在上一篇文章“
用于图像分类的神经网络概述”中 ,我们熟悉了卷积神经网络的基本概念以及基本思想。 在本文中,我们将研究一些具有强大处理能力的深度神经网络架构,例如AlexNet,ZFNet,VGG,GoogLeNet和ResNet,并总结每种架构的主要优势。 本文的结构基于博客条目
“卷积神经网络的基本概念”,第3部分 。
当前,
ImageNet挑战是机器识别系统和图像分类开发背后的主要诱因。 该活动是一项处理数据的竞赛,其中为参与者提供了大量数据(超过一百万张图像)。 竞赛的任务是开发一种算法,该算法使您可以将所需图像分类为1000种类别的对象(例如狗,猫,汽车和其他物体),并且错误的数量最少。
根据比赛的正式规则,算法必须为每个类别的图像提供不超过五个类别的对象列表,并以置信度降序排列。 根据与图像的地面真实属性最匹配的标签评估图像标记质量。 这个想法是让算法能够识别图像中的多个对象,并且在检测到的任何对象实际存在于图像中但不包含在地面真实属性中的情况下,不计入罚分。
在竞赛的第一年,为参与者提供了用于训练模型的预选图像属性。 例如,这些可能是使用矢量量化处理过的
SIFT算法的标志,适用于单词袋方法或表示为空间金字塔。 但是,在2012年,该领域取得了真正的突破:多伦多大学的一组科学家证明,与基于先前选择的图像属性的矢量建立的传统机器学习模型相比,深度神经网络可以显着提高结果。 在以下各节中,将考虑2012年提出的第一个创新架构以及在2015年之前一直遵循的架构。
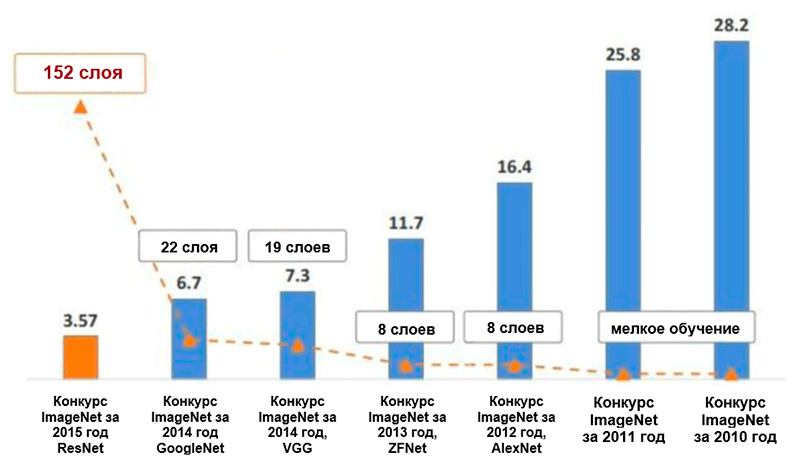 五个主要类别的ImageNet *图像分类中的错误数量(百分比)的变化图。 图片取自Kaiming He的演讲: 深度残差学习以进行图像识别
五个主要类别的ImageNet *图像分类中的错误数量(百分比)的变化图。 图片取自Kaiming He的演讲: 深度残差学习以进行图像识别亚历克斯网
多伦多大学的一组科学家(A. Krizhevsky,I。Sutskever和J. Hinton)于2012年提出了
AlexNet体系结构。 这是一项创新性的工作,其中作者首次(当时)使用了深度卷积神经网络,其总深度为八层(五层卷积层和三层完全连接层)。
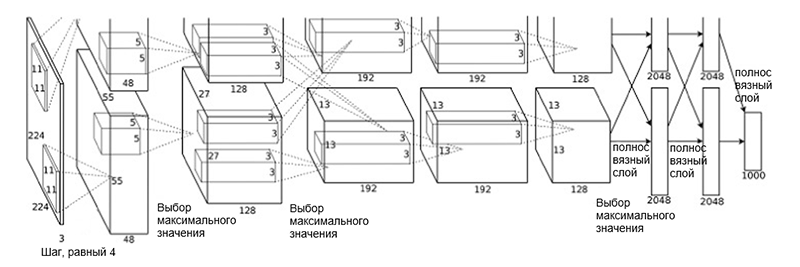 架构AlexNet
架构AlexNet网络体系结构包括以下几层:
- [卷积层+最大值选择+归一化] x 2
- [卷积层] x 3
- [选择最大值]
- [全层] x 3
这样的方案可能看起来有些奇怪,因为学习过程由于其高计算复杂性而被划分在两个GPU之间。 GPU之间的这种工作分离要求将模型手动分离为相互交互的垂直块。
AlexNet的体系结构已将五个主要类别的错误数量减少到16.4%,几乎是以前的高级开发的一半! 在该架构的框架内还引入了一种激活功能,例如线性整流单元(
ReLU ),这是目前的行业标准。 以下是AlexNet体系结构的其他主要功能及其学习过程的简要概述:
- 密集数据扩充
- 排除方法
- 使用SGD矩进行优化(请参阅优化指南“梯度下降优化算法概述”)
- 手动调整学习速度(将该系数降低10并保持准确性)
- 最终模型是七个卷积神经网络的集合
- 培训是在两个NVIDIA * GeForce GTX * 580图形处理器上进行的,每个图形处理器上总共有3 GB的视频内存。
Zfnet
纽约大学的研究人员
M.Zeiler和R.Fergus提出的
ZFNet网络架构几乎与AlexNet架构相同。 它们之间的唯一重要区别如下:
- 第一卷积层中的过滤器大小和步长(在AlexNet中,过滤器大小为11×11,步长为4;在ZFNet中,过滤器大小为7×7和2)
- 干净的卷积层(3、4、5)中的过滤器数。
 ZFNet架构
ZFNet架构借助ZFNet架构,五个主要类别的错误数量下降到11.4%。 也许其中的主要作用是对超参数(过滤器的大小和数量,包大小,学习速度等)的精确调整。 但是,ZFNet体系结构的思想也可能对卷积神经网络的发展做出了非常重要的贡献。 齐勒和弗格斯(Ziller and Fergus)提出了一种可视化核心,重量和图像隐藏视图的系统,称为DeconvNet。 多亏了她,对卷积神经网络的更好理解和进一步发展成为可能。
VGG网
2014年,牛津大学的K. Simonyan和E. Zisserman提出了一种名为
VGG的架构。 这种结构的主要和独特的想法是
使过滤器尽可能简单 。 因此,使用大小为3的滤波器和1的步长执行所有卷积运算,并且使用大小为2的滤波器和2的步长执行所有子采样操作。但是,这还不是全部。 除了卷积模块的简单性,网络的深度已显着增长-现在已达到19层! 在这项工作中首先提出的最重要的想法是
施加卷积层而没有子采样层 。 潜在的想法是,这样的覆盖层仍然提供足够大的接收场(例如,3个3×3大小的叠加的卷积层(以1为步长)的接收场类似于一个7×7的卷积层),但是,参数的数量明显少于带有大型过滤器(用作正则化器)的网络。 另外,可以引入附加的非线性变换。
本质上,作者已经证明,即使使用非常简单的构建基块,您也可以在ImageNet竞赛中获得出色的质量结果。 五个主要类别的错误数量减少到7.3%。
 VGG架构。 请注意,滤镜的数量与图像的空间大小成反比。
VGG架构。 请注意,滤镜的数量与图像的空间大小成反比。谷歌网
以前,体系结构的整个发展都是为了简化过滤器并增加网络深度。 2014年,C。Szegedy与其他参与者提出了一种完全不同的方法,并创建了当时最复杂的架构GoogLeNet。
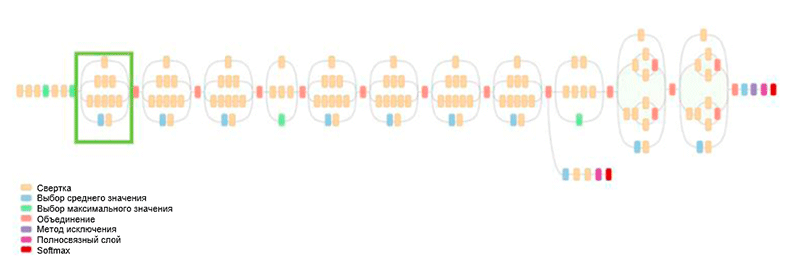 GoogLeNet体系结构。 它使用了Inception模块,在图中以绿色突出显示。 网络构建基于这些模块
GoogLeNet体系结构。 它使用了Inception模块,在图中以绿色突出显示。 网络构建基于这些模块这项工作的主要成就之一就是所谓的Inception模块,如下图所示。 其他体系结构的网络逐层依次处理输入数据,而使用Inception模块时,
并行处理输入数据 。 这样可以加快输出速度,并最大程度减少
参数总数 。
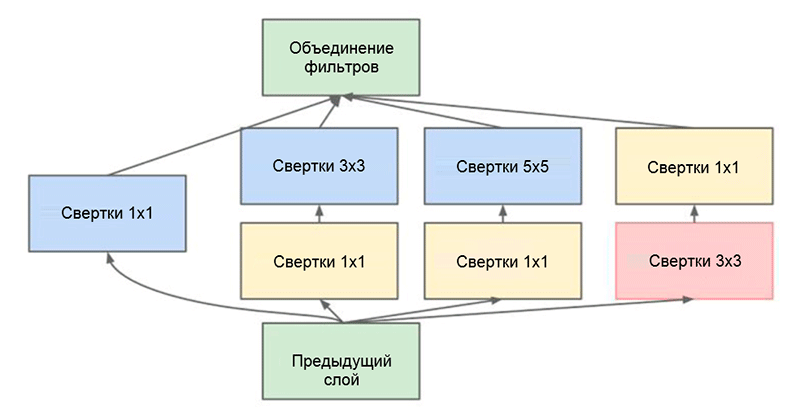 初始模块。 请注意,该模块使用多个并行分支,这些分支根据相同的输入数据计算不同的属性,然后将结果合并
初始模块。 请注意,该模块使用多个并行分支,这些分支根据相同的输入数据计算不同的属性,然后将结果合并在Inception模块中使用的另一个有趣的技巧是使用大小为1×1的卷积层,这似乎毫无意义,直到我们回想起滤镜覆盖深度的整个维度这一事实。 因此,1×1卷积是减小属性映射维的简单方法。 这种卷积层首先
由 M. Lin等人在
Network中提出,也可以在博客文章
卷积[1×1]中找到全面而易于理解的解释
-与 A. Prakash的
直觉相反 。
最终,该体系结构将五个主要类别的错误数量又降低了一半,降至6.7%。
Resnet
2015年,来自Microsoft Research Asia的一组研究人员(Cuming Hee等人)提出了一个想法,该想法目前被大多数社区认为是深度学习发展中最重要的阶段之一。
深度神经网络的主要问题之一是梯度消失的问题。 简而言之,这是将误差反向传播方法用于梯度计算算法时出现的技术问题。 处理错误的反向传播时,将使用链规则。 此外,如果梯度在网络末端具有较小的值,则在到达网络起点时可以取无限小的值。 这可能会导致性质完全不同的问题,包括原则上不可能学习网络(有关更多信息,请参阅R. Kapur的博客文章
渐变梯度问题 )。
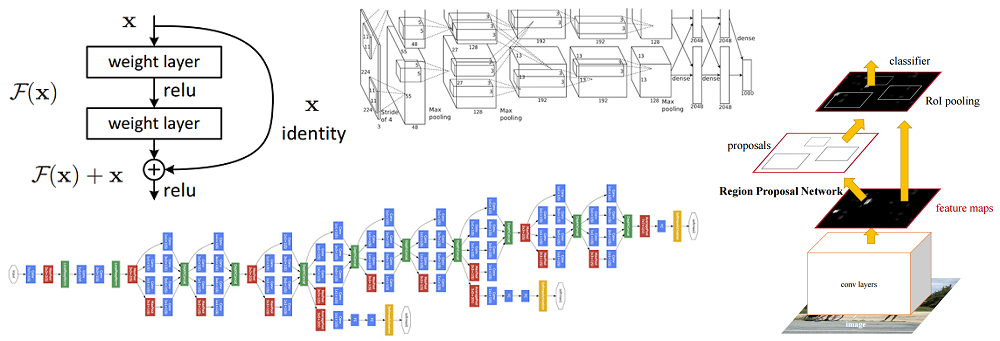
为了解决这个问题,蔡明熙及其小组提出了以下想法-允许网络研究残差映射(应添加到输入中的元素)而不是显示器本身。 从技术上讲,这是使用图中所示的旁路连接完成的。
 剩余块的示意图:输入数据通过缩短的连接传输,绕过转换层,并添加到结果中。 请注意,“相同”连接不会向网络添加其他参数,因此其结构并不复杂
剩余块的示意图:输入数据通过缩短的连接传输,绕过转换层,并添加到结果中。 请注意,“相同”连接不会向网络添加其他参数,因此其结构并不复杂这个想法非常简单,但同时非常有效。 它解决了梯度消失的问题,允许它通过“相同”的连接从上层移动到下层而没有任何变化。 由于这个想法,您可以训练非常深,非常深的网络。
在2015年赢得ImageNet挑战赛的网络包含152层(作者能够训练包含1001层的网络,但是产生的结果大致相同,因此他们停止使用它)。 此外,此想法还可以将五个领先类别的错误数从字面上减少一半-达到3.6%的值。 根据A. Karpathy
在ImageNet竞赛中通过与卷积神经网络竞争所学的知识的研究,该任务的人工绩效约为5%。 这意味着,至少在此图像分类任务中,ResNet体系结构能够超越人工结果。