
2014年,我加入了Schibsted Media Group的小型团队,成为该公司的第六位数据科学专家。 从那时起,我在一个拥有40多名此类人员的组织中从事数据科学领域的许多工作。 在这篇文章中,我将谈论我在过去四年中学到的一些东西,首先是作为专家,然后是数据科学经理。
这篇文章以罗伯特·张(Robert Chang)及其出色的文章“ 在Twitter中进行数据科学 ”为例,当我在2015年首次阅读该文章时,我发现它非常有价值。 我自己的贡献是与世界各地的数据科学专家和管理人员分享同样有用的想法。
我将帖子分为两部分:
- 第一部分:现实生活中的数据科学
- 第二部分:管理数据科学团队
在第一部分中,我重点介绍了数据科学专家的实际工作,而第二部分讨论了如何尽可能高效地管理数据科学团队。 我要说的是,这两个部分对于专家和管理人员都非常重要。
我不会花很多时间描述谁和谁是数据科学专家,以及谁不是-整个Internet上都有关于该主题的足够文章。
简要介绍Schibsted:全球20多个国家/地区的媒体和市场。 我主要从事市场业务,每天有数百万人在这里买卖商品。 如果您想看看Schibsted的一些现实世界中数据科学工作的例子,这里有一些选择:
考虑到这一点,让我们开始吧!
第一部分:现实生活中的数据科学
在一家雄心勃勃的新公司中以一名数据科学专家的身份开始确实很棒,但也似乎令人恐惧。 我周围的人期望什么? 我的同事将具有什么技能水平? 如何为公司服务? 在一个大肆宣传的位置,有时候很难不觉得自己是冒名顶替者 。
对简单性的恐惧常常促使数据科学专业人士将重点主要放在复杂性上。 这使我们得出第一个结论。
1.1。 困难增加价值,从简单开始
他们聘请了一位数据科学专家,所以这个问题一定一定很复杂,对吧?

这种假设通常会误导您作为数据科学专家。 首先,您通常会使用相当简单的方法解决您在业务中遇到的问题。 其次,重要的是要记住,复杂性会增加价值。 复杂的模型可能需要更多的工作来实施,更高的错误风险以及向客户解释的更多困难。 因此,您应该始终首先寻找最简单的方法。
但是,如何理解最简单的方法是否足够?
1.2。 始终有基本模型
如果不与基本模型进行比较,那么对模型质量的估计很可能没有意义。 在大多数情况下,仅凭随机选择与准确性进行比较是远远不够的。

在某个时候,我们建立了一个模型来预测用户将返回我们站点的可能性-返回模型。 在我们的模型中使用了大约15个基于用户行为的属性,我们实现了约0.8 ROC-AUC的精度。 与随机预测的准确性(0.5)相比,我们对该结果感到非常满意。 但是,当我们从模型中删除除以下两个最重要的标志以外的所有内容时:最近(上次访问的天数)和频率(过去访问的天数),我们发现对这两个变量进行简单的逻辑回归可以得出78%的ROC-AUC ! 换句话说,通过丢弃超过85%的属性,我们可以实现97%以上的性能。
我已经看过很多次了,数据科学专家如何展示复杂模型下的离线实验结果,而无需任何简单的基础模型进行比较。 看到这一点时,您应该总是问:我们可以使用简单得多的模型来达到相同的结果吗?
1.3。 使用您拥有的数据
我曾经与一位数据工程师和另一位数据科学专家共进午餐。 当他谈论“只要他拥有X,Y或Z的数据”时,他可以做的所有令人惊奇的事情时,后者的眼睛就闪闪发光。 在对话过程中的某个时刻,工程师笑了:“您,数据科学专家,总是谈论您可以使用您没有的数据做什么。 如何处理您拥有的数据?”

听起来很粗鲁,但是工程师表达了一个重要的道理。 您将永远不会拥有完美的数据集,并且将始终有可以使用的数据。 在大多数情况下,您可以利用自己拥有的东西做一些事情。
1.4负责数据
如上所述,数据质量和完整性几乎总是一个问题。 但是,您无需坐下来等待某人向您展示银盘上的数据,而是需要对所需的数据说话并承担责任。

我不是在从数据管理模型的角度谈论正式所有权。 我在谈论扩大我的角色,并在可能的情况下帮助获得所需的数据。
这可能意味着参与数据收集方案和格式的创建。 这可能意味着查看在Web应用程序界面中运行的Javascript代码,以确保在适当的时候触发事件。 否则可能意味着无需等待数据工程师为您做所有事情就可以建立数据管道。
1.5。 忘记数据
显然,这与我上面所说的一切相矛盾,但是重要的是不要过多地关注您所拥有的数据。

当出现新问题时,您应该首先尝试忘记现有数据。 为什么这样 是的,因为您现有的数据可能会限制决策的空间,并且这会使您无法找到最佳方法。 您将被困在局部最优中,您将在其中尝试将解决方案拉到可用数据集上的任何问题上(用于学习之外)。 结果,您将永远不会有新的数据集。
1.6。 深入了解因果关系
我们都知道,关联并不意味着因果关系。 问题在于,许多数据科学专家都止于此,并且害怕将原因与影响联系起来。

为什么这是一个问题? 因为产品经理,营销团队,您的CEO或您与之共事的人根本不需要担心这种关联。 他们关心因果关系。
产品经理希望确保当他决定发布此新功能时,将触发10%的产品参与。 市场营销团队想知道,将信件的数量从每周2个增加到4个不会导致人们取消订阅新闻通讯。 首席执行官想知道,对更好的定位进行投资将导致广告收入的增长。
好吧,有没有折衷的解决方案? 原来有两个。
最著名的在线实验。 实际上,您运行随机试验,其中包括最受欢迎的A / B测试。 这个想法很简单:由于我们意外地选择了目标群体和对照组,因此,如果我们发现两组之间在统计学上有显着差异,那么我们使用的“治疗方法”就可以认为是原因。 无需进行哲学推理,实际上这是一个合理的假设。
因果关系搜索的一种鲜为人知的方法是因果模型。 这里的想法是,您对世界的因果结构进行假设,然后使用观察性数据(非实验性)来检查这些假设是否与数据一致,或者评估各种因果关系的强度。 亚当·凯勒赫(Adam Kelleher)写了很多文章“ 因果数据科学 ”,我建议阅读。 此外,因果关系的圣经是朱迪亚·珀尔(Judea Pearl)撰写的《 因果关系》 。
以我的经验,大多数数据科学专家在创建机器学习模型及其离线评估方面都有丰富的经验。 很少有在线评估和实验经验的人。 解释很简单:您可以从Kaggle下载数据集,训练模型并在几分钟内离线评估它。 另一方面,要在线评估此模型,您需要访问现实世界。 即使您在拥有数百万用户的Internet公司中工作,您也常常必须克服许多障碍才能向用户展示您的机器学习模型。
现在,虽然很少有数据科学专家具有丰富的在线评估经验,但很少有因果建模经验。 我认为有很多充分的理由。 原因之一是大多数关于因果关系的书都是理论上的,其中很少有关于如何在现实世界中启动因果关系建模的实用指南。 我预测,在未来几年中,我们将看到因果建模的更多实用指南。
深入了解因果关系将使您可以向客户提供实用的建议,同时也可以确保您作为数据科学专家的诚信。
第二部分:管理数据科学团队
与其他许多公司一样,Schibsted也有两条职业道路:独立工作者和领导者。 在数据科学领域,第一个目标读者是那些确实想增加其在数据科学领域的知识并通过实际工作和技术领导力为公司做出贡献的人。 领导力之路适合那些对人的发展和团队管理充满热情的人。
我完全不确定哪条路适合我,但最终我决定尝试领导者的路。 当我意识到这对我来说确实是正确的方法时,并没有花费太多时间,但是,当然,我遇到了很多问题(而且我仍然会这样做!)。
您将面临的第一个挑战是,世界上很少有其他数据科学经理。 如果您认为经验丰富的数据科学专家很少,那么经验丰富的数据科学经理的人数就会减少很多倍。 因此,您或多或少地留给了自己的设备。
但是,管理数据科学团队与管理其他类型的团队是如此不同吗? 是的,没有。
如果您以前从未管理过团队,则可能会找到管理方面的经典阅读材料,例如安德鲁·格罗夫(Andrew Grove)的“ 高产出管理” ( High Output Management) 。 此外,主动寻求高级管理人员(来自其他学科)的建议也至关重要。
但是,数据科学团队有几个关键差异,因此现在我们将重点讨论结论,尤其是与数据科学团队相关的结论。
2.1。 数据科学团队并不是真正的团队
当大多数人想到团队时,他们会想到这样的事情:

巴塞罗那足球俱乐部这样的足球队有哪些特点? 至少三件事:
- 共同目标
- 团队中的不同角色,每个角色都有不同的职责
- 独立实现目标
如果您要管理一个仅由数据科学专家组成的团队,则很可能无法满足所有这些特征。 相反,您的团队将拥有:
- 不断变化的目标
- 专家,他们擅长于同一件事:数据科学
- 您可以与之合作的其他团队最终影响用户和收入
对于数据科学专家团队而言,比足球队更合适的比喻是:
对Mulder和Scully服务的需求随时间而变化。 需要他们的经验时,他们会被吸引。 如果没有与FBI以外的人交谈,他们将永远无法解决问题。
为什么这种区别很重要?
因为如果您有一个数据科学专家团队,并且将他们作为具有共同目标,各种角色和完全自治的“经典”团队进行管理,那么您很快就会感到沮丧。
我已经看到数据科学团队像任何其他产品或开发团队一样进行管理,这不可避免的结果是数据科学专家开始做任何事情,但数据科学除外。 相反,他们最终会开发,分解或管理产品。
因此,数据科学专家是不同的。 但是,如何保证数据科学不会出现在象牙塔中呢?
2.2。 将数据科学专业人员嵌入其他团队
当您将数据科学专家与产品经理,程序员,界面研究人员,市场营销人员等并肩作战时,魔术就会发生。
简而言之,您要最大化的目标功能如下:团队中的数据科学专家与其他团队中的人之间富有成果的互动。
我喜欢使用广泛的渠道概念来考虑它。 让我们通过与数据科学专家配对的产品经理来说明这一点。
最糟糕的是,它们之间没有通道时:

这意味着DS和PM之间没有通信。 换句话说,DS不会知道PM面临的任何产品问题,这使得无法分析或解决这些问题。
当我们之间有一个狭窄的通道时,会更好一点:
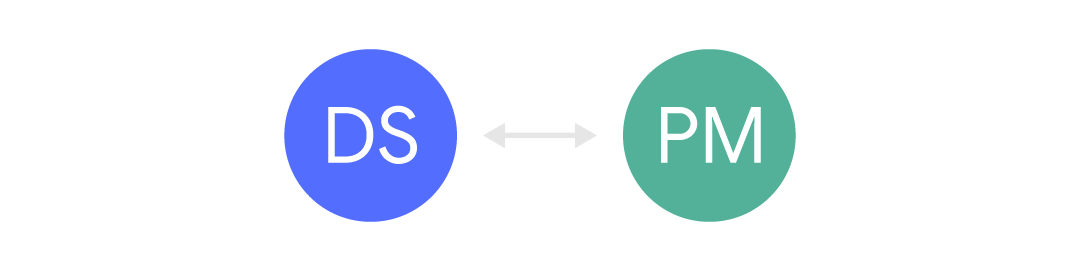
在这种情况下,信息来了,但是通常是有限的,并且通常是异步的。 信息来自其他人(例如,另一位经理)或通过请求表等获得。当期望数据科学专家将为许多不同的客户提供服务时,这种交流是很常见的。 但这可能令人沮丧,因为经常缺少业务环境,这可能导致误解和愚蠢的大惊小怪。
最有效的条件是当我们拥有广泛的渠道时:

从最直接的意义上讲,广泛的渠道是指数据科学专家坐在产品经理旁边。 当然,这使他们能够更有效地交流。 使人们保持身体接近并不总是很方便甚至是不可能的(Schibsted的我们分布在22个不同的国家!),但是这种原理有一些虚拟的版本:从Slack到远程结对编程和环聊。
自然,公司中的每个产品经理都不可能与您团队中的每个数据科学专家一起组织广泛的渠道,这是无法扩展的。 作为数据科学经理,您的任务是确定何时组织哪些广泛的渠道。 然后躲开!
在Schibsted,当我们积极致力于创造广泛的渠道时,其中之一就是开发我们的汽车定价工具,该工具可帮助您在出售汽车时设定价格( 在挪威的Finn市场上试用 )。 最初,我们有一个比较精简的渠道,例如:“尝试建立最准确的定价模型。” 我们发现这种方法效率很低,因为有很多产品问题,如果不对用户进行早期试验就无法回答。
但是,经过一段时间后,所有结果都以我们将一位数据科学专家整合到产品团队中而结束,我们得到了更好的结果。 您可以在这篇文章中了解我们有关汽车评级工具的早期工作。
我们从一开始就拥有广泛渠道的一个例子是新数字订户的预测模型 。 该模型帮助将销售转化率提高了540%,并于2017年获得了INMA最佳数据分析奖。
2.3。 负责分析效率
安德鲁·格鲁夫(Andrew Grove)在《高产出管理》一书中指出,作为经理,您拥有团队的成果。 这意味着数据科学经理必须投资于创造最佳的环境,以使其数据科学专家高效地工作。

这在许多方面都与上述嵌入模型相反。 如果始终嵌入所有内容,则很有可能会导致数据仓库和非最佳基础架构重复多次。
一些开发经理声称,当您成为领导者时,您应该完全停止编码。 , Data Science 10% : , . . Data Science.
« 15 , , , , ad-hoc ?! , ».
« ― ?»
.
, . , , , Data Science.
, Lean Management, Data Science. XKCD :
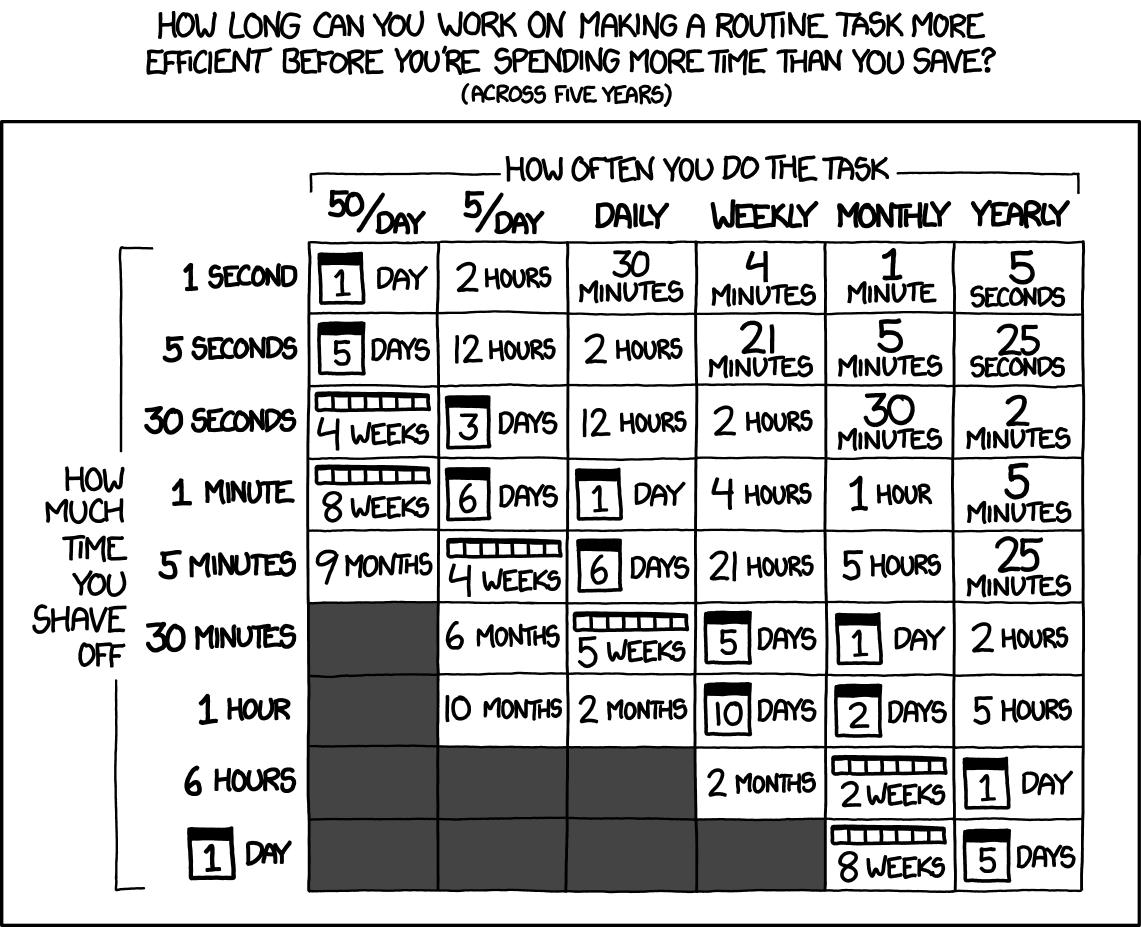
, Data Science . !
2.4。 -> ->
«» , Data Science, . Data Science . , , , .

:
- . 98% , , (… , ).
- , , - , .
, Data Science, , , , .
, , .
, , , , . , .
, ― . , . . Slack . ( !) , .
. . , !
, ? , , . , , , Data Science.
. , , , , . .
2.5。 ,
Data Science. , . , , - , ?
Ferrari, .

, .

Ferrari , .

Data Science ― , , . , , , , (ROI).
Data Science. - , .
, , . , , , , ― , . , , .
, Data Science . , . , , , .
2.6。 OKR
, Data Science. Objectives and Key Results (OKR). , OKR ― , . , . OKR , .
OKR , , , , .
, OKR , . , : , .
, , OKR.
-: OKR. OKR , , , . « », . , . , .
LSTM ? , NLP-, , LSTM . ? . ? , .
OKR, .
, OKR . , .
-: OKR . , . , :
, , 10 , . , , ― . . OKR .
, , OKRs ― .
2.7。
最后,最重要的一点。
当谷歌正在研究他的团队两年来找出是什么使一些球队,而其他表现良好-废弃的,有一件事是站了出来。这是心理安全。
简而言之,心理安全可以概括为相信您犯错不会受到惩罚的信念。
现在,在第一部分的介绍中考虑这个问题。冒充者综合症在数据科学中非常大。当您感到冒名顶替时,您会担心什么?犯错误。
多年来,我发现来自各个领域的人们都来学习数据科学。 在我们的Schibsted团队中,我们很幸运,我们有很棒的人,他们有非常广泛的经验。 具有金融,研究,教育,咨询,软件开发等经验的人员
假设所有这些人都知道同一件事是愚蠢的。 相反,这种多样化体验的价值在于每个人都为团队带来新的东西。
“独角兽”数据科学的想法是心理安全的毒药。
是否有快速解决方案来提高心理安全性? 我不这么认为。 但是我认为,作为经理,它应该在您的优先级列表的顶部-尤其是在您创建新团队或新成员加入时。 尽管没有快速解决方案,但是可以采取一些明显的措施来提高心理安全性。 以下是一些对我们有效的方法:
- 建立反馈文化。 明确说明,在演示,冲刺等之后,您的团队成员必须互相交流“优点和可以改进的地方”。顺便说一句,作为经理,您也必须这样做! 并教人们如何正确给出建设性反馈-这对每个人来说都不是自然的事情。
- 增加面对面的时间 。 配对编程,在板上解决问题……这对于远程团队而言尤其重要。 这张票几乎肯定是值得的。
- 创建对或团队而不是个人工作。 您最终可能会减少团队的工作量,但会做得更好。 和那些一起工作的人将建立彼此的信任。
- 鼓励公开和诚实的会议讨论 。 积极工作以平衡所有参与者的直播时间-可能需要有人讲话。
- 记住文化差异 。 您可以来自平等,明晰和直接的文化 。 您很有可能会错过来自团队成员的信号,这些信号源自分层,隐式和间接的文化。
- 进行小组实验以不断改进。 让整个团队参与“您如何成功管理团队”问题,使每个人对团队的幸福感负有责任。
- 测量幸福感和心理安全感。 寻找一种简单的方法来定期询问有关幸福和心理安全的问题。 如果您没有用于这些目的的流行的HR系统, 则从Typeform开始并进行迭代,直到您和团队发现它有用为止。 与团队共享(匿名)平均评分或发现,并将其包括在改善情况中。
...
恭喜,您已经结束了! 我希望这篇文章对您作为数据科学专家或经理有帮助。
我们经历了很多,这是一个简短的清单:
第一部分:现实生活中的数据科学
1.1。 复杂性增加价值,从简单开始
1.2。 始终有基本模型
1.3。 使用您拥有的数据
1.4。 负责数据
1.5。 忘记数据
1.6。 深入了解因果关系
第二部分:管理数据科学团队
2.1。 数据科学团队并不是真正的团队
2.2。 将数据科学专业人员嵌入其他团队
2.3。 负责分析效率
2.4。 数据->权力->政治
2.5。 利用您的资源,争取高投资回报
2.6。 OKR聚焦和对齐
2.7。 首先,心理安全
...
感谢您的阅读! 如果这有帮助,请考虑与他人分享此信息。 我希望有一天能看到您对担任专家或数据科学经理的想法