成比
回到我们的示例,我们注意到在对象模型中,我们将用户个人资料带入了一个单独的实体-个人资料。 但是在关系模型中,我们没有为其选择单独的表。
OneToOne态度通常是不好的做法,因为 在选择中,我们有一个不合理的JOIN(即使在大多数情况下,即使指定fetchType = LAZY,我们也会有JOIN-我们将在以后讨论此问题)。
有@Embedable和@Embeded批注以在公共表中显示合成。 第一个放在字段上方,第二个放在班级上方。 它们是可互换的。
实体经理
EntityManager(EM)的每个实例都定义了一个与数据库交互的会话。 在EM实例中,存在一级缓存。 在这里,我将重点强调以下几点:
- 捕获数据库连接
这只是一个有趣的观点。 Hibernate在接收EM时不会捕获Connection,而是在首次访问数据库或打开事务时捕获(尽管可以解决此问题)。 这样做是为了减少繁忙连接的时间。 在接收EM-a期间,将检查是否存在JTA事务。 - 永久实体始终具有ID
- 描述数据库中一行的实体通过引用等效
如上所述,EM具有一级缓存,其中的对象通过引用进行比较。 因此,出现了一个问题-应该使用哪些字段来覆盖equals和hashcode? 考虑以下选项:
- 冲水如何工作
刷新-在数据库中执行累积的insert-s,update-s和delete-s。 默认情况下,在以下情况下执行刷新:
- 在执行查询之前(em.get除外),必须遵守ACID原则。 例如:我们更改了攻击机的出生日期,然后我们想获得成人攻击机的数量。
如果我们谈论的是CriteriaQuery或JPQL,则如果查询影响实体在第一级缓存中的表,则将执行刷新。 - 提交交易时;
- 有时,当持久化一个新实体时-我们只能通过插入才能获得其ID。
现在进行一点测试。 在这种情况下将执行多少次UPDATE操作?
val spaceCraft = em.find(SpaceCraft.class, 1L); spaceCraft.setCoords(...); spaceCraft.setCompanion( findNearestSpaceCraft(spacecraft) );
刷新操作下隐藏了一个有趣的休眠功能-它试图减少锁定数据库中的行所花费的时间。
另请注意,冲洗操作有不同的策略。 例如,您可以禁止“合并”对数据库的更改-它称为MANUAL(它也禁用了脏检查机制)。
- 脏检查
脏检查是在冲洗操作期间执行的机制。 其目的是查找已更改并更新的实体。 为了实现这种机制,休眠模式必须存储对象的原始副本(将实际对象与之进行比较)。 更确切地说,休眠存储对象字段的副本,而不是对象本身。
值得注意的是,如果实体的图很大,那么脏检查的操作可能会很昂贵。 不要忘记休眠状态存储了2个实体副本(大致而言)。
为了“降低成本”,请使用以下功能:
- em.detach / em.clear-从EntityManager分离实体
- FlushMode = MANUAL-在读取操作中很有用
- 不可变 -还避免脏检查操作
- 交易次数
如您所知,休眠允许您仅在事务内更新实体。 读操作提供了更多的自由-我们可以执行它们而无需显式打开事务。 但这恰恰是一个问题:为读操作显式打开事务是否值得?
我会列举一些事实:
- 任何语句都在事务内部的数据库中执行。 即使我们显然没有打开它。 (自动提交模式)。
- 通常,我们不仅限于对数据库的一个查询。 例如:要获取前10条记录,您可能希望返回记录总数。 这几乎总是2个请求。
- 如果我们谈论的是Spring数据,那么默认情况下 ,存储库方法是事务性的 ,而read方法是只读的。
- @Transactional spring注释(readOnly = true)也影响FlushMode,更确切地说,Spring将其置于MANUAL状态,因此休眠状态将不会执行脏检查。
- 对一个或两个数据库查询进行综合测试将显示自动提交的速度更快。 但是在战斗模式下,情况可能并非如此。 ( 关于这个主题的优秀文章 ,+查看评论)
简而言之:优良作法是在事务中与数据库进行任何通信。
发电机
需要使用生成器来描述实体的主键将如何接收值。 让我们快速浏览一下这些选项:
- GenerationType.AUTO-生成器选择基于方言。 这不是最佳选择,因为“显式优于隐式”规则仅在此处适用。
- GenerationType.IDENTITY是配置生成器的最简单方法。 它依赖于表中的自动增量列。 因此,要获取具有持久性的ID,我们需要进行插入。 这就是为什么它消除了延迟保留并因此进行批处理的可能性。
- 当我们从序列中获取ID时, GenerationType.SEQUENCE是最方便的情况。
- GenerationType.TABLE-在这种情况下,hibernate通过附加表模拟序列。 不是最佳选择,因为 在这种解决方案中,休眠状态必须使用单独的事务并每行锁定。
让我们更多地讨论序列。 为了提高操作速度,休眠使用了不同的优化算法。 所有这些都旨在减少与数据库的对话次数(往返次数)。 让我们更详细地看一下它们:
- 无 -无优化。 对于每个id,我们拉序列。
- pooled和pooled-lo-在这种情况下,我们的序列应增加一定的间隔-数据库中的N(SequenceGenerator.allocationSize)。 在应用程序中,我们有一个特定的池,无需访问数据库即可从中将值分配给新实体。
- hilo-要生成ID,hilo算法使用2个数字:hi(存储在数据库中-从序列调用获得的值)和lo(仅存储在应用程序中-SequenceGenerator.allocationSize)。 基于这些数字,生成id的时间间隔计算如下:[(hi-1)* lo + 1,hi * lo + 1)。 出于明显的原因,该算法被认为已过时,不建议使用它。
现在让我们看看如何选择优化器。 Hibernate有几个序列发生器。 我们将对其中2个感兴趣:
- SequenceHiLoGenerator是使用hilo优化器的旧生成器。 如果我们具有hibernate.id.new_generator_mappings == false属性,则默认为选中状态。
- SequenceStyleGenerator-默认使用(如果hibernate.id.new_generator_mappings == true属性)。 该生成器支持多个优化器,但默认存储池。
您还可以配置生成器注释@GenericGenerator。
死锁
让我们看一个可能导致死锁的伪代码情况的示例:
Thread #1: update entity(id = 3) update entity(id = 2) update entity(id = 1) Thread #2: update entity(id = 1) update entity(id = 2) update entity(id = 3)
为了防止此类问题,hibernate具有避免这种死锁的机制-hibernate.order_updates参数。 在这种情况下,所有更新将按ID排序并执行。 我还要再次提及,休眠模式试图“延迟”连接的捕获以及执行insert-s和update-s。
套装,包袋,清单
Hibernate有3种主要方法来呈现OneToMany通信集合。
- 集合-没有重复的无序实体集合;
- 袋-无序的一组实体;
- 列表是一组有序的实体。
在Java核心中,没有用于Bag的类来描述这种结构。 因此,除非您指定将对我们的集合进行排序的列(OrderColumn批注。不要与SortBy混淆),否则所有List和Collection都是bag。 我强烈建议您不要使用OrderColumn注释,因为(我认为)这些功能的实现较差-不是最佳的sql查询,或者工作表中可能存在NULL。
问题出现了,但是使用手提袋或套装更好的是什么呢? 首先,在使用袋子时,可能会出现以下问题:
- 如果您的休眠版本低于5.0.8,则存在一个相当严重的错误-HHH-5855-插入子实体时可能会重复(对于cascadType = MERGE和PERSIST);
- 如果对多对多关系使用bag,则hibernate在从集合中删除实体时会生成极其不合适的查询-它首先从联接表中删除所有行,然后执行插入;
- Hibernate无法同时为同一实体获取多个包。
如果要向@OneToMany连接中添加另一个实体,使用Bag会更有利可图,因为 它不需要为此操作加载所有相关实体。 让我们来看一个例子:
强度参考
引用是对对象的引用,我们决定推迟加载。 在ManyToOne与fetchType = LAZY的关系的情况下,我们得到了这样的参考。 对象的初始化发生在访问实体的字段时,但id除外(因为我们知道该字段的值)。
值得注意的是,在延迟加载的情况下,引用始终引用数据库中的现有行。 因此,大多数延迟加载用例在OneToOne关系中不起作用-休眠状态需要为JOIN来检查连接的存在,并且已经有一个JOIN,然后休眠将其加载到对象模型中。 如果我们在OneToOne中指示nullable = true,则LazyLoad应该可以工作。
我们可以使用em.getReference方法创建自己的引用。 是的,在这种情况下,不能保证引用引用数据库中的现有行。
让我们举一个使用这样的链接的例子:
以防万一,我提醒您,如果关闭EM或分离链接,我们将获得LazyInitializationException。
日期和时间
尽管Java 8具有出色的用于日期和时间的API,但JDBC API仍然允许您仅使用旧的日期API。 因此,我们将分析一些有趣的观点。
首先,您需要清楚地了解LocalDateTime与Instant和ZonedDateTime之间的区别。 (我不会伸展,但是我会在这个主题上发表出色的文章:
第一篇和
第二篇 )
如果简短LocalDateTime和LocalDate代表数字的常规元组。 它们不受特定时间限制。 即 飞机着陆时间不能存储在LocalDateTime中。 并且通过LocalDate出生的日期很正常。 即时表示一个时间点,相对于该时间点,我们可以获取地球上任何一点的本地时间。
更有趣和重要的一点是日期如何存储在数据库中。 如果贴有TIMESTAMP WITH TIMEZONE类型,则应该没有问题,但是如果TIMESTAMP(WITHOUT TIMEZONE)站立,则日期的写入/读取可能不正确。 (不包括LocalDate和LocalDateTime)
让我们看看为什么:
当我们保存日期时,将使用具有以下签名的方法:
setTimestamp(int i, Timestamp t, java.util.Calendar cal)
如您所见,这里使用了旧的API。 需要可选的Calendar参数将时间戳转换为字符串表示形式。 即它本身存储时区。 如果未传输日历,则默认情况下将日历与JVM时区一起使用。
有3种方法可以解决此问题:
- 设置所需的时区JVM
- 使用hibernate参数-hibernate.jdbc.time_zone(在5.2中添加)-将仅修复ZonedDateTime和OffsetDateTime
- 使用类型TIMESTAMP WITH TIMEZONE
一个有趣的问题,为什么LocalDate和LocalDateTime不属于此类问题?
答案要回答这个问题,您需要了解java.util.Date类的结构(java.sql.Date和java.sql.Timestamp,在此情况下其继承人和它们的区别不会打扰我们)。 Date以毫秒为单位存储日期(从1970年开始,以毫秒为单位),大致以UTC表示,但是toString方法根据系统timeZone转换日期。
因此,当我们从数据库中获取没有时区的日期时,该日期将映射到Timestamp对象,以便toString方法显示其所需的值。 同时,自1970年以来的毫秒数可能会有所不同(取决于时区)。 这就是为什么始终仅正确显示本地时间的原因。
我还给出了一个代码示例,负责将Timesamp转换为LocalDateTime和Instant:
批处理
默认情况下,查询一次发送到数据库一次。 启用批处理后,休眠将能够在一个查询中向数据库发送多个语句。 (即批处理减少了往返数据库的次数)
为此,您必须:
- 启用批处理并设置最大语句数:
hibernate.jdbc.batch_size(建议5到30) - 启用对插入和更新的排序:
hibernate.order_inserts
hibernate.order_updates
- 如果使用版本控制,则还需要启用
hibernate.jdbc.batch_versioned_data-注意此处,您需要jdbc驱动程序才能提供更新期间受影响的行数。
我还要提醒您有关em.clear()操作的有效性-它可以将实体与em解除绑定,从而释放内存并减少脏检查操作的时间。
如果我们使用postgres,那么我们也可以说休眠以使用
多原始插入 。
N + 1个问题
这是一个无处不在的话题,因此请快速浏览。
N + 1问题是这样的情况:至少有N + 1个请求发生,而不是单个请求选择N本书。
解决N + 1问题的最简单方法是获取相关表。 在这种情况下,我们可能会遇到其他几个问题:
- 分页。 在OneToMany关系的情况下,休眠将无法指定偏移量和限制。 因此,分页将在内存中发生。
- 笛卡尔积的问题是当数据库返回N * M * K行以选择具有M章和K作者的N本书时的情况。
还有其他方法可以解决N + 1问题。
- FetchMode-允许您更改子实体的加载算法。 就我们而言,我们对以下方面感兴趣:
- FetchType.SUBSELECT-在单独的请求中加载子记录。 缺点是主请求的所有复杂性都在子选择中重复进行。
- BATCH(FetchType.SELECT + BatchSize批注) -也将记录作为单独的请求加载,但是与子查询一起,它会产生类似WHERE parent_id IN(?,?,?,...,N)的条件
值得注意的是,在Criteria API中使用提取时,FetchType被忽略-始终使用JOIN - JPA EntityGraph和Hibernate FetchProfile-允许您将实体加载规则制作成单独的抽象-我认为这两种实现方式都很不方便。
测试中
理想情况下,开发环境应提供有关休眠操作以及与数据库交互的尽可能多的有用信息。 即:
- 记录中
- org.hibernate.SQL:调试
- org.hibernate.type.descriptor.sql:跟踪
- 统计资料
- hibernate.generate_statistics
在有用的实用程序中,可以区分以下内容:
- DBUnit-允许您以XML格式描述数据库的状态。 有时很方便。 但是最好再考虑一下是否需要它。
- 数据源代理
- p6spy是最古老的解决方案之一。 提供高级查询日志记录,运行时等。
- com.vladmihalcea:db-util:0.0.1是发现N + 1个问题的便捷实用程序。 它还允许您记录查询。 该组合包括一个有趣的Retry批注,在OptimisticLockException的情况下重试该事务。
- 嗅探 -允许您通过注释对请求的数量进行断言。 在某些方面,比弗拉德的决定更为优雅。
但是我再次重申,这仅用于开发,不应包含在生产中。
文学作品