在执行我们编写的代码之前,它要走很长一段路。
安德烈·梅利霍夫 (
Andrey Melikhov)在其有关RIT ++ 2018的报告中,使用V8引擎的示例检查了该路径上的每个步骤。 深入了解如何使我们深入了解编译器的原理以及如何提高JavaScript代码的生产率。

我们将了解WASM是否是提高代码性能的灵丹妙药,以及是否总是有理由进行优化。
剧透: “过早的优化是所有弊端的根源,” Donald Knuth说。
 关于演讲者:
关于演讲者: Andrei Melikhov在Yandex.Money工作,在Node.js上积极写作,而在浏览器中很少写作,因此服务器JavaScript更接近他。 Andrew支持并开发devShacht社区,因此请查看
GitHub或
Medium 。
动机和词汇
今天我们将讨论JIT编译。 我认为这对您很有趣,因为您正在阅读。 但是,让我们澄清一下为什么您需要知道什么是JIT以及V8的工作方式,以及为什么在浏览器中编写React还是不够的。
- 由于我们的语言特定,因此您可以编写更有效的代码 。
- 它揭示了为什么在其他人的库中以这种方式而不是其他方式编写代码的困惑 。 有时我们遇到旧的库,看到写的东西有些奇怪,但是如果这是必要的,则没有必要-不清楚。 当您知道它是如何工作的时,您就知道为什么这样做了。
- 这只是很有趣 。 此外,它使我们能够了解Axel Rauschmeier,Benedict Moyrer和Dan Abramov在Twitter上的交流。
维基百科说,JavaScript是一种具有动态类型的高级解释型编程语言。 我们将处理这些条款。
编译与解释编译-以二进制代码交付程序时,该程序最初针对其工作环境进行了优化。
解释-当我们按原样交付代码时。
JavaScript是按原样提供的-它是一种解释语言,如Wikipedia所写。
动态和静态输入静态和动态类型经常与弱和强类型混淆。 例如,C是具有静态弱类型的语言。 JavaScript具有弱动态类型。
哪个更好? 如果程序可以编译,则它适合于将在其中执行的环境,这意味着它将更好地工作。 静态类型使此代码更有效。 在JavaScript中,情况恰恰相反。
但是与此同时,我们的应用程序变得越来越复杂:在客户端和服务器上,巨大的集群都出现在Node.js上,可以很好地工作并替代Java应用程序。
但是,如果最初看起来是个失败者,那一切将如何运作。
JIT将调和所有人! 或至少尝试一下。
我们有一个JIT(及时编译)发生在运行时。 我们将谈论她。
JS引擎
- 不受欢迎的查克拉,位于Internet Explorer中。 它甚至不适用于JavaScript,但与Jscript兼容-有一个这样的子集。
- 在Edge中工作的现代Chakra和ChakraCore;
- FireFox中的SpiderMonkey;
- WebKit中的JavaScriptCore。 它也用在React Native中。 如果您有适用于Android的RN应用程序,那么它也可以在JavaScriptCore上运行-该应用程序捆绑了该引擎。
- V8是我的最爱。 并不是最好的,我只使用Node.js,在所有基于Chrome的浏览器中,Node.js都是主要引擎。
- Rhino和Nashorn是Java中使用的引擎。 在他们的帮助下,您还可以在那里执行JavaScript。
- JerryScript-用于嵌入式设备;
- 和其他...
您可以编写自己的引擎,但是如果要有效执行,您将采用大致相同的方案,我将在后面显示。
今天我们将讨论V8,是的,它以8缸发动机命名。
我们爬到引擎盖下
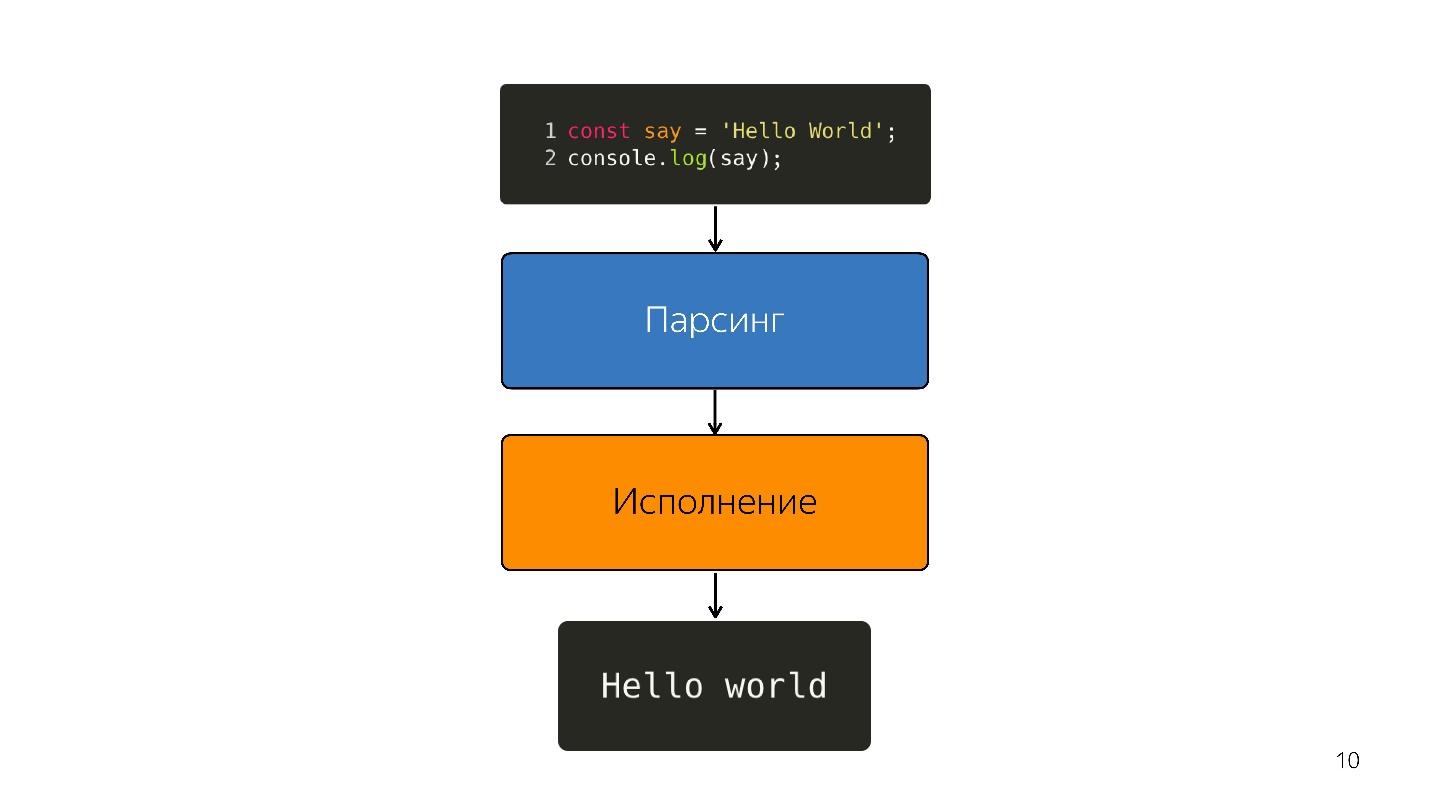
javascript如何执行?
- 提供了用JavaScript编写的代码。
- 他正在解析;
- 正在执行;
- 得到的结果。
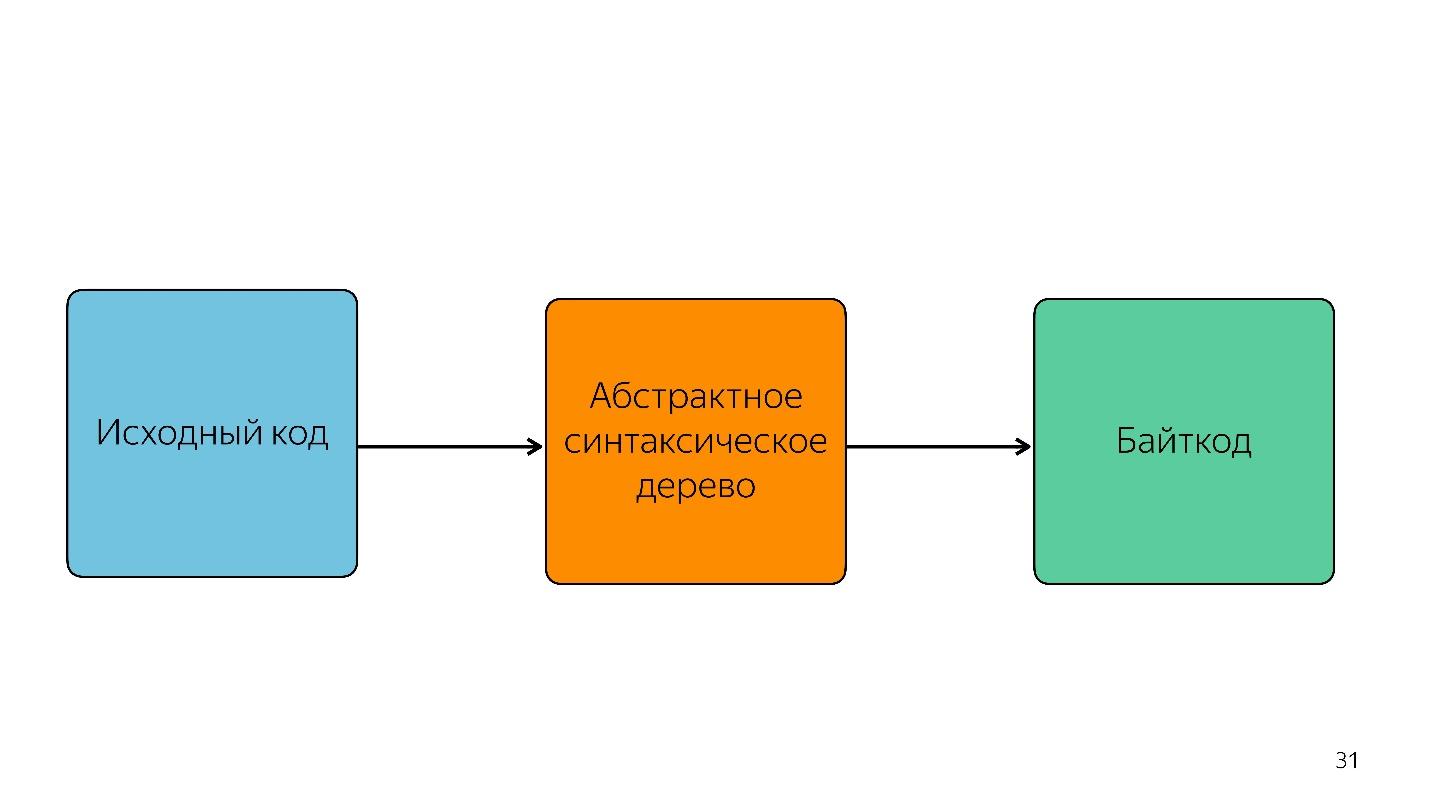
解析将代码转换成
抽象语法树 。 AST以树的形式显示代码的语法结构。 尽管很难阅读,但这实际上对程序很方便。
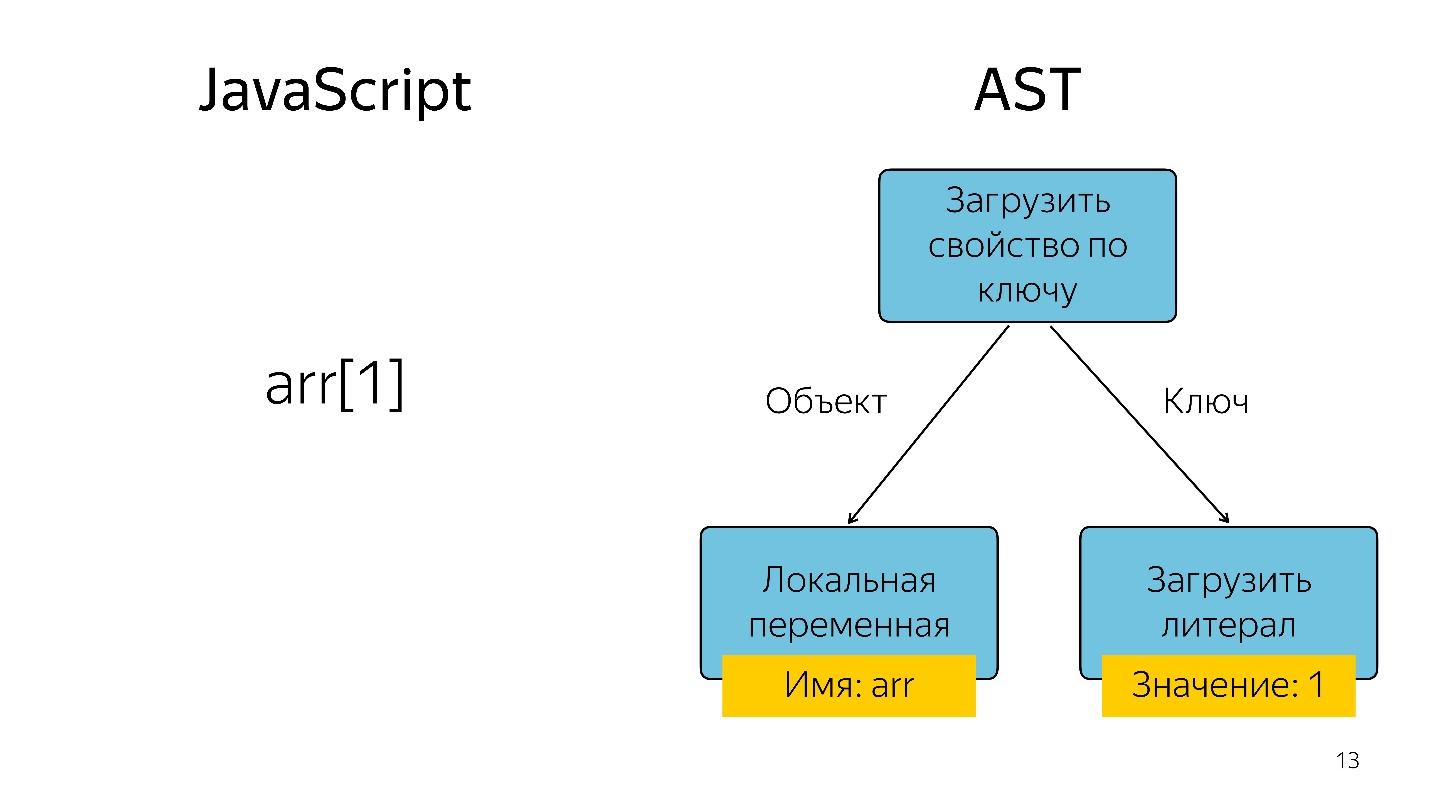
以树的形式获取索引为1的数组元素表示为一个运算符和两个操作数:按键和这些键加载属性。
AST在哪里使用?
AST不仅在引擎中。 使用AST,许多实用程序都可以编写扩展名,包括:
- ESLint;
- 巴别塔
- 更漂亮
- Jscodeshift。
例如,并不是所有人都知道的很酷的Jscodeshift允许您编写转换。 如果更改函数的API,则可以在其上设置这些转换并在整个项目中进行更改。

我们继续前进。 处理器不理解抽象语法树;它需要
机器代码 。 因此,通过语言解释器,可以通过解释器进行进一步的转换。
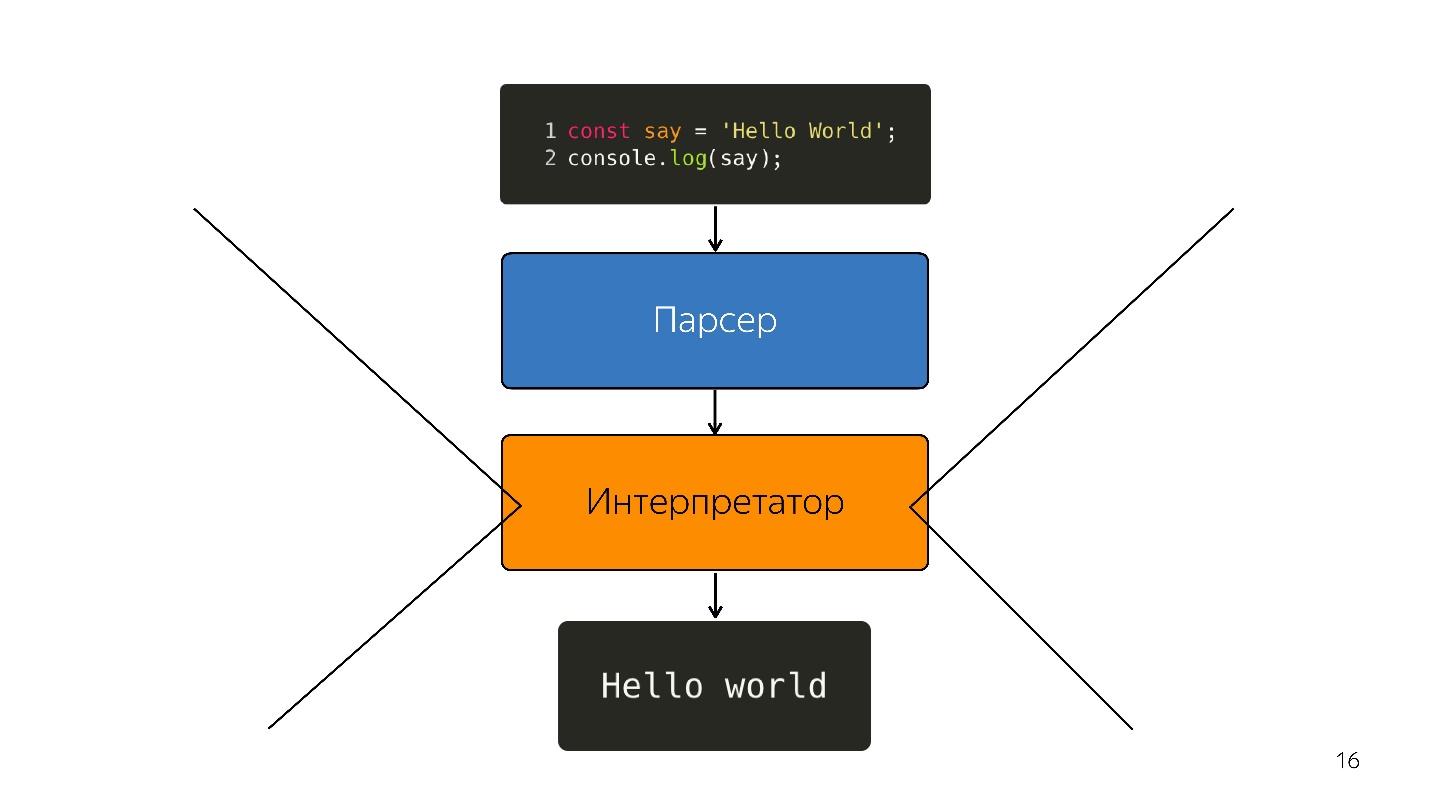
事实如此,尽管浏览器有一些JavaScript-突出显示行,打开内容,然后关闭。 但是现在我们有了SPA,Node.js和
解释器的应用程序,并且
解释器正在成为瓶颈 。
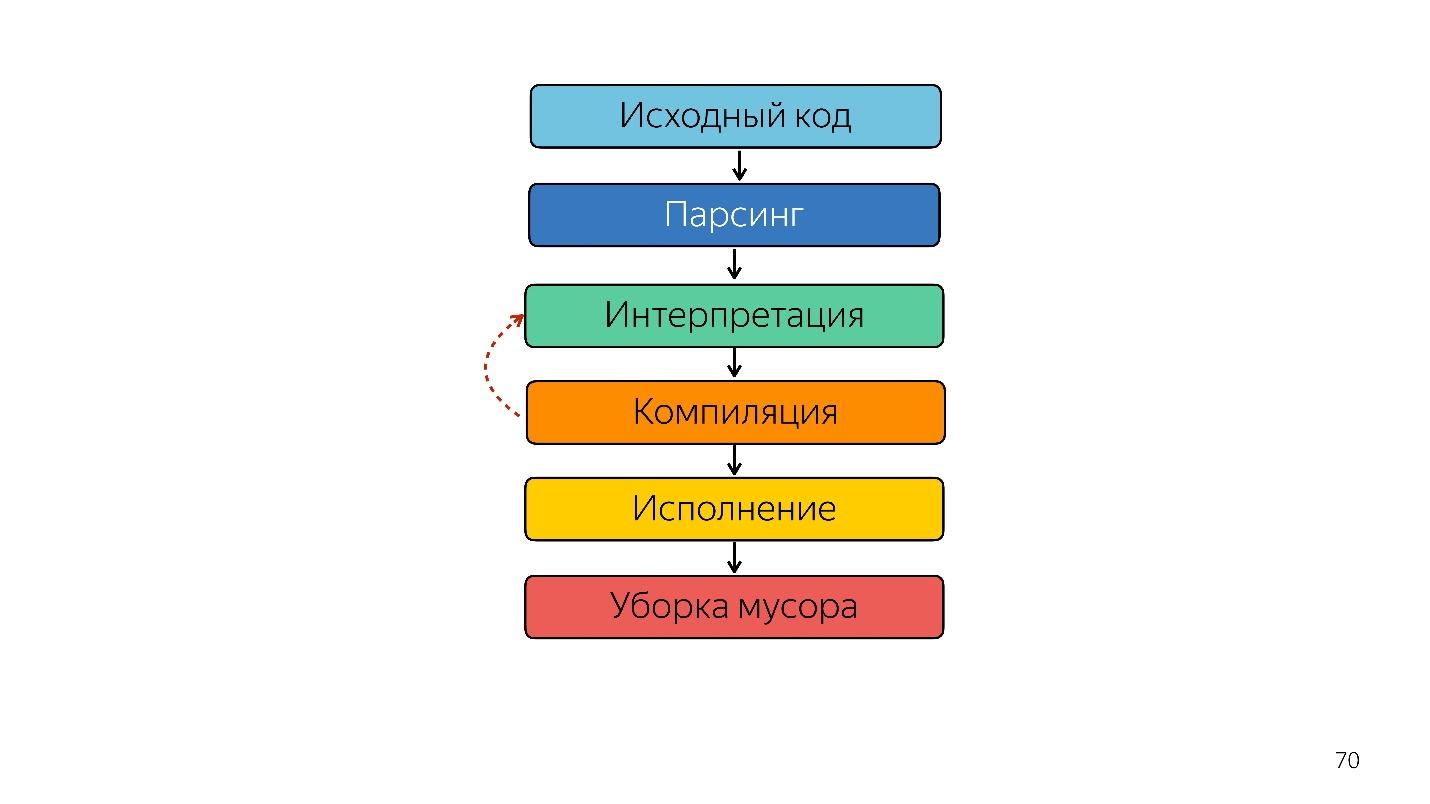
优化JIT编译器
代替解释器,出现了一个优化的JIT编译器,即即时编译器。 提前编译器在应用程序执行之前工作,而JIT-在此期间工作。 在优化问题上,JIT编译器尝试猜测代码将如何执行,将使用哪种类型,并优化代码以使其更好地工作。
这种优化称为
推测性优化,因为它推测的是之前代码发生了什么。 也就是说,如果某个数字类型的东西被调用了10次,则编译器认为这种情况将一直发生,并针对该类型进行优化。
自然地,如果布尔输入,则会发生去优化。 考虑一个加数字的函数。
const foo=(a, b) => a + b;
foo (1, 2);
foo (2, 3);折叠一次,第二次。 编译器会建立这样的预测:“这些是数字,我有一个不错的加数字的解决方案!” 然后您编写
foo('WTF', 'JS') ,并将这些行传递给函数-我们有JavaScript,我们可以添加带数字的行。
此时,发生了非优化。
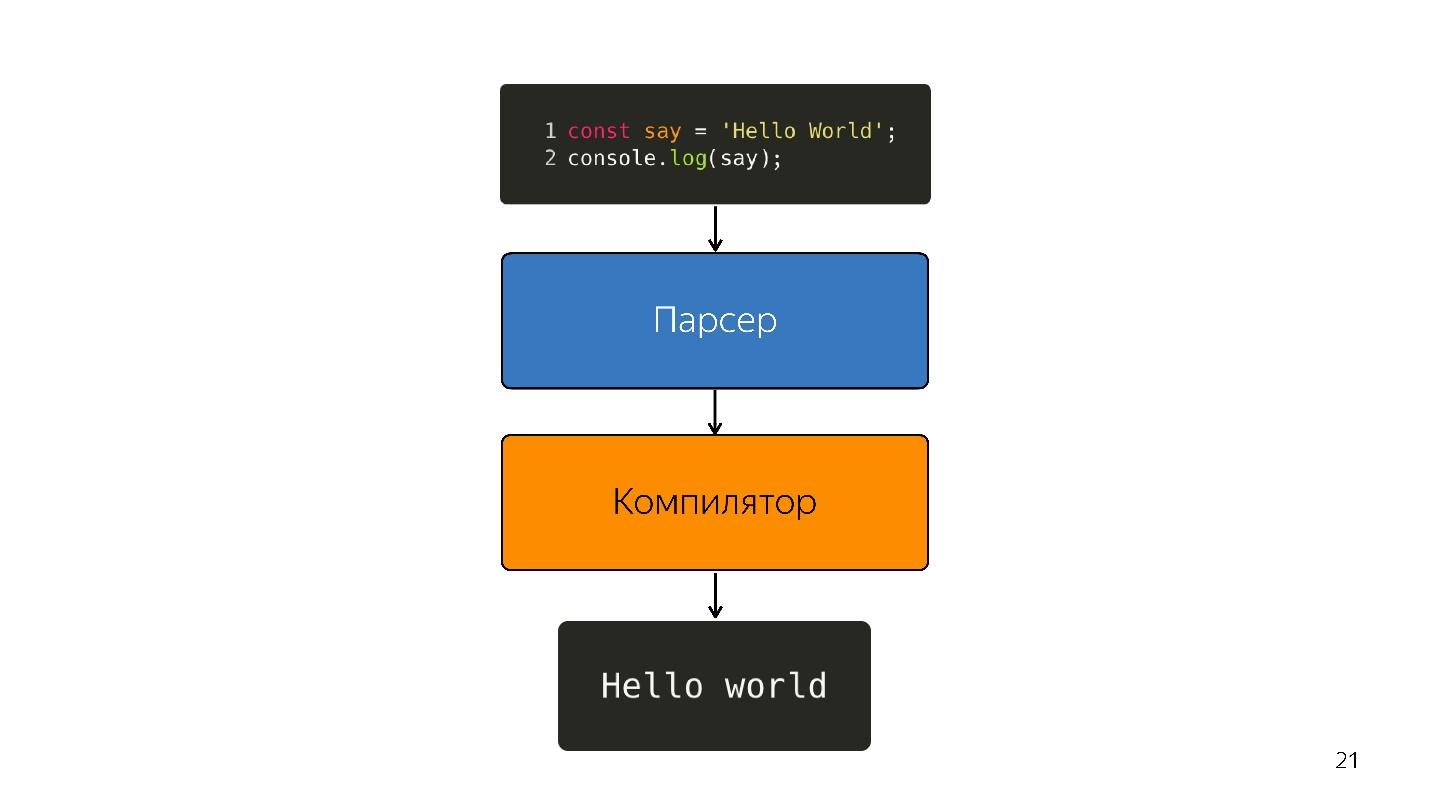
因此,解释器被编译器取代。 上图似乎有一个非常简单的管道。 实际上,一切都有些不同。
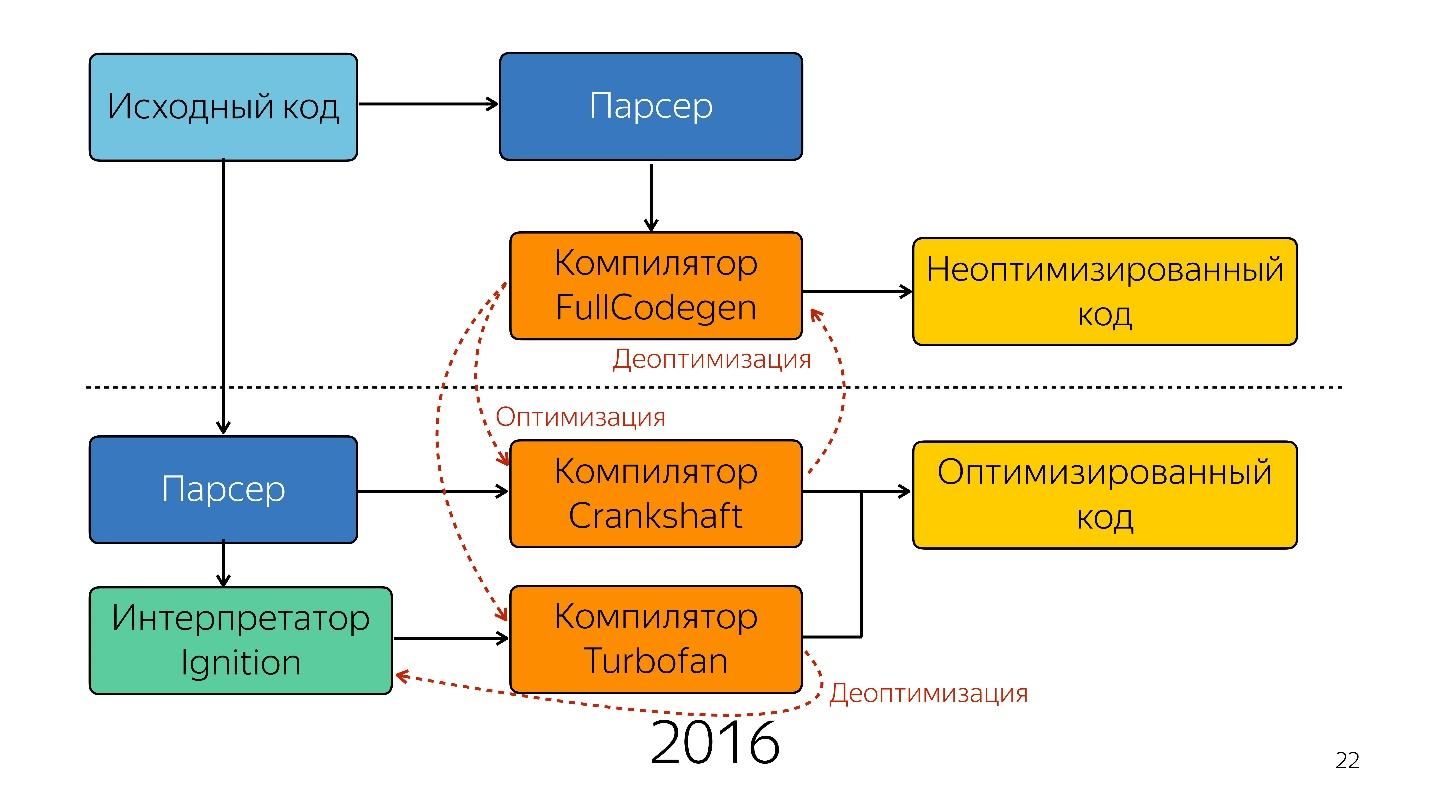
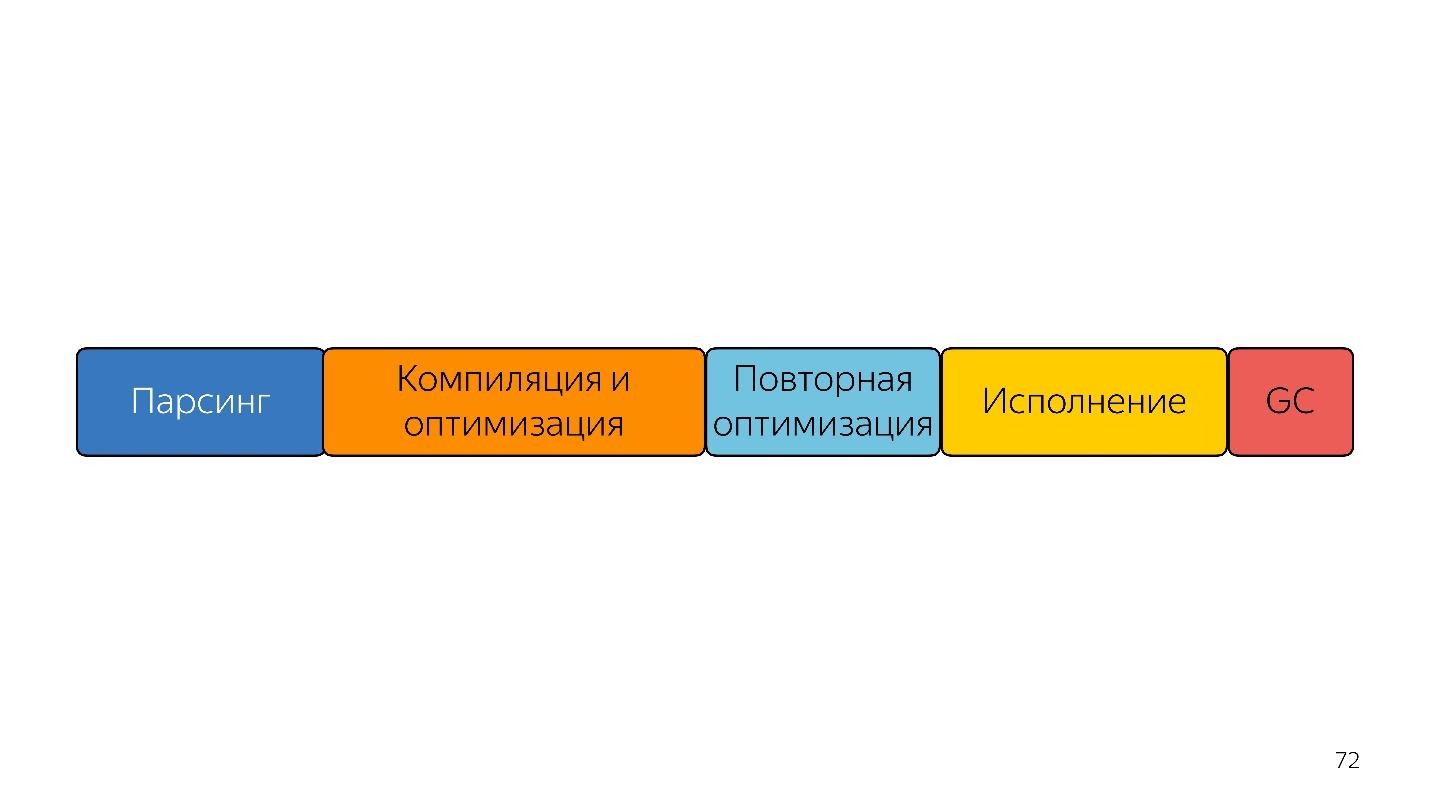
直到去年。 去年,您可能会听到Google的许多报道,他们通过TurboFan启动了新的管道,现在该计划看起来更简单了。
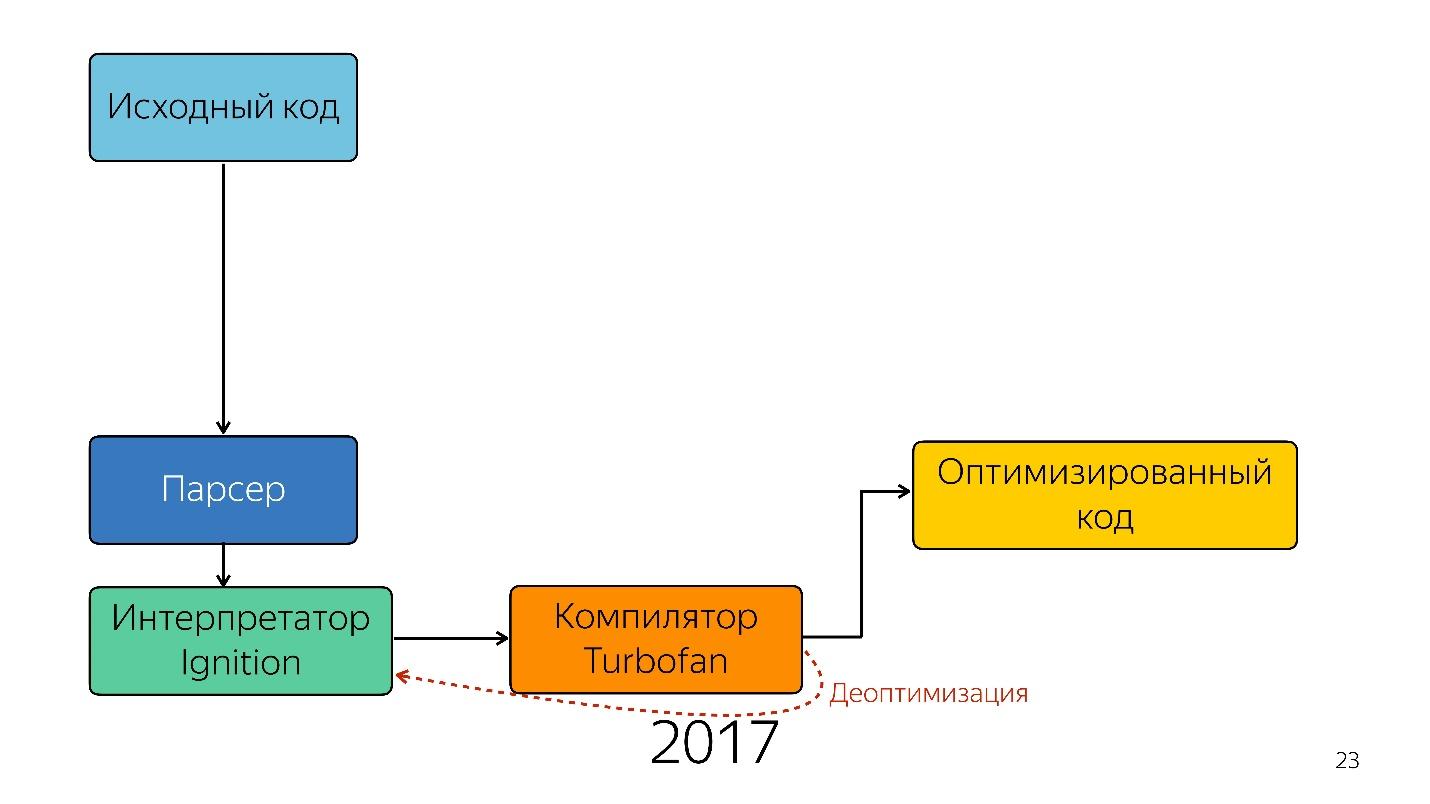
有趣的是,一位翻译出现在这里。
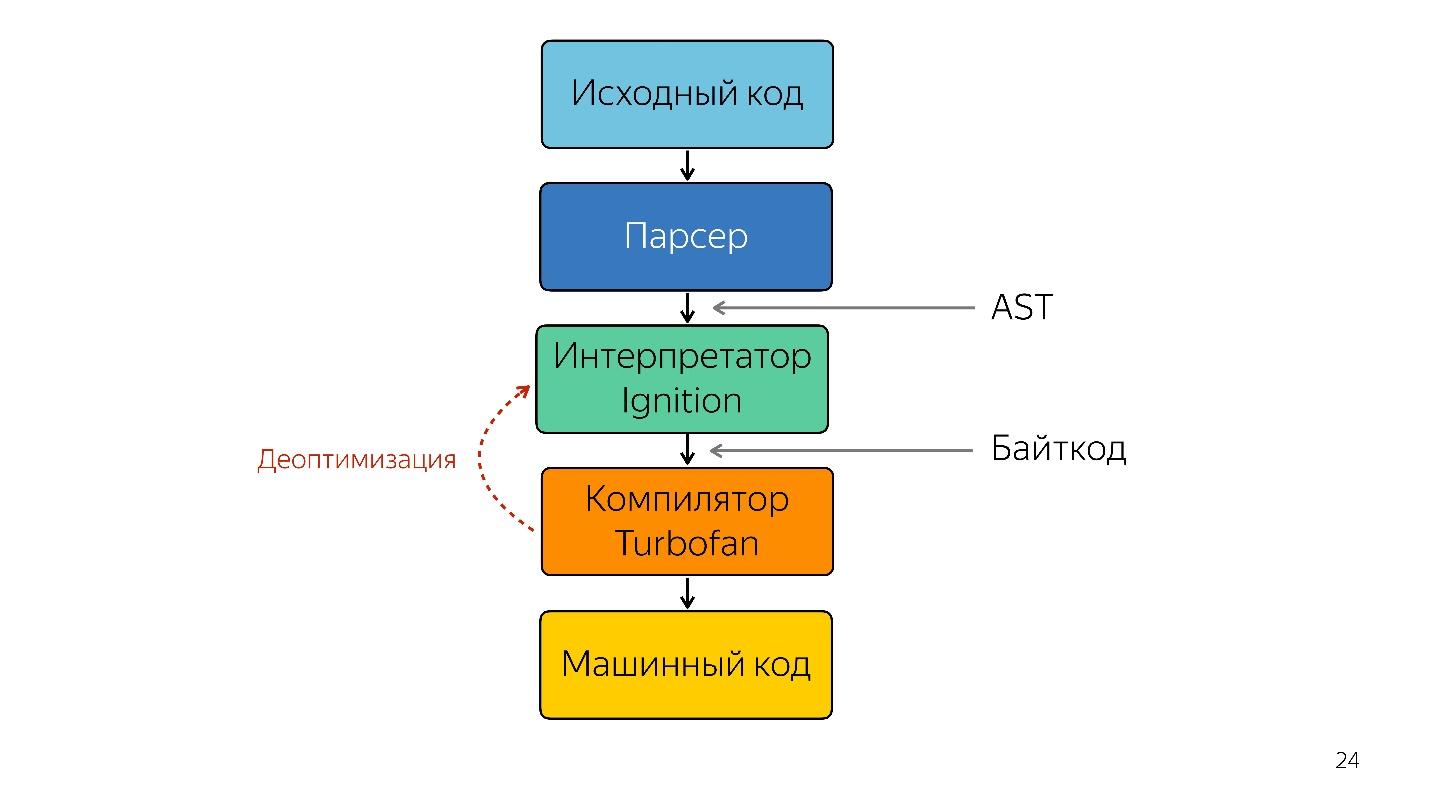
需要一个解释器将抽象语法树转换为字节码,然后将字节码传递给编译器。 在非优化的情况下,他再次去了解释器。
口译点火
以前,没有点火解释器架构。 Google最初说不需要解释器-JavaScript已经足够紧凑并且可以解释-我们不会赢得任何东西。
但是使用移动应用程序的团队遇到了以下问题。

从2013年到2014年,人们开始使用移动设备访问互联网的次数比台式机更多。 基本上,这不是iPhone,而是来自较简单的设备-它们的内存很少且处理器较弱。
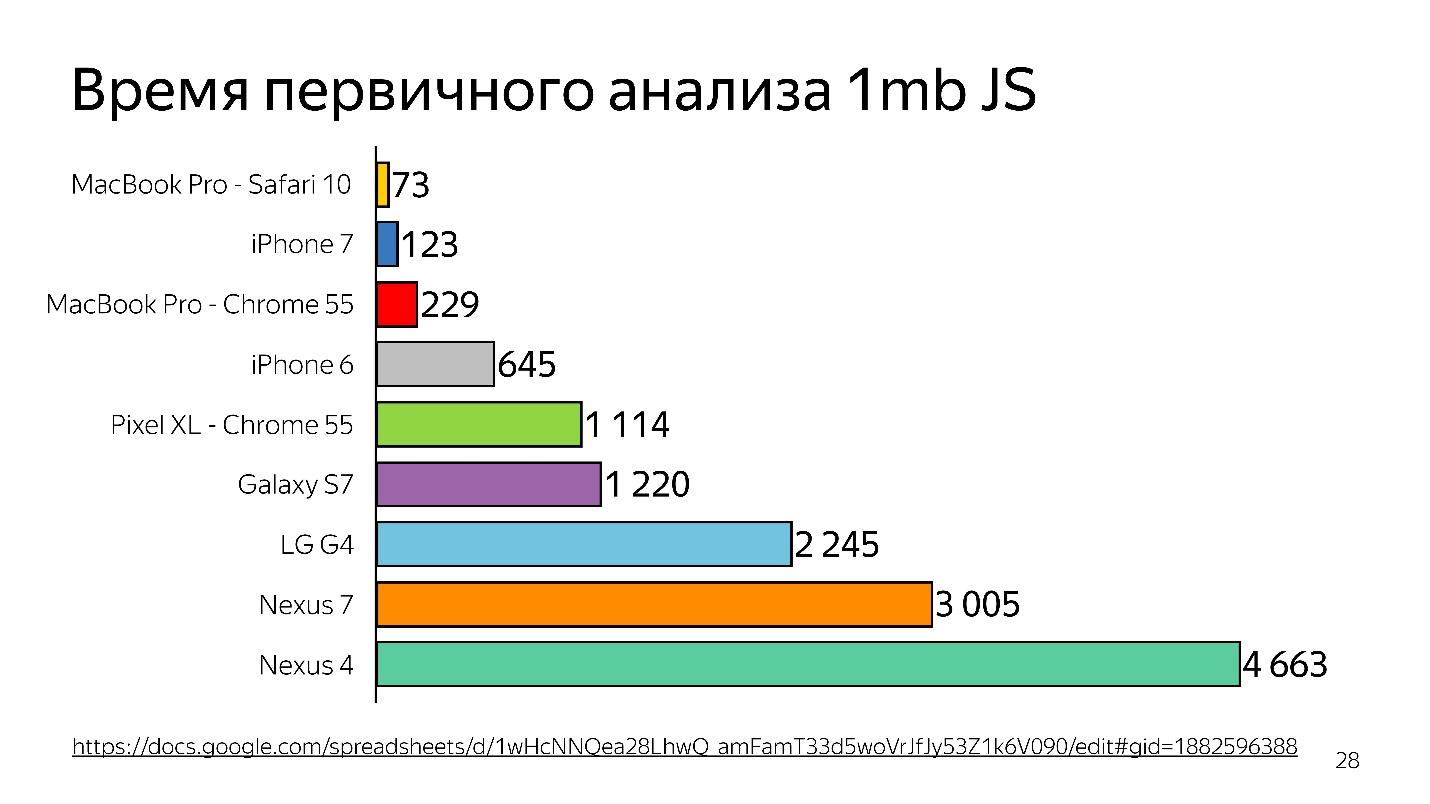
上图是启动解释器之前对1 MB代码的初始分析的图表。 可以看出,台式机大获全胜。 iPhone也不错,但是它具有不同的引擎,我们正在谈论的是可在Chrome中运行的V8。
您是否知道,如果您在iPhone上安装了Chrome,它仍然可以在JavaScriptCore上运行?
因此,浪费了时间-这仅仅是分析,而不是执行-您的文件已加载,并且试图了解其中写入的内容。
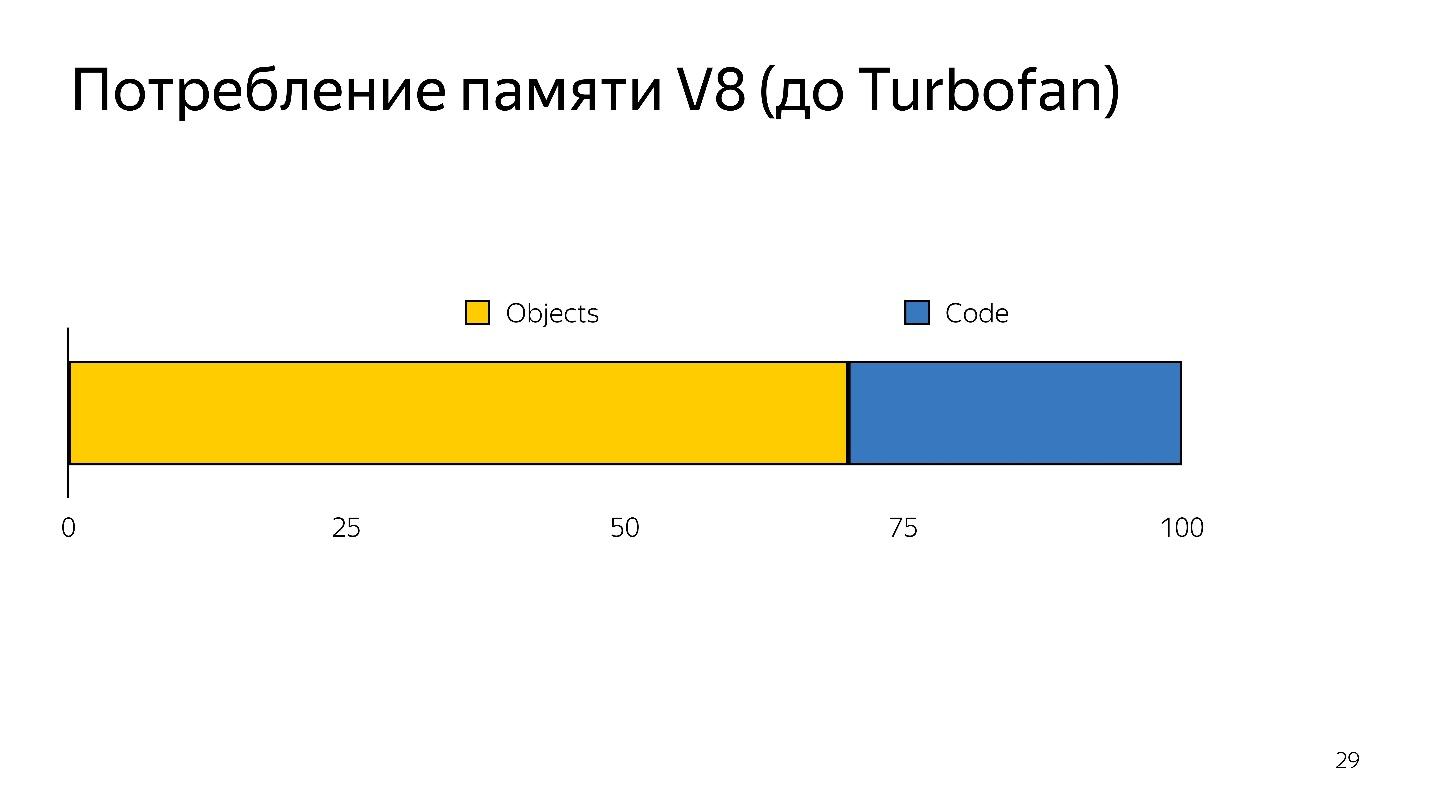
当发生非优化时,您需要再次获取源代码,即 它需要存储在某个地方。 花了很多内存。
因此,口译员有两项任务:
- 减少解析开销;
- 减少内存消耗。
通过切换到字节码解释器解决了这些任务。
 Chrome中的字节码是带电池的注册机
Chrome中的字节码是带电池的注册机 。 SpiderMonkey有一台堆叠的计算机,所有数据都在堆栈中,但是没有寄存器。 他们在这里。
我们不会完全分析它是如何工作的,只是看一下代码片段。

它在这里说:取电池中的值,并将其加到寄存器
a0中的值,即变量
a中 。 到目前为止,有关类型的信息一无所知。 如果它是真正的汇编代码,那么编写该代码时应了解内存中有哪些移位,内存中有什么移位。 这只是一条指令-将寄存器
a0中的内容加到电池中的值上。
当然,解释器不仅会采用抽象语法树并将其转换为字节码。
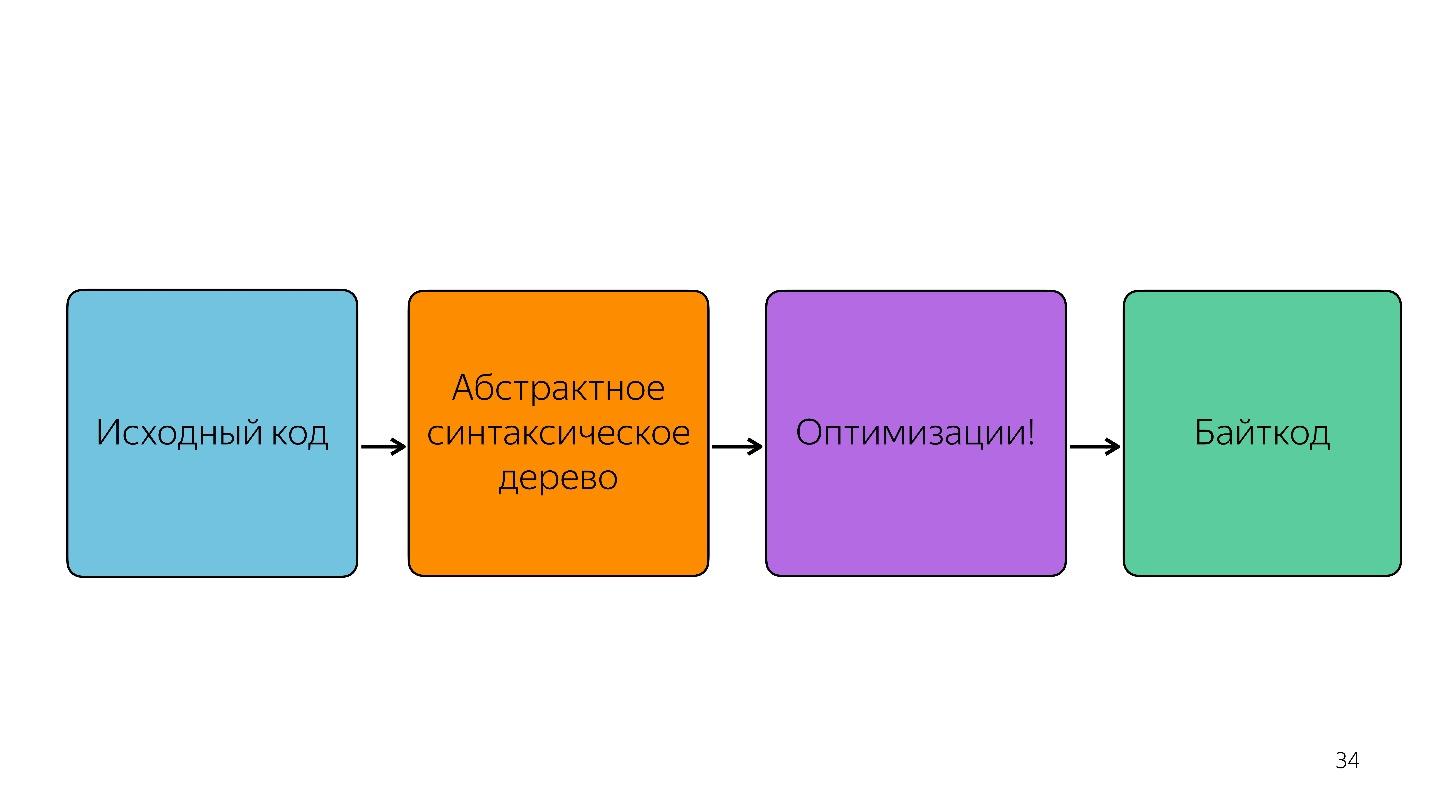
还有一些优化,例如消除死代码。
如果未调用一段代码,则会将其丢弃,并且不会进一步存储。 如果Ignition看到两个数字相加,则将其相加并以不存储不必要信息的方式离开它们。 仅在此之后才获得字节码。
优化和反优化
冷热功能
这是最简单的主题。
冷函数是一次调用或根本没有调用的函数,热函数是多次调用的函数。 无法确切地说出多少次-在任何时候都可以重做。 但是到某个时候,该功能变得很热,引擎知道需要对其进行优化。

工作计划。
- 点火(解释器)收集信息。 他不仅将JavaScript转换为字节码,而且还了解输入了哪些类型,哪些函数变得很热,并且他将所有这些告诉编译器。
- 有一个优化。
- 编译器执行代码。 一切正常,但是在这里出现了一个他没想到的类型,他没有使用此类型的代码。
- 发生非优化。 编译器访问此代码的Ignition解释器。
这是一个经常发生的正常循环,但不是无限的。 在某个时候,引擎会说:“不,无法优化”,并且在没有优化的情况下开始执行。 重要的是要理解必须遵守单态性。
单态是当相同类型总是出现在函数的输入中时。 也就是说,如果您一直都在获取字符串,则无需在此处传递布尔值。
但是如何处理对象呢? 对象都是对象。 我们有类,但它们不是真实的-只是原型模型上的糖。 但是引擎内部有所谓的隐藏类。
隐藏的课程
在所有引擎中都有隐藏的类,不仅在V8中。 就V8而言,每个地方的名称都不同,它就是Map。
您创建的所有对象都有隐藏的类。 如果你
看一下内存探查器,您将看到存在一些元素,这些元素存储在元素列表中,属性存储在属性中,而映射(通常是第一个参数),在其隐藏类上指示了指向它的链接。
Map描述了对象的结构,因为从原则上讲,在JavaScript中,键入只能是结构上的,而不是名义上的。 我们可以描述对象的外观,用途。
删除/添加隐藏类对象的属性时,对象会更改,并分配一个新对象。 让我们看一下代码。
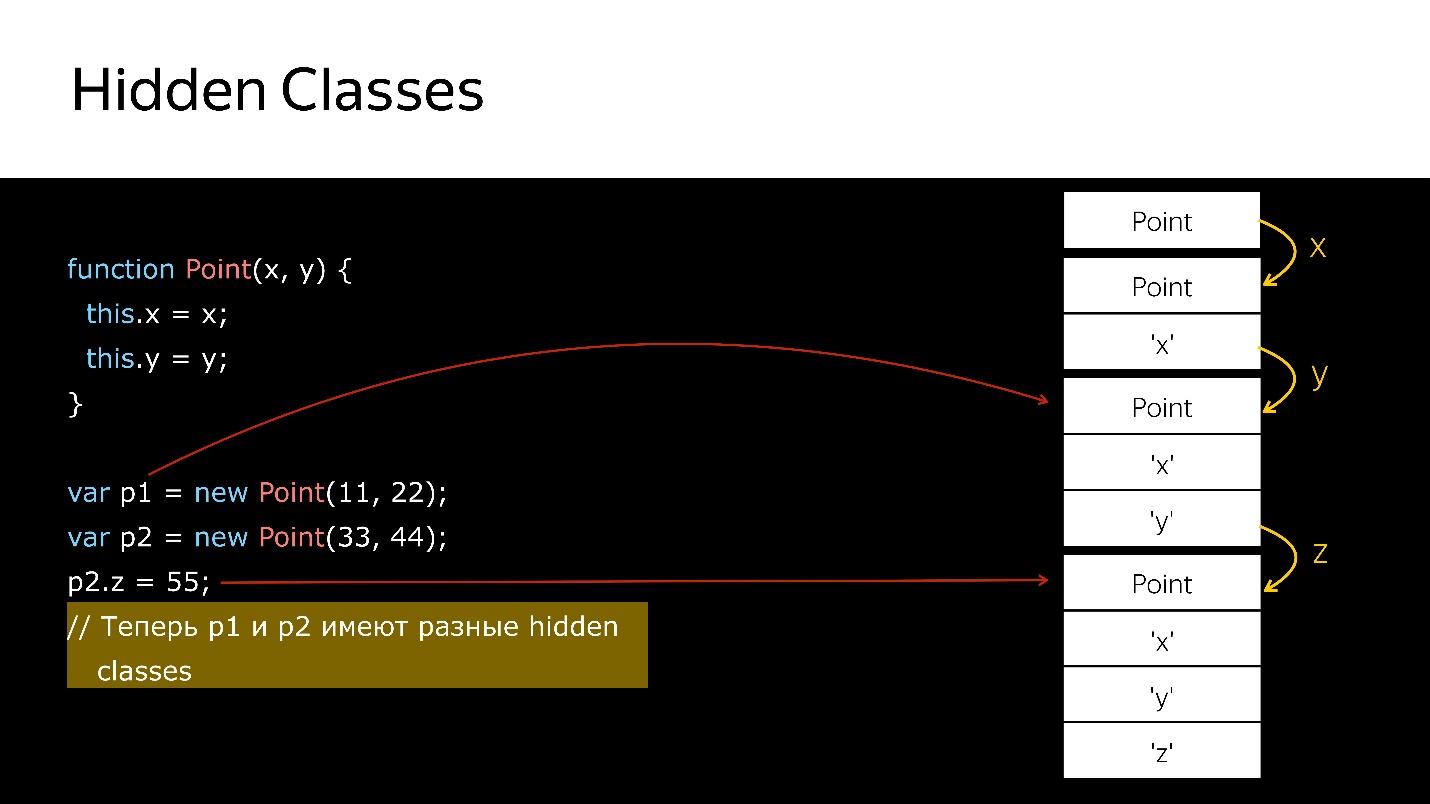
我们有一个构造函数,用于创建Point类型的新对象。
- 创建一个对象。
- 将隐藏的类绑定到它,这表明它是Point类型的对象。
- 我们添加了x字段-一个新的隐藏类,它表示它是Point类型的对象,其中x值位于第一个。
- 添加了y-新的Hidden类,其中x,然后是y。
- 创建另一个对象-发生相同的事情。 也就是说,他还绑定了已经创建的内容。 目前,这两个对象具有相同的类型(通过Hidden类)。
- 将新字段添加到第二个对象时,新的Hidden类将出现在对象中。 现在对于引擎p1和p2,它们是不同类的对象,因为它们具有不同的结构
- 如果将第一个对象转移到某处,则将第二个对象转移到某处时,将发生去优化。 第一个引用一个隐藏的类,第二个引用另一个。
如何检查隐藏的类?在Node.js中,您可以运行node -allow-natives-syntax。 然后,您将有机会以特殊的语法编写命令,这当然不能在生产中使用。 看起来像这样:
%HaveSameMap({'a':1}, {'b':1})
没有人保证明天这些命令会起作用,它们不在ECMAScript规范中,仅用于调试。
您认为将是为两个对象调用%HaveSameMap函数的结果。 正确答案是错误的,因为一个拥有一个字段,另一个拥有
b 。 这些是不同的对象。 此知识可用于Inline Caches技术。
内联缓存
我们调用一个非常简单的函数,该函数从对象返回一个字段。 归还单位似乎非常简单。 但是,如果您查看ECMAScript规范,将会看到有很多工作要做,这些工作可以从对象中获取字段。 因为,如果该字段不在对象中,则该字段可能在其原型中。 也许是setter,getter等。 所有这些都需要检查。

在这种情况下,该对象具有一个映射链接,该链接说:要获得字段
x ,您需要将偏移量加1,我们得到
x 。 您无需爬任何地方,任何原型,一切都在附近。 内联缓存使用此。
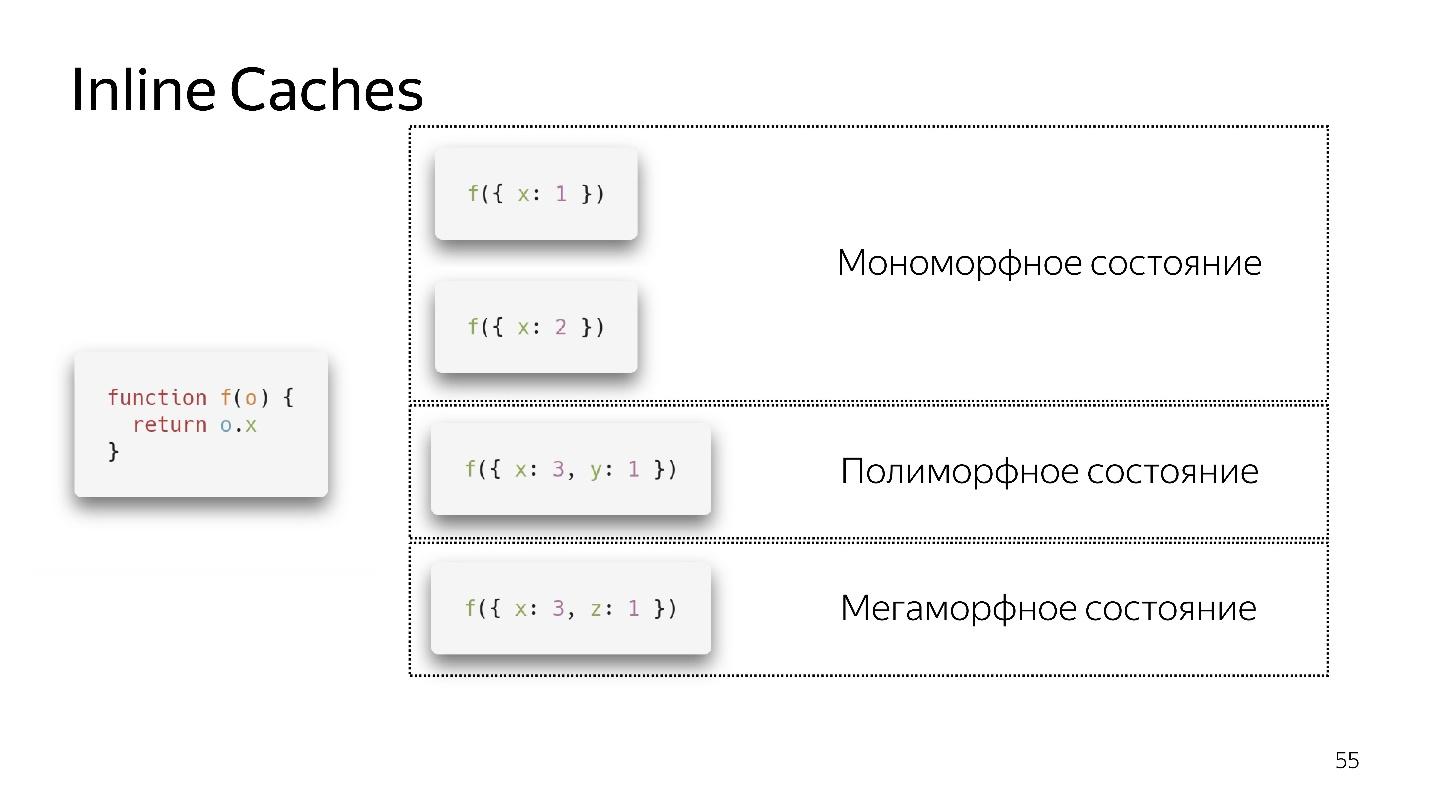
- 如果我们是第一次调用该函数,那么一切都很好,解释器已经完成了优化
- 对于第二个调用,将保存单态状态。
- 我第三次调用该函数,传递了一个略有不同的对象{x:3,y:1}。 发生非优化,如果出现,我们将进入多态状态。 现在,执行此功能的代码知道两种不同类型的对象可以飞入其中。
- 如果我们多次传递不同的对象,它将保持多态,并添加新的ifs。 但是在某个时候投降并进入了巨形状态,即 什么时候:“入口处有太多不同类型的商品-我不知道如何对其进行优化!”
似乎现在允许4种多态状态,但是明天可能有8种。这是由引擎的开发人员决定的。 我们最好保持单态,在极端情况下为多态。 单态和多态状态之间的转换非常昂贵,因为您将需要转到解释器,再次获取代码,然后再次对其进行优化。
数组
在JavaScript中,除了特定的Typed Arrays外,还有一种类型
数组。 V8引擎中有6个:
1. [1、2、3、4] // PACKED_SMI_ELEMENTS-只是一个小整数的压缩数组。 有针对他的优化。
2. [1.2,2.3,3.4,4.6] // PACKED_DOUBLE_ELEMENTS-包含双重元素的数组,也有一些优化,但速度较慢。
3. [1,2,3,4,'X'] // PACKED_ELEMENTS-一个打包的数组,其中包含对象,字符串和其他所有内容。 对他来说,也有优化。
以下三种类型是与前三种类型相同但有孔的数组:
4. [1,/ *孔* /,2,2,/ *孔* /,3,4] // HOLEY_SMI_ELEMENTS
5. [1.2,/ *孔* /,2,2,/ *孔* /,3,4] // HOLEY_DOUBLE_ELEMENTS
6. [1,/ *孔* /,'X'] // HOLEY_ELEMENTS
当阵列中出现孔洞时,优化的效率就会降低。 它们开始工作不佳,因为不可能连续遍历此数组,无法进行迭代排序。 每个后续类型的优化程度均较低
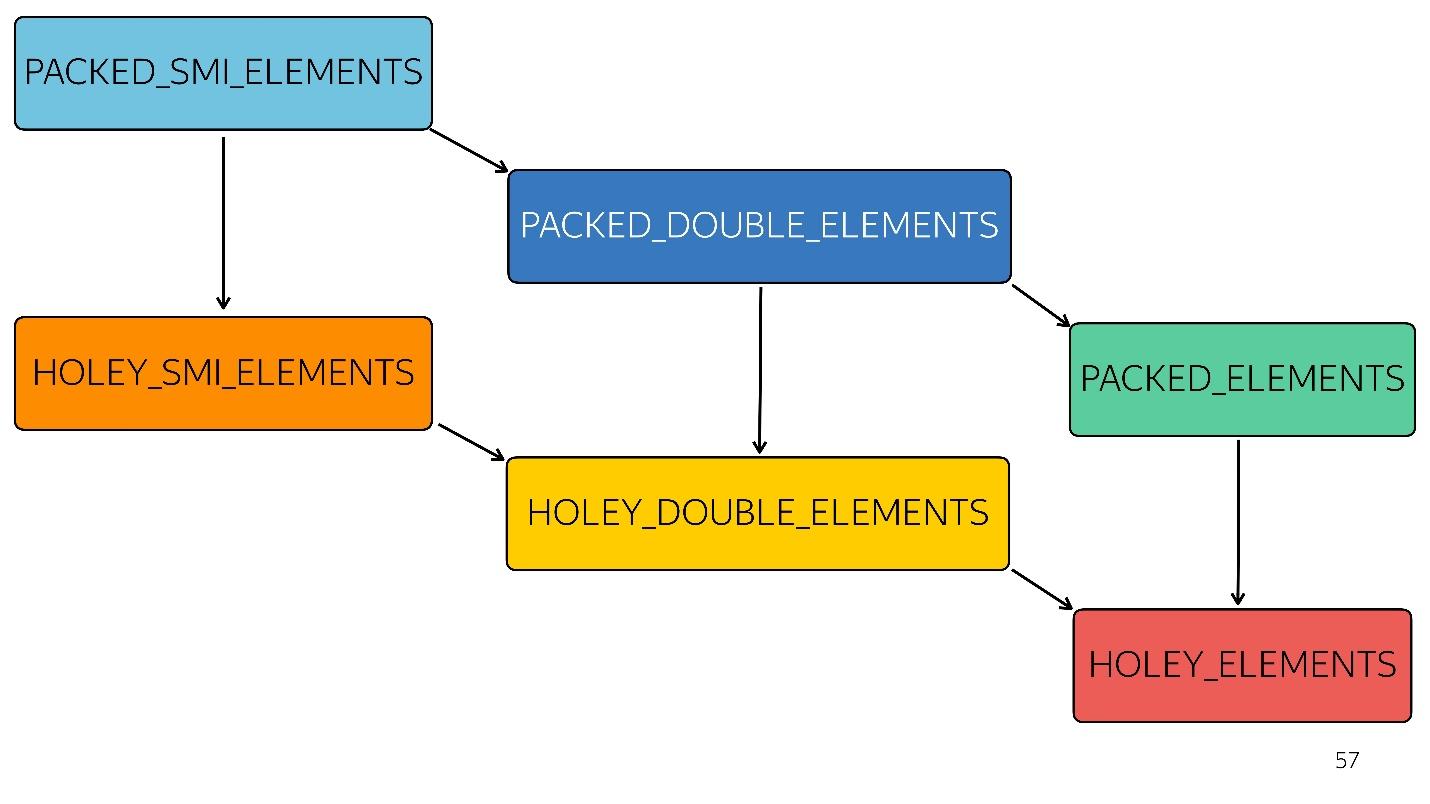
在该图中,以上所有内容均得到了优化。 也就是说,您内部的所有本机方法(映射,缩小,排序)都得到了优化。 但是对于每种类型,优化都会变得更糟。
例如,一个简单的数组[
1,2,3 ]出现在输入中(类型打包的小整数)。 我们通过向其添加一个双精度来稍微更改了该数组-进入了PACKED_DOUBLE_ELEMENTS状态。 向其添加一个对象-转到下一个状态,绿色矩形PACKED_ELEMENTS。 给它添加孔-进入HOLEY_ELEMENTS状态。 我们希望将其恢复到以前的状态,以使其再次变为“良好”状态-我们删除编写的所有内容,并保持相同的状态……有漏洞! 即,该图右下方的HOLEY_ELEMENTS。 回来这不起作用。 您的阵列只会变得更糟,反之亦然。
类数组对象
我们经常遇到类似数组的对象-这些对象看起来像数组,因为它们具有长度的迹象。 实际上,它们就像是海盗猫,也就是说,它们看起来很相似,但是在朗姆酒消费的效率上,猫会比海盗更糟。 同样,类似数组的对象就像一个数组,但是效率不高。

我们最喜欢的两个类似数组的对象是参数和document.querySelectorAII。 有这么漂亮的功能性东西。
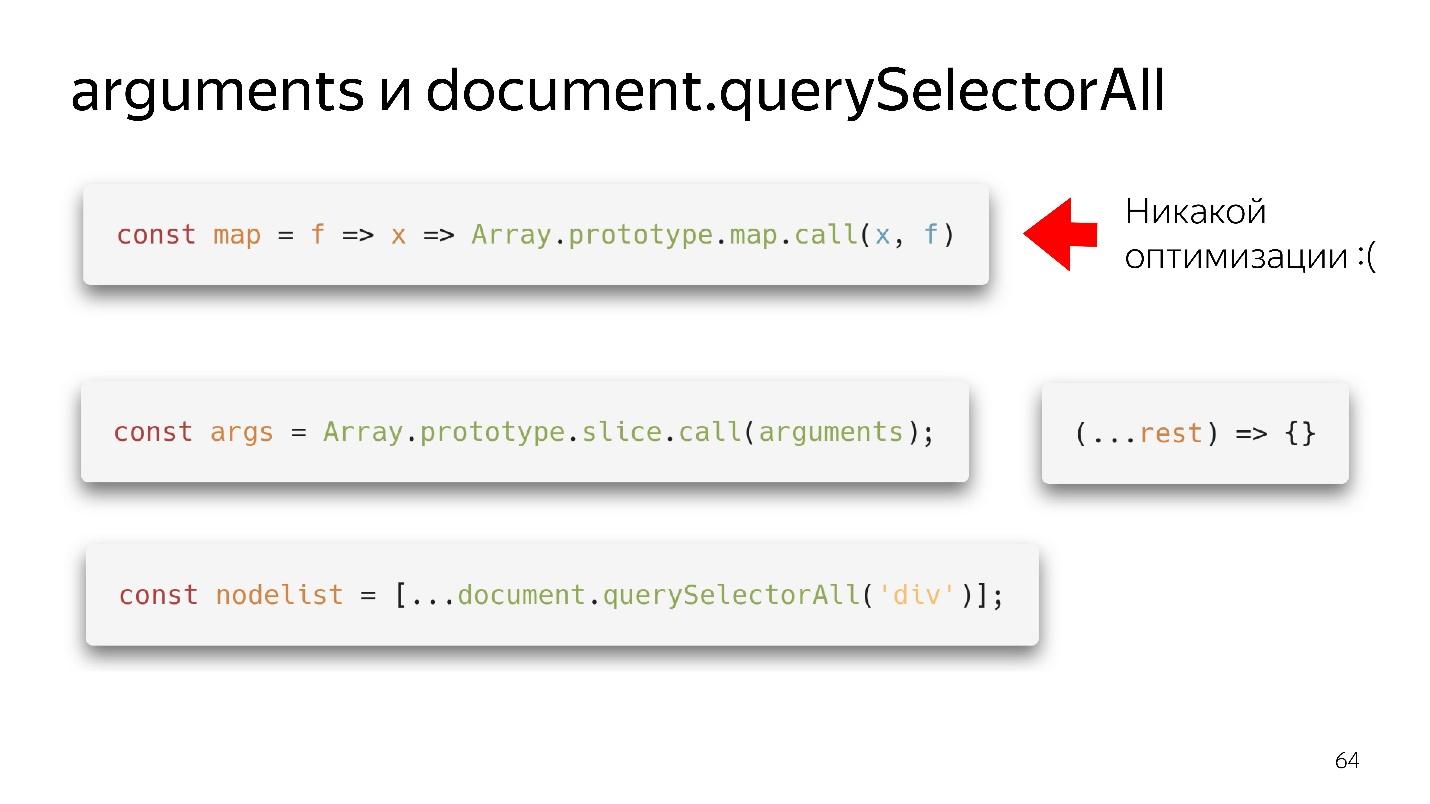
我们得到了一张地图-我们将其从原型中剔除,似乎可以使用。 但是,如果没有输入数组,就不会进行优化。 我们的引擎无法对对象进行优化。
需要做什么?
- 老式的选项-通过slice.call()变成一个实数数组。
- 现代的选择更好:写(... rest),得到一个干净的数组-而不是参数-一切都很好!
与querySelector相同-由于扩展,我们可以将其转换为完整的数组并使用所有优化。
大阵列
谜语:新数组(1000)与数组= []
哪种选择更好:立即创建一个大型数组并在一个循环中填充1000个对象,还是创建一个空数组并逐步填充?
正确答案:取决于。
有什么区别?
- 当我们以第一种方式创建数组并填充1000个元素时,我们将创建1000个孔。 该阵列将不会被优化。 但是他会很快写。
- 根据第二个变体创建一个数组,分配了一些内存,例如,我们写了60个元素,分配了更多的内存,等等。
也就是说,在第一种情况下,我们写得很快-我们工作很慢; 第二,我们写得很慢-我们工作很快。
垃圾收集器
垃圾收集器还会消耗一些时间和资源。 如果不深入研究,我将给出最常见的基础。

我们的生成模型包含了
年轻与老对象的
空间 。 创建的对象落入年轻对象的空间。 一段时间后,开始清洁。 如果无法通过根目录的链接访问该对象,则可以将其收集到垃圾中。 如果该对象仍在使用中,它将移到较旧的对象空间,该对象的清理频率较低。 但是,在某些时候,旧对象将被删除。

自动垃圾收集器就是这样工作的-它在没有对象链接的基础上清除对象。 这是两种不同的算法。
- 清除速度很快,但效果不佳 。
- 标记扫描很慢但很有效。
如果您开始在Node.js中分析内存消耗,您将得到类似的信息。

起初,它突然增长-这是Scavenge算法的工作。 然后急剧下降-这种Mark-Sweep算法在旧对象空间中收集了垃圾。 此刻,一切开始放慢一点。
您无法控制它 ,因为您不知道何时会发生。 您只能调整尺寸。
因此,管道具有浪费时间的垃圾回收阶段。
甚至更快?
让我们展望未来。 接下来做什么,如何更快?
在这条线上,块大小与花费的时间大致相关。
对于听说过字节码的人来说,想到的第一件事-立即将字节码提交给输入并解码,而不是解析它-将会更快!

问题在于字节码现在不同了。 就像我说的那样:在Safari中,在FireFox中,在Chrome中。 尽管如此,Mozilla,Bloomberg和Facebook的开发人员提出了这样的
建议 ,但这是未来。
如果编译器没有猜测,则还有另一个问题-编译,优化和重新优化。 想象一下,在输入处有一种静态类型的语言可以生成有效的代码,这意味着不再需要重新优化,因为我们已经获得了高效的代码。 这样的输入只能被编译和优化一次。 生成的代码将更加高效并且执行速度更快。
还有什么可以做的? 想象一下,这种语言具有手动内存管理功能。 然后不需要垃圾收集器。 这条线变得越来越短。

猜猜是什么样子?
Web装配体它是这样工作的:手动内存管理,静态类型
语言和快速执行。

WebAssembly是银弹吗?

不,因为它代表JavaScript。 WASM还无法执行任何操作。 他无权访问DOM API。 它在JavaScript引擎内-在同一引擎内! 它通过JavaScript完成所有操作,因此
WASM不会加快您的代码 。 它可以加快单个计算的速度,但是JavaScript和WASM之间的交换将成为瓶颈。
因此,虽然我们的语言仅是JavaScript,但黑匣子提供了一些帮助。
合计
可以区分三种类型的优化。
●
算法优化维亚切斯拉夫·埃格罗夫(Vyacheslav Egorov)发表了一篇文章“
也许您不需要Rust来加快JS的速度 ”,他曾经开发过V8,现在正在开发Dart。 简要讲述她的故事。
有一个JavaScript库不能很快运行。 有些人用Rust重写了它,编译并获得了WebAssembly,应用程序开始运行得更快。 经验丰富的JS开发人员Vyacheslav Egorov决定回答他们。 他应用了算法优化,JavaScript解决方案变得比Rust解决方案快得多。 反过来,这些人看到了这一点,进行了相同的优化,然后又赢了,但不是很多-取决于引擎:在Mozilla中他们赢了,在Chrome中他们赢了。
今天,我们没有谈论算法优化,并且前端渲染通常不谈论它们。 这是非常糟糕的,因为
算法还允许代码运行更快 。 您只需删除不需要的循环。
●
特定于语言的优化这就是我们今天谈到的:我们的语言是动态解释的。 了解数组,对象和单态性的工作原理
使您可以编写高效的代码 。 必须知道并正确编写。
●
引擎特定的优化这些是最危险的优化。 如果您的开发人员非常聪明,但不善于交际,他们做了很多这样的优化,没有告诉任何人,没有写文档,那么如果您打开代码,则不会看到JavaScript,而是看到Crankshaft Script。 也就是说,JavaScript写的是对两年前曲轴引擎的工作方式有深刻的了解。 一切正常,但现在不再需要。
因此,必须对此类优化进行记录,并通过测试证明其有效性。 必须对其进行监视。 仅在您真正放慢脚步的那一刻,您才需要去找他们-只是在没有如此深的设备知识的情况下也无法做到。 因此,唐纳德·克努斯(Donald Knuth)的著名短语似乎合乎逻辑。

无需仅仅因为您阅读了有关它们的正面评论即可尝试实施任何形式的硬性优化。
一个人应该害怕这样的优化,一定要记录下来并留下指标。 通常,总是收集指标。
指标很重要!有用的链接:Frontend Conf Moscow 4 5 . 15 , , :
- (KeepSolid) , Offline First Persistent Storage
- (TradingView) WebGL WebAssembly , , API .
- , Google Docs.