
在线电影院Okko的分析部门中的我们希望尽可能自动地计算Alexander Nevsky的电影费用,并希望在空闲时间学习新事物并实现一些很酷的事物,由于某些原因,这些东西通常会转化为Telegram的机器人。 例如,在2018年FIFA世界杯开始之前,我们推出了一个机器人进行工作聊天,该机器人收集了关于最终位置分配的赌注,并在决赛之后根据预先制定的指标计算了结果并确定了获胜者。 克罗地亚尚未在前四名中排名第四。
最近,我们从整理TOP-10俄罗斯喜剧的空闲时间中致力于创建一个可以找到用户最喜欢的名人的机器人 。 在工作聊天中,每个人都非常欣赏这个主意,因此我们决定将其公开发布。 在本文中,我们简要回顾了这一理论,并讨论了我们的机器人的创建以及如何自己做。
一点理论(主要是图片)
在前面的一篇文章中 ,我详细讨论了如何配置人脸识别系统。 有兴趣的读者可以点击该链接,我仅在下面概述要点。
因此,您有一张照片,其中甚至可能显示了一张脸,并且您想了解它是谁。 为此,您需要遵循4个简单的步骤:
- 选择与面部接壤的矩形。
- 突出显示面部关键点。
- 对齐并修剪脸部。
- 将面部图像转换为某种机器解释的表示形式。
- 将此视图与您可用的其他视图进行比较。
人脸选择
尽管卷积神经网络最近学会了在图像中找到人脸,但并不比经典方法差,但是它们在速度和易用性方面仍不如经典HOG 。
HOG-定向梯度直方图。 这个家伙将源图像的每个像素与其梯度相关联-梯度是像素亮度变化最大的方向的向量。 这种方法的优点是它不关心像素亮度的绝对值,仅它们的比率就足够了。 因此,将以近似相同的梯度直方图显示正常,变暗,光线不足和嘈杂的脸部。
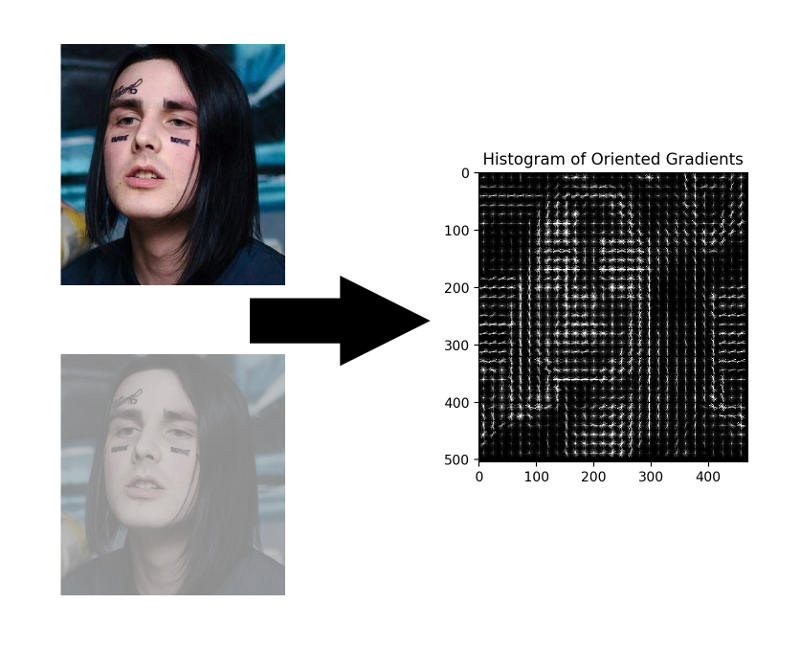
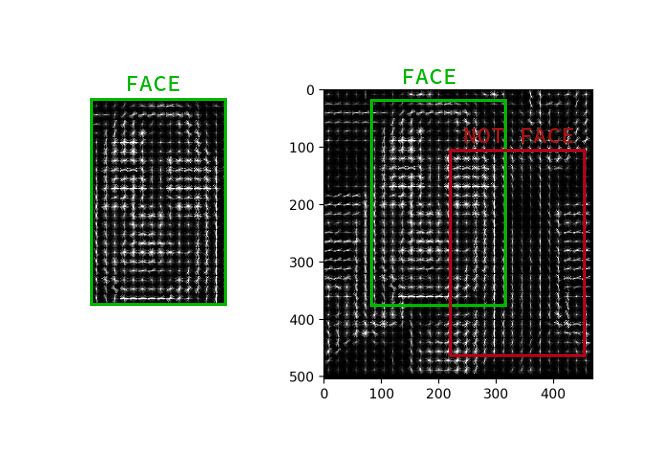
不必为每个像素计算梯度,而为每个小正方形n x n计算平均梯度就足够了。 然后,使用接收到的矢量场,您可以通过一个带有窗口的检测器,并为每个窗口确定面部在其中的可能性。 检测器可以是SVM,随机森林或其他任何东西。
突出重点

关键点是有助于识别太空中人物的点。 虚弱和不安全的科学家通常需要68个关键点,在特别被忽视的情况下,甚至需要更多。 正常的和自信的男孩,每秒赚300k,总是有五个:眼睛和鼻子的内外角。
这样的点可以例如通过级联回归器来提取。
人脸对齐
在儿童期应用程序胶合? 这里的一切都完全相同:您建立仿射变换,将三个任意点转换为它们的标准位置。 鼻子可以保持原状,但眼睛可以计算其中心-这是准备好的三点。

将面部图像转换为矢量

自有关FaceNet的文章发表以来已经过去了三年 ,在这段时间里出现了许多有趣的训练方案和损失函数,但是在可用的OpenSource解决方案中,正是她占据了主导地位。 显然,整个过程是易于理解,实施和良好结果的结合。 至少要感谢在过去三年中将体系结构更改为ResNet的事实。
FaceNet从三重示例中学习:(锚定,肯定,否定)。 锚定和正例属于一个人,而负数则被选为另一个人的脸,由于某种原因,该网络与第一个人太近。 损失函数的设计方式是纠正这种误解,将必要的示例汇总在一起,并从中删除不必要的示例。

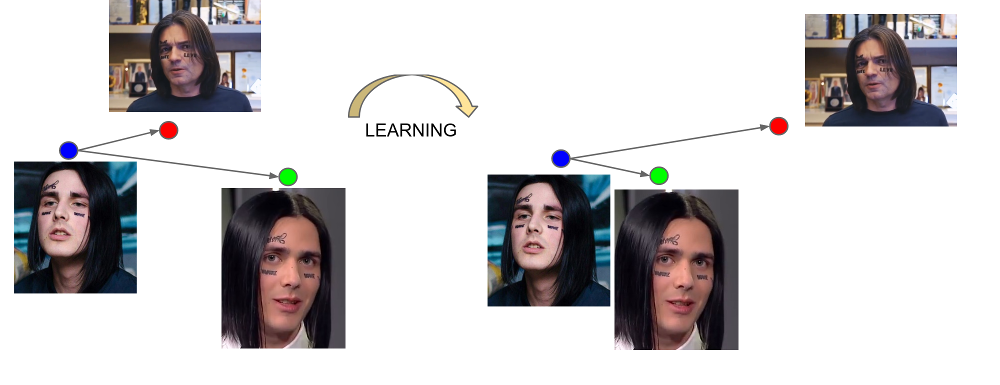
网络最后一层的输出称为嵌入-人在特定小尺寸空间(通常为128维)中的代表表示。
人脸比较
训练有素的嵌入的优点在于,一个人的脸部显示在某个较小的空间邻域中,而远离其他人的脸部。 因此,对于该空间,您可以输入相似性的度量,即距离的倒数:欧几里得或余弦,具体取决于训练网络的距离。
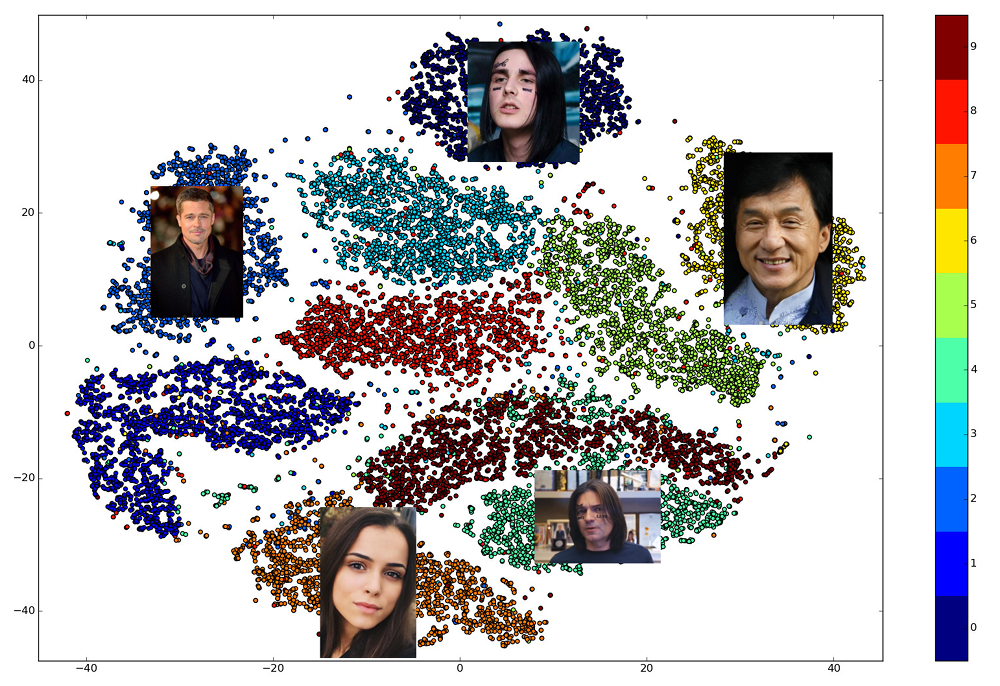
因此,我们事先需要为将要在其中进行搜索的所有人员建立嵌入,然后针对每个请求在其中找到最接近的向量。 或者,以另一种方式解决如果我们要使用一些更高级的业务逻辑,则找到k最接近的邻居的问题,其中k可能等于一个,也可能不等于。 拥有结果向量的人将与请求人最相似。

使用哪个库?
选择实现管道各个部分的开放库非常棒。 dlib和OpenCV可以找到面孔和关键点,并且可以为任何大型神经网络框架找到经过预先训练的网络版本。 有一个OpenFace项目,您可以在其中选择满足速度和质量要求的体系结构。 但是只有一个库允许您在对三个高级函数的调用中实现人脸识别的所有5点: dlib 。 同时,它是用现代C ++编写的,使用BLAS,具有Python的包装器,不需要GPU,并且可以在CPU上快速运行。 我们的选择落在了她身上。
制作自己的机器人
在每一个有关创建机器人的指南中,都已经对这一部分进行了描述,但是一旦我们编写了相同的机器人,就必须重复一下。 我们写@BotFather并要求他为我们的新机器人添加令牌。
令牌看起来像这样: 643075690:AAFC8ola8WRdhGbJtzjmkOhne1FGfu1BFg 。 在对Telegram bot API的每个请求中,都必须授权。
我希望现阶段选择编程语言的人不会有任何疑问。 当然,您必须使用Haskell编写。 让我们从主模块开始。
import System.Process main :: IO () main = do (_, _, _, handle) <- createProcess (shell "python bot.py") _ <- waitForProcess handle putStrLn "Done!"
从代码中可以看到,将来我们将使用特殊的DSL编写电报机器人。 该DSL上的代码写在单独的文件中。 安装域语言和所有必要的东西。
python -m venv .env source .env/bin/activate pip install python-telegram-bot
python-telegram-bot是目前最容易创建bot的框架。 它易于学习,灵活,可扩展,支持多线程。 不幸的是,目前还没有一个普通的异步框架,必须使用古老的线程代替神圣的协程。

使用python-telegram-bot启动python-telegram-bot很容易。 将以下代码添加到bot.py
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
运行机器人。 出于调试目的,可以使用python bot.py完成此操作,而无需运行Haskell代码。
这种简单的漫游器能够保持最少的对话,因此,可以很容易地将其安排为前端开发人员。
但是开发人员的前端已经太多了,因此我们将尽快将其终止,并继续实施主要功能。 为简单起见,我们的漫游器只会回复包含照片的消息,而忽略其他任何消息。 将代码更改为以下内容。
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
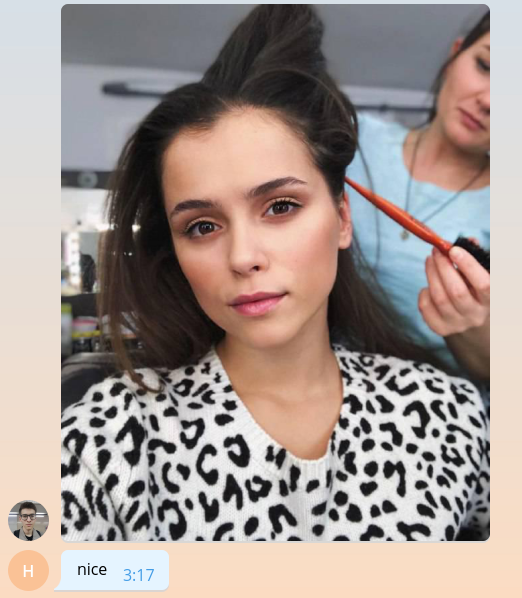
当图片进入电报服务器时,它会自动调整为几个预定的尺寸。 该机器人又可以从message.photo列表中按升序排列的图像中下载任何大小的图像。 最简单的选择:拍摄最大的图像。 当然,在杂货店环境中,您需要考虑网络负载和负载时间,并选择最小尺寸的图像。 将图像下载代码添加到handle_photo函数的顶部。
import io
message = update.message photo = message.photo[~0] with io.BytesIO() as fd: file_id = bot.get_file(photo.file_id) file_id.download(out=fd) fd.seek(0)
图像已下载并在内存中。 为了解释它并以像素强度矩阵的形式呈现,我们使用Pillow和numpy库。
from PIL import Image import numpy as np
以下代码需要添加到with块中。
image = Image.open(fd) image.load() image = np.asarray(image)
dlib的时间到了。 在功能之外,创建一个面部检测器。
import dlib
face_detector = dlib.get_frontal_face_detector()
在函数内部,我们使用它。
face_detects = face_detector(image, 1)
该功能的第二个参数表示在尝试检测面部之前必须应用的放大倍数。 它越大,检测器将能够检测到的面孔越小且越复杂,但是它将工作的时间越长。 face_detects以检测者对面部在其前方的信心的降序排列的面部列表。 在实际的应用程序中,您很可能希望应用一些选择主要人物的逻辑,在案例研究中,我们将仅限于选择第一个。
if not face_detects: bot.send_message(chat_id=update.message.chat_id, text='no faces') face = face_detects[0]
我们进入下一阶段-寻找关键点。 下载经过训练的模型,并将其负载移到功能之外。
shape_predictor = dlib.shape_predictor('path/to/shape_predictor_5_face_landmarks.dat')
找到关键点。
landmarks = shape_predictor(image, face)
剩下的只有很小的东西:拉直脸,通过ResNet驱动脸并获得128维嵌入。 幸运的是,dlib允许您一次调用所有这些操作。 您只需要下载预先训练的模型 。
face_recognition_model = dlib.face_recognition_model_v1('path/to/dlib_face_recognition_resnet_model_v1.dat')
embedding = face_recognition_model.compute_face_descriptor(image, landmarks) embedding = np.asarray(embedding)
看看我们生活的美好时光。 卷积神经网络的整体复杂性,支持向量法以及应用于人脸识别的仿射变换都封装在三个库调用中。
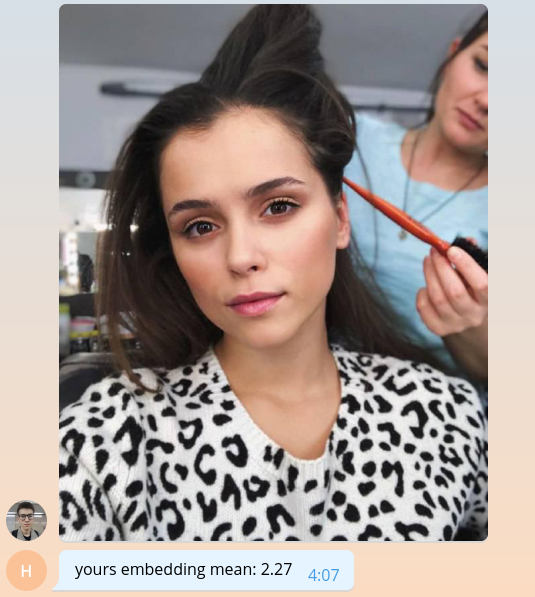
由于我们尚不知道如何做有意义的事情,因此让我们将嵌入的平均值乘以一千,返回给用户。
bot.send_message( chat_id=update.message.chat_id, text=f'yours embedding mean: {embedding.mean() * 1e3:.2f}' )
为了使我们的机器人能够确定用户喜欢哪些名人,我们现在需要为每个名人找到至少一张照片,在其上嵌入图片并将其保存在某处。 我们只会将10位名人添加到我们的训练机器人中,手动查找他们的照片并将其放在photos目录中。 它应该是这样的:
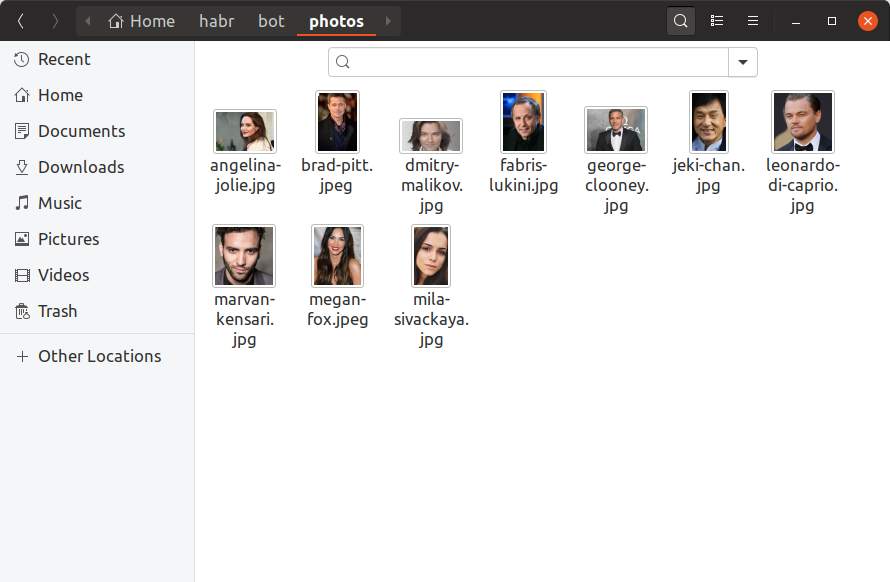
如果您想在数据库中拥有一百万名人,那么所有内容看起来都将完全一样,只有更多的文件,而且您不太可能用手寻找它们。 现在,让我们使用我们已经知道的dlib调用创建build_embeddings.py实用程序,并将名人嵌入及其名称以二进制格式保存。
import os import dlib import numpy as np import pickle from PIL import Image face_detector = dlib.get_frontal_face_detector() shape_predictor = dlib.shape_predictor('assets/shape_predictor_5_face_landmarks.dat') face_recognition_model = dlib.face_recognition_model_v1('assets/dlib_face_recognition_resnet_model_v1.dat') fs = os.listdir('photos') es = [] for f in fs: print(f) image = np.asarray(Image.open(os.path.join('photos', f))) face_detects = face_detector(image, 1) face = face_detects[0] landmarks = shape_predictor(image, face) embedding = face_recognition_model.compute_face_descriptor(image, landmarks, num_jitters=10) embedding = np.asarray(embedding) name, _ = os.path.splitext(f) es.append((name, embedding)) with open('assets/embeddings.pickle', 'wb') as f: pickle.dump(es, f)
将嵌入加载添加到我们的机器人代码中。
import pickle
with open('assets/embeddings.pickle', 'rb') as f: star_embeddings = pickle.load(f)
通过详尽的搜索,我们将找出谁是我们的用户。
ds = [] for name, emb in star_embeddings: distance = np.linalg.norm(embedding - emb) ds.append((name, distance)) best_match, best_distance = min(ds, key=itemgetter(1)) bot.send_message( chat_id=update.message.chat_id, text=f'your look exactly like *{best_match}*', parse_mode='Markdown' )
请注意,我们使用欧几里德距离作为距离,因为 借助dlib中的网络进行了精确的培训。

仅此而已,恭喜! 我们创建了一个简单的机器人,可以确定用户喜欢的名人。 寻找更多照片,添加品牌,可扩展性,少量日志记录以及一切都可以在生产中发布仍然是剩下的。 所有这些主题都太多了,以致于无法与庞大的代码清单进行详细讨论,因此,我将在下一部分中以问答形式概述要点。
完整的培训机器人代码可在GitHub上获得 。
我们谈论我们的机器人
您的数据库中有多少名人? 您在哪里找到的?
创建机器人时,最合乎逻辑的决定似乎是从我们内部的内容库中获取名人数据。 她以图表的形式存储电影以及与电影相关的所有实体,包括演员和导演。 对于每个人,我们都可以从iCloud,相关影片和别名中了解她的姓名,登录名和密码,这些信息可用于生成指向该网站的链接。 在清理并仅提取必要的信息之后, json文件仍然如下:
[ { "name": " ", "alias": "tilda-swinton", "role": "actor", "n_movies": 14 }, { "name": " ", "alias": "michael-shannon", "role": "actor", "n_movies": 22 }, ... ]
目录中有22,000个此类条目。 顺便说一句,不是目录,而是目录。
在哪里可以找到所有这些人的照片?

好吧,你知道, 在这里和那里 。 例如,有一个很棒的库 ,它允许您从Google上传图片查询结果。 2万2千人-人数不多,我们使用56个视频流在不到一个小时的时间内为他们下载了照片。
在下载的照片中,您需要丢弃格式错误的破碎,嘈杂的照片。 然后只留下那些有脸并且这些脸满足特定条件的脸:眼睛之间的最小距离,头的倾斜度。 所有这些给我们留下了12,000张照片。
在目前的12,000名名人中,用户仅发现2名,也就是说,大约有8,000名名人仍然与众不同。 不要就这样离开它! 打开电报并找到它们全部。
如何确定欧几里得距离的相似度百分比?
好问题! 的确,与余弦相反,欧几里德距离不受限制。 因此,出现一个合理的问题,如何向用户展示比“恭喜,您的嵌入与安吉丽娜·朱莉的嵌入之间的距离是0.27635462738”更有意义? 我们的团队成员之一提出了以下简单而巧妙的解决方案。 如果您建立嵌入之间的距离分布,那将是正常的。 因此,对于他来说,您可以计算平均值和标准偏差,然后根据这些参数,为每个用户考虑有多少百分比的人不太喜欢他们的名人 。 这等效于对从d到正无穷大的概率密度函数进行积分,其中d是用户与名人集会之间的距离。
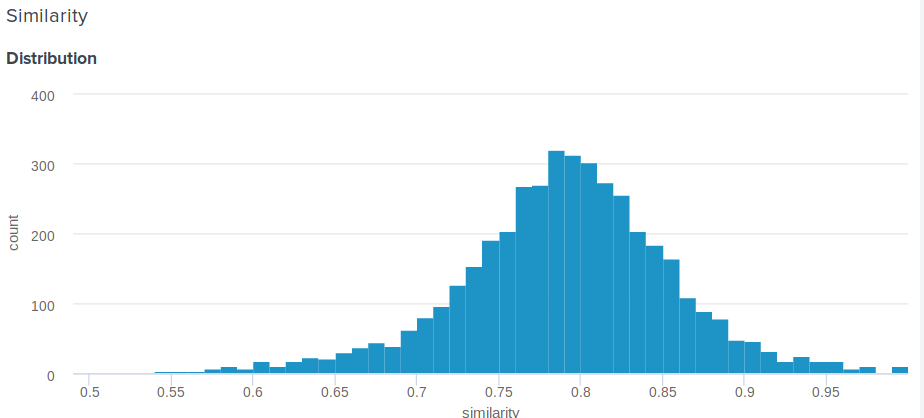
这是我们使用的确切功能:
def _transform_dist_to_sim(self, dist): p = 0.5 * (1 + erf((dist - self._dist_mean) / (self._dist_std * 1.4142135623730951))) return max(min(1 - p, 1.0), self._min_similarity)
真的有必要遍历所有工会的名单以找到匹配的人吗?
当然不是,这不是最佳选择,并且需要很多时间。 优化计算的最简单方法是使用矩阵运算。 您可以从它们组成一个矩阵,然后从矩阵中减去一个向量,而不是彼此减去向量,然后按行计算L2范数。
scores = np.linalg.norm(emb - embeddings, axis=1) best_idx = scores.argmax()
这已经极大地提高了生产率,但是事实证明,您甚至可以更快。 使用nmslib库会使搜索精度降低一些,从而可以大大加快搜索速度。 它使用HNSW方法近似搜索k最近的邻居。 对于所有可用向量,应建立一个所谓的索引,然后在其中进行搜索。 您可以如下创建并保存欧几里得距离的索引:
import nmslib index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) for idx, emb in enumerate(embeddings): index.addDataPoint(idx, emb) index_time_params = { 'indexThreadQty': 4, 'skip_optimized_index': 0, 'post': 2, 'delaunay_type': 1, 'M': 100, 'efConstruction': 2000 } index.createIndex(index_time_params, print_progress=True) index.saveIndex('./assets/embeddings.bin')
参数M和efConstruction在文档中进行了详细描述,并根据所需的准确性,索引构建时间和搜索速度通过实验进行选择。 使用索引之前,必须下载:
index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) index.loadIndex('./assets/embeddings.bin') query_time_params = {'efSearch': 400} index.setQueryTimeParams(query_time_params)
efSearch参数影响查询的准确性和速度,并且可能与efConstruction不匹配。 现在您可以提出请求。
ids, dists = index.knnQuery(embedding, k=1) best_dx = ids[0] best_dist = dists[0]
在我们的例子中, nmslib比矢量线性版本快20倍,平均处理一个请求0.005秒。
如何使我的机器人准备投入生产?
1.异步
首先,您需要使handle_photo函数异步。 就像我已经说过的那样, python-telegram-bot为此提供了多线程,并实现了一个方便的装饰器。
from telegram.ext.dispatcher import run_async @run_async def handle_photo(bot, update): ...
现在,框架本身将在其池中的单独线程中启动处理程序。 创建Updater时设置池大小。 “但是在python中没有多线程!” 你们中最不耐烦的人已经惊呼了。 这并非完全正确。 由于存在GIL,因此常规Python代码实际上不能并行执行,但是GIL被释放以等待所有IO操作,并且还可以由使用C扩展的库释放。
现在分析一下handle_photo函数:它仅包括等待IO操作(上传照片,发送响应,从磁盘读取照片等)以及从numpy , nmslib和Pillow库调用函数。
我没有提到dlib是有原因的。 释放GIL不需要调用本机代码的库,而dlib此权利。 她不需要这个锁,她只是不放手。 作者说他会很乐意接受适当的请求,但是我太懒了。
2.多重处理
处理dlib的最简单方法是将模型封装在单独的实体中,然后在单独的进程中运行它。 并且更好地在过程池中。
def _worker_initialize(config): global model model = Model(config) model.load_state() def _worker_do(image): return model.process_image(image) pool = multiprocessing.Pool(8, initializer=_worker_initialize, initargs=(config,))
result = pool.apply(_worker_do, (image,))
3.铁
如果您的机器人需要不断从磁盘读取照片,请确保该磁盘是SSD。 甚至将它们安装到RAM中。 对电报服务器执行Ping操作,信道质量也很重要。
4.防洪
电报不允许漫游器每秒发送30条以上的消息。 如果您的漫游器很流行,并且很多人同时使用它,那么很容易就可以暂停几秒钟的禁令,这对许多用户来说都是令人失望的。 为了解决这个问题, python-telegram-bot为我们提供了一个队列,该队列不能每秒发送超过指定的消息限制,并在发送之间保持相等的间隔。
from telegram.ext.messagequeue import MessageQueue
要使用它,您需要定义自己的机器人并在创建Updater时将其替换。
from telegram.utils.promise import Promise class MQBot(Bot): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self._message_queue = MessageQueue( all_burst_limit=30, all_time_limit_ms=1000 ) def __del__(self): try: self._message_queue.stop() finally: super().__del__() def send_message(self, *args, **kwargs): is_group = kwargs.get('chat_id', 0) >= 0 return self._message_queue(Promise(super().send_message, args, kwargs), is_group)
bot = MQBot(token=TOKEN) updater = Updater(bot=bot)
5.网页挂钩
在产品环境中,应始终使用Web Hooks代替Long Polling,以从Telegram服务器接收更新。 它的全部内容和用法可以在这里阅读。
6.琐事
json . , ultrajson .
IO-: , , . , .
6.
, . , , , . , .
, , BI-tool Splunk .
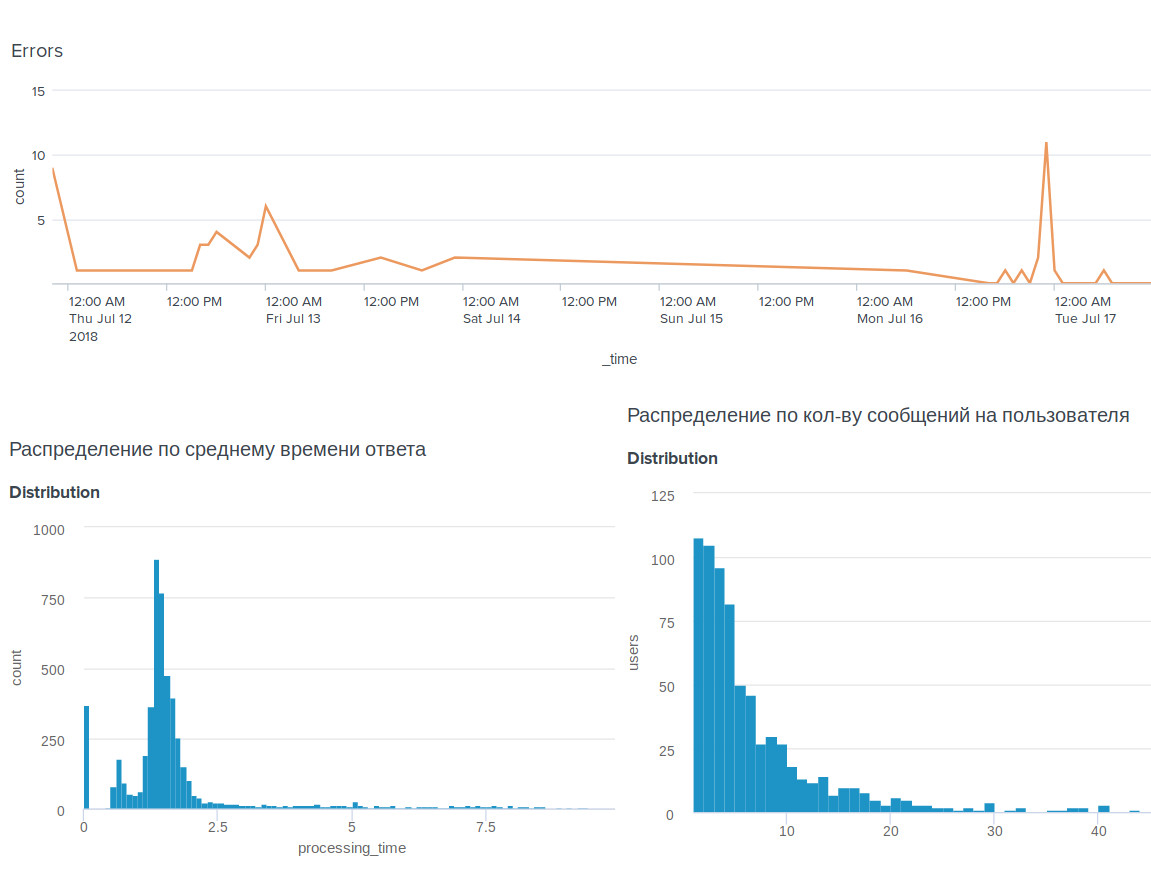
, . , .
, . , : @OkkoFaceBot .