这是J. Subbotnik关于数据库的第二次演讲-我们几周前发表的
第一篇演讲。
通用DBMS小组负责人Dmitry Sarafannikov谈到了Yandex中数据仓库的发展:我们如何决定创建一个与S3兼容的接口,为什么选择PostgreSQL,我们踩了什么样的耙子以及如何处理它们。
大家好! 我叫Dima,在Yandex中是数据库。
我将告诉您我们如何进行S3,如何精确地进行S3以及以前的存储方式。 第一个是Elliptics,它以开源形式发布,可在GitHub上获得。 许多人可能遇到过它。

这实际上是具有512位密钥的分布式哈希表,是SHA-512的结果。 它形成一个钥匙圈,在机器之间随机分配。 如果要在此处添加计算机,则会重新分配密钥,从而发生重新平衡。 该存储库有其自身的问题,特别是与重新平衡有关。 如果您有足够数量的密钥,那么随着数量的不断增长,您需要不断地将汽车丢到那里,而在大量密钥上,重新平衡可能根本不会收敛。 这是一个很大的问题。
但与此同时,当您一次上传大量的内容,然后对其进行只读加载时,此存储空间可用于或多或少的静态数据。 对于此类决策,它非常适合。
我们走得更远。 重新平衡的问题非常严重,因此出现了下一个存储空间。

它的本质是什么? 这不是键值存储,这是值存储。 当您将某个对象或文件上传到那里时,它会用一个键回答您,然后您可以通过该键来拾取该文件。 它有什么作用? 从理论上讲,如果存储中有可用空间,则百分之一百的写访问权限。 如果您有一台打字机,那么您只需写信给没有空余空间的其他人,就可以得到其他键并从容地获取数据。
这种存储非常容易扩展,可以用铁丢它,它将起作用。 它非常简单,可靠。 它的唯一缺点是:客户端不管理密钥,并且所有客户端必须将密钥存储在某个位置,并存储其密钥的映射。 这给大家带来不便。 实际上,这对于所有客户来说都是非常相似的任务,并且每个人都在自己的配置数据库中以自己的方式解决它,等等。这很不方便。 但同时,我也不想失去这种存储的可靠性和简单性,实际上它可以以网络速度运行。
然后我们开始研究S3。 这是键值存储,客户端管理密钥,整个存储分为所谓的存储桶。 在每个存储桶中,键空间从负无穷大到正无穷大。 关键是某种文本字符串。 我们就此选择了解决方案。 为什么选择S3?
一切都很简单。 至此,已经编写了许多用于各种编程语言的现成客户端,已经编写了许多用于在S3中存储内容的现成工具,例如数据库备份。 安德鲁
谈到了其中一个例子。 已经有一个经过深思熟虑的API,并且已经运行了很多年,您不需要在那里发明任何东西。 该API具有许多便利的功能,例如清单,分段上传等。 因此,我们决定继续坚持下去。
如何从我们的存储中制作S3? 想到什么? 由于客户自己存储键的映射,因此我们只需将数据库放在它们旁边,然后将这些键的映射存储在其中。 阅读时,我们只会在数据库中找到密钥和存储,然后将其所需的内容提供给客户。 如果您示意性地画出草图,填充是如何发生的?

有一个特定的实体,在这里称为代理,即所谓的后端。 他接受文件,将其上传到存储,从那里获取密钥并将其保存到数据库,一切都非常简单。
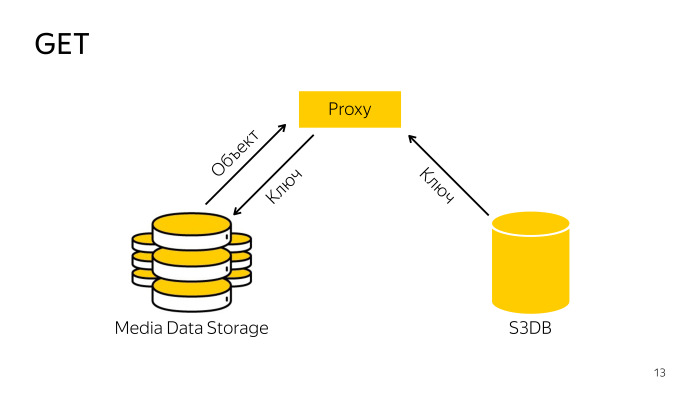
收据怎么样? 代理在数据库中找到必要的密钥,随密钥一起存储,从那里下载对象,然后将其提供给客户端。 一切也很简单。
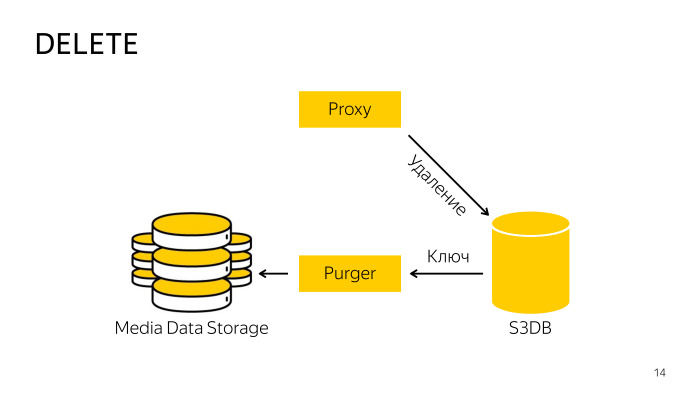
如何清除? 直接从存储中删除时,代理不起作用,因为很难协调数据库和存储,因此它只转到数据库,告诉它该对象已删除,然后将该对象移至删除队列,然后在后台由经过专门培训的专业人员机器人将获取这些密钥,并将其从存储和数据库中删除。 这里的一切也很简单。
我们选择PostgreSQL作为该配置数据库的数据库。
您已经知道我们非常爱他。 随着Yandex.Mail的转移,我们在PostgreSQL上获得了足够的专业知识,并且当不同的邮件服务转移时,我们开发了几种所谓的分片模式。 其中一个在稍作修改的情况下在S3上表现不错,但是在那儿运行得很好。
分片有哪些选择? 这是一个很大的存储库,在整个Yandex范围内,您必须立即想到将有许多对象,必须立即考虑如何将其全部分片。 您可以代表对象通过散列进行分片,这是最可靠的方法,但是在这里不起作用,因为S3具有例如应按排序顺序显示键列表的列表,当您缓存时,所有排序都将消失,您需要删除所有对象,以便输出符合API规范。
下一个选项,您可以代表存储区或ID通过哈希进行分片。 一个存储桶可以位于一个数据库碎片中。
另一种选择是跨关键范围分片。 在存储桶中,从负无穷大到正无穷大都有空间,我们可以将其划分为任意多个范围,我们将此范围称为一个块,它只能存在一个碎片中。

我们选择了第三个选项,即按碎片进行分片,因为从理论上讲,一个桶中可以有无限多的对象,而且愚蠢地它不能放入一块铁中。 会有很大的问题,因此我们将根据需要削减和整理碎片。 仅此而已。

怎么了 整个数据库由三个部分组成。 S3代理-一组主机,也有一个数据库。 PL /代理位于平衡器之下,来自后端的请求飞到那里。 进一步的S3Meta,例如一组低音,存储有关存储桶和存储块的信息。 还有S3DB,存储对象的碎片,删除队列。 如果示意性地描绘,则看起来像这样。
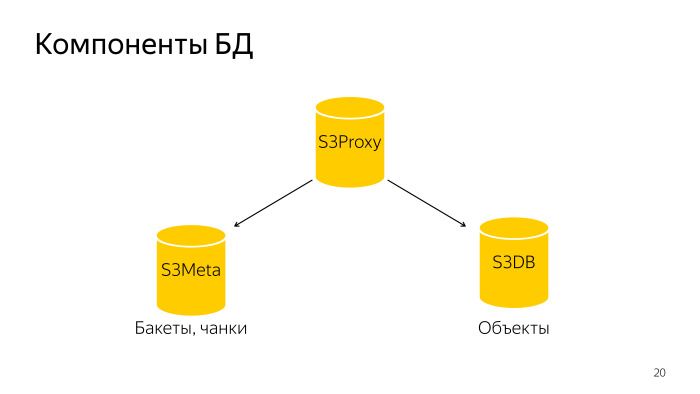
一个请求到达S3Proxy,它到达S3Meta和S3DB并向顶部发出信息。

让我们更详细地考虑。 S3Proxy,其中的函数是用过程语言PLProxy创建的,它是一种语言,允许您执行远程存储的过程或请求。 从本质上讲,这就是ObjectInfo函数的代码,类似于Get请求。
LProxy群集具有“群集”运算符,在本例中为db_ro。 这是什么意思?

如果是典型的数据库分片配置,则有一个主数据库和两个副本。 Master进入db_rw群集,所有三台主机进入db-ro,在这里您可以发送只读请求,并将写请求发送到db_rw。 db_rw集群包括所有分片的所有主节点。
下一条RUN ON语句采用值all,这意味着要对所有分片执行数组或某种分片。 在这种情况下,它将接收get_object_shard函数的结果作为输入;这是给定对象所在的分片的编号。
和目标-在远程分片上调用哪个函数。 他将调用此函数并替换飞入该函数的参数。

get_object_shard函数也是用PLProxy(已经是meta_ro群集)编写的,请求将转到S3Meta分片,该分片将返回此函数get_bucket_meta_shard。
S3Meta也可以被分片,我们也将其放置好,虽然这无关紧要,但是有机会。 它将在S3Meta上调用get_object_shard函数。

get_bucket_meta_shard只是代表存储桶的文本哈希,我们仅通过代表存储桶的哈希对S3Meta进行了混洗。

考虑一下S3Meta发生了什么。 最重要的信息是带有块的表。 我删除了一些不必要的信息,剩下的最重要的是bucket_id,开始键,结束键和该块所在的碎片。

在这样的表上查询将是什么样的,它将返回给我们测试对象所在的块? 像这样 文本形式的负无穷大,我们将其表示为空值,其中有些细微的点需要检查start_key和end_key是否为Null。

该请求看起来不太好,该计划看起来更糟。 作为此类请求计划的选项之一,BitmapOr。 6,000个骨头值得这样的计划。

有什么不同吗? PostgreSQL中有一个很棒的事情,就是gist索引,它可以索引范围类型,范围本质上就是我们需要的。 我们创建了这种类型,s3.to_keyrange函数实际上返回了我们的范围。 我们可以使用contains运算符进行检查,找到密钥所在的块。 为此,在此处构建了排除约束,以确保这些块不相交。 我们需要允许(最好在数据库级别)一些约束,以确保块不能彼此相交,以便响应请求仅返回一行。 否则,这将不是我们想要的。 这样的请求计划就是通常的index_scan。 此条件完全符合索引条件,并且这样的计划只有700根骨头,少了10倍。

什么是排除约束?

让我们创建一个包含两列的测试表,并向其中添加两个约束,一个约束是每个人都知道的,一个排除约束,它具有参数相等的运算符。 让我们将两个运算符设置成相等,这样就建立了一个盘子。

然后,我们尝试插入两条相同的行,我们得到第一个约束上违反键唯一性的错误。 如果我们删除它,那么我们已经违反了排除约束。 这是唯一约束的常见情况。

实际上,唯一约束与运算符相等的排除约束相同,但是在排除约束的情况下,您可以构建一些更一般的情况。

我们有这样的索引。 如果仔细观察,您会发现它们都是要点索引,并且通常它们是相同的。 您可能会问,为什么要完全重复这项业务。 我会告诉你的。

索引是如此重要,尤其是摘要索引,使得表过着自己的生活,发生更新,被分割等等,索引在那里变坏,不再是最优的。 并且有这样一种做法,特别是pg repack扩展,有时会不定期地重建索引。
如何在唯一约束下重建索引? 当前创建create index,在不锁定的情况下在其旁边平静地创建相同的索引,然后约束user_index中的alter表这样。 一切,一切都很好,在这里行之有效。
在排除约束的情况下,您只能通过重新索引锁定来重建它,更确切地说,您的索引将被排他地阻塞,实际上您将剩下所有查询。 这是不可接受的,要点索引可以建立足够长的时间。 因此,我们紧靠第二个索引,该索引较小,体积较小,占用的空间较小,滑翔机可以使用它,并且我们可以竞争性地重建该索引而不会阻塞。
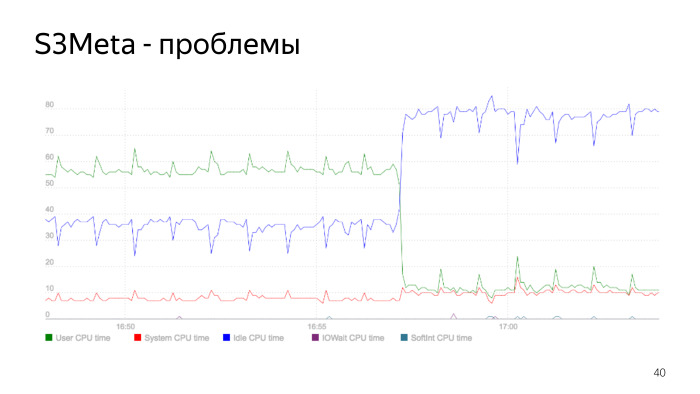
这是处理器消耗的图表。 绿线是user_space中的处理器消耗,它从50%跃升到60%。 此时,消耗量急剧下降,这是重建索引的时刻。 我们重建了索引,删除了旧的索引,我们的处理器消耗急剧下降。 这是一个要点索引问题,这是一个很好的例子。
完成所有这些操作后,我们从9.5版S3DB开始,根据计划,我们计划在每个分片中堆叠100亿个对象。 如您所知,当一个表有很多行时,就会出现超过10亿甚至更早的问题,而所有问题都会变得更加糟糕。 有一种离别的习惯。 当时有两种选择,一种是通过继承的标准,但由于线性分区选择速度快,因此效果不佳。 从对象的数量来看,我们需要很多分区。 然后,来自Postgres Pro的家伙们积极地看到了pg_pathman扩展名。

我们选择了pg_pathman,我们别无选择。 甚至是1.4版。 如您所见,我们使用256个分区。 我们将整个对象表分为256个分区。
pg_pathman是做什么的? 使用此表达式,您可以创建256个分区,这些分区通过bid列中的哈希进行分区。

pg_pathman如何工作?
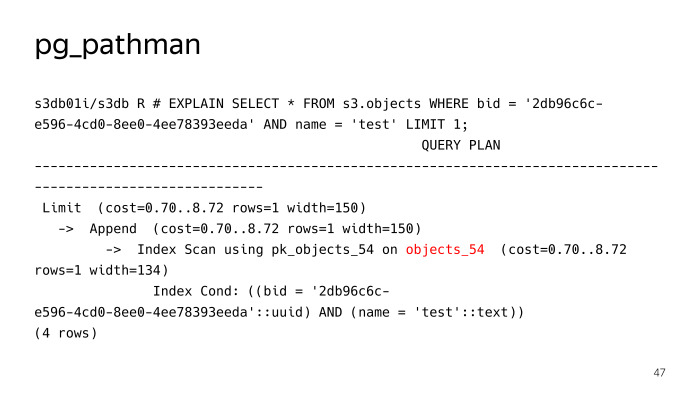
它在滑翔机上注册了它的钩子,并根据要求进一步替换了该计划。 我们看到他没有用名称test对一个对象进行常规搜索查询来搜索256个分区,但立即确定有必要爬到objects_54表,但是这里的一切进展都不顺利,pg_pathman有其自身的问题。 首先,刚开始锯的时候有很多错误,但是由于有来自Postgres Pro的家伙,他们很快就将它们修复并修复了。
第一个问题是更新它的困难。 第二个问题是准备好的语句。
让我们更详细地考虑。 特别是更新。 pg_pathman由什么组成?

它基本上由C代码组成,并打包到一个库中。 它由一个SQL部分,用于创建分区的各种函数等组成。 另外,与库中函数的接口。 这两个部分不能同时更新。
从这里开始,出现了类似这种用于更新pg_pathman版本的算法的难题,我们首先使用新版本推出了一个新软件包,但是PostgreSQL在内存中加载了旧版本,它使用了它。 在任何情况下,都必须立即重新启动基础。
接下来,我们调用set_enable_parent函数,它将打开父表中的功能,默认情况下该功能处于关闭状态。 接下来,关闭pathman,重新启动数据库,说ALTER EXTENSION UPDATE,这时所有内容都归入父表。
接下来,打开pathman,然后运行扩展中的函数,该函数将在短时间内从受到攻击的父表中转移对象,然后将其转移回应放置它们的表中。 然后关闭对父表的使用,在其中搜索。

下一个问题是准备好的语句。

如果我们阻止相同的普通请求,请按出价和关键字搜索,然后尝试执行它。 执行五次-一切都很好。 我们执行第六次-我们看到了这样的计划。 在这方面,我们看到所有256个分区。 如果仔细观察这些条件,我们会看到1美元,2美元,这就是所谓的通用计划,即通用计划。 前五个查询是单独构建的,这些参数使用了单独的计划,pg_pathman可以立即确定,因为该参数是预先知道的,因此可以立即确定要去的表。 在这种情况下,他不能这样做。 因此,该计划应具有所有256个分区,而当执行者执行此操作时,他将对所有256个分区采取共享锁,并且这种解决方案的性能并非立竿见影。 它只是失去了所有优势,并且任何请求都要花费很长时间。

我们如何摆脱这种情况? 我必须将所有内容包装在动态SQL中的execute中的存储过程中,以便不使用准备好的语句,并且每次都要构建计划。 就是这样。
不利之处在于,您必须将所有代码塞入涉及这些表的结构中。 这在这里很难阅读。

对象如何分布? 在每个S3DB分片中,存储了块计数器,还提供了有关该分片中哪些块的信息,并为其存储了计数器。 对于对象的每个变异操作(添加,删除,更改,重写),这些计数器都会更改块。 为了在活动填充处于该块中时不更新同一行,我们在将增量计数器插入单独的表中时使用了一种相当标准的技术,并且每分钟一次,一个特殊的机器人会遍历并聚合所有这些内容,从而在该块中更新计数器。

此外,这些计数器会延迟发送到S3Meta,已经完整了解了哪个块中有多少个计数器,然后您可以查看分片的分布,该分片中有多少个对象,并基于此决定新块落在哪里。 创建存储桶时,默认情况下,会创建一个从负无穷大到正无穷大的单个块,具体取决于S3Meta知道的对象的当前分布,它属于某种分片。
当您将数据倒入该存储桶时,所有这些数据都会倒入该块中,当达到一定大小时,将出现一个特殊的机械手来共享该块。

我们将这些块减小。 我们这样做是为了在这种情况下,可以将此小块拖动到另一个分片中。 块拆分如何发生? 这是一个常规的机器人,它通过两阶段提交来拆分S3DB中的该块,并更新S3Meta中的信息。
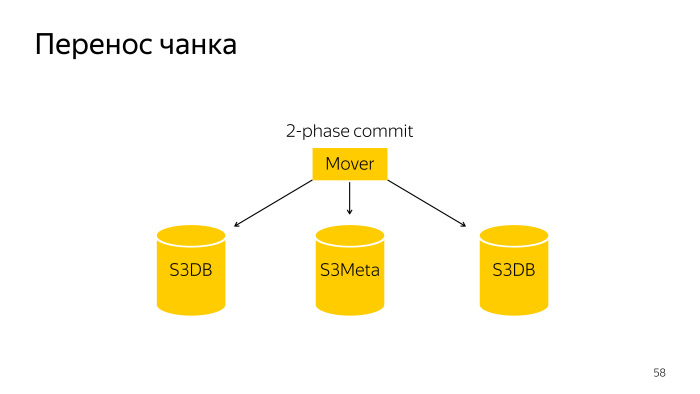
块传输是一个稍微复杂些的操作;它是在三个基础S3Meta和两个碎片S3DB上从两个拖到另一个的两阶段提交。

S3具有清单功能,这是最困难的事情,并且也存在问题。 实际上,清单说S3-向我展示我拥有的对象。 以红色突出显示的参数现在为Null。 该参数(分隔符,分隔符)可以指定所需的分隔符列表。
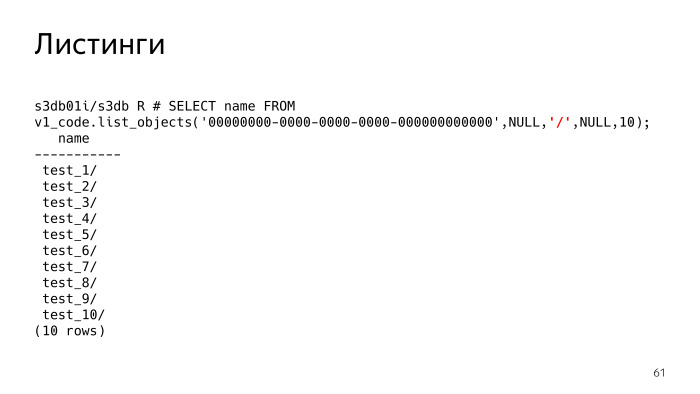
这是什么意思? 如果未设置分隔符,则会看到仅给出了文件列表。 如果我们设置了分界符,则实质上,S3应该向我们显示文件夹。 我必须了解有这样的文件夹,实际上,它显示了当前文件夹中的所有文件夹和文件。 当前文件夹带有前缀,此参数为Null。 我们看到有10个文件夹。
并非像文件系统那样,所有密钥都以某种分层树结构存储。 每个对象都存储为字符串,并且具有简单的公共前缀。 S3必须自己了解这是驴。

SQL, . , PL/pgSQL. , repeatable read. , . , - - , .
Recursive CTE, , - , execute PL/pgSQL. , . , , , list objects. , .
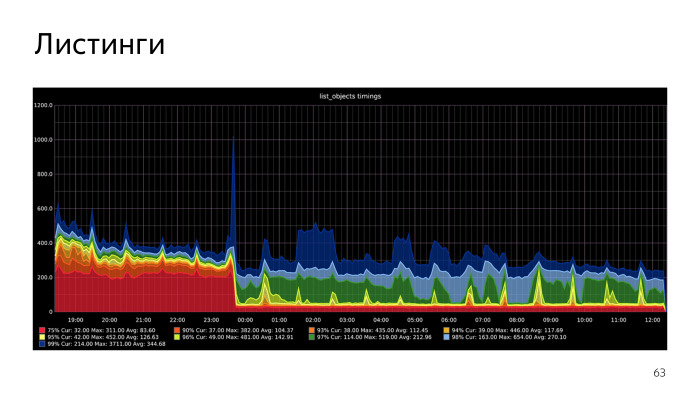
, .
. , .
Docker,
Behave Behave
. , , , .
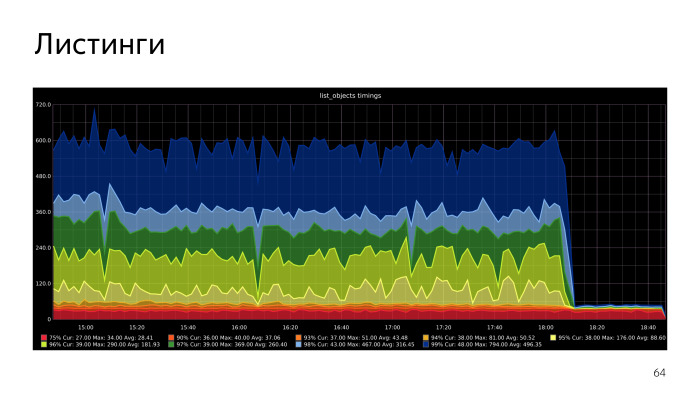
. , , CPU S3Meta. Gist index CPU, , . CPU S3Meta . , . PLProxy , S3Meta S3DB. , . S3Meta . , .
在逻辑复制中,我们将解决许多问题,我们将尝试将其推向上游。第二个选项-您可以拒绝直方图,尝试将此文本范围放入btree。这不是一维类型,并且btree仅适用于一维类型。但是,块不应该与我们重叠的条件将使我们可以将案例放在btree中。就在昨天,我们制作了一个可行的原型。它是在PL / pgSQL函数上实现的。我们有了明显的加速,我们将朝这个方向进行优化。