
几个月以来,我们一直在收集有关人工智能的备忘录,并定期与朋友和同事共享。 最近,已经开发了一个完整的收藏集,并且我们在备忘录中添加了描述和/或引号,以使其阅读起来更加有趣。 最后,您会发现复杂度为“ O big”(Big-O)的选择。 好好享受
UPD 如果在单独的选项卡中将其打开或保存到磁盘,则许多图片将更具可读性。神经网络
 神经网络备忘录
神经网络备忘录神经网络图
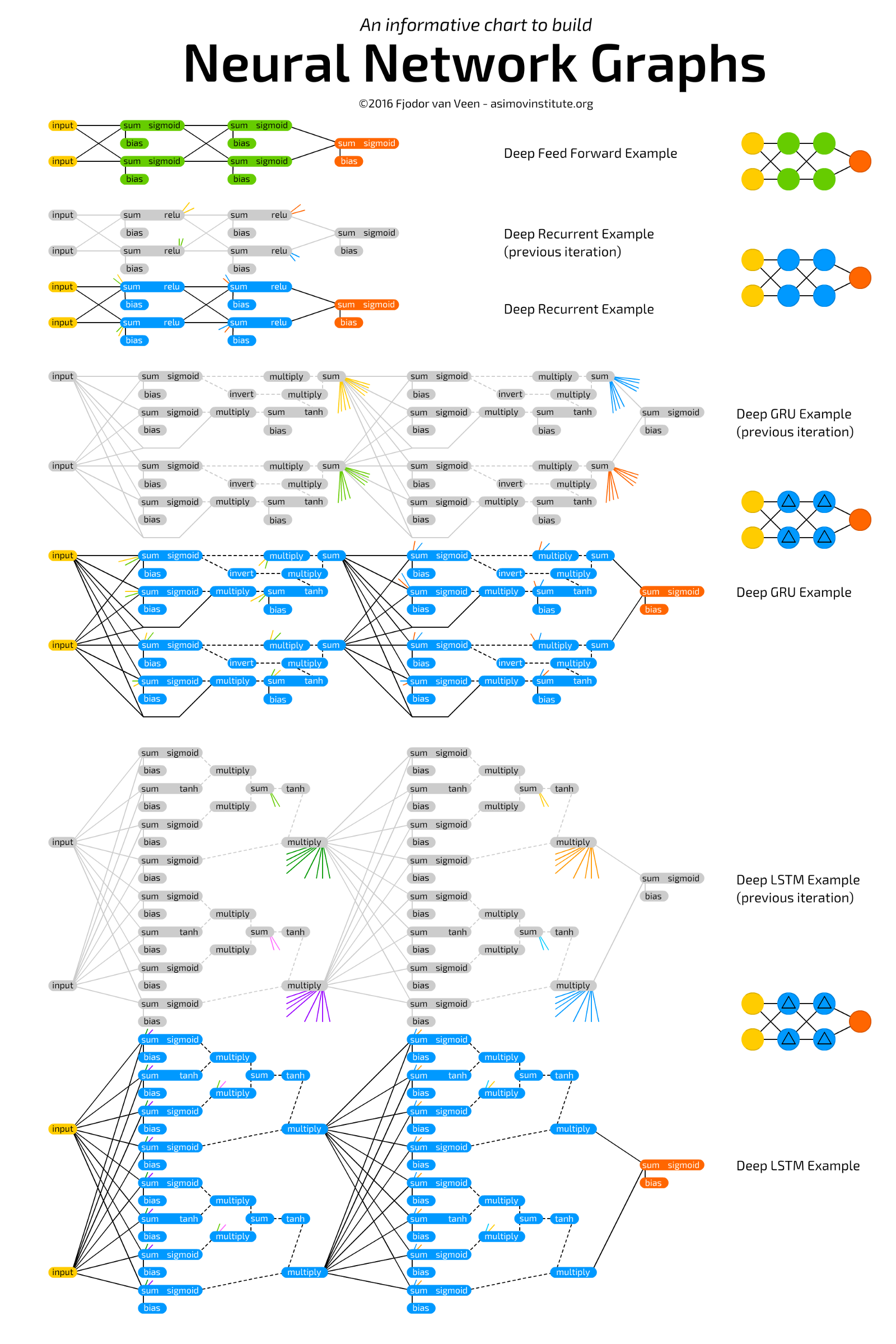 神经网络图上的备注
神经网络图上的备注 神经网络备忘录
神经网络备忘录机器学习概述
 机器学习指南
机器学习指南Scikit学习算法
本机器学习指南将帮助您找到正确的评分算法,这是工作中最困难的部分。 该流程图将帮助您检查文档并为每种算法设置一般方向。 这将帮助您更好地了解您面临的问题以及如何解决它们。
Scikit-learn (以前称为
scikits.learn )是一个免费的Python机器学习库。 它包括各种类型的
分类 ,
回归和
聚类算法 ,包括
支持向量法 ,
随机森林算法(“随机森林”),
梯度提升 ,
k-均值方法和
DBSCAN 。 Scikit-learn旨在与Python
NumPy和
SciPy计算和科学库进行交互。

 Scikit学习备忘录
Scikit学习备忘录机器学习算法指南
此Microsoft Azure备忘录将帮助您为预测分析解决方案选择正确的机器学习算法。 备忘录首先询问数据的性质,然后建议最佳算法。

数据科学用Python
 数据科学的Python备忘录
数据科学的Python备忘录 大数据备忘录
大数据备忘录张量流
2017年5月,Google宣布了第二代TPU及其在
Google Compute Engine中的可用性。 第二代TPU的性能高达180 teraflop,而64个TPU集群的性能高达11.5 petaflop。
 TensorFlow备忘录
TensorFlow备忘录凯拉斯
2017年,谷歌的TensorFlow团队决定将Keras支持集成到TensorFlow核心库中。 Chollet解释说,Keras是一个接口,而不是端到端的机器学习系统。 它提供了更高层次,更直观的抽象集,从而简化了神经网络的配置,而与后端中使用的科学计算库无关。

脾气暴躁的
NumPy用于
Cpython ,这是一个参考Python实现,是非优化字节码解释器。 为此版本的Python编写的数学算法通常比编译后的算法慢得多。 NumPy库部分地解决了由于多维数组以及针对数组工作而优化的函数和运算符带来的速度问题。 必须使用NumPy(主要是内部循环)重写部分代码。
 顽皮的备忘录
顽皮的备忘录大熊猫
“熊猫”这个名称来自计量经济学术语“
面板数据 ”,用于多维结构化数据集。
 熊猫备忘录
熊猫备忘录数据争吵
数据整理(
“放牧”数据,主要数据处理 )-这个术语开始渗透到流行文化中。 在2017年的电影《 Kong:Skull Island》中,其中一位角色是我们的数据争吵者Steve Woodward。
 数据整理备忘录
数据整理备忘录 熊猫数据整理备忘录
熊猫数据整理备忘录数据处理与dplyr和tidyr
 dplyr和tidyr的数据整理备忘录
dplyr和tidyr的数据整理备忘录 dplyr和tidyr的数据整理备忘录
dplyr和tidyr的数据整理备忘录西皮
SciPy基于NumPy数组对象。 该库是NumPy堆栈的一部分,其中包括
Matplotlib ,
Pandas和
SymPy等工具,以及一组用于科学计算的扩展库。 NumPy堆栈以及
MATLAB ,
GNU Octave和
Scilab应用程序具有相同的用户群体。 NumPy堆栈有时也称为SciPy堆栈。
 西皮备忘录
西皮备忘录Matplotlib
Matplotlib是用于Python及其计算数学扩展NumPy的图形库。 它提供了一个面向对象的API,用于使用通用GUI工具(例如
Tkinter ,
wxPython ,
Qt或
GTK +)在应用程序中嵌入图形。 还有一种基于状态机的pylab程序接口(例如OpenGL),其设计类似于
MATLAB ,尽管不建议使用它。
SciPy使用matplotlib。
Pyplot是matplotlib模块,提供了类似于MATLAB的接口。 Matplotlib的使用方式与MATLAB相同,可让您使用Python,并且免费。
 Matplotlib备忘
Matplotlib备忘数据可视化
 数据可视化备忘录
数据可视化备忘录 ggplot备忘录
ggplot备忘录皮斯帕克
 PySpark备忘录
PySpark备忘录“哦大”(Big-O)
 算法复杂度备忘
算法复杂度备忘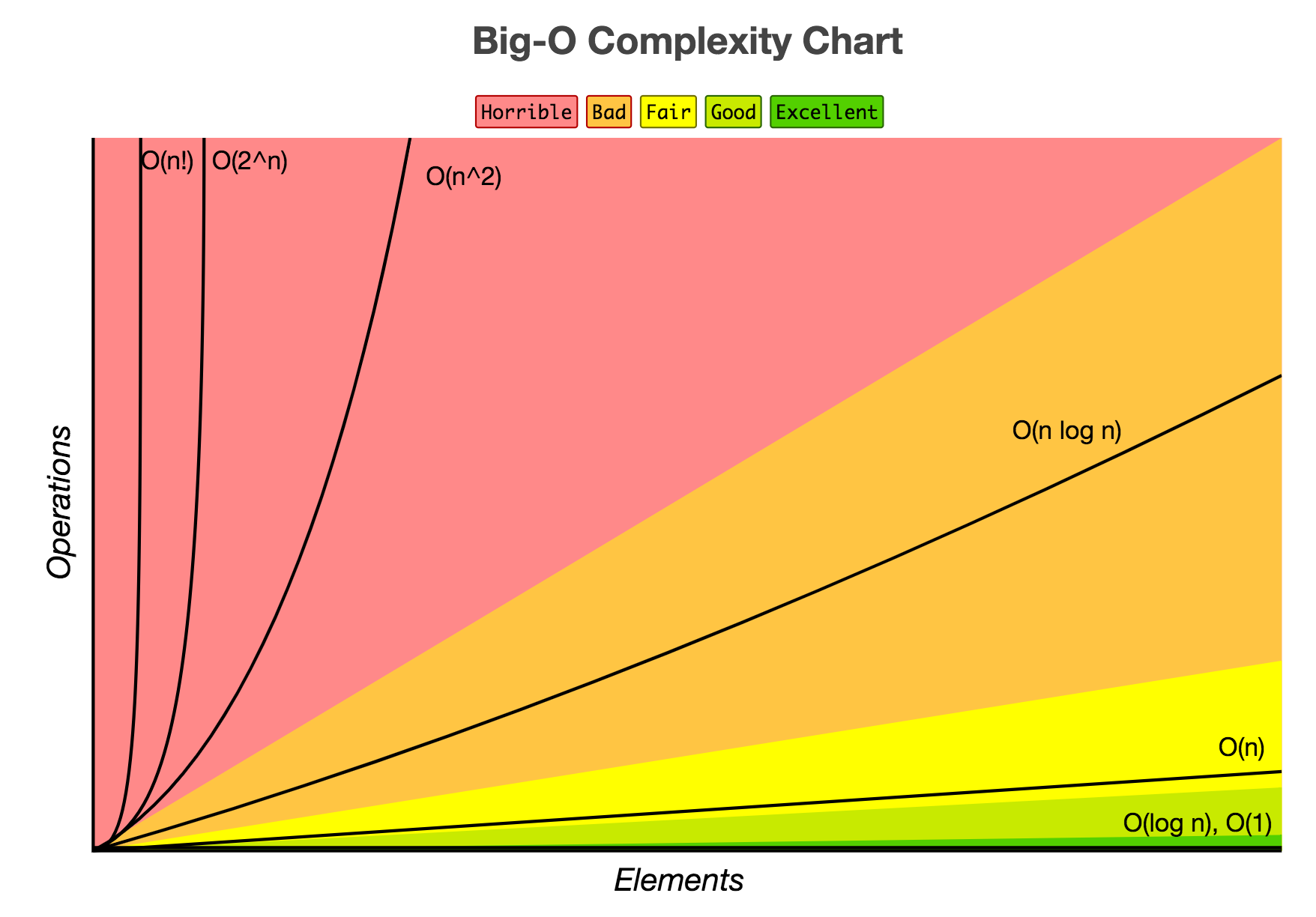 算法复杂度备忘
算法复杂度备忘 关于算法中数据结构的运算复杂性的备忘录
关于算法中数据结构的运算复杂性的备忘录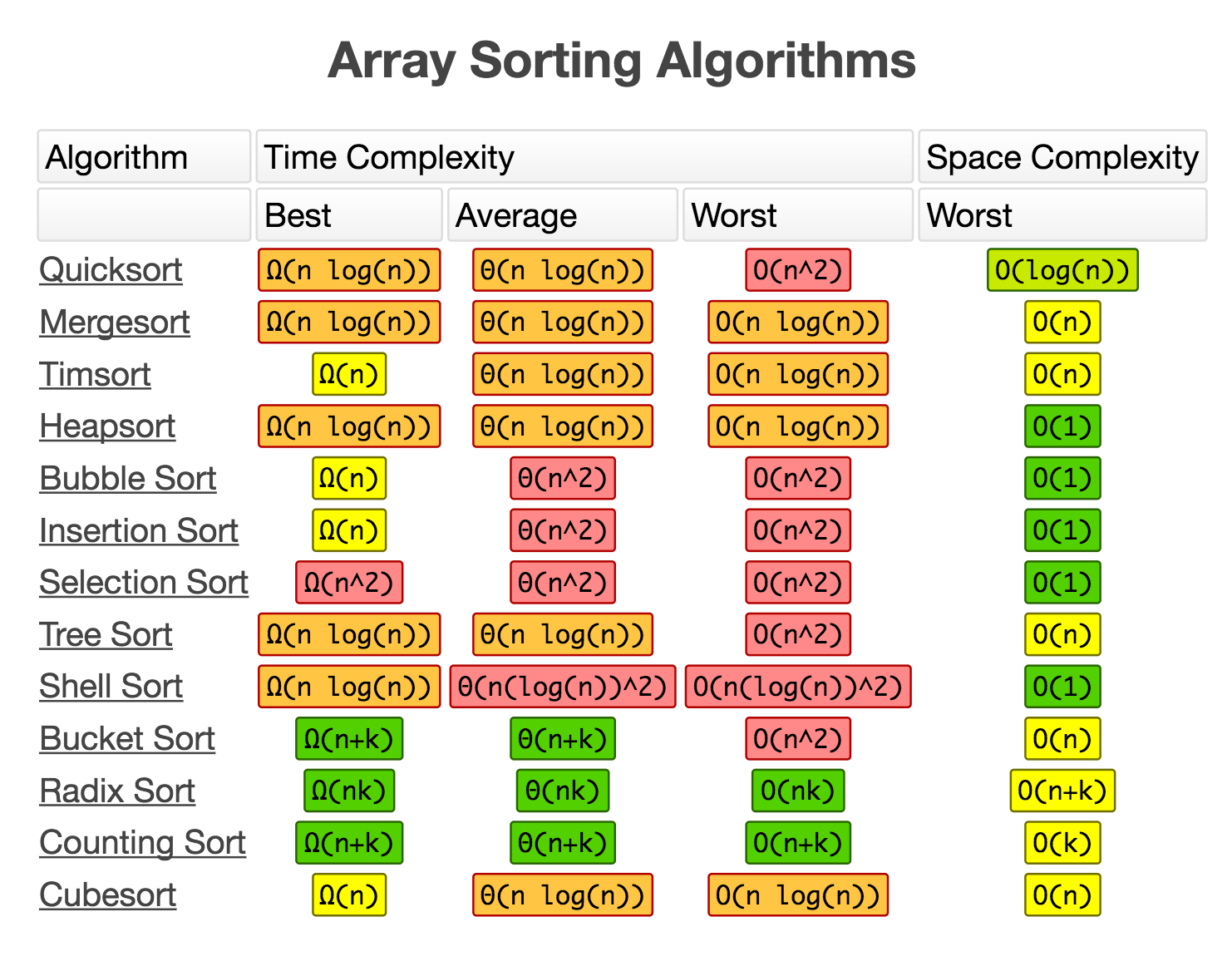 关于数组排序算法复杂性的备忘录
关于数组排序算法复杂性的备忘录资料来源
算法复杂度备忘散景备忘录数据科学备忘录数据整理备忘录Ggplot备忘录凯拉斯·莫莫机器学习指南机器学习指南机器学习指南Matplotlib备忘神经网络备忘录神经网络图上的备注神经网络顽皮的备忘录熊猫备忘录熊猫备忘录Pyspark备忘录Scikit备忘录Scikit学习备忘录西皮备忘录TensorFlow备忘录