我们经常被问到为什么不安排数据科学家竞赛。 事实是,根据经验,我们知道其中的解决方案根本不适用于产品。 是的,要雇用那些将处于领先地位的人,这并不总是明智的。
当所有可能的算法和超参数值以组合方式获取,并且所得到的模型在多个级别上使用彼此的信号时,通常会借助所谓的中文堆叠赢得此类比赛。 这些解决方案的常见问题是复杂性,不稳定,调试和支持困难,训练和预测中的资源消耗很高,在模型的重复训练的每个周期中都需要仔细的人工监督。 仅在比赛中这样做是有道理的-出于当地指标和排名排名十分之一的考虑。
但是我们尝试了
大约一年前,我们决定尝试在生产中使用堆叠。 众所周知,尽管线性模型使这种矢量的尺寸很大,但仍可以从表示为单词袋并用tf-idf矢量化的文本中提取有用的信号。 我们的系统已经执行了这样的矢量化处理,因此,对于简历,职位空缺,我们结合起来并不难,并基于它们进行逻辑回归教学,从而针对给定的职位空缺预测候选人通过给定的简历点击的可能性。
然后,由于模型考虑了元属性,因此该预测将被主要模型用作附加功能。 优点是,即使使用ROC AUC 0.7,来自此类元属性模型的信号也很有用。 该实施每天产生约2000个响应。 最重要的是-我们意识到我们可以继续前进。
线性模型未考虑要素之间的非线性相互作用。 例如,无法考虑到,如果简历中有“ C”,而职位空缺中有“系统程序员”,那么响应的可能性就非常高。 除职位空缺和履历外,除文本外,还有许多数字和类别字段,并且在履历中,文本分为许多单独的块。 因此,我们决定为线性模型添加特征的二次扩展,并对字段和块中tf-idf向量的所有可能组合进行分类。
我们尝试使用元符号来预测在各种情况下做出响应的可能性:
- 在职位描述中有一组给定的术语,类别;
- 在空缺的文本字段和简历的文本字段中,遇到了一组特定的术语
- 空缺的文本字段中有一些术语没有在简历的文本字段中找到;
- 空缺中出现某些术语,履历表中符合设定的类别值;
- 在空缺和简历中,满足了一对给定的类别值。
然后,在功能选择的帮助下,他们选择了几十个发挥最大作用的元属性,进行了A / B测试并将其投入生产。
结果,我们每天收到超过23000个新回复。 一些属性在强度上进入了顶部属性。
例如,在推荐系统中,最重要的属性是
在逻辑回归模型中过滤合适的简历:- 简历中的地理区域;
- 简历中的专业领域;
- 工作说明和最近的工作经验之间的区别;
- 空缺和简历的地理区域差异;
- 空缺职位和简历标题之间的区别;
- 空缺职位和简历专业之间的差异;
- 简历中具有一定薪水的申请人单击具有一定薪水的空缺的可能性(逻辑回归的元符号);
- 具有特定简历名称的人单击具有一定工作经验的职位空缺的可能性(逻辑回归的元符号);
在XGBoost模型中过滤相关简历:- 文本中的职位空缺和简历有多相似;
- 空缺的名称和简历的名称之间的差异,以及简历中经验中所有职位的差异,并考虑了文本交互作用;
- 考虑到文本交互,空缺标题和简历标题之间的区别;
- 空缺的名称和简历的名称之间的差异以及简历经验中的所有职位,而没有考虑文本交互作用;
- 具有指定工作经验的候选人出现该名字的空缺的可能性(逻辑回归的元符号);
- 职位描述和简历中以前的工作经验之间的区别;
- 空缺和履历在文字上有多少不同;
- 职位描述和简历中以前的工作经验之间的区别;
- 某个性别的人对某个名字的空缺做出反应的可能性(逻辑回归的元符号)。
在XGBoost的排名模型中:- 空缺名称中出现的,不在简历标题和位置中的术语作出回应的可能性(逻辑回归的元符号);
- 从空缺中匹配区域并恢复
- 职位空缺中没有出现的回应的可能性(逻辑回归的元符号);
- 预计空缺对用户的吸引力(ALS上的元标记);
- 职位空缺和履历表中出现的条款作出回应的可能性(逻辑回归上的元符号);
- 空缺名称与简历中的标题+职位之间的距离,其中术语由用户操作(交互)加权;
- 职位空缺与简历之间的距离;
- 空缺标题与简历名称之间的距离,其中术语由用户的行为(交互)加权;
- 职位空缺和专业化对tf-idf相互作用的响应概率(逻辑回归的元符号);
- 空缺和简历文本之间的距离;
- 通过空缺名称和简历名称(神经网络上的元属性)的DSSM。
良好的结果表明,从这个方向来看,您仍然可以每天以相同的营销成本提取一定数量的回复和邀请。
例如,已知的是,在具有大量征兆的情况下,逻辑回归增加了再训练的可能性。
让我们将简历和职位空缺tf-idf矢量化器与一万个单词和短语的字典一起使用。 那么在逻辑回归中二次展开的情况下,将有2 * 10000 +10000²权重。 显然,由于稀疏,即使是个别情况也能显着影响每个人的体重。
因此,现在我们尝试在逻辑回归中创建元符号,其中使用因子分解机压缩二次展开系数。 我们的10,000平方米的权重表示为尺寸为10,000x150(例如,我们选择的潜在矢量尺寸为150)的潜在矢量矩阵。 同时,压缩过程中的个别案例不再发挥重要作用,该模型开始更好地考虑更一般的模式,而不是记住特定案例。
我们还在已经
写过的DSSM神经网络和我们也
写过的 ALS上使用了元属性,但以一种简化的方式。 总体而言,迄今为止,元属性的引入使我们(和我们的客户)每天对职位空缺的回复超过了4.4万(线索)。
结果,求职建议中的简化模型堆叠方案现在看起来像这样:
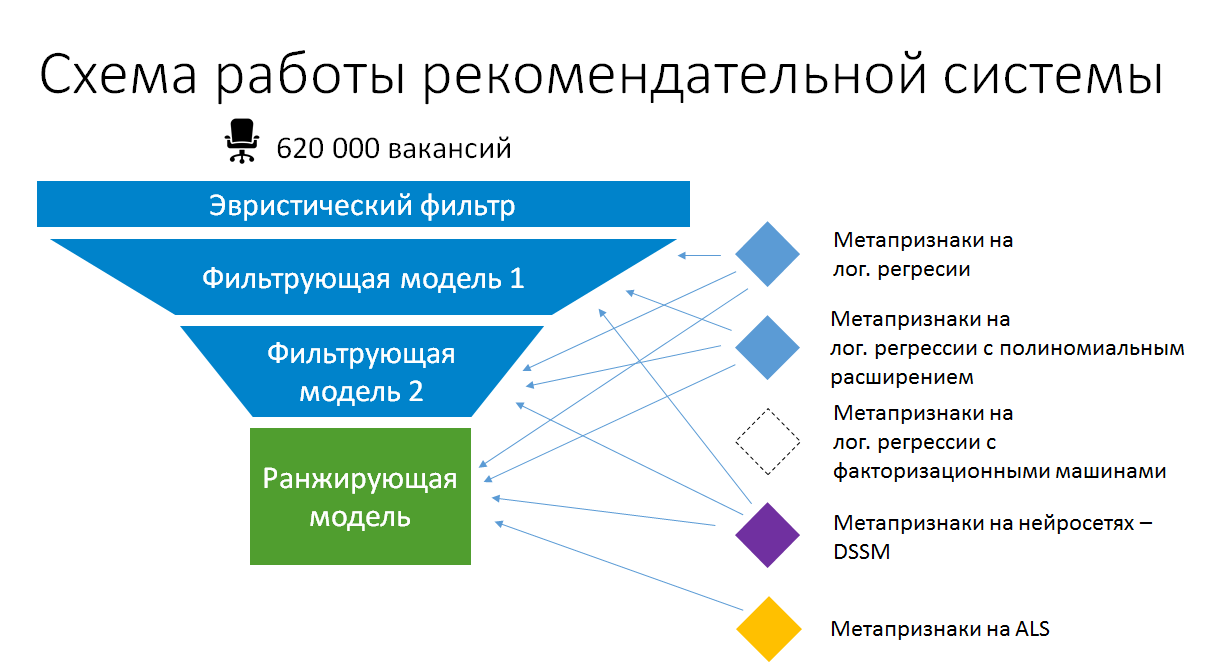
因此,在生产中堆叠是有意义的。 但这不是自动组合堆叠。 我们确保创建元属性所基于的模型保持简单,并最大程度地利用现有数据和计算出的静态属性。 只有这样,它们才能继续生产,而不会逐渐变成不受支持的黑匣子,并保持可以重新训练和改进的状态。