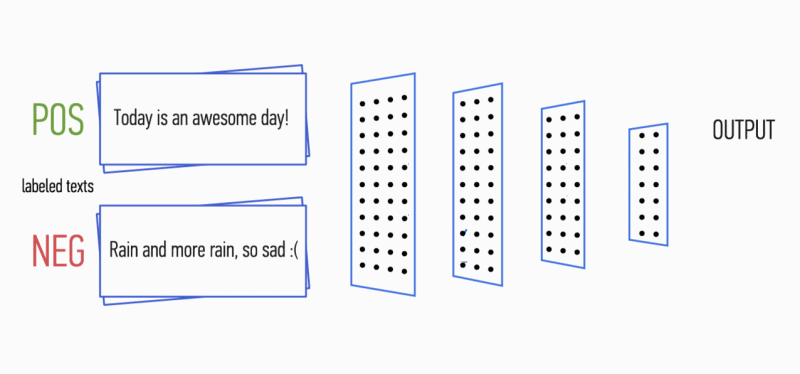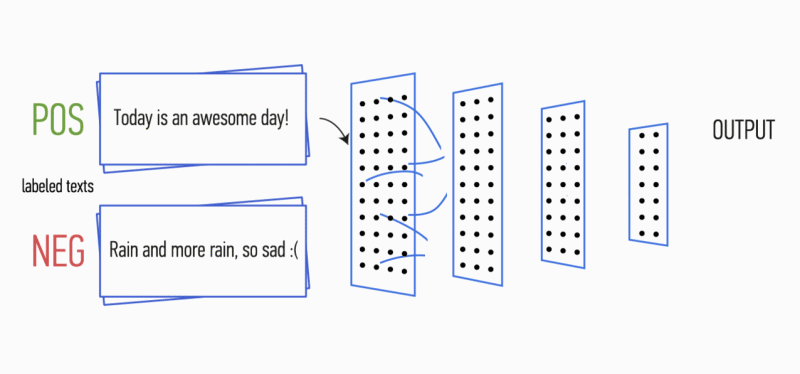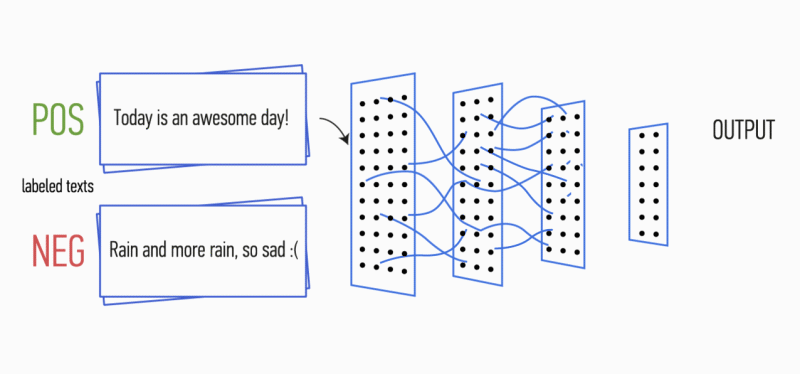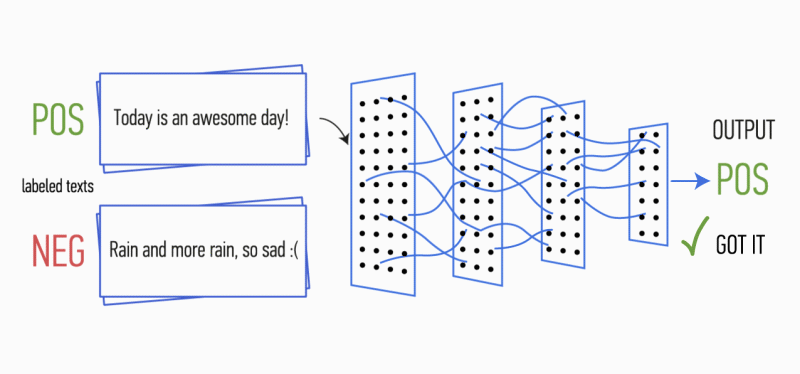
假设您有一段文字。 是否有可能理解这段文字所带来的情感:喜悦,悲伤,愤怒? 可以的 我们简化了任务,并且将情感分类为正面或负面,没有具体说明。 解决此问题的方法有很多,其中一种是
卷积神经网络 (Convolutional Neural Networks)。 CNN最初是为图像处理而开发的,但是它们成功地处理了自动文字处理领域的任务。 我将向您介绍使用卷积神经网络对俄语语言的语调进行二进制分析的过程,其中,单词的矢量表示是在经过训练的
Word2Vec模型的基础上形成的。
本文具有概述性,我强调了实际内容。 我想立即警告您,在每个阶段做出的决定可能都不是最佳选择。 在阅读之前,我建议您熟悉有关在自然语言处理任务中使用CNN的
介绍性文章 ,并阅读有关单词矢量表示方法的
材料 。
建筑学
正在考虑的CNN架构基于方法[1]和[2]。 方法[1]使用卷积和递归网络的合奏,在计算机语言学的年度年度竞赛中,SemEval-2017在分析声调的任务5项提名中获得第一名[3]。
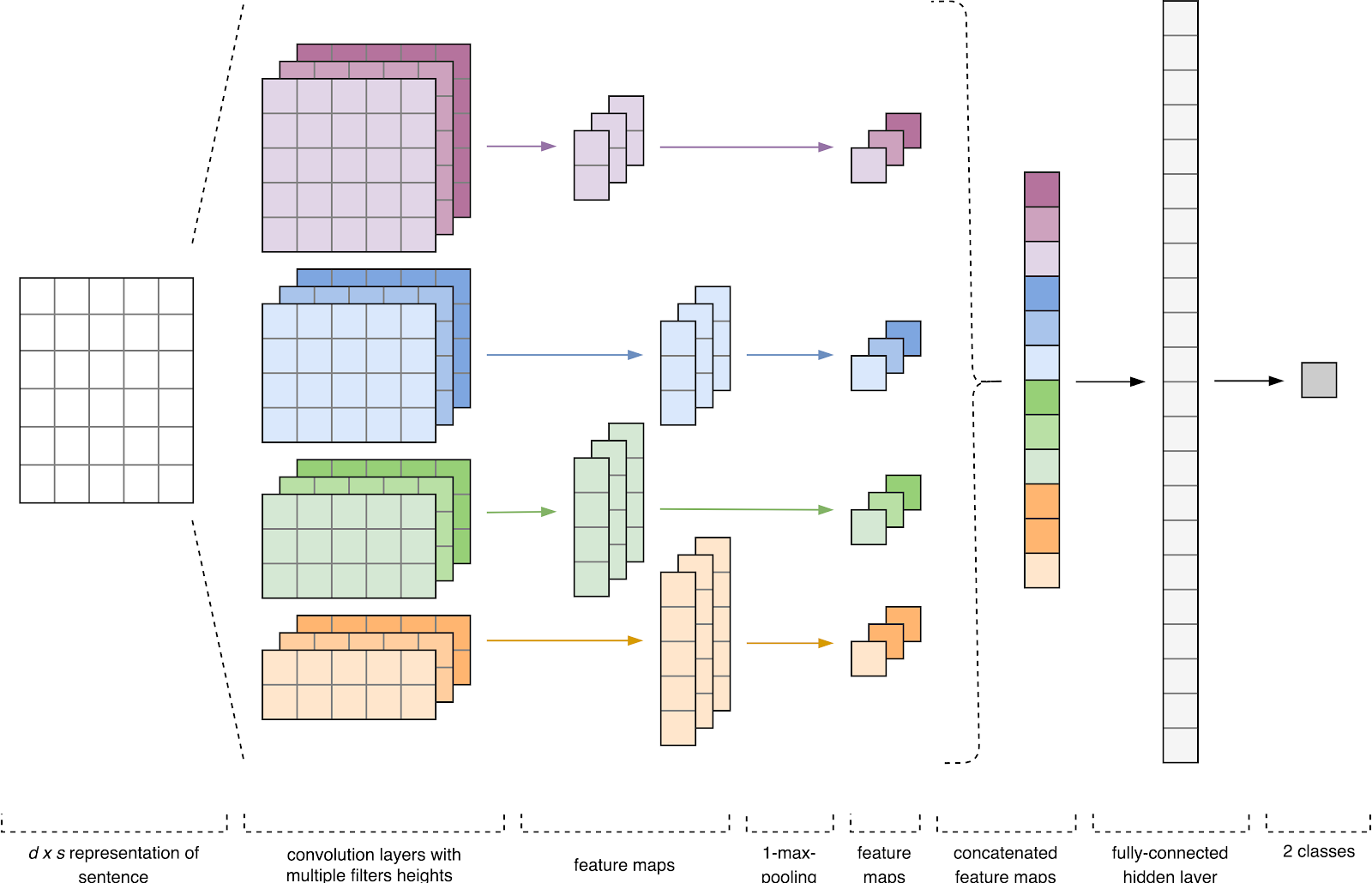 图1. CNN架构[2]。
图1. CNN架构[2]。CNN输入(图1)是一个具有固定高度
n的矩阵,其中每一行是令牌到维数
k的特征空间中的矢量映射。 诸如Word2Vec,Glove,FastText等分布式语义工具通常用于形成特征空间。
在第一阶段,输入矩阵由卷积层处理。 通常,过滤器的宽度等于属性空间的尺寸,并且只有一个参数配置为过滤器尺寸-height
h 。 事实证明,
h是过滤器一起考虑的相邻线的高度。 因此,每个滤波器的输出特征矩阵的尺寸根据该滤波器的高度
h和原始矩阵
n的高度而变化。
接下来,在每个滤波器的输出处获得的特征图由具有特定压缩功能(图像中的1-max合并)的子采样层进行处理,即 减小生成的特征图的尺寸。 因此,无论每个卷积在文本中的位置如何,都将提取最重要的信息。 换句话说,对于所使用的矢量显示,卷积层和子采样层的组合使得可以从文本中提取最高有效的
n- g。
此后,将在每个子采样层的输出处计算出的特征图组合为一个公共特征向量。 它被馈送到隐藏的,完全连接的层的输入,然后馈送到神经网络的输出层,在该层中计算最终的类别标签。
训练数据
为了进行培训,我选择了
尤莉亚·鲁布佐娃(Yulia Rubtsova)的短文本语料库,该
语料库是基于Twitter的俄语消息而形成的[4]。 它包含114 991条正面推文,111 923条负面推文以及未分配的推文库,其消息量为17 639 674条。
import pandas as pd import numpy as np
培训之前,课文通过了初步处理:
- 转换为小写;
- 用“ e”代替“ e”;
- 替换指向“ URL”令牌的链接;
- 用USER令牌替换用户的提及;
- 删除标点符号。
import re def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
接下来,我将数据集以4:1的比例分为训练样本和测试样本。
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=1)
单词的矢量显示
卷积神经网络的输入数据是高度固定为
n的矩阵,其中每一行都是一个单词到维数为
k的特征空间中的向量映射。 为了形成神经网络的嵌入层,我使用了Word2Vec [5]分布式语义实用程序,该实用程序旨在将单词的语义映射到向量空间中。 Word2Vec通过假设在相似的上下文中发现了语义相关的单词来查找单词之间的关系。 您可以在
原始文章以及
此处和
此处阅读有关Word2Vec的更多信息。 由于推文具有作者标点符号和表情符号的特征,因此定义句子的边界变得相当耗时。 在这项工作中,我假设每条推文仅包含一个句子。
未分配推文的基础以SQL格式存储,并包含超过1750万条记录。 为了方便起见,我使用
此脚本将其转换为SQLite。
import sqlite3
然后,使用Gensim库,我使用以下参数训练了Word2Vec模型:
- size = 200-属性空间的尺寸;
- window = 5-算法分析的上下文中的单词数;
- min_count = 3-该单词必须至少出现3次,以便模型将其考虑在内。
import logging import multiprocessing import gensim from gensim.models import Word2Vec logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
 图2.使用t-SNE可视化相似词簇。
图2.使用t-SNE可视化相似词簇。为了更详细地了解图2中Word2Vec的操作。
图 2显示了来自训练模型的相似词的几个聚类的可视化,并使用
t-SNE可视化算法映射到二维空间中。
文本的矢量显示
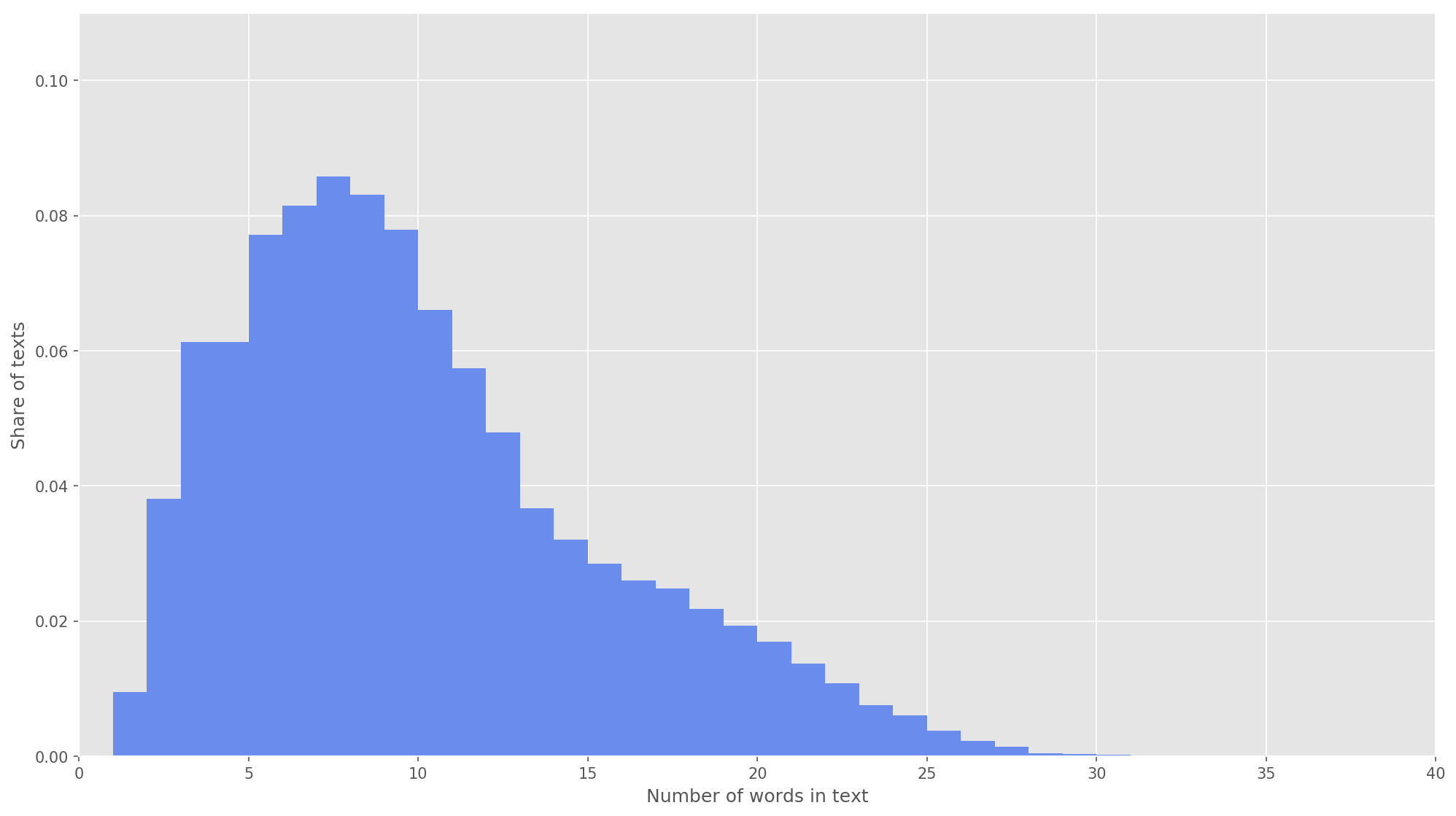 图3.文本长度的分布。
图3.文本长度的分布。在下一步中,每个文本都映射到令牌标识符数组。 我选择文本向量
的维数
s = 26 ,因为在该值下,成形主体中所有文本的99.71%被完全覆盖(图3)。 如果在分析过程中,推文中的单词数超过了矩阵的高度,则剩余的单词将被丢弃,并且在分类中不予考虑。 提案矩阵的最终尺寸为
s×d = 26×200 。
from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences
卷积神经网络
为了构建神经网络,我使用了Keras库,该库充当TensorFlow,CNTK和Theano的高级附加组件。 Keras提供了出色的文档,以及一个涵盖许多机器学习任务(例如
初始化嵌入层)的博客。 在我们的案例中,嵌入层是通过学习Word2Vec获得的权重而启动的。 为了最大程度地减少嵌入层中的更改,我在训练的第一阶段将其冻结。
from keras.layers import Input from keras.layers.embeddings import Embedding tweet_input = Input(shape=(SENTENCE_LENGTH,), dtype='int32') tweet_encoder = Embedding(NUM, DIM, input_length=SENTENCE_LENGTH, weights=[embedding_matrix], trainable=False)(tweet_input)
在已开发的体系结构中,使用了高度为
h =( 2、3、4、5)的过滤器,它们分别用于并行处理双字母组,三字母组,4克和5克。 在每个神经网络中为每个滤波器高度添加10个卷积层,其激活函数为ReLU。 寻找最佳高度和过滤器数量的建议可以在[2]中找到。
经过卷积层处理后,属性映射被馈送到子采样层,在其中进行了1-max-pooling操作,从而从文本中提取了最重要的n-gram。 在下一阶段,它们合并为一个公共特征向量(合并层),该向量被馈送到具有30个神经元的隐藏的完全连接层中。 在最后阶段,将最终的特征图通过S型激活函数馈送到神经网络的输出层。
由于神经网络易于重新训练,因此在嵌入层之后和隐藏的完全连接层之前,我添加了一个辍学正则化,其顶点弹出概率为p = 0.2。
from keras import optimizers from keras.layers import Dense, concatenate, Activation, Dropout from keras.models import Model from keras.layers.convolutional import Conv1D from keras.layers.pooling import GlobalMaxPooling1D branches = []
我使用Adam优化函数(自适应矩估计)和作为误差函数的二进制交叉熵来配置最终模型。 分类器的质量根据宏观平均的准确性,完整性和f度量进行评估。
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[precision, recall, f1]) model.summary()
在训练的第一阶段,将嵌入层冻结,将所有其他层训练10个时代:
- 用于训练的示例组的大小为32。
- 验证样本的大小:25%。
from keras.callbacks import ModelCheckpoint checkpoint = ModelCheckpoint("models/cnn/cnn-frozen-embeddings-{epoch:02d}-{val_f1:.2f}.hdf5", monitor='val_f1', save_best_only=True, mode='max', period=1) history = model.fit(x_train_seq, y_train, batch_size=32, epochs=10, validation_split=0.25, callbacks = [checkpoint])
日志Train on 134307 samples, validate on 44769 samples
Epoch 1/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.5703 - precision: 0.7006 - recall: 0.6854 - f1: 0.6839 - val_loss: 0.5014 - val_precision: 0.7538 - val_recall: 0.7493 - val_f1: 0.7452
Epoch 2/10
134307/134307 [==============================] - 218s 2ms/step - loss: 0.5157 - precision: 0.7422 - recall: 0.7258 - f1: 0.7263 - val_loss: 0.4911 - val_precision: 0.7413 - val_recall: 0.7924 - val_f1: 0.7602
Epoch 3/10
134307/134307 [==============================] - 213s 2ms/step - loss: 0.5023 - precision: 0.7502 - recall: 0.7337 - f1: 0.7346 - val_loss: 0.4825 - val_precision: 0.7750 - val_recall: 0.7411 - val_f1: 0.7512
Epoch 4/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4956 - precision: 0.7545 - recall: 0.7412 - f1: 0.7407 - val_loss: 0.4747 - val_precision: 0.7696 - val_recall: 0.7590 - val_f1: 0.7584
Epoch 5/10
134307/134307 [==============================] - 229s 2ms/step - loss: 0.4891 - precision: 0.7587 - recall: 0.7492 - f1: 0.7473 - val_loss: 0.4781 - val_precision: 0.8014 - val_recall: 0.7004 - val_f1: 0.7409
Epoch 6/10
134307/134307 [==============================] - 217s 2ms/step - loss: 0.4830 - precision: 0.7620 - recall: 0.7566 - f1: 0.7525 - val_loss: 0.4749 - val_precision: 0.7877 - val_recall: 0.7411 - val_f1: 0.7576
Epoch 7/10
134307/134307 [==============================] - 219s 2ms/step - loss: 0.4802 - precision: 0.7632 - recall: 0.7568 - f1: 0.7532 - val_loss: 0.4730 - val_precision: 0.7969 - val_recall: 0.7241 - val_f1: 0.7522
Epoch 8/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4769 - precision: 0.7644 - recall: 0.7605 - f1: 0.7558 - val_loss: 0.4680 - val_precision: 0.7829 - val_recall: 0.7542 - val_f1: 0.7619
Epoch 9/10
134307/134307 [==============================] - 227s 2ms/step - loss: 0.4741 - precision: 0.7657 - recall: 0.7663 - f1: 0.7598 - val_loss: 0.4672 - val_precision: 0.7695 - val_recall: 0.7784 - val_f1: 0.7682
Epoch 10/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.4727 - precision: 0.7670 - recall: 0.7647 - f1: 0.7590 - val_loss: 0.4673 - val_precision: 0.7833 - val_recall: 0.7561 - val_f1: 0.7636
然后他选择了验证数据集上F值最高的模型,即 在第八个教育阶段获得的模型(F
1 = 0.7791)。 该模型解冻了嵌入层,此后又启动了五个训练时代。
from keras import optimizers
日志Train on 134307 samples, validate on 44769 samples
Epoch 1/5
134307/134307 [==============================] - 2042s 15ms/step - loss: 0.4495 - precision: 0.7806 - recall: 0.7797 - f1: 0.7743 - val_loss: 0.4560 - val_precision: 0.7858 - val_recall: 0.7671 - val_f1: 0.7705
Epoch 2/5
134307/134307 [==============================] - 2253s 17ms/step - loss: 0.4432 - precision: 0.7857 - recall: 0.7842 - f1: 0.7794 - val_loss: 0.4543 - val_precision: 0.7923 - val_recall: 0.7572 - val_f1: 0.7683
Epoch 3/5
134307/134307 [==============================] - 2018s 15ms/step - loss: 0.4372 - precision: 0.7899 - recall: 0.7879 - f1: 0.7832 - val_loss: 0.4519 - val_precision: 0.7805 - val_recall: 0.7838 - val_f1: 0.7767
Epoch 4/5
134307/134307 [==============================] - 1901s 14ms/step - loss: 0.4324 - precision: 0.7943 - recall: 0.7904 - f1: 0.7869 - val_loss: 0.4504 - val_precision: 0.7825 - val_recall: 0.7808 - val_f1: 0.7762
Epoch 5/5
134307/134307 [==============================] - 1924s 14ms/step - loss: 0.4256 - precision: 0.7986 - recall: 0.7947 - f1: 0.7913 - val_loss: 0.4497 - val_precision: 0.7989 - val_recall: 0.7549 - val_f1: 0.7703
验证样本中的最高指标
F 1 = 76.80%是在训练的第三个时代实现的。 测试数据上训练模型的质量为
F 1 = 78.1% 。
表1.对测试数据的情感分析的质量。
结果
作为基准解决方案,我用多项分布模型
训练了朴素的贝叶斯分类器,比较结果列在表中。 2。
表2.音调分析质量的比较。
如您所见,CNN分类的质量比MNB高出几个百分点。 如果您致力于优化超参数和网络体系结构,则可以进一步提高指标值。 例如,您可以更改训练时代的次数,检查使用单词及其组合的各种矢量表示的效果,选择过滤器的数量及其高度,实施更有效的文本预处理(错字校正,归一化,标记),调整其中隐藏的完全连接层和神经元的数量。
Github上提供了源代码,可以在
此处下载经过训练的CNN和Word2Vec模型。
资料来源
- Cliche M.BB_twtr在SemEval-2017上的任务4:Twitter与CNN和LSTM的情感分析//第11届国际语义评估研讨会(SemEval-2017)的会议记录。 -2017年-S.573-580。
- Zhang Y.,Wallace B.对卷积神经网络进行句子分类的敏感性分析(和从业人员指南)// arXiv预印本arXiv:1510.03820。 -2015年
- Rosenthal S.,Farra N.,Nakov P.SemEval-2017任务4:Twitter中的情感分析//第11届国际语义评估研讨会(SemEval-2017)的会议记录。 -2017年-S.502-518。
- Yu。V. Rubtsova。 构建用于设置音调分类器的文本正文//软件产品和系统,2015年,第1号(109),-C.72-78。
- Mikolov T.等。 单词和短语的分布式表示及其组成//神经信息处理系统的进展。 -2013 .-- S.3111-3119。