在俄罗斯几乎没有人拥有Glaster,任何经历都很有趣。 从
上一期的讨论来看,我们拥有大型和工业产品,并且需求旺盛。 我谈到了将备份从企业存储迁移到Glusterfs的经验。
这还不够硬。 我们没有停下来,而是决定收集更严重的东西。 因此,在这里我们将讨论擦除编码,分片,重新平衡及其限制,压力测试等问题。

- 更多体积/亚体积理论
- 热备用
- /愈/ he愈/平衡
- 重新启动3个节点后的结论(从不执行此操作)
- 从不同的虚拟机以不同的速度进行记录以及分片开/关如何影响子卷负载?
- 光盘离开后重新平衡
- 快速重新平衡
你想要什么
任务很简单:收集便宜但可靠的商店。 尽可能便宜,可靠-以便将我们自己的文件存储在其上进行出售不会感到恐惧。 再见 然后,经过长时间测试并备份到另一个存储系统(也包括客户端存储系统)。
应用程序(顺序IO) :
-备份
-测试基础架构
-测试大量媒体文件的存储。
我们在这里。
-战斗文件和严格的测试基础架构
-存储重要数据。
与上次一样,主要要求是Glaster实例之间的网络速度。 首先10G就可以了。
理论:什么是分散体积?
分散卷基于擦除编码(EC)技术,该技术可有效防止磁盘或服务器故障。 就像RAID 5或RAID 6,但不是。 它以一种方式存储每个砖块的文件的编码片段,使得仅需要存储在其余Briks中的片段的子集即可恢复文件。 在创建卷期间,管理员可以配置不丢失数据访问权而可能不可用的块数。
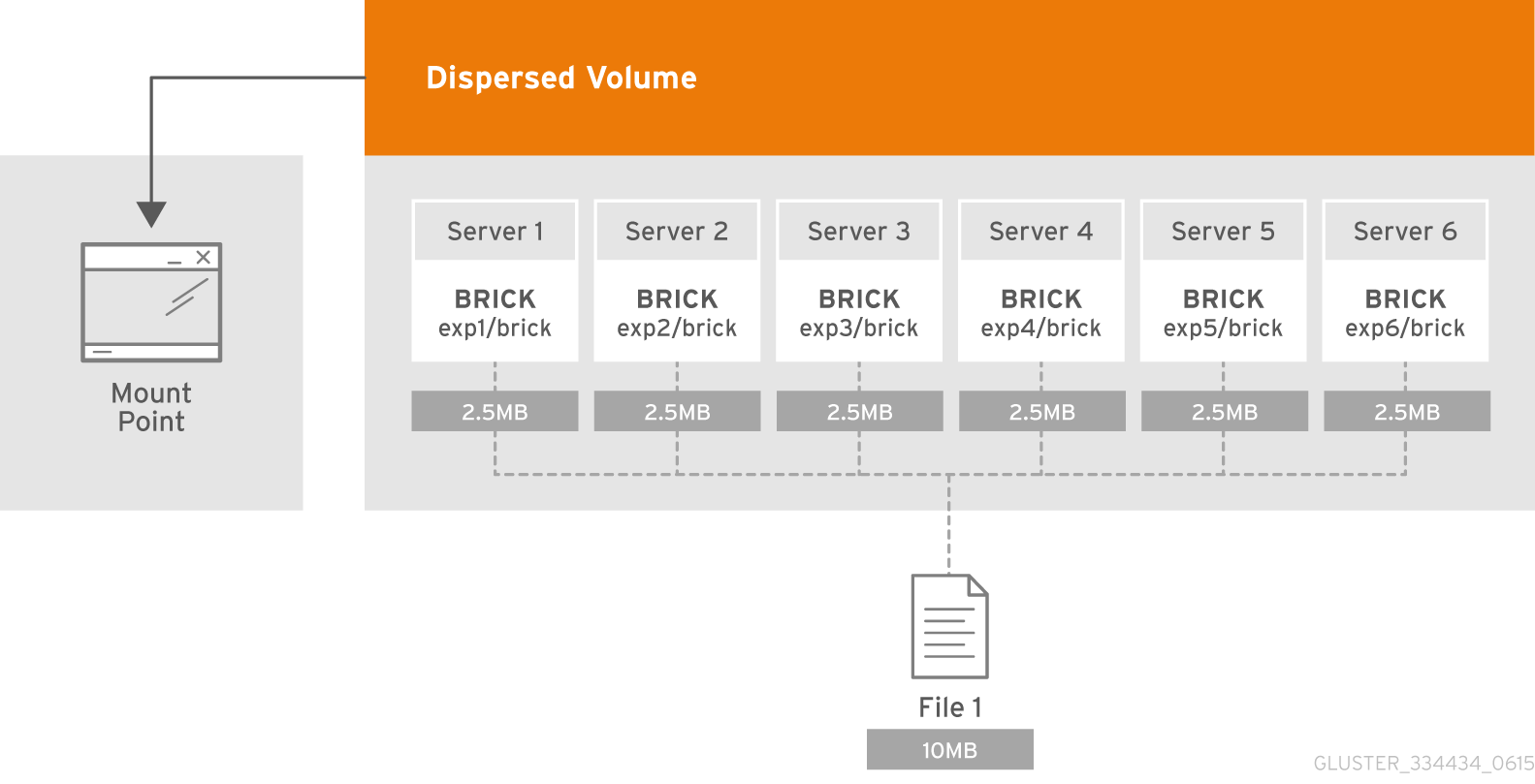
什么是子卷?
GlusterFS术语中的子卷的实质与分布式卷一起体现。 在分布式分散擦除中,编码仅在超低音扬声器的框架中起作用。 并且在这种情况下,例如,使用分布式复制的数据将在低音炮的框架内进行复制。
它们每个都分布在不同的服务器上,这使它们可以自由丢失或同步输出。 在图中,服务器(物理)标记为绿色,子狼点缀。 它们每个都以磁盘(卷)的形式呈现给应用程序服务器:

可以确定,在6个节点上的分布式分散4 + 2配置看起来非常可靠,我们可以在每个低音炮中丢失任何2台服务器或2个磁盘,同时继续访问数据。
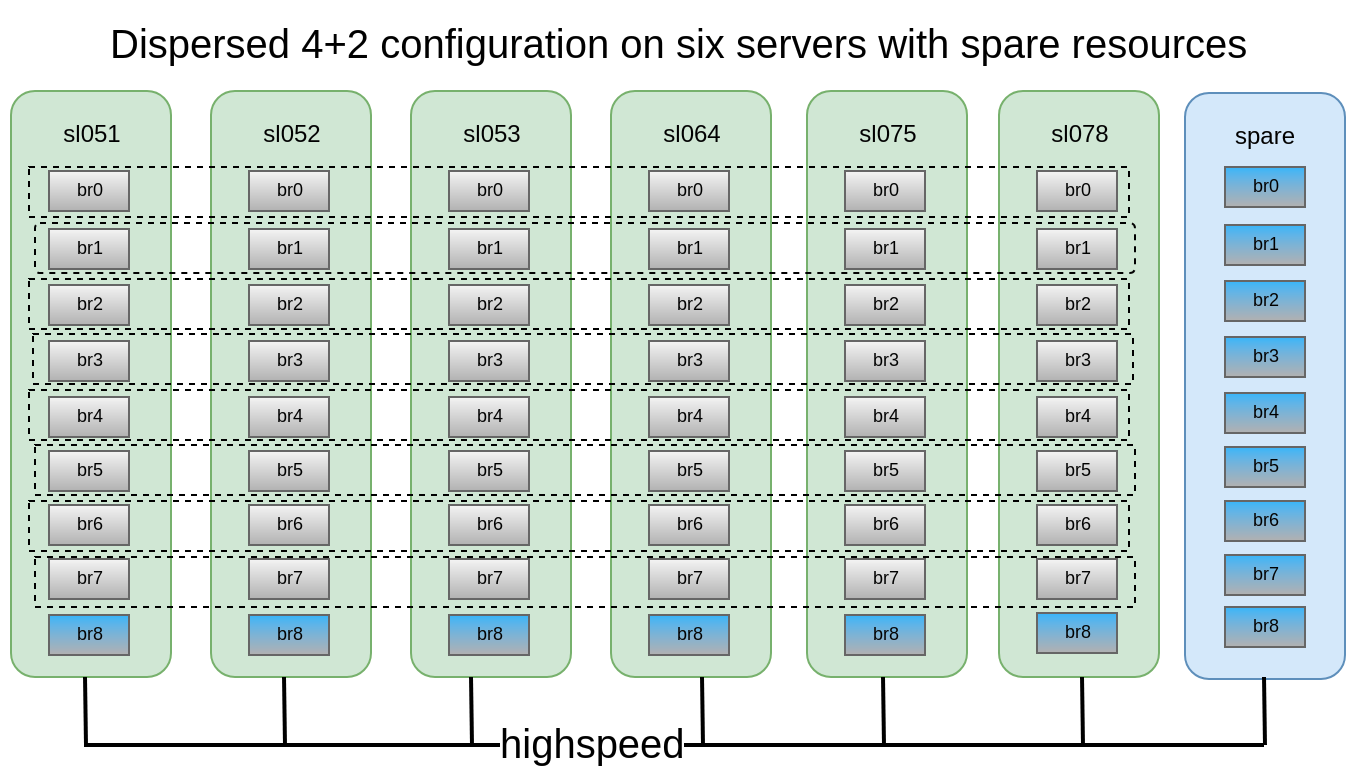
我们可以使用6个旧的DELL PowerEdge R510,它具有12个磁盘插槽和48x2TB 3.5 SATA驱动器。 原则上,如果市场上有一台服务器具有12个磁盘插槽,并且具有多达12 TB的驱动器,那么我们最多可以收集576 TB的可用空间的存储。 但是请不要忘记,即使最大的硬盘尺寸逐年增加,它们的性能仍然保持不变,而重建10-12TB的磁盘可能需要一周的时间。
 批量创建:
批量创建:有关如何准备积木的详细说明,请阅读我
以前的文章gluster volume create freezer disperse-data 4 redundancy 2 transport tcp \ $(for i in {0..7} ; do echo {sl051s,sl052s,sl053s,sl064s,sl075s,sl078s}:/export/brick$i/freezer ; done)
我们创建了,但是我们并不急于启动和安装,因为我们仍然必须应用几个重要的参数。
我们得到了: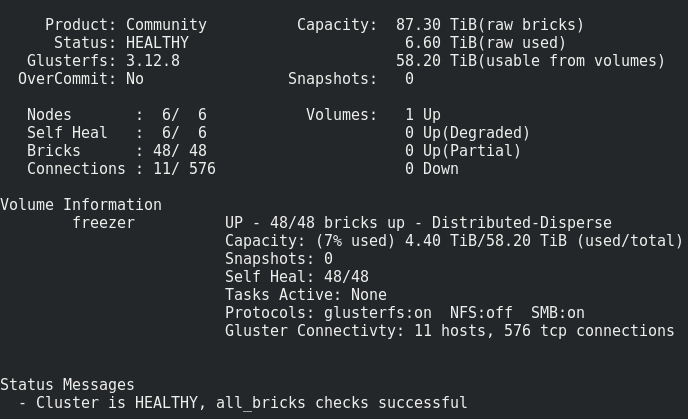
一切看起来都很正常,但有一个警告。
它包括在砖头上记录这样的体积:文件被逐个放置在半狼中,并且没有均匀地分布在它们之间,因此,我们迟早会遇到文件的大小,而不是整个卷的大小。 我们可以在此存储库中放入的最大文件大小是低音炮的可用大小减去其上已占用的空间。 就我而言,小于8 Tb。
怎么办 怎么样通过分片或条带化卷可以解决此问题,但是,如实践所示,条带化的效果非常差。
因此,我们将尝试分片。
分片的详细信息 在这里 。
简而言之,分片是什么 :
放入一个卷中的每个文件将分为多个部分(碎片),这些部分相对均匀地排列在子狼中。 分片的大小由管理员指定,标准值为4 MB。
创建卷之后但在开始之前打开分片 :
gluster volume set freezer features.shard on
我们设置分片的大小(这是最佳选择吗?来自oVirt的Dudes建议使用512MB) :
gluster volume set freezer features.shard-block-size 512MB
根据经验,事实证明,使用分散体积4 + 2的砖中碎片的实际大小等于碎片块大小/ 4,在我们的情况下为512M / 4 = 128M。
根据擦除编码逻辑的每个碎片将根据子世界框架中的砖块分解为:4 * 128M + 2 * 128M
绘制使用这种配置的gluster幸存的失败案例:在这种配置下,我们可以承受同一子卷中2个节点或2个任何磁盘的故障。
为了进行测试,我们决定将结果存储放到我们的云下,然后从虚拟机运行。
我们从15个VM中打开顺序记录,然后执行以下操作。
重新启动第一个节点:17:09
它看起来不重要(通过ping.timeout参数〜5秒不可用)。
17:19
全面he愈。
修复条目的数量仅在增加,这可能是由于对集群的高级别写入。
17:32
决定关闭来自VM的记录。
治愈次数开始下降。
17:50
治愈了。
重新引导2个节点:观察到与第一个节点相同的结果。重新启动3个节点:挂载点发出传输端点未连接,VM收到ioerror。
打开节点后,Glaster恢复了自身,没有我们这边的干扰,治疗过程开始了。但是15个虚拟机中有4个无法上升。 我在管理程序上看到错误:
2018.04.27 13:21:32.719 ( volumes.py:0029): I: Attaching volume vol-BA3A1BE1 (/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1) with attach type generic... 2018.04.27 13:21:32.721 ( qmp.py:0166): D: Querying QEMU: __com.redhat_drive_add({'file': u'/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1', 'iops_rd': 400, 'media': 'disk', 'format': 'qcow2', 'cache': 'none', 'detect-zeroes': 'unmap', 'id': 'qdev_1k7EzY85TIWm6-gTBorE3Q', 'iops_wr': 400, 'discard': 'unmap'})... 2018.04.27 13:21:32.784 ( instance.py:0298): E: Failed to attach volume vol-BA3A1BE1 to the instance: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized Traceback (most recent call last): File "/usr/lib64/python2.7/site-packages/ic/instance.py", line 292, in emulation_started c2.qemu.volumes.attach(controller.qemu(), device) File "/usr/lib64/python2.7/site-packages/c2/qemu/volumes.py", line 36, in attach c2.qemu.query(qemu, drive_meth, drive_args) File "/usr/lib64/python2.7/site-packages/c2/qemu/_init_.py", line 247, in query return c2.qemu.qmp.query(qemu.pending_messages, qemu.qmp_socket, command, args, suppress_logging) File "/usr/lib64/python2.7/site-packages/c2/qemu/qmp.py", line 194, in query message["error"].get("desc", "Unknown error") QmpError: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized qemu-img: Could not open '/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1': Could not read image for determining its format: Input/output error
关闭分片后,硬付清3个节点 Transport endpoint is not connected (107) /GLU/volumes/e0/e0bf9a42-8915-48f7-b509-2f6dd3f17549: ERROR: cannot read (Input/output error)
我们还会丢失数据,无法恢复。
轻轻地分片偿还3个节点,会不会有数据损坏?有,但是更少(巧合?),我丢失了30个驱动器中的3个。
结论:- 这些文件的修复无限期停止,重新平衡无济于事。 我们得出的结论是,当第三个节点关闭时,正在进行活动记录的文件将永远丢失。
- 在生产环境中,切勿在4 + 2配置中重新加载超过2个节点!
- 如果您确实要重新引导3个以上的节点,如何不丢失数据? P在安装点和/或停止音量时停止录制。
- 节点或积木应尽快更换。 为此,非常需要在每个节点中使用1-2 a的热备用砖,以便快速更换。 还有一个备用节点,带有备用节点,以防发生节点转储。
测试驱动器更换案例也非常重要
船首驶离(圆盘):
17:20我们敲开一块砖头:
/dev/sdh 1.9T 598G 1.3T 33% /export/brick6
17:22 gluster volume replace-brick freezer sl051s:/export/brick_spare_1/freezer sl051s:/export/brick2/freezer commit force
您可以在更换积木时看到这样的缩水(来自1个来源的记录):

更换过程很长,每个群集的记录级别很小,默认设置为1 TB,大约需要一天的时间才能恢复。
可调治疗参数: gluster volume set cluster.background-self-heal-count 20
选项:disperse.background-heals
默认值:8
说明:此选项可用于控制并行愈合的次数
选项:disperse.heal-wait-qlength
默认值:128
说明:此选项可用于控制可以等待的治疗次数
选项:disperse.shd-max-threads
默认值:1
说明:每个本地砖可以执行SHD并行修复的最大数量。 这样可以大大减少恢复时间,但是如果您没有支持该功能的存储硬件,也可以压垮您的积木。
选项:disperse.shd-wait-qlength
默认值:1024
描述:此选项可用于控制每个子卷可以SHD等待的治愈次数
选项:分散.cpu扩展名
默认值:自动
说明:强制使用cpu扩展名来加速galois场计算。
选项:分散。自愈窗口大小
默认值:1
说明:每个文件可同时应用自我修复过程的最大块数(128KB)。站着:
disperse.shd-max-threads: 6 disperse.self-heal-window-size: 4 cluster.self-heal-readdir-size: 2KB cluster.data-self-heal-algorithm: diff cluster.self-heal-window-size: 2 cluster.heal-timeout: 500 cluster.background-self-heal-count: 20 cluster.disperse-self-heal-daemon: enable disperse.background-heals: 18
使用新参数,可在8小时内完成1 TB数据的处理(快3倍!)
令人不快的时刻是结果比以前更大了原为: Filesystem Size Used Avail Use% Mounted on /dev/sdd 1.9T 645G 1.2T 35% /export/brick2
成为: Filesystem Size Used Avail Use% Mounted on /dev/sdj 1.9T 1019G 843G 55% /export/hot_spare_brick_0
有必要了解。 可能事情是使薄磁盘膨胀。 随后更换增加的砖块,尺寸保持不变。
重新平衡:在扩展(或不迁移数据)卷(分别使用add-brick和remove-brick命令)之后,您需要在服务器之间重新平衡数据。 在非复制卷中,所有块均应准备好以执行替换块操作(启动选项)。 在复制的卷中,副本中的至少一块砖应该向上。调整再平衡:选项:cluster.rebal-throttle
默认值:正常
说明:设置重新平衡操作期间节点上允许的最大并行文件迁移数。 默认值为正常,最多允许[[$(处理单位)-4)/ 2),2]个文件到b
一次迁移。 惰性将一次仅允许迁移一个文件,而积极的将允许最多[[$(处理单位)-4)/ 2),4]选项:cluster.lock-migration
默认值:关闭
说明:如果启用此功能,将在重新平衡期间迁移与文件关联的posix锁选项:cluster.weighted-rebalance
默认值:开
说明:启用后,文件将以与它们的大小成正比的概率分配给砖块。 否则,所有积木将具有相同的概率(旧版行为)。比较编写,然后读取相同的参数(性能测试的更详细结果-在PM中): fio --fallocate=keep --ioengine=libaio --direct=1 --buffered=0 --iodepth=1 --bs=64k --name=test --rw=write/read --filename=/dev/vdb --runtime=6000


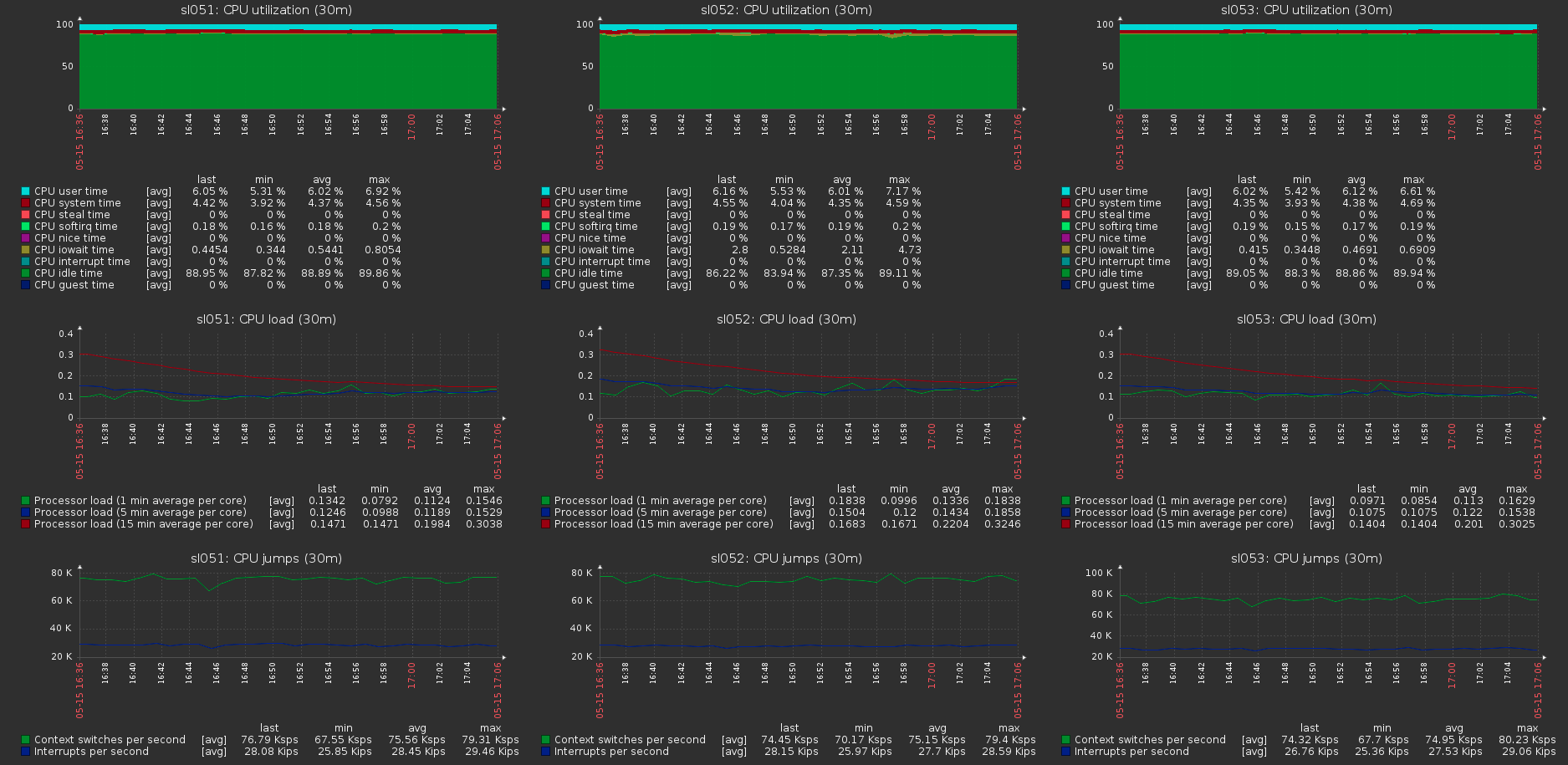
 如果有意思,请将rsync速度与到达Glaster节点的流量进行比较:
如果有意思,请将rsync速度与到达Glaster节点的流量进行比较: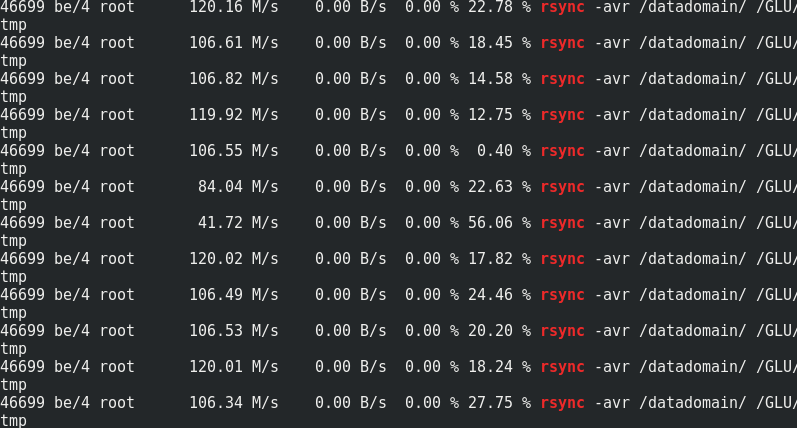
 可以看出,大约170 MB / s /流量到110 MB / s /有效负载。 事实证明,这是额外流量的33%,是擦除编码冗余的1/3。在有负载和没有负载的情况下,服务器端的内存消耗不会改变:
可以看出,大约170 MB / s /流量到110 MB / s /有效负载。 事实证明,这是额外流量的33%,是擦除编码冗余的1/3。在有负载和没有负载的情况下,服务器端的内存消耗不会改变: 群集主机上的负载具有最大的卷负载:
群集主机上的负载具有最大的卷负载: