
数据科学中的新语言。 朱莉娅是俄罗斯相当罕见的语言,尽管它在国外已经使用了5年(他们也让我感到惊讶)。 俄文没有任何资料来源,因此我决定以一本精彩的书为例,以朱莉娅为例。 学习语言的最好方法是开始用某种语言写东西。
为此也要引起注意,请使用机器学习。你好habrozhitelam。
前一段时间,我开始学习朱莉娅的新语言。 好吧,像新的一样。 这是Matlab和Python之间的语法,语法非常相似,并且语言本身是用C / C ++编写的。 通常,创建历史,内容,原因和原因在Wikipedia上,以及在Habré上的几篇文章中。
开始学习语言的第一件事-对,Coursera上的Google谷歌英语
在线课程 。 关于基本语法+,与此同时,编写了一个有关非洲疾病预测的小型项目。 立即掌握基础知识和实践。 如果您需要证书,请购买完整版本。 我免费。 此版本之间的区别在于,没有人会检查您的测试和DZ。 对我而言,结识比证书更重要。 (读卡住的50块钱)
之后,我决定读一本关于朱莉娅的书。 Google发布了书籍清单,并进一步研究了评论和评论,选择其中一本书并在亚马逊上订购。 书籍版本总是更好地阅读和用铅笔绘画。
这本书被Zacharias Voulgaris博士称为
“数据科学的
朱莉娅” 。 我要呈现的摘录在我修复的代码中包含许多错字,因此将提供工作版本+结果。
神经网络
这是分类算法在最近邻居方法中的应用示例。 可能是最古老的机器学习算法之一。 该算法没有学习阶段,非常快。 其含义非常简单:要对新对象进行分类,您需要从数据集(数据库)中找到相似的“邻居”,然后通过投票确定类。
我将立即保留Julia的现成软件包,最好使用它们来减少时间并减少错误。 但是,此代码在某种程度上表示了Julia语法。 与通过阅读函数的一般形式的摘要相比,通过示例学习一种新语言比对我来说更方便。
因此,我们在入口处拥有:
训练数据X (训练样本),
训练数据标签x (对应标签),
测试数据Y (测试选择),
邻居数k (邻居数)。
您将需要3个功能:
距离计算功能,分类功能和
main 。
底线是:取测试数组的一个元素,计算从它到训练数组的元素的距离。 然后,我们选择那些
k元素的索引,这些索引要尽可能地接近。 我们将被测元素分配给
k个最近邻居中最常见的类。
function CalculateDistance{T<:Number}(x::Array{T,1}, y::Array{T,1}) dist = 0 for i in 1:length(x) dist += (x[i] - y[i])^2 end dist = sqrt(dist) return dist end
该算法的主要功能。 训练和测试样本的对象之间的距离矩阵,训练集的标签以及最近的“邻居”数量进入输入。 输出是新对象的预测标签以及每个标签的概率。
function Classify{T<:Any}(distances::Array{Float64,1}, labels::Array{T,1}, k::Int) class = unique(labels) nc = length(class) #number of classes indexes = Array(Int,k) #initialize vector of indexes of the nearest neighbors M = typemax(typeof(distances[1])) #the largest possible number that this vector can have class_count = zeros(Int, nc) for i in 1:k indexes[i] = indmin(distances) #returns index of the minimum element in a collection distances[indexes[i]] = M #make sure this element is not selected again end klabels = labels[indexes] for i in 1:nc for j in 1:k if klabels[j] == class[i] class_count[i] +=1 end end end m, index = findmax(class_count) conf = m/k #confidence of prediction return class[index], conf end
当然,还有所有功能。
我们将在输入处有一个训练集
X ,训练集标记
x ,测试集
Y和“邻居”
数k 。
在输出中,我们将收到预测的标签以及每个班级获奖的相应概率。
function main{T1<:Number, T2<:Any}(X::Array{T1,2}, x::Array{T2,1}, Y::Array{T1,2}, k::Int) N = size(X,1) n = size(Y,1) D = Array(Float64,N) #initialize distance matrix z = Array(eltype(x),n) #initialize labels vector c = Array(Float64, n) #confidence of prediction for i in 1:n for j in 1:N D[j] = CalculateDistance(X[j,:], vec(Y[i,:])) end z[i], c[i] = Classify(D,x,k) end return z, c end
测试中
让我们测试一下我们得到了什么。 为了方便起见,我们将算法保存在文件kNN.jl中。
该基础是从
开放式机器学习课程中借用的。 该数据集称为三星人类活动识别。 数据来自三星Galaxy S3手机的加速度计和陀螺仪,人们还知道口袋里拿着手机的人的活动类型-他走路,站立,躺下,坐下还是上下楼梯。 我们将解决将体育活动类型准确确定为分类问题的问题。
标签将对应以下内容:
1-步行
2-爬楼梯
3-下楼梯
4座
5-这时一个人站在
6-该人在撒谎
include("kNN.jl") training = readdlm("samsung_train.txt"); training_label = readdlm("samsung_train_labels.txt"); testing = readdlm("samsung_test.txt"); testing_label = readdlm("samsung_test_labels.txt"); training_label = map(Int, training_label) testing_label = map(Int, testing_label) z = main(training, vec(training_label), testing, 7) n = length(testing_label) println(sum(testing_label .== z[1]) / n)
结果: 0.9053274516457415通过正确预测的对象与整个测试样品的比率来评估质量。 似乎还不错。 但是我的目标是向朱莉娅展示,并且让他在数据科学领域占有一席之地。
可视化
接下来,我想尝试可视化分类结果。 为此,您需要构建一个二维图片,该图片具有561个符号并且不知道哪个符号最重要。 因此,为了减少特征的正交子空间的维数和后续数据设计,决定使用
主成分分析 (PCA)。 在Julia中,就像在Python中一样,有现成的软件包,因此我们可以简化我们的生活。
using MultivariateStats #for PCA A = testing[1:10,:] #PCA for A M_A = fit(PCA, A'; maxoutdim = 2) Jtr_A = transform(M_A, A'); #PCA for training M = fit(PCA, training'; maxoutdim = 2) Jtr = transform(M, training'); using Gadfly #shows training points and uncertain point pl1 = plot(training, layer(x = Jtr[1,:], y = Jtr[2,:],color = training_label, Geom.point), layer(x = Jtr_A[1,:], y = Jtr_A[2,:], Geom.point)) #predicted values for uncertain points from testing data z1 = main(training, vec(training_label), A, 7) pl2 = plot(training, layer(x = Jtr[1,:], y = Jtr[2,:],color = training_label, Geom.point), layer(x = Jtr_A[1,:], y = Jtr_A[2,:],color = z[1], Geom.point)) vstack(pl1, pl2)
在第一个图中,标记了训练集和测试集中的几个对象,需要将其分配给他们的班级。 因此,第二张图显示这些对象已被标记。

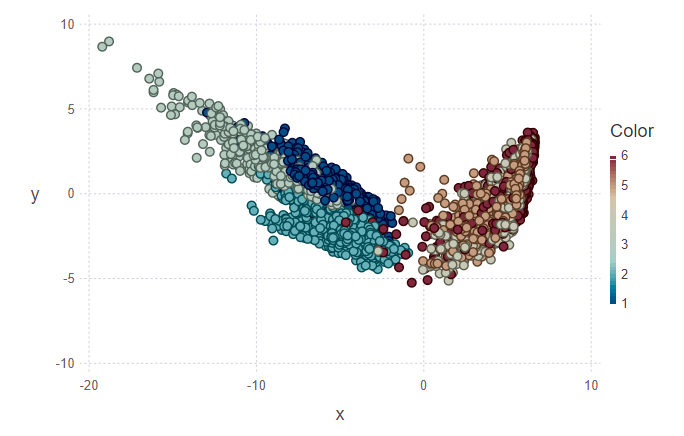
println(z[1][1:10], z[2][1:10]) > [5, 5, 5, 5, 5, 5, 5, 5, 5, 4][1.0, 0.888889, 0.888889, 0.888889, 1.0, 1.0, 1.0, 1.0, 0.777778, 0.555556]
看着图像,我想问一个问题:“为什么这些簇很丑?”。 我会解释。 由于数据的性质和PCA的使用,未对各个群集进行非常清晰的划分。 对于PCA,只是走楼梯和爬楼梯就像一堂课-运动课。 因此,第二类是其余的类(坐着,站着,躺着,它们之间不是很明显的区别)。 因此,可以将明确的分隔分为两类,而不是六种。
结论
对我而言,这只是Julia的初衷,也是该语言在机器学习中的使用。 顺便说一句,我比专业人士更可能是业余爱好者。 但是,尽管我感兴趣,但我将继续更深入地研究此问题。 许多外国消息人士押注朱莉娅。 好吧,拭目以待。
PS:如果有意思,我可以在以下文章中告诉您有关语法的功能,IDE以及安装时遇到问题的信息。