大家好! 我们提醒您,不久前我们出版了一
本有关Spark的
书 ,而现在一
本有关Kafka的
书正在接受最新的校对。
我们希望这些书能够取得成功,足以继续该主题-例如,有关Spark Streaming的文献的翻译和出版。 我们今天想为您提供有关将该技术与Kafka集成的翻译。
1.理由Apache Kafka + Spark Streaming是创建实时应用程序的最佳组合之一。 在本文中,我们将详细讨论这种集成的细节。 此外,我们将以Spark Streaming-Kafka为例。 然后,我们讨论“接收方方法”以及Kafka和Spark Streaming直接集成的选项。 因此,让我们开始集成Kafka和Spark Streaming。
 2. Kafka和Spark Streaming的集成
2. Kafka和Spark Streaming的集成在集成Apache Kafka和Spark Streaming时,有两种可能的方法来配置Spark Streaming以从Kafka接收数据-即 整合Kafka和Spark Streaming的两种方法。 首先,您可以使用收件人和高级Kafka API。 第二种(较新的)方法是没有收件人的工作。 两种方法都有不同的编程模型,例如在性能和语义保证方面有所不同。
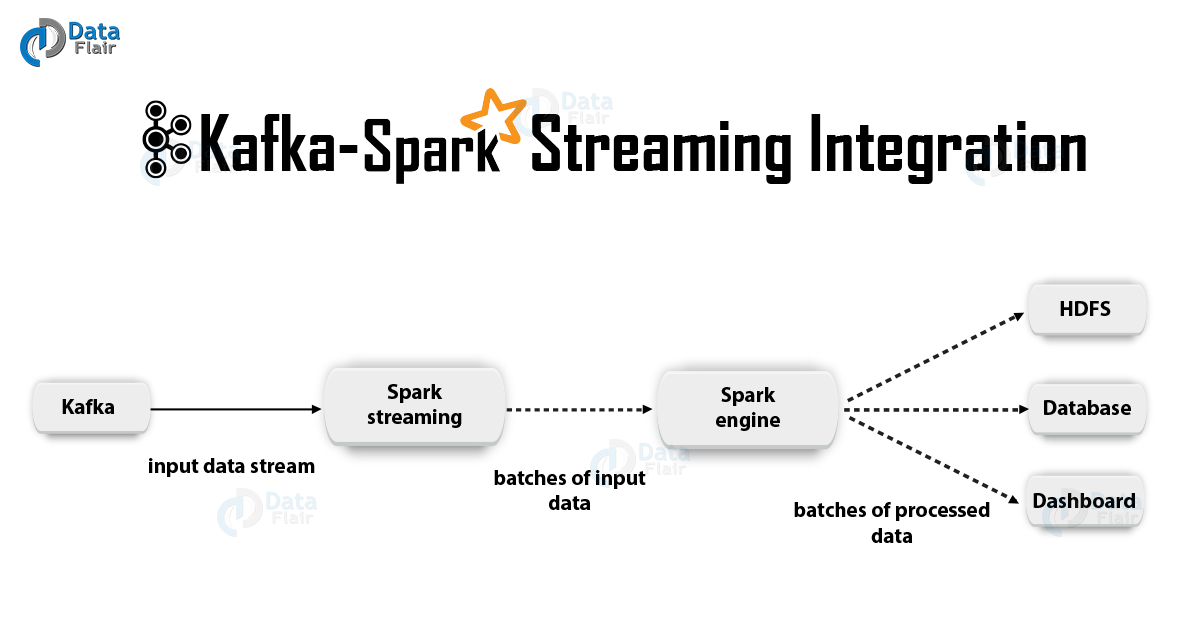
让我们更详细地考虑这些方法。
一个 基于收件人的方法在这种情况下,数据的接收是由收件人提供的。 因此,使用Kafka提供的高级消费API,我们实现了收件人。 此外,接收到的数据存储在Spark Artists中。 然后,在Kafka-Spark Streaming中启动作业,在其中处理数据。
但是,使用这种方法时,在发生故障(使用默认配置)的情况下仍然存在数据丢失的风险。 因此,有必要在Kafka-Spark Streaming中另外包含一个预写日志,以消除数据丢失。 因此,从Kafka接收的所有数据都同步存储在分布式文件系统中的预写日志中。 因此,即使在系统出现故障后,也可以还原所有数据。
接下来,我们将研究如何在具有Kafka-Spark Streaming的应用程序中对收件人使用这种方法。
我 装订现在,我们将流应用程序与以下针对Scala / Java应用程序的工件相连,我们将使用SBT / Maven的项目定义。
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
但是,在部署我们的应用程序时,我们将不得不添加上述库及其依赖项,Python应用程序将需要此库。
ii。 程式设计接下来,通过将
KafkaUtils导入到流应用程序代码中来创建
DStream输入流:
import org.apache.spark.streaming.kafka._ val kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
此外,使用createStream选项,可以指定键类和值类,以及用于解码的相应类。
iii。 部署方式与任何Spark应用程序一样,spark-submit命令用于启动。 但是,细节在Scala / Java应用程序和Python应用程序中略有不同。
此外,使用
–packages您可以将
spark-streaming-Kafka-0-8_2.11及其依赖项直接添加到
spark-submit ,这对于无法使用SBT / Maven管理项目的Python应用程序很有用。
./bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 ...
您还可以从Maven存储库下载Maven工件
spark-streaming-Kafka-0-8-assembly的JAR存档。 然后将其添加到带有
jars spark-submit 。
b。 直接方式(无收件人)在使用接收者的方法之后,开发了一种较新的方法-“直接”方法。 它提供可靠的端到端保修。 在这种情况下,我们会定期向Kafka询问每个主题/部分的偏移量偏移量,而不安排通过接收者传送数据。 另外,确定读取的片段的大小,这对于正确处理每个分组是必需的。 最后,一个简单的消耗性API用于从具有指定偏移量的Kafka数据读取范围,尤其是在启动数据处理作业时。 整个过程就像从文件系统读取文件。
注意:此功能出现在Scala和Java API的Spark 1.3中,以及Python API的Spark 1.4中。
现在让我们讨论如何在我们的流应用程序中应用这种方法。
消费者API在以下链接中有更详细的描述:
Apache Kafka使用者| 卡夫卡消费者的例子我 装订
是的,仅Scala / Java应用程序支持此方法。 使用以下工件,构建SBT / Maven项目。
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
ii。 程式设计接下来,导入KafkaUtils并在流应用程序代码中创建一个输入
DStream :
import org.apache.spark.streaming.kafka._ val directKafkaStream = KafkaUtils.createDirectStream[ [key class], [value class], [key decoder class], [value decoder class] ]( streamingContext, [map of Kafka parameters], [set of topics to consume])
在Kafka参数中,您将需要指定
metadata.broker.list或
bootstrap.servers 。 因此,默认情况下,我们将使用从Kafka的每个部分中的最后一个偏移量开始的数据。 但是,如果要从最小的片段开始读取,则需要在Kafka参数中设置配置选项
auto.offset.reset 。
此外,使用选项
KafkaUtils.createDirectStream ,您可以从任意偏移量开始读取。 然后,我们将执行以下操作,这将使我们能够访问每个包中消耗的Kafka片段。
如果我们要使用特殊工具在Zookeeper的基础上组织对Kafka的监视,可以在其帮助下自行更新Zookeeper。
iii。 部署方式在这种情况下,部署过程与接收方的变体中的部署过程类似。
3.直接方法的好处由于以下原因,将Spark Streaming与Kafka集成的第二种方法优于第一种:
一个 简化并发在这种情况下,您无需创建许多Kafka输入流并将其组合。 但是,Kafka-Spark Streaming将创建与将要使用的Kafka分段一样多的RDD分段。 所有这些Kafka数据都将并行读取。 因此,可以说我们将在Kafka和RDD段之间建立一一对应的关系,这样的模型更易于理解且易于配置。
b。 实效为了完全消除第一种方法期间的数据丢失,需要将信息存储在主要记录的日志中,然后再进行复制。 实际上,这是低效的,因为数据被复制了两次:第一次是由Kafka本身复制,第二次是通过预写日志复制。 在第二种方法中,由于没有接收者,因此消除了此问题,因此不需要引导写日记帐。 如果我们在Kafka中有足够长的数据存储空间,则可以直接从Kafka恢复消息。
s 一次精确语义基本上,我们在第一种方法中使用了高级Kafka API将消耗的读取片段存储在Zookeeper中。 但是,这是使用来自Kafka的数据的习惯。 尽管可以可靠地消除数据丢失,但是在某些故障中,个别记录可能会被消耗两次。 重点是Kafka-Spark Streaming中可靠的数据传输机制与Zookeeper中发生的片段读取之间的不一致。 因此,在第二种方法中,我们使用简单的Kafka API,它不需要求助于Zookeeper。 在这里,在Kafka-Spark Streaming中跟踪读取的片段,为此,使用了控制点。 在这种情况下,Spark Streaming和Zookeeper / Kafka之间的不一致将被消除。
因此,即使发生故障,Spark Streaming也仅严格接收一次每个记录。 在这里,我们需要确保将数据存储在外部存储中的输出操作是幂等的或原子事务,在其中存储结果和偏移量。 这就是在我们的结果推导中实现一次精确语义的方式。
虽然有一个缺点:Zookeeper中的偏移量不会更新。 因此,基于Zookeeper的Kafka监视工具不允许您跟踪进度。
但是,如果处理是以这种方式安排的,我们仍然可以引用偏移量-我们转向每个程序包并自行更新Zookeeper。
这就是我们想要讨论的有关集成Apache Kafka和Spark Streaming的全部内容。 希望您喜欢。