大家好! 我的名字叫Misha Kamenshchikov,我从事数据科学和Avito建议团队中微服务的开发。 在本文中,我将讨论我们对类似广告的建议,以及如何通过多臂土匪对其进行改进。 我在Highload ++ Siberia会议上以及在“数据与科学:市场营销”事件中就此主题做了演讲。

文章大纲
关于Avito的建议
首先,简要概述了Avito上的所有建议类型。
个性化的用户项目建议
用户项目推荐基于用户的操作,旨在帮助他快速找到感兴趣的产品,或显示可能有趣的东西。 它们可以在网站和应用程序的主页上或邮件列表中看到。 为了创建这样的建议,我们使用两种类型的模型:离线和在线。
离线模型基于矩阵分解算法,该算法可在几天内对所有数据进行训练,并将建议存储在快速存储库中,以分发给用户。 在线模型会根据用户历史记录中的广告内容即时考虑建议。 离线模型的优势在于,它们提供了更准确和高质量的建议,但是它们没有考虑到固定训练样本后在模型训练期间可能发生的最新用户操作。 在线模型会立即响应用户的操作,并且建议会随每个操作而改变。
冷启动建议
所有推荐系统都有一个所谓的“冷启动”问题。 其含义是上述模型无法在没有操作历史的情况下向新用户提供建议。 在这种情况下,最好让用户熟悉网站上的内容,同时不仅要选择随机广告,而且要选择例如在用户区域内受欢迎的类别中的广告。
搜索建议
对于经常使用搜索的用户,我们会建议您使用搜索快捷方式-他们会将用户发送到特定类别并设置过滤器。 这些建议可以在应用程序主页的顶部找到。
项项建议
项目建议在网站上以产品卡上类似的公告形式显示。 可以在所有平台的广告说明下看到它们。 推荐模型目前仅包含内容,并且不使用有关用户操作的信息,因此我们可以立即在网站上的活动广告中选择类似的广告来制作新广告。 在本文的后面,我将讨论这种特殊类型的推荐。
有关在Avito上的所有类型建议的更多详细信息,我们已经在博客中进行了撰写 。 如有兴趣,请阅读。
类似广告
这是带有类似广告的图块的外观:

此类推荐首先出现在网站上,并且该逻辑已在Sphinx搜索引擎上实现。 实际上,该模型是各种因素的线性组合:单词匹配,距离,价格差异和其他参数。
根据目标广告的参数,在Sphinx中生成一个请求,并使用内置排名器进行排名。
请求示例:
SELECT id, weight as ranker_weight, ranker_weight * 10 + (metro_id=42) * 5 + (location_id=2525) * 10 + (110000 / (abs(price - 1100000) + 110000)) * 5 as rel FROM items WHERE MATCH('@title |scott|scale|700|premium') AND microcat_id=100 ORDER BY rel DESC, sort_time DESC LIMIT 0,32 OPTION max_matches=32, ranker=expr('sum(word_count)')
如果您尝试更正式地描述此方法,则可以想象一些权重形式的排名 和广告参数 (来源是原始广告)和 (定位广告)。 对于每个参数,我们引入相似度函数 。 它们可以是二进制的(例如,广告所在城市的重合),可以是离散的(广告之间的距离)和连续的(例如,价格的相对差)。 然后,对于两个公告,最终得分将由公式表示
使用搜索引擎,您可以快速阅读此公式的值以获取足够多的广告,并实时对投放进行排名。
这种方法在其原始形式中表现得很好,但是有很多缺点。
解决问题
首先,首先以专家的方式选择权重,这是毫无疑问的。 有时权重会发生变化,但是权重的变化是基于点反馈,而不是通常基于对用户行为的分析。
其次,权重在站点上进行了硬编码,对其进行更改非常不便。
迈向自动化
改进推荐模型的第一步是在Python的单独微服务中删除所有逻辑。 这项服务已经完全属于我们的建议小组,因此我们可以经常进行实验。
每个实验都可以通过所谓的“配置”来表征-一套用于排名的权重。 我们希望生成配置并根据用户操作选择最佳配置。 如何生成这些配置?
第一个选项从一开始就是专家生成的配置。 就是说,利用从主题领域获得的知识,我们假设,例如,在搜索汽车时,人们对价格接近他们所查看的价格的选择感兴趣,而不仅是相似的模型,这可能会花费更多。
第二个选项是随机配置。 我们为每个参数设置某种分布,然后从该分布中抽取一个样本。 此方法更快,因为您无需考虑所有类别的每个参数。
一个更复杂的选择是使用遗传算法。 我们知道哪个配置在用户操作方面给我们带来了最佳效果,因此在每次迭代时,我们都可以保留它们并添加新的:随机或专家。
机器学习的使用是一个更复杂的选择,需要长期的试验历史来满足。 我们可以将一组参数表示为特征向量,将目标度量表示为目标变量。 然后,我们将找到一组参数,根据模型的评估,这些参数将最大化我们的目标指标。
在我们的案例中,我们选择了前两种方法以及最简单形式的遗传算法:我们留下最好的,除去最坏的。
现在,我们进入了文章中最有趣的部分:我们可以生成配置,但是如何进行实验以使其快速高效?
实验性
实验可以以A / B / ...测试的形式进行。 为此,我们需要生成N个配置,等待具有统计意义的结果,最后选择最佳配置。 这可能会花费相当长的时间,并且在整个测试过程中,固定的一组用户可能会收到质量较差的建议-随机生成配置很可能。 另外,如果我们想向实验中添加一些新配置,则必须再次重新启动测试。 但是我们希望快速进行实验,以便能够更改实验条件。 这样用户就不会遭受故意的不良配置的困扰。 多武装的土匪会帮助我们。
多臂土匪
该方法的名称来自“单臂匪徒”-赌场中的老虎机,带有杠杆,您可以拉动并获得胜利。 想象一下,您所在的房间里有许多这样的机器,并且您有N次免费尝试在其中任何一个机器上玩的机会。 当然,您想赢取更多的钱,但是您不预先知道哪台机器能赢得最大的收益。 多臂匪的问题恰恰在于找到损失最少的最赚钱的机器(在不利的机器上玩)。
如果我们根据建议任务来表述,结果表明机器是配置,每次尝试都是用于生成建议的配置选择,并且增益是一些目标指标,具体取决于用户的反馈。
土匪胜过A / B / ...测试的优势
它们的主要优点是,它们使我们能够根据特定配置的成功来更改流量。 这只是解决了人们在整个实验中都会得到不好的建议的问题。 如果他们不点击建议,则强盗会很快理解这一点,并且不会选择此配置。 此外,我们始终可以向实验添加新配置,也可以直接删除当前配置之一。 所有这些共同为我们提供了进行实验的灵活性,并通过A / B / ...测试解决了该方法的问题。

ster徒策略
有很多解决多武装匪徒问题的策略。 接下来,我将描述我们尝试在任务中应用的几类易于实现的策略。 但是首先,您需要了解如何比较策略的有效性。 如果我们事先知道哪支笔能获得最大增益,那么最佳策略将始终是拉动这支笔。 我们确定步骤数并计算最佳奖励 。 对于策略,我们还将计算奖励。 并介绍概念 :
可以将其他策略与此值进行比较。 我注意到策略具有变化的性质
可能会有所不同,对于少数几个步骤,一种策略可能会更好;而对于较大的一步,另一种策略可能会更好。
贪婪策略
顾名思义,贪婪策略是基于一个简单的原理-始终选择平均回报最大的笔。 此类的策略在我们探索环境以确定这种笔的方式方面有所不同。 例如,有 策略。 她有一个参数- ,它确定了我们选择最佳笔而不是最佳笔的概率,从而探索了我们的环境。 您还可以减少随时间推移进行研究的可能性。 这个策略叫做 。 贪婪策略很容易实现且易于理解,但并不总是有效。
UCB1
这种策略是完全确定性的-笔是根据当前可用信息唯一确定的。 这是公式:
公式的一部分
表示第j支笔的中间,并负责剥削,就像贪婪的策略一样。 公式的第二部分负责探索,
是动作总数
-第j支笔的动作数。 这个策略有一个可靠的估计
。 你可以
在这里阅读。
汤普森采样
在这种策略中,我们为每支笔分配一个随机分布,然后在每个步骤中从该分布中采样一个数字,并根据最大值选择一支笔。 根据反馈,我们更新分布参数,以使最好的笔对应于平均分布较大的分布,并且其分散度随操作次数而减少。 您可以在一篇出色的文章中了解有关此策略的更多信息。
策略比较
让我们在带有三个手柄的人工环境中模拟上述策略,每个手柄对应于带有参数的伯努利分布 相应地。 我们的策略:
- 与 ;
- UCB1;
- 汤普森Beta采样
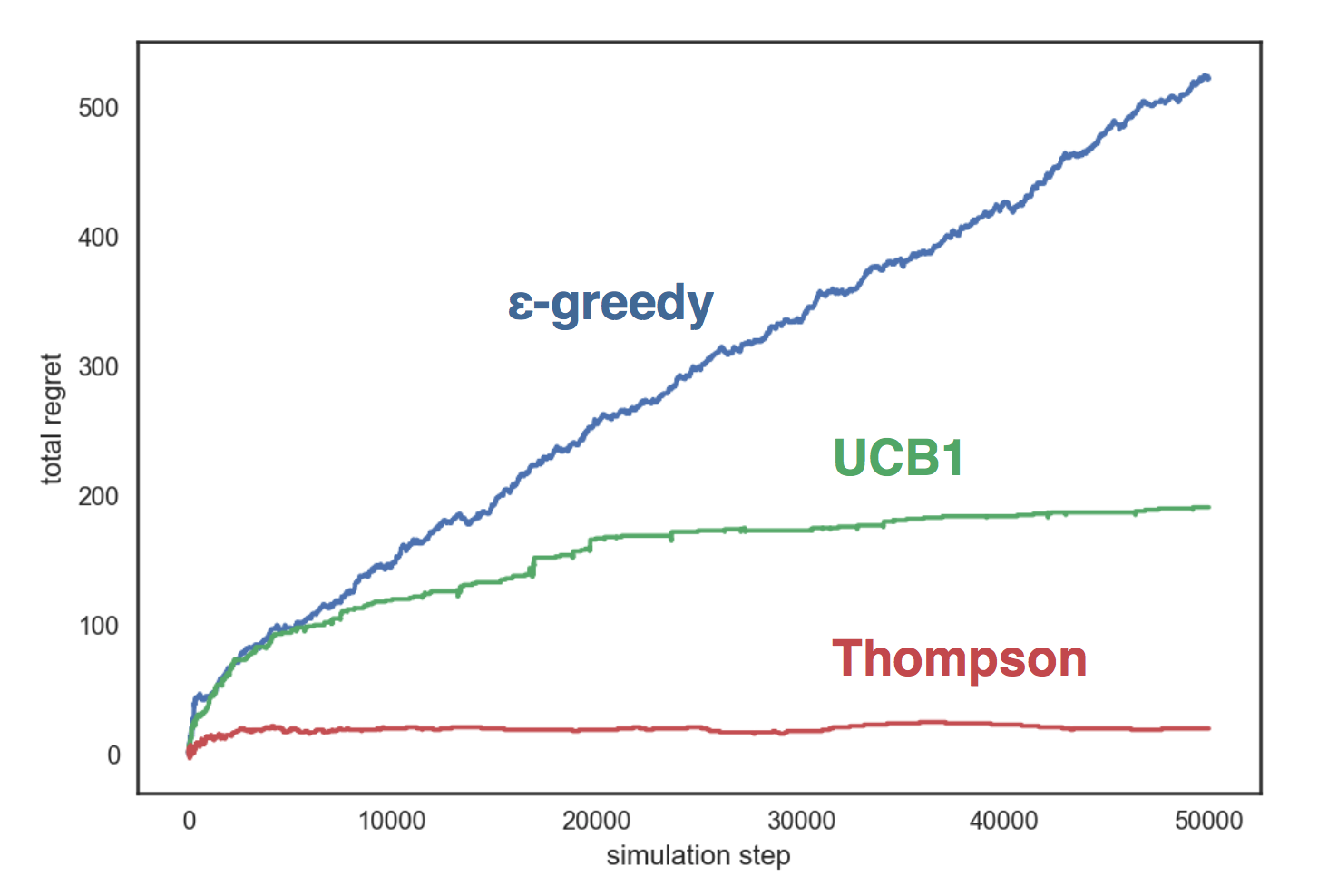
该图显示了贪婪策略 呈线性增长,在其他两个策略中-对数增长,汤普森的抽样显示自己比其他方法和她的方法好得多 几乎不会随着步数的增长而增长。
比较代码可在GitHub上获得 。
我向您介绍了多臂匪,现在我可以告诉您我们如何使用它们。
阿维托的多臂匪
因此,我们有几个配置(参数集),我们希望借助多臂匪徒从中选择最佳配置。 要让匪徒学习,我们需要一个重要的细节-用户反馈。 同时,我们接受培训的行动的选择应符合我们的目标-我希望用户进行更多交易并提供更好的建议。
选择目标动作
选择目标行动的第一种方法是非常简单和天真的。 作为目标指标,我们选择了视图数量,土匪们学会了如何优化该指标。 但是有一个问题:更多的观点并不总是很好。 例如,在“自动”类别中,我们设法将视图数量增加了15%,但与此同时,联系请求的数量却下降了大约相同的数量。 经过仔细检查,结果发现土匪选择了一支笔,该笔中的按区域过滤器处于关闭状态。 因此,该街区展示了来自俄罗斯各地的广告,当然,类似广告的选择范围更大。 这导致视图数量增加:从外观上看,建议的质量似乎更好,但是当他们进入产品卡片时,人们意识到汽车离他们很远,因此没有提出联系请求。
第二种方法是学习如何从查看块转换为联系请求。 这种方法似乎比以前的方法更好,这仅仅是因为该指标几乎直接对建议的质量负责。 但是出现了另一个问题-每日季节性。 取决于一天中的时间,转换值可能相差四(!)倍(通常比配置更好的效果要多),幸运的是,在第一个间隔内获得高转换率的笔仍然比其他笔数更频繁地被选择。
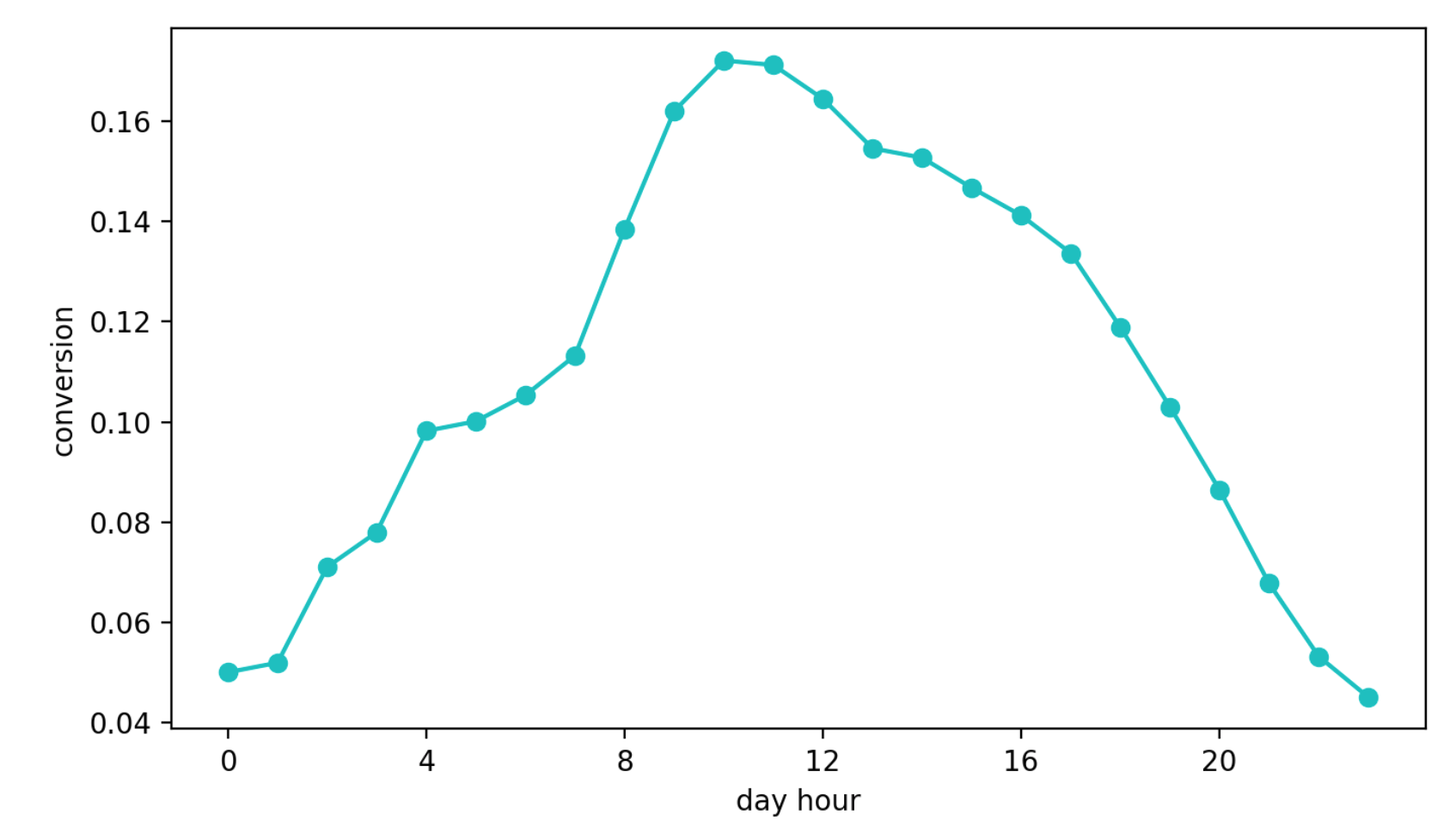
每日转换动态(Y轴值已更改)
最后,第三种方法。 我们现在使用它。 我们挑出参考小组,该参考小组始终会收到有关同一算法的建议,并且不受强盗的影响。 接下来,我们查看目标群体和参考中联系人的绝对数量。 他们的关系不受季节限制,因为我们是随机选择参考组,而且这种方法很方便地基于汤普森抽样。
我们的策略
如上所述,我们区分了参考人群和目标人群。 然后使用beta分布初始化N个句柄(每个句柄对应一个配置)
在每一步:
- 对于每支笔,我们从与其对应的分布中抽取一个数字,然后根据最大值选择一支笔;
- 计算分组中的动作数 和 在一定时间范围内(在我们的示例中为10秒),并更新所选笔的分布参数: , 。
使用此策略,我们可以优化所需的指标,目标组中的联系请求数量,并避免了我上面描述的问题。 另外,在全球A / B测试中,这种方法显示了最佳结果。
结果
全局A / B测试的组织方式如下:将所有广告随机分为两组。 对于其中一个的公告,我们在匪徒的帮助下展示了建议,对于另一个-则采用了旧的专家算法。 然后,我们测量每个组中的转化联系请求的数量(从相似的块切换到广告后做出的请求)。 平均而言,在所有类别中,拥有匪徒的团体比对照组的目标行动多出约10%,但在某些类别中,这种差异可以达到30%。
创建的平台使您可以快速更改逻辑,向匪徒添加配置并验证假设。
如果您对我们的推荐服务或多臂匪有疑问,请在评论中提问。 我很乐意回答。