云服务的元数据存储应满足哪些要求? 是的,不是最普通的,但适用于支持地理分布的数据中心和Active-Active的企业。 显然,该系统应具有良好的伸缩性,
容错能力,并且希望能够实现可定制的操作一致性。只有Cassandra可以满足所有这些要求,而没有其他适合的条件。 应该注意的是,Cassandra确实很酷,但是使用它就像过山车一样。
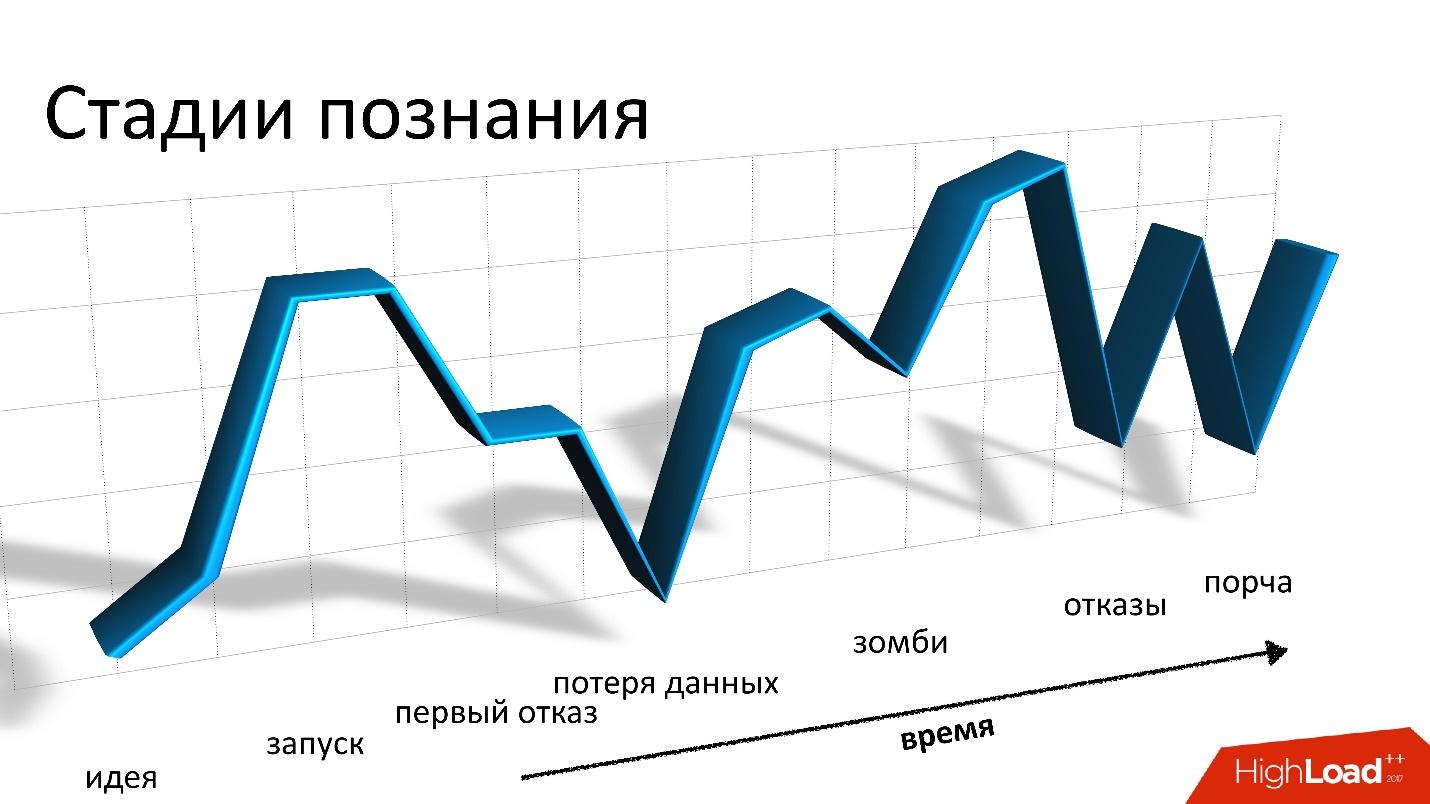
在2017年Highload ++的一份报告中,
Andrei Smirnov (
smira )认为谈论好东西并不有趣,但他详细谈到了他必须面对的每个问题:关于数据丢失和损坏,关于僵尸和性能损失的问题。 这些故事确实让人想起过山车,但是对于所有问题,都有解决方案,欢迎您前来解决。
关于演讲者: Andrey Smirnov在Virtustream工作,该公司为企业实施云存储。 这个想法是有条件的,亚马逊为每个人做云,而Virtustream做大公司需要的特定事情。
关于Virtustream的几句话
我们在一个完全远程的小型团队中工作,并且我们从事一种Virtustream云解决方案。 这是数据存储的云。

简单地说,这是一个S3兼容的API,您可以在其中存储对象。 对于那些不知道S3是什么的人来说,它只是一个HTTP API,您可以使用它将对象上传到某个地方的云中,将其取回,删除它们,获取对象列表等。 此外-基于这些简单操作的更复杂功能。
我们具有亚马逊没有的一些独特功能。 其中之一就是所谓的地理区域。 在通常情况下,创建存储库并说要在云中存储对象时,必须选择一个区域。 区域本质上是一个数据中心,您的对象将永远不会离开该数据中心。 如果他发生了什么事,那么您的对象将不再可用。
如图所示,我们提供了地理区域,其中数据同时位于多个数据中心(DC)中,至少两个位于其中。 客户可以与任何数据中心联系,因为对他而言,它是透明的。 它们之间的数据被复制,也就是说,我们一直在Active-Active模式下工作。 这为客户端提供了其他功能,包括:
- 直流故障或连接中断时,存储,读取和写入的可靠性更高;
- 即使其中一个DC发生故障,数据仍然可用;
- 将操作重定向到“最近”的DC。
这是一个有趣的机会-即使这些DC在地理位置上相距遥远,但其中一些DC可能在不同的时间点更接近客户。 访问数据到最近的DC只是更快。
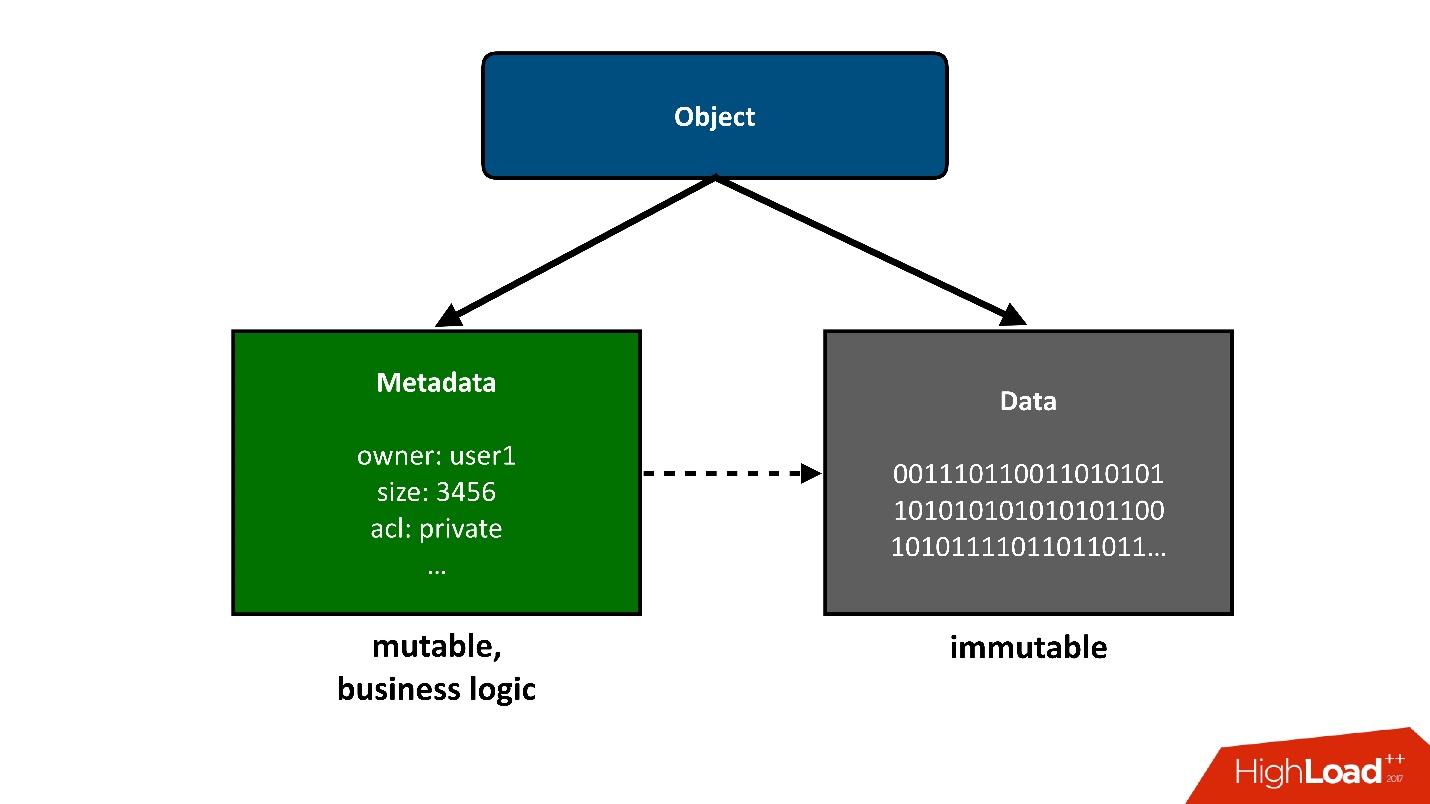
为了将我们将要讨论的结构分为几部分,我将把存储在云中的那些对象展示为两个大块:
对象的第一个简单片段是
data 。 它们没有更改,仅下载一次,仅此而已。 以后可能发生的唯一事情是,如果不再需要它们,我们可以将其删除。
我们之前的项目与EB的数据存储有关,因此我们在数据存储方面没有任何问题。 对我们来说,这已经是一个已解决的任务。
2.
元数据 。 所有最有趣的业务逻辑都与竞争有关:访问,记录,重写-在元数据区域中。
有关对象的元数据将其自身带入了项目的最大复杂性,元数据存储了指向对象存储数据块的指针。
从用户的角度来看,这是单个对象,但是我们可以将其分为两部分。 今天,我将
只谈论元数据 。
人物
- 数据 :4 PB。
- 元数据集群 :3。
- 对象 :400亿。
- 元数据大小 :160 TB(包括复制)。
- 变化率(元数据): 3000个对象/ s。
如果仔细查看这些指标,首先引起您注意的是存储对象的平均大小很小。 每单位体积的主数据中有很多元数据。 对于我们来说,这并不比现在给您一个惊喜。
我们计划至少要有一个数据阶(如果不是2个),而不是元数据。 即,每个对象将明显更大,而元数据的数量将更少。 因为数据的存储成本较低,所以从硬件的角度以及在对数据进行维护和执行各种操作的角度而言,使用它们进行的操作较少,而元数据则要昂贵得多。
而且,这些数据以相当高的速度变化。 我在这里给出了峰值,非峰值不是很多,但是,尽管如此,在特定的时间点仍可以获得相当大的负载。
这些数字已经从一个工作系统中获得,但是让我们回到设计云存储的时候。
选择元数据存储库
当我们面对想要拥有Active-Active地理区域的挑战,并且需要将元数据存储在某个地方时,我们认为可能吗?
显然,存储库(数据库)应具有以下属性:
我们真的希望我们的产品非常受欢迎,并且我们不知道它会如何同时增长,因此该系统应该可以扩展。
元数据必须安全地存储,因为如果我们丢失元数据,并且其中存在指向数据的链接,那么我们将丢失整个对象。
由于我们在多个DC中工作,并且允许DC可能不可用的事实,而且,DC之间的距离很远,因此,在大多数API操作期间,我们不能要求在Windows中同时执行此操作两个DC。 如果第二个DC不可用,它将太慢并且不可能。 因此,部分操作应在一个DC中本地进行。
但是,显然,某些时候应该会发生某种融合,并且在解决所有冲突之后,两个数据中心中的数据都应该可见。 因此,必须调整操作的一致性。
在我看来,Cassandra适合这些要求。
卡桑德拉
如果我们不必使用Cassandra,我将感到非常高兴,因为对我们而言,这是一种新的体验。 但是没有其他合适的方法了。 在我看来,这是这种存储系统在市场上最可悲的情况-
别无选择 。

什么是卡桑德拉?
这是一个分布式键值数据库。 从体系结构和嵌入其中的想法的角度来看,在我看来,一切都很酷。 如果我这样做了,我会做同样的事情。 刚开始时,我们考虑过编写自己的元数据存储系统。 但是,我们越来越意识到,我们将不得不做与Cassandra非常相似的事情,而为此付出的努力是不值得的。 对于整个开发
,我们只有一个半月 。 花钱让他们写数据库会很奇怪。
如果Cassandra像蛋糕一样分层,我将选择3层:
1.
每个节点上的本地KV存储。这是一个节点集群,每个节点都可以在本地存储键值数据。
2.
在节点上分片数据(一致的哈希)。Cassandra可以在群集的各个节点之间分发数据,包括复制,并且这样做的方式是群集可以增加或减少大小,并且可以重新分发数据。
3.
协调器,将请求重定向到其他节点。当我们从应用程序访问某些查询的数据时,Cassandra可以将查询分布到节点中,以便我们获得所需的数据并具有所需的一致性级别-我们希望仅读取仲裁数据,或想要具有两个DC的仲裁,等等。
对于我们来说,两年的卡桑德拉(Cassandra)-无论是过山车还是过山车-无论您想要什么。 一切从头开始,我们对Cassandra的经验为零。 我们很害怕。 我们开始了,一切都很好。 但是随后不断下降并开始起飞:问题,一切都不好,我们不知道该怎么办,遇到错误,然后解决问题,等等。
这些过山车原则上不会结束到今天。
好啊
第一章和最后一章,我说卡桑德拉很棒。 这真的很酷,一个很棒的系统,但是如果我继续说它是多么的好,我想您将不会感兴趣。 因此,我们将更加关注坏处,但稍后。
卡桑德拉真的很好。
- 这是使我们能够以毫秒为单位的响应时间的系统之一 ,即明显少于10 ms。 这对我们有好处,因为响应时间通常对我们很重要。 对我们而言,使用元数据进行的操作只是与对象存储(无论是接收还是记录)相关的任何操作的一部分。
- 从记录的角度来看,实现了高可伸缩性 。 您可以以惊人的速度编写Cassandra,在某些情况下,例如当我们在记录之间移动大量数据时,这是必需的。
- 卡桑德拉确实是容错的 。 一个节点的崩溃不会立即导致问题,尽管它们迟早会开始。 卡桑德拉宣称它没有单一的故障点,但是实际上,到处都有故障点。 实际上,使用数据库的人都知道,即使是节点崩溃也通常不会在早上发生。 通常,这种情况需要更快地解决。
- 简单性。 不过,与其他标准的Cassandra关系数据库相比,更容易了解正在发生的事情。 很多时候,出问题了,我们需要了解正在发生的事情。 与使用另一个数据库相比,Cassandra有更多的机会来弄清楚它,找到最小的螺钉。
五个坏故事
我再说一遍,卡桑德拉(Cassandra)很好,它对我们有用,但是我会讲五个关于坏消息的故事。 我认为这就是您要阅读的内容。 我将按时间顺序排列这些故事,尽管它们之间的联系不是很紧密。

这个故事对我们来说是最可悲的。 由于我们存储用户数据,因此最糟糕的事情就是丢失它们,并
永久丢失它们 ,就像这种情况下发生的那样。 如果在Cassandra中丢失了数据,我们提供了恢复数据的方法,但是我们丢失了数据,因此我们真的无法恢复。
为了解释这是如何发生的,我将不得不谈论一下我们内部的所有事物如何安排。
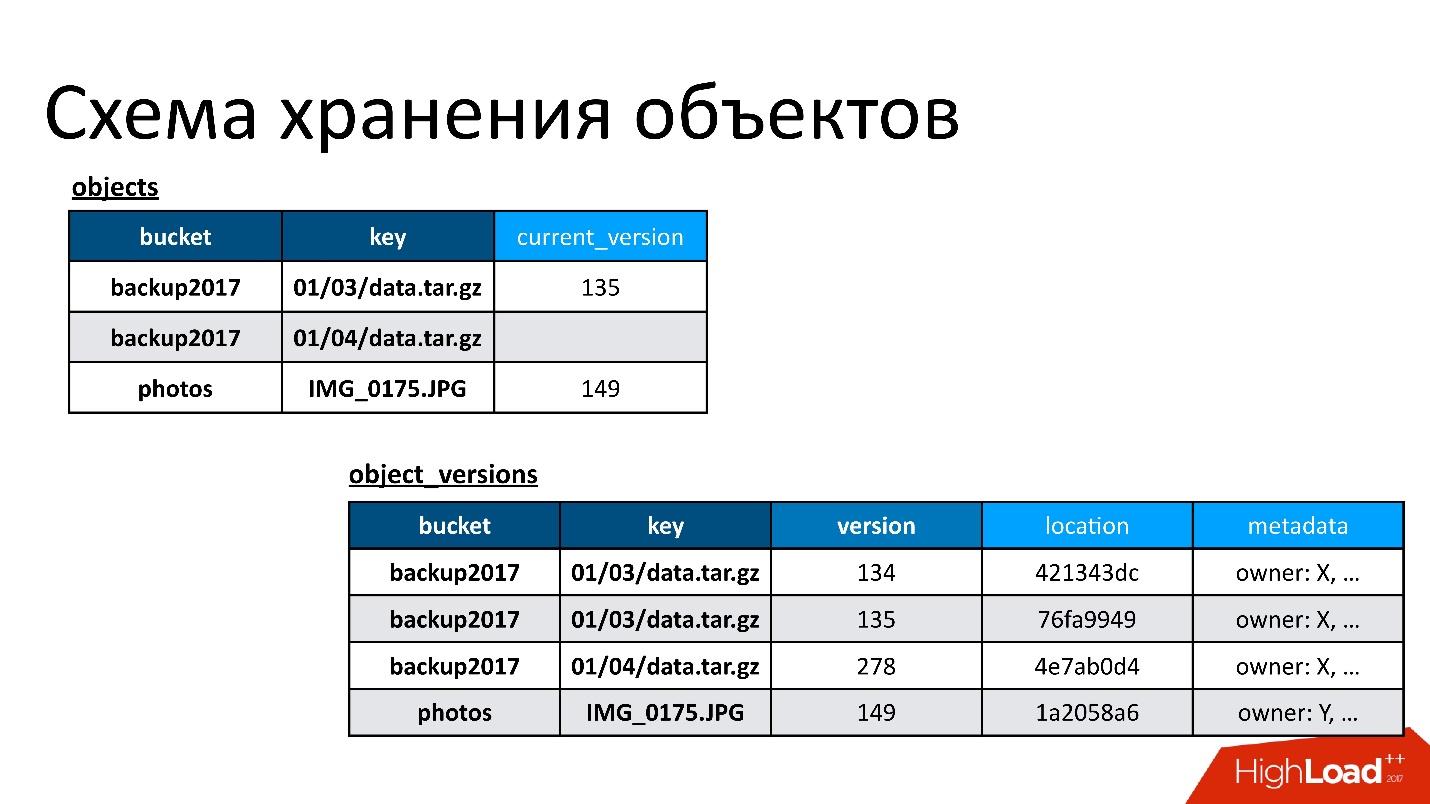
从S3的角度来看,有一些基本的东西:
- 存储桶-可以想象为用户将对象上载到其中的巨大目录(以下称为存储桶)。
- 每个对象都有一个名称(键)和与之关联的元数据:大小,内容类型和指向该对象数据的指针。 同时,存储桶的大小不受任何限制。 也就是说,它可以是10个键,也许是1000亿个键-没有区别。
- 任何竞争性操作都是可能的,也就是说,同一密钥中可能有多个竞争性填充,竞争性删除等。
在我们的情况下,可能会发生主动-主动操作,包括竞争地出现在不同的DC中,而不仅仅是在一个DC中。 因此,我们需要某种保护方案,使我们能够实现这种逻辑。 最后,我们选择了一个简单的策略:最后记录的版本获胜。 有时会进行一些竞争性运营,但我们的客户不一定故意这样做。 可能只是一个开始的请求,但是客户端没有等待答案,发生了其他事情,再次尝试,等等。
因此,我们有两个基本表:
- 对象表 。 在其中,一对(存储桶的名称和密钥的名称)与其当前版本相关联。 如果对象被删除,则此版本中没有任何内容。 如果对象存在,则有其当前版本。 实际上,在此表中,我们仅更改当前版本的字段。
- 对象的版本表 。 我们仅将新版本插入此表。 每次下载新对象时,我们都会在版本表中插入一个新版本,为其指定唯一编号,保存有关该版本的所有信息,最后在对象表中更新指向该对象的链接。
该图显示了如何将对象表和对象版本相关联的示例。

这是一个具有两个版本的对象-一个是当前版本,一个是旧版本,还有一个已被删除的对象,并且其版本仍然存在。 我们需要不时清理不必要的版本,即删除其他人没有提及的内容。 此外,我们不需要立即删除它,我们可以在延迟模式下进行删除。 这是我们的内部清洗,我们只删除不再需要的内容。
出现问题了。
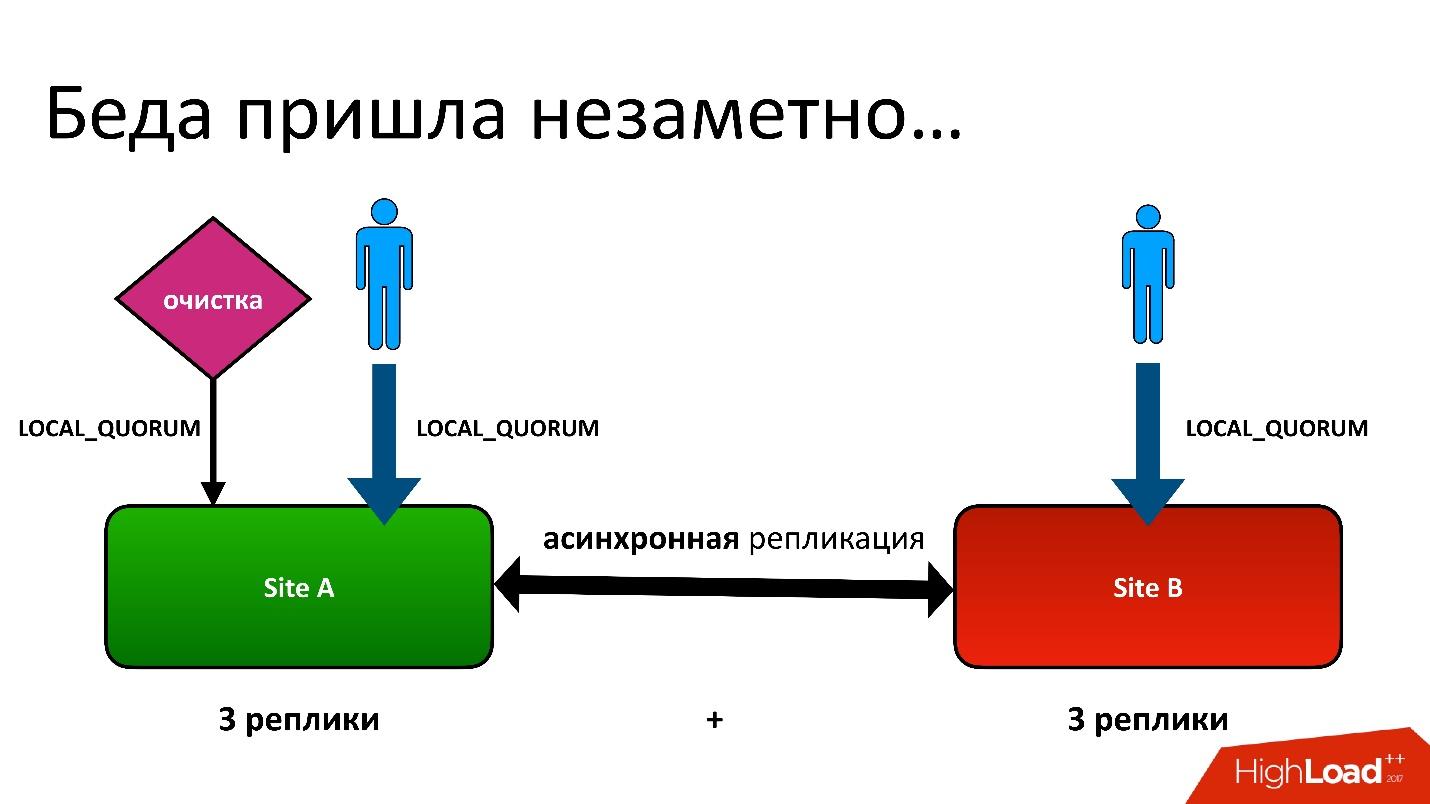
问题是这样的:我们有两个主动DC。 在每个DC中,元数据存储在三个副本中,也就是说,我们有3 + 3-只有6个副本。 当客户与我们联系时,我们将执行一致的操作(从Cassandra的角度来看,它称为LOCAL_QUORUM)。 也就是说,可以保证记录(或读取)发生在本地DC的2个副本中。 这是保证-否则操作将失败。
Cassandra将始终尝试在所有6行中进行书写-99%的时间里一切都会好的。 实际上,所有6个副本都是相同的,但对我们保证2。
尽管这不是一个地理区域,但我们处境艰难。 即使对于一个DC中的普通区域,我们仍然将元数据的第二个副本存储在另一个DC中。 这是一个很长的故事,我不会给出所有细节。 但是最后,我们进行了清理,删除了不必要的版本。
然后出现了同样的问题。 清理过程还可以在一个数据中心内实现本地仲裁的一致性,因为在两个数据中心中运行它没有意义,因为它们会相互竞争。
一切都很好,直到证明我们的用户有时仍会写到另一个我们并不怀疑的数据中心为止。 一切都是为了以防万一,以防万一,但事实证明他们已经在使用它了。
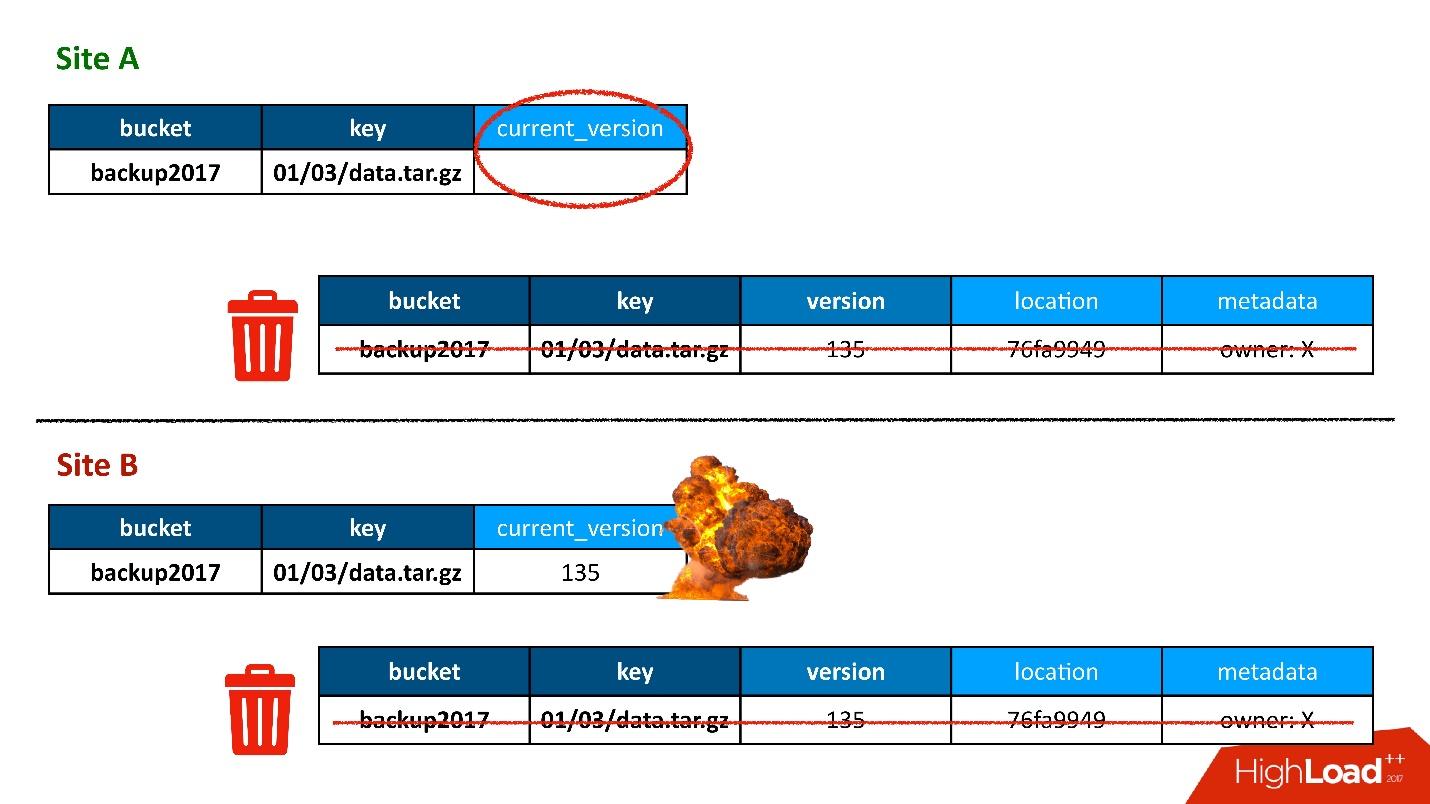
在大多数情况下,一切都很好,直到有一天出现了版本表中的记录在两个DC中都被复制的情况,但是对象表中的记录原来只在一个DC中,但并没有在第二个DC中结束。 因此,在第一个(上部)DC中启动的清洁程序发现,没有人引用该版本并将其删除。 而且我不仅删除了版本,还删除了数据,所有内容都是完整的,因为它只是一个不必要的对象。 而且这种清除是不可撤销的。
当然,还有一个“繁荣”,因为我们在对象表中仍然有一个记录,该记录指向一个不再存在的版本。
因此,我们第一次丢失数据,并且确实无法挽回地丢失了-好一点。
解决方案
怎么办 在我们的情况下,一切都很简单。
由于我们将数据存储在两个数据中心中,因此清理过程是一个收敛和同步的过程。 我们必须从两个DC读取数据。 仅当两个DC均可用时,此过程才有效。 因为我说过这是一个延迟的过程,在处理API期间不会发生,所以这并不可怕。
一致性ALL是Cassandra 2的功能。在Cassandra 3中,一切都好一点-一致性水平,在每个DC中都称为仲裁。 但是无论如何,都存在
速度慢的问题,因为首先,我们必须转向远程DC。 其次,在所有6个节点的一致性的情况下,这意味着它以这6个节点中最差的速度工作。
但是同时,当并非所有副本都同步时,就会发生所谓的
读取修复过程。 也就是说,当某处录制失败时,此过程将同时修复它们。 这就是Cassandra的运作方式。
发生这种情况时,我们收到客户的投诉,称该对象不可用。 我们弄清楚了,明白了为什么,我们要做的第一件事就是找出我们还有多少这样的对象。 我们运行了一个脚本,当一个表中有一个条目但另一个表中没有条目时,它试图找到与此类似的构造。
突然我们发现我们有
10%的此类记录 。 如果我们没有想到事实并非如此,那么可能不会发生更糟的事情。 问题不同。

僵尸已潜入我们的数据库。 这是此问题的半官方名称。 为了了解它是什么,您需要讨论删除在Cassandra中的工作方式。
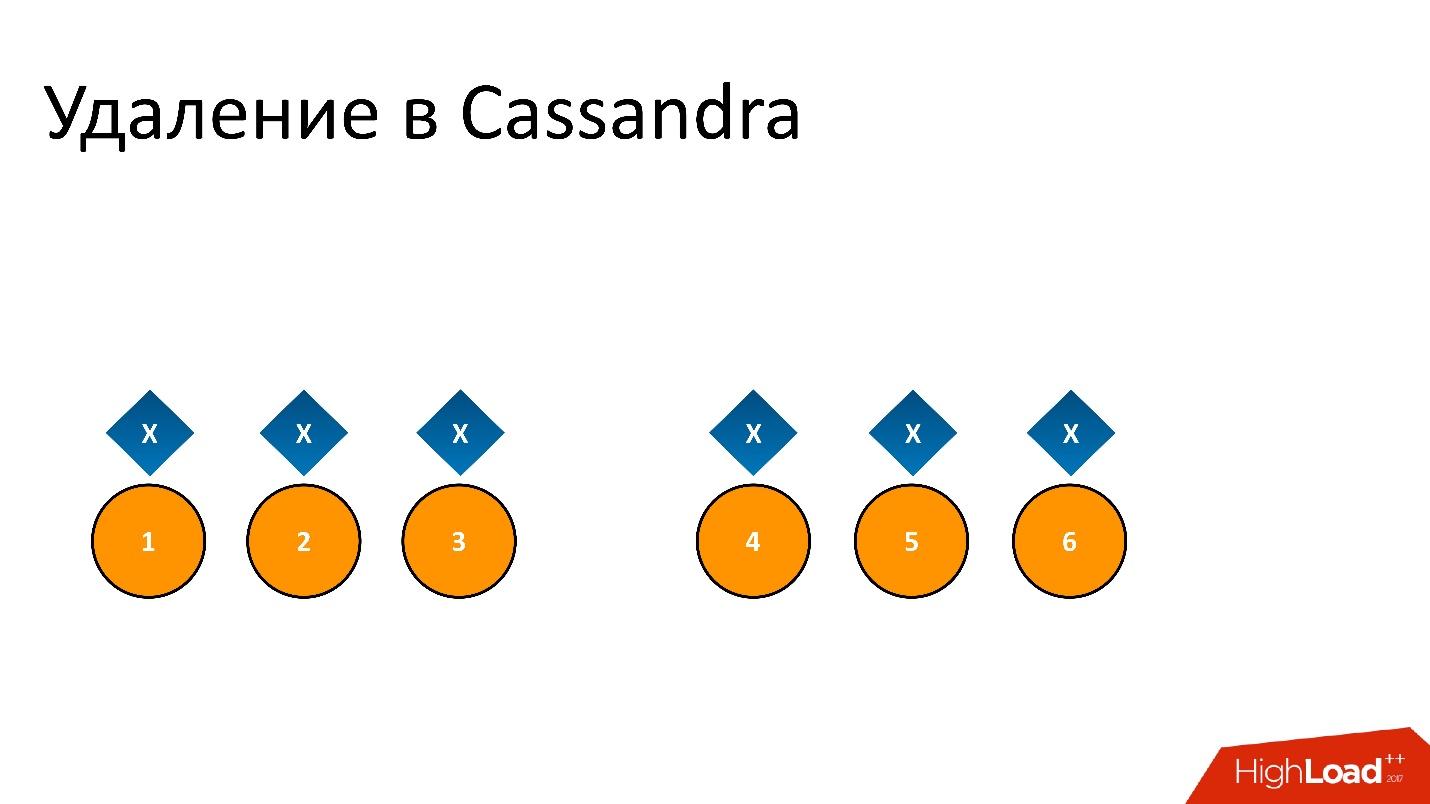
例如,我们记录了一些数据
x并将其完美复制到所有6个副本中。 如果我们要删除它,则删除操作可能与Cassandra中的任何操作一样,并非在所有节点上都执行。
例如,我们要保证DC中3分之2的一致性。 让删除操作在五个节点上执行,但保留在一条记录上,例如,因为该节点当时不可用。
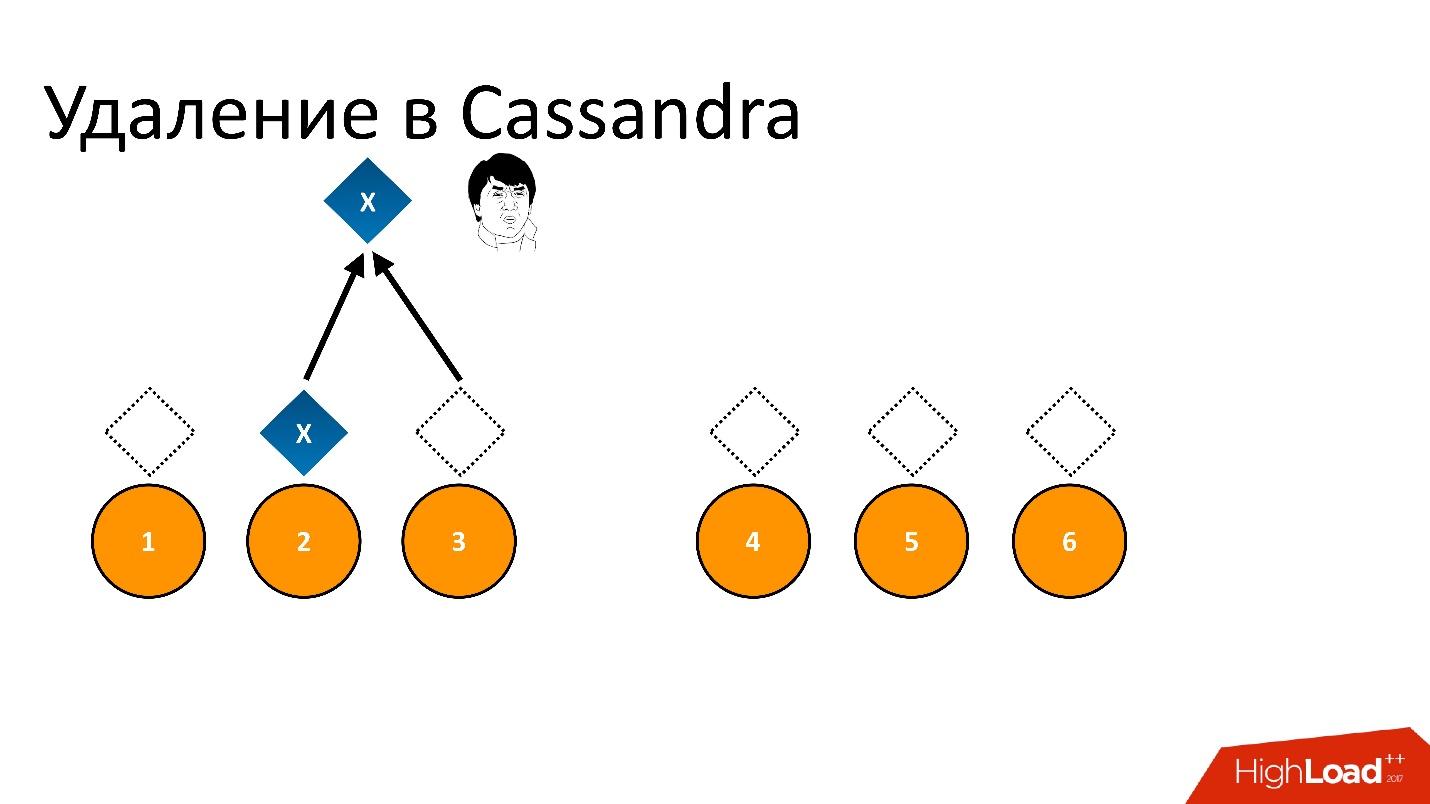
如果我们删除它,然后尝试以相同的一致性读取“我想要三分之二”,那么Cassandra会看到值及其不存在,将其解释为数据的存在。 也就是说,当我们回读时,她会说:“哦,有数据!”,尽管我们删除了它们。 因此,您不能以这种方式删除。

卡桑德拉的删除方式有所不同。
删除实际上是一个记录 。 当我们删除数据时,Cassandra会写一些小的标记,称为
Tombstone (墓碑)。 它标志着数据已删除。 因此,如果我们同时读取删除令牌和数据,那么在这种情况下,Cassandra总是更喜欢删除令牌,并说实际上没有数据。 这就是你所需要的。
Tombstone — , , , , - , . Tombstone .
Tombstone gc_grace_period . , , .
?
Repair
Cassandra , Repair (). — , . , , , , / , , - - , .. . Repair , .

, - , - . Repair , , . - , — . , .

Repair, , , , — , . 6 . — , , .

, — , - . , . , - , , , .
解决方案
, :
, repair. , , .
repair — , repair. , , 10-20 , , 3 . Tombstone , . , , -.

Cassandra, . .
S3 . , — 10 , 100 . API, — . , , , , , . , , , — , . .
API?

, — , , — , , . . — . , , . , , Cassandra. , — , , , .
, , , , . , . , , . , - , .
Cassandra , . , , , , , .
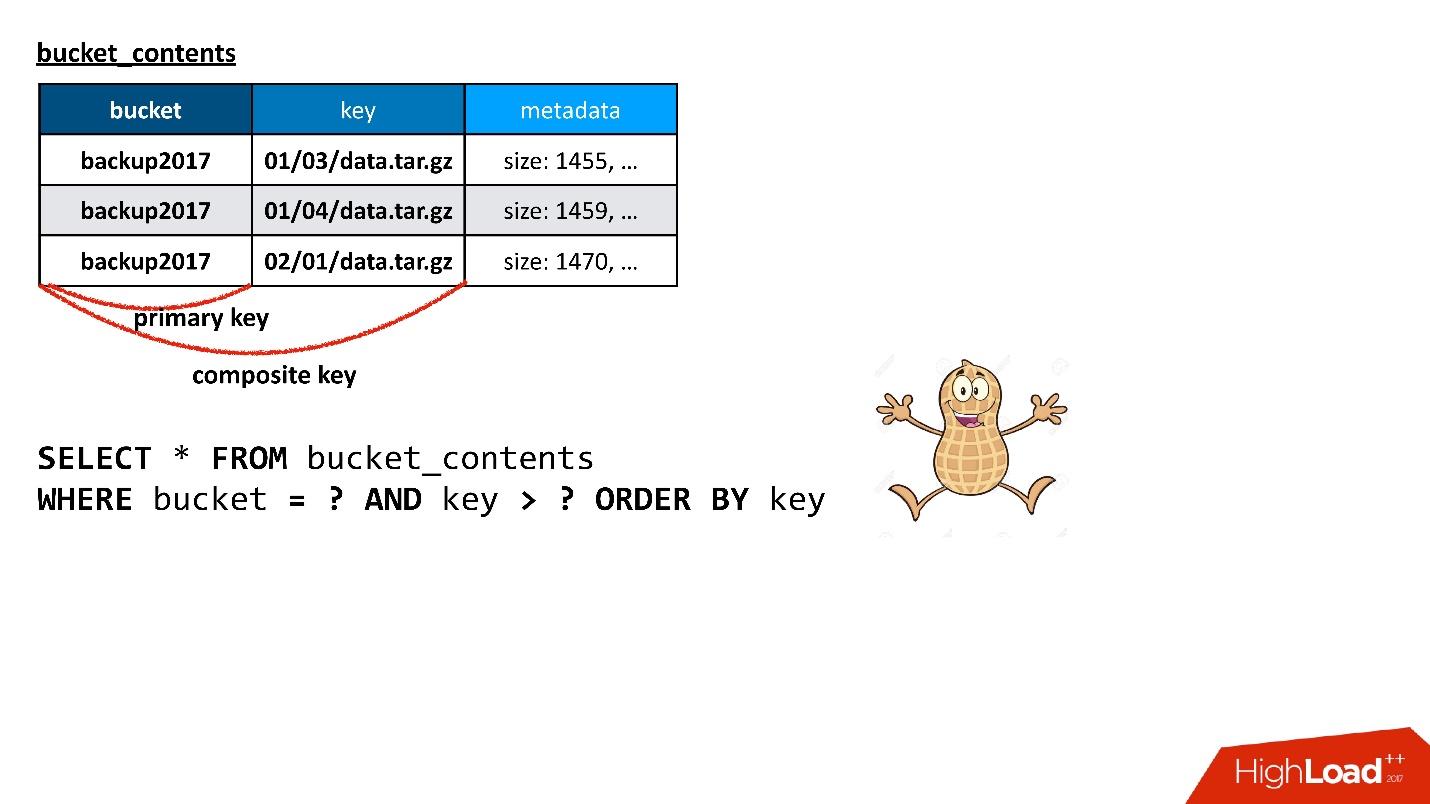
, Cassandra
composite key . , — , - , — . , . ? , , !
, , , , — , .
. Cassandra ,
Cassandra . , , Cassandra, : , , SQL .. !

. Cassandra ? , , API. , , , , ( ) .
, .
, . , , , . , — — . , , , .
Cassandra , . : « 100 », , , , , , 100, .
, ( ), — , , . , , , , , - . 100 , - , , . , SQL .
Cassandra , , Java, . ,
Large Partition , . — , , , , — . , , garbage collection .. .
, ,
, , .
, , - .

, , . . , Large Partition.
:
- ( , - );
- , , . , .
, , , key_hash 0. ,
, . , . , , .
, .

— , , , - - .
— , N ? , Large Partition, — . , . : . , , , , - . , . , , .

— , , - . - , , . , , . , , ..
— , ? , . ? - md5- — , - 30 — , - . . , , .

, , , , . — , . , . , - - - , - - — . , . .
, , , .
- .
- .
- Cassandra.
- 联机重新分发(不停止操作,也不失去一致性)。
现在我们有了存储桶的某种状态,它以某种方式分为多个分区。 然后我们了解到某些分区太大或太小。 我们需要找到一个新的分区,一方面,它将是最佳的,即每个分区的大小将小于我们的某些限制,并且它们或多或少是统一的。 在这种情况下,从当前状态到新状态的转换应该需要最少的操作数。 显然,任何过渡都需要在分区之间移动键,但是移动得越少越好。
我们做到了。 如果我们通常讨论使用元数据,那么处理分发选择的部分可能是整个服务中最困难的部分。 我们重写了它,对其进行了重新设计,并继续这样做,因为总是发现某些客户端或某些创建密钥的模式对这种方案的弱点不利。
例如,我们假设桶将或多或少均匀地生长。 也就是说,我们选择了某种分布,并希望所有分区都将根据该分布而增长。 但是我们发现一个客户总是写在最后,因为他的密钥总是按顺序排列。 他一直都在最后一个分区中跳动,该分区以这样的速度增长,在一分钟之内就可以达到10万个键。 而10万个大约是适合一个分区的值。
我们根本没有时间用我们的算法来处理这样的密钥添加,因此我们不得不为此客户引入一种特殊的预发行版。 因为我们知道他的键是什么样子,所以如果我们看到它是他,我们就可以开始在结尾处提前创建空分区,以便他可以在那儿平静地写东西,到目前为止,我们将稍作休息,直到下一次迭代,此时我们再次必须重新分配所有内容。
所有这些都是在不停止操作的情况下在线发生的。 可能会有读取,写入操作,您可以随时请求键列表。 即使我们正在进行重新分区,它也将始终保持一致。
这很有趣,事实证明是Cassandra。 在这里,您可以玩一些与Cassandra能够解决冲突有关的技巧。 如果我们在同一行上写了两个不同的值,则时间戳较大的值将获胜。
通常,时间戳是当前时间戳,但是可以手动传递。 例如,我们要向字符串中写入一个值,如果客户自己写了一些东西,则无论如何都应删除该值。 也就是说,我们正在复制一些数据,但是我们希望客户,如果他突然与我们同时写信,则能够覆盖它。 然后,我们只需复制带有时间戳的数据即可。 然后,无论记录的创建顺序如何,任何当前的记录都会被故意磨损。
这些技巧可让您在线进行操作。
解决方案
- 绝对不要让大分区出现 。
- 根据任务按主键中断数据 。
如果在数据方案中计划了类似大型分区的操作,则应立即尝试对其进行处理-确定如何破坏它以及如何摆脱它。 迟早会出现这种情况,因为在几乎所有任务中迟早都会出现任何反向索引。 我已经告诉过您这样的故事-我们在对象中有一个存储桶键,我们需要从存储桶中获取键列表-实际上,这是一个索引。
此外,不仅从数据来看,分区也可能很大,从墓碑(删除标记)来看,分区也可能很大。 从Cassandra内部构件的角度(从外面看不到它们),删除标记也是数据,并且如果要删除的对象很多,则分区可能很大,因为删除是一条记录。 您也不应该忘记这一点。

另一个始终不变的故事是,从始至终都出了问题。 例如,您看到来自Cassandra的响应时间增加了,响应速度很慢。 如何理解和理解问题所在? 从来没有外部信号表明存在问题。

例如,我给出一个图表-这是整个群集的平均响应时间。 它表明我们有一个问题-最大响应时间是12秒-这是Cassandra的内部超时。 这意味着她会超时。 如果超时超过12秒,则最有可能意味着垃圾收集器正在工作,并且Cassandra甚至没有时间在正确的时间进行响应。 她通过超时来回答自己,但是,正如我所说,对大多数请求的响应时间平均应该在10毫秒内。
在图表上,平均值已经超过了数百毫秒-出了点问题。 但是看这张照片,不可能理解是什么原因。

但是,如果在Cassandra节点上扩展相同的统计信息,则可以看到,原则上,所有节点几乎没有什么,但是一个节点的响应时间相差一个数量级。 他很可能有某种问题。
节点统计完全改变了画面。 这些统计信息来自应用程序端。 但是实际上,通常很难理解问题所在。 当应用程序访问Cassandra时,它使用协调器访问某个节点。 也就是说,应用程序发出一个请求,然后协调器将其重定向到具有数据的副本。 那些已经回答了,协调员形成了最终的回答。
但是,为什么协调员反应缓慢? 也许问题出在他身上,也就是说,他放慢脚步并慢慢回答? 还是他慢下来了,因为复制品对他的反应很慢? 如果副本响应缓慢,从应用程序的角度来看,它看起来像是来自协调器的缓慢响应,尽管与它无关。
这是一个令人高兴的情况-很明显,只有一个节点响应缓慢,很可能是问题所在。
解释的复杂性
- 协调器响应时间(节点与副本本身)。
- 特定表还是整个节点?
- GC暂停? 线程池不足?
- 未压缩的SSTable太多了吗?
总是很难理解哪里出了问题。 它只
需要大量的统计信息和监视信息 ,无论是在应用程序方面还是在Cassandra本身,因为如果确实很糟糕,Cassandra看不到任何东西。 您可以在每个特定节点的每个特定表的级别查看单个查询的级别。
例如,在某些情况下,Cassandra SSTables中所谓的一个表(单独的文件)太多了。 为了阅读,大致来说,Cassandra必须对所有SSTables进行排序。 如果它们太多,那么简单的排序过程就会花费太多时间,并且阅读开始下降。
解决方案是压缩,这减少了这些SSTable的数量,但应注意,对于一个特定的表,它只能在一个节点上。 不幸的是,由于Cassandra是用Java编写并在JVM上运行的,因此垃圾收集器可能已经暂停了一下,以至于根本没有时间响应。 当垃圾收集器进入暂停状态时,不仅您的请求变慢,而且
节点之间的Cassandra集群内的交互也开始变慢 。 彼此的节点开始被视为已断开,即掉落,死亡。
更加有趣的情况开始了,因为当一个节点认为另一个节点已关闭时,它首先不向其发送请求,其次,它开始尝试保存需要复制到另一个节点的数据。自己在本地,所以他开始慢慢地自杀,等等。
在某些情况下,只需使用正确的设置即可解决此问题。 例如,可能有足够的资源,一切都很好,但是仅需要增加一个线程池(线程池的数量是固定大小)即可。
最后,也许我们需要限制驾驶员方面的竞争力。 有时会发生发送了太多竞争性请求的情况,并且像任何数据库一样,Cassandra无法处理这些请求,并且当响应时间呈指数增长时,问题就变得荡然无存了,而我们正努力进行越来越多的工作。
对上下文的理解
这个问题总是有一定的关联性的-集群中正在发生的事情,修复是否正在工作,在哪个节点上,在哪个键空间,在哪个表中。
例如,我们在铁方面遇到了相当荒谬的问题。 我们看到部分节点很慢。 后来发现原因是在BIOS中其处理器处于节能模式。 由于某种原因,在最初安装铁时发生了这种情况,与其他节点相比,大约使用了50%的处理器资源。
实际上,了解这样的问题可能很困难。 症状是这样-似乎节点执行了压缩,但执行速度很慢。 有时它与铁连接,有时不与铁连接,但这只是另一个Cassandra错误。
因此,监视是强制性的并且需要很多。 Cassandra中的功能越复杂,与简单的读写操作之间的距离就越远,它存在的问题就越多,并且它可以杀死具有足够数量的查询的数据库的速度越快。 因此,如果可能,不要看一些“美味”的芯片并尝试使用它们,最好尽可能避免使用它们。 并非总是可能-当然,迟早有必要。

最新的故事是关于Cassandra如何弄乱数据的。 在这种情况下,它发生在Cassandra内部。 那很有趣。
我们大约每周一次在数据库中看到数十条损坏的行出现-它们实际上被垃圾堵塞了。 此外,Cassandra会验证输入到她的数据。 例如,如果它是一个字符串,则应在utf8中。 但是在这些行中是垃圾,而不是utf8,而Cassandra甚至与它无关。 当我尝试删除(或执行其他操作)时,无法删除不是utf8的值,因为尤其是我不能在WHERE中输入该值,因为密钥必须为utf8。
变质的线条在某些时候出现,像是闪光灯,然后又消失了几天或几周。
我们开始寻找问题。 我们以为可能是某个特定节点出现了问题,例如我们正在处理,对数据进行某些操作,复制SSTables。 也许一样,您可以看到这些数据的副本吗? 也许这些副本有一个公共节点,最小的公共因子? 也许某些节点崩溃了? 不,不是那样的。
也许有磁盘的东西? 磁盘上的数据是否损坏? 再没有
也许是回忆? 不行 散布在群集中。
也许这是某种复制问题? 一个节点破坏了一切,并进一步复制了一个坏值? -不
最后,也许这是一个应用程序问题?
而且,在某些时候,受损的线开始出现在两个卡桑德拉星团中。 一个使用2.1版,第二个使用第三版。 看起来Cassandra有所不同,但问题是相同的。 也许我们的服务发送了错误的数据? 但是很难相信。 Cassandra验证输入数据;它无法写入垃圾。 但是突然之间?
什么都不适合。
发现了针!
我们经过艰苦的努力,直到发现一个小问题:为什么我们在我们不太关注的节点上从JVM进行了某种故障转储? 并以某种方式在堆栈跟踪垃圾收集器中看起来可疑...由于某种原因,某些堆栈跟踪也被垃圾阻塞。
最后,我们意识到-哦,
由于某种原因,我们使用的是旧版本2015的JVM 。 这是将Cassandra集群组合在不同版本的Cassandra上的唯一常见现象。
我仍然不知道问题出在哪里,因为在JVM的正式发行说明中没有对此进行任何编写。 但是更新后,一切都消失了,问题不再出现。 而且,尽管从一开始它就不会在集群中发生,而是从某个时候开始,尽管它在同一个JVM上运行了很长时间。
数据恢复
我们从中学到了什么:
●备份无用。
我们发现,数据在记录的第二秒就被破坏了。 当数据进入协调器时,它们已经被破坏。
●可以部分恢复未损坏的色谱柱。
有些列没有损坏,我们可以读取此数据,部分还原它。
●最后,我们必须从各种来源进行恢复。
我们在对象中有备份元数据,但是在数据本身中。 为了重新连接对象,我们使用了日志等。
●原木无价!
我们能够恢复所有损坏的数据,但是最后,即使数据库丢失了数据,即使您没有采取任何行动,也很难信任该数据库。
解决方案
- 经过大量测试后更新JVM。
- JVM崩溃监视。
- 拥有独立于Cassandra的数据副本。
提示:尝试获取某种独立于Cassandra的数据副本,如有必要,可以从中进行恢复。 这可能是最后一个解决方案。 让它花费大量时间和资源,但是应该有一些选项可以让您返回数据。
虫子
●
发布测试质量不佳当您开始使用Cassandra时,会产生一种持续的感觉(尤其是相对而言,是从“好的”数据库(例如PostgreSQL)迁移过来的),如果您修复了前一个版本中的错误,则肯定会添加一个新的错误。 该错误并非是胡说八道,它通常是数据损坏或其他不正确的行为。
●
具有复杂功能的持久性问题功能越复杂,使用它的问题,错误等就越多。
●
不要在2.1中使用增量修复我谈论过的著名修复是在标准模式下轮询所有节点时修复数据一致性,效果很好。 但是不是所谓的增量模式(当修复跳过自上次修复以来未更改的数据时,这是很合逻辑的)。 它是很久以前正式宣布的一项功能,但是所有人都说:“不,在2.1版中,永远不要使用它! 他一定会想念的。 在3中,我们对其进行了修复。”
●
但不要在3.x中使用增量修复当第三个版本问世时,几天后他们说:“不,您不能在第三个版本中使用它。 这里列出了15个错误,因此在任何情况下都不要使用增量修复。 第四届我们会做得更好!”
我不相信他们。 这是一个大问题,尤其是随着群集大小的增加。 因此,您需要不断监视他们的bugtracker并查看会发生什么。 不幸的是,没有他们就不可能与他们生活在一起。
●
需要跟踪JIRA
如果您将所有数据库分散在可预测性范围内,那么对我来说,Cassandra在红色区域的左侧。 这并不意味着它不好,您只需要为Cassandra在任何意义上都是不可预测的事实做好准备:无论是在它的工作方式上还是在某些事情可能发生的事实上。

我希望您能找到其他耙子并继续前进,因为从我的角度来看,无论如何,卡桑德拉都是好人,当然也不会感到无聊。 只要记住路上的颠簸!
HighLoad ++活动家公开会议
7月31日,在莫斯科的19:00,将举行演讲者,程序委员会和高负载系统HighLoad ++ 2018开发人员会议的活动家会议。我们将就今年的计划组织一次小型头脑风暴会议,以免错过任何新的重要内容。 会议是开放的,但您需要注册 。
征集论文
在Highload ++ 2018上积极接受报告的申请。程序委员会正在等待您的摘要,直到夏天结束。