引言
不久前,我成为一个项目的参与者,该项目开发的软件产品旨在分析来自医疗组织的患者记录和有关其健康状况的数据,以创建统一的医学记录。 长期以来,该团队无法开发出一种组合患者数据的方法。 起点是对开放式EMPI (开放式企业主患者索引)解决方案的源代码的研究,这促使我们采用字符串相似度分析算法。 从那时起,开始对材料进行更深入的研究,这使得可以首先创建布局,然后创建可行的解决方案。
到目前为止,在各种各样的演示中,人们不得不听到很多有关此类产品工作逻辑的问题,从中我得出结论,对文本链接方法的回顾将引起广大读者的兴趣。
该材料是维基百科文章“ 记录链接 ”的翻译,包括版权和附加内容。
什么是文字链接?
术语“记录链接”描述了将文本记录从一个数据源附加到另一数据源的记录的过程,只要它们描述了相同的对象。 在计算机科学中,这称为“数据映射”或“对象标识问题” 。 有时会使用其他定义,例如“标识” , “绑定” , “重复检测” , “重复数据删除” , “匹配记录” , “对象标识” ,它们描述了相同的概念。 这种术语的丰富性导致信息处理和结构化方法( 记录 绑定和数据绑定)分离 。 尽管它们都通过不同的参数集来确定匹配对象的标识,但是当提及一个人的“本质”时,通常使用术语“链接文本记录”,而“数据链接”则意味着可以在数据集之间链接任何网络资源,分别使用标识符的广义概念,即URI。
为什么需要这个?
当开发用于构建自动化系统的软件产品时,该自动化系统用于与个人数据处理有关的各个领域(医疗保健,历史记录,统计数据,教育等),任务是识别来自各种来源的会计科目数据。
然而,当从大量来源收集描述时,会出现使它们的明确识别变得困难的问题。 这些问题包括:
- 错别字
- 字段排列(例如,名字);
- 缩写的使用和缩写;
- 使用不同格式的标识符(日期,文件编号等)。
- 语音失真
- 等
原始数据的质量直接影响绑定过程的结果。 由于这些问题,数据集通常被转移到处理过程中,尽管它们描述了相同的对象,但看起来这些记录看起来是不同的。 因此,一方面,评估所有传输的记录标识符的适用性,以供在识别过程中使用;另一方面,对记录本身进行归一化或标准化,以使其具有单一格式。
历史之旅
链接笔记的最初想法是Halbert L. Dunn提出的,他于1946年在《美国公共卫生杂志》上发表了题为“记录链接”的文章。
后来,在1959年,Howard B. Newcombe在《科学》杂志的一篇关于“生命记录的自动链接”的文章中,奠定了现代字符串绑定理论的概率基础,该理论由Ivan Fellegi和Alan于1969年开发和加强桑特(艾伦·桑特)。 他们的工作“记录链接理论”仍然是许多链接算法的数学基础。
算法的主要发展是在上世纪90年代。 然后,从各个领域(统计,归档,流行病学,历史等)出发,我们现在在软件产品中经常使用的算法出现了,例如Jaro-Winkler距离与Levenshtein距离的相似性(距离) ,但是,某些解决方案,例如语音Soundex算法,出现得更早了-上世纪20年代。
文字输入比较算法
区分用于比较文本记录的确定性算法和概率性算法。 确定性算法基于记录属性的完全一致。 概率算法可以计算记录属性的对应程度,并据此确定它们之间关系的可能性。
确定性算法
比较字符串的最简单方法是基于清晰的规则,即根据数据集属性的匹配数在对象之间生成链接时。 也就是说,如果两个记录的全部或某些属性相同,则它们将通过确定性算法相互对应。 确定性算法适用于比较由一组数据描述的主题,这些数据由一个共同的标识符(例如,养老金中个人账户的个人保险号-SNILS)标识,或具有几个可以信任的代表标识符(出生日期,性别等)。
将结构清晰(标准化)的数据集传输到处理过程时,可以应用确定性算法。
例如,它具有以下文本输入集:
| 不行 | 笑话 | 名 | 出生日期 | 性别 |
|---|
| A1 | 163-648-564 96 | 兹瓦涅茨基·米哈伊尔(Zhvanetsky Mikhail) | 1934年3月6日 | 中号 |
| A2 | 163-648-564 96 | 兹瓦涅茨基·米哈伊尔(Zhvanetsky Mikhail) | 1934年3月6日 | 中号 |
| A3 | 126-029-036 24 | 伊尔琴科·维克多(Ilchenko Victor) | 1937年1月2日 | 中号 |
| A4 | | 诺维科娃·克拉拉(Novikova Klara) | 12.26.1946 | ˚F |
| 不行 | 笑话 | 名 | 出生日期 | 性别 |
|---|
| B1 | 126-029-036 24 | 伊里琴科·维克多(Ilyichenko Victor) | 1937年1月2日 | 中号 |
| B2 | | 日瓦涅茨基·米哈伊尔 | 1934年3月6日 | 中号 |
| B3 | | Zerchaninova克拉拉 | 12.26.1946 | 2 |
先前曾说过,最简单的确定性算法是使用唯一标识符,该标识符应该唯一地识别一个人。 例如,我们假设所有具有相同标识符值(SNILS)的记录都描述相同的主题,否则它们是不同的主题。 在这种情况下,确定性连接将生成以下对:A1和A2,A3和B1。 B2将不与A1和A2关联,因为该标识符无关紧要,尽管其内容与指定记录一致。
这些例外导致需要用新规则补充确定性算法。 例如,如果没有唯一标识符,则可以使用其他属性,例如姓名,出生日期和性别。 在给定的示例中,该附加规则将不再给出B2和A1 / A2的对应关系,因为现在名称有所不同-姓氏存在语音上的失真。
可以使用语音分析方法解决此问题,但是如果您更改姓氏(例如,在结婚的情况下),则需要诉诸新规则,例如比较出生日期或允许记录的可用属性有所不同(例如性别)。
该示例清楚地表明,确定性算法对数据质量非常敏感,并且记录属性数量的增加可能导致所应用规则的数量大量增加,这使确定性算法的使用大大复杂化。
此外,如果存在与输入信息进行比较的经过验证的数据集(主参考),则可以使用确定性算法。 但是,在不断补充主目录本身的情况下,可能需要对现有关系进行彻底检查,这使得确定性算法的使用非常耗时或根本不可能。
概率算法
链接字符串记录的概率算法所使用的属性集比确定性属性集的属性集要广,对于每个属性,将计算权重系数,该权重系数确定在最终估计估计记录的符合性时影响连接的能力。 累积总重量高于某个阈值的记录被视为相关,累积总重量低于某个阈值的记录被视为不相关。 从范围中间获得总权重值的对被视为链接的候选对象,可以稍后考虑(例如,由操作员),他们将决定其并集(链接)或不绑定它们。 因此,与确定性算法不同(确定性算法是大量的清晰(已编程)规则的集合),概率算法可以通过选择阈值来适应数据质量,而无需重新编程。
因此,概率算法将权重系数( u和m )分配给记录的属性,借助这些系数,可以确定它们之间的对应关系或不一致性。
系数u确定两个独立记录的标识符随机重合的概率。 例如,出生月份的u概率(当有十二个均匀分布的值时)为1 \ 12 = 0.083。 值不均匀分布的标识符对于不同值(有时包括缺失值)的概率不同。
系数m是比较对中的标识符彼此对应或非常相似的概率-例如,在Jaro-Winkler算法的概率很高或在Levenshtein算法的概率很低的情况下。 如果记录的属性完全一致,则该值应为1.0,但是鉴于这种可能性较低,因此应该对系数进行不同的评估。 可以在对数据集进行初步分析的基础上进行此评估,例如,通过手动“学习”用于识别大量匹配和不匹配对的概率算法,或通过迭代启动算法以选择最合适的m系数值。
如果将m概率定义为0.95,则出生月份的依从/不依从系数将如下所示:
| 公制 | 分享链接 | 分享价值,而非参考 | 频次 | 机重 |
|---|
| 合规 | m = 0.95 | u = 0.083 | m \ u = 11.4 | ln(米/ u)/ ln(2)≈3.51 |
| 不匹配 | 1米= 0.05 | 1-u = 0.917 | (1-m)/(1-u)≈0.0545 | ln((1-m)/(1-u))/ ln(2)≈-4.20 |
为了确定其他记录标识符的合规性和不合规系数,应进行类似的计算。 然后,将一条记录的每个标识符与另一条记录的对应标识符进行比较,以确定该对的总权重:将对应对的权重以累加的总和添加到总结果中,而从总结果中减去不合适的对的权重。 将结果量与识别出的阈值进行比较,以确定是否自动配对分析对或将其转移给操作员进行考虑。
封锁
确定合规性/不合规性阈值是在获得可接受的灵敏度(算法检测到的相关记录的份额)与结果的预测值(即准确性,作为由算法链接的真实匹配记录的度量)之间的平衡。 由于定义阈值可能是一项非常困难的任务,尤其是对于大型数据集,因此通常使用一种称为阻塞的方法来提高计算效率。 试图在记录之间进行比较,以显示基本属性值之间的显着差异( 区别 )。 由于灵敏度降低,这导致精度提高。
例如,基于姓氏的语音编码进行锁定会减少所需的比较总数,并增加记录之间的关系正确的可能性,因为这两个属性已经一致,但可能会跳过与姓氏相同的人相关的记录发生变化(例如,由于结婚)。 按出生月份分组是一个更稳定的指标,只有在源数据中存在错误时才可以进行调整,但会在正预测值和敏感性下降方面带来更适度的收益,因为它创建了十二个不同的超大型数据集组,并且不会导致速度提高计算。
因此,最有效的文本输入链接系统通常使用几种阻塞通行证以各种方式对数据进行分组,以准备应稍后提交进行分析的记录组。
机器学习
最近,已使用各种机器学习方法来链接文本记录。 在2011年的一篇论文中,兰德尔·威尔逊(Randall Wilson)表明,经典的文本记录概率链接算法等效于朴素的贝叶斯算法,并且由于分类特征是独立的,因此遭受了相同的问题。 为了提高分析的准确性,作者建议使用一种称为单层感知器的神经网络的基本模型,该模型的使用可以大大超过使用传统概率算法获得的结果。
语音编码
语音算法会将两个发音相似的单词与相同的代码进行匹配,从而使您可以根据它们的语音相似性来比较这些单词。
尽管最近对某些算法进行了修改以与其他语言一起使用,或者最初将其创建为国家解决方案(例如,Caverphone),但大多数语音算法都旨在分析英语单词。
声音
比较两个字符串的声音的经典算法是Soundex(声音索引的缩写)。 它为具有相似英语发音的字符串设置相同的代码。 Soundex最初于1930年代被美国国家档案局使用,以回顾性分析1890年至1920年的人口普查。
算法的作者是Robert C. Russel和Margaret King Odell,他们在上个世纪20年代获得了专利。 该算法本身在上世纪下半叶开始流行,当时它成为美国流行科学期刊上多篇文章的主题,并发表在D. Knut的专着《编程的艺术》中。
戴奇-莫科托夫Soundex
由于Soundex仅适用于英语,因此一些研究人员已尝试对其进行修改。 1985年,加里·莫科托夫(Gary Mokotoff)和兰迪·达奇(Randy Daitch)提出了Soundex算法的一种变体,旨在比较东欧(包括俄罗斯)的姓氏质量。
在90年代,劳伦斯·菲利普(Lawrence Philips)提出了Soundex算法的替代版本,称为Metaphone。 新算法使用了更大的英语发音规则集,因此更加准确。 后来,基于拉丁字母的转录,将算法修改为可用于其他语言。
2002年,《程序员》杂志第8期发表了彼得·坎科夫斯基(Peter Kankowski)的文章,讲述了他对英语版本的Metaphone算法的改编。 此版本的算法根据俄语的规则和规范转换源词,同时考虑到未加重的元音的语音和可能的辅音“合并”。
而不是结论
作为多次迭代的结果,在引言中提到的软件产品开发项目的项目团队开发了一种体系结构解决方案,其方案如图所示。
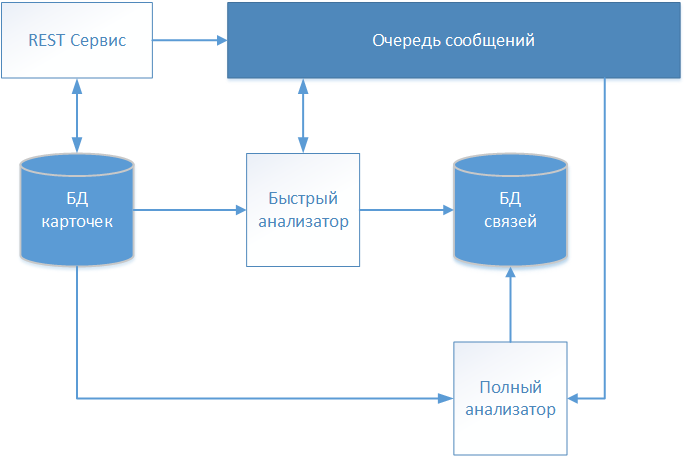
通过REST服务接受患者的文字描述,并将其存储在存储库(卡数据库)中,而无需进行任何更改。 由于我们的系统可以处理医学数据,因此选择了FHIR (快速医疗保健互操作性资源)标准进行信息交换。 有关接收到的患者卡的信息将传输到消息队列中,以进行进一步的分析和建立通信的决策。
要处理的第一张卡是使用确定性算法运行的“快速分析器” 。 如果确定性算法的所有规则均已解决,则它将在单独的存储(链接数据库)中创建包含已处理卡链接的记录。 该记录除了包含被分析卡的标识符之外,还包含通信的建立日期和标识全局标识的患者的条件标识符。 另外的卡进一步被称为指定的全局标识符,从而形成描述特定个人的阵列。
如果确定性算法未找到匹配项,则卡信息通过消息队列传输到“全分析器”。
( ). . :

1. -
, . 2.
2.
- , ().
3.
, , ( ) , .
4.
, . . , , . , , , .