
根据对全球数据中心进行的大量运营评估的结果,Uptime Institute指出,数据中心的人员配备水平因地而异。 这种观察有些令人费解,但这并不奇怪。 尽管人员配备对于试图保持卓越运营的数据中心来说是一项重要活动,但许多其他因素也会影响组织对所需人员配备水平的决策。
在可能影响总体人员配备水平的因素中,可以选择出数据中心的复杂性,人员流动,所需的技术支持工作时间,与承包商签订的合同数量以及可访问性的业务目标。 成本也令人不安,因为每个员工都是数据中心的直接成本。 由于这些因素,有必要不断审查数据中心的人员配备水平,以合理的价格提供有效的支持。
Uptime Institute经常会提出以下问题:“我的数据中心的合适人员配备是多少?” 不幸的是,没有一个简明的答案适用于每个数据中心。 适当的人员配备取决于许多变量。
完成维护任务和确保完成技术支持转换所需的时间是两个主要变量。 满足维护要求的人员配备是一个相对固定的因素,但是取决于数据中心人员执行哪些操作以及将什么功能分配给承包商。 人员配置技术支持转移的定义是用于监视数据中心以及响应任何事件和事件的人员配备。 可以通过多种方式确定技术支持班次的人员配备。 每种人员配置方法都会对运营产生潜在影响,具体取决于技术支持涵盖哪些流程。
转变趋势
长期配备合格人员的主要目的是通过防止事故,制止或隔离事故,以及防止事故蔓延或影响其他系统,来最大程度地减少由异常事件引起的故障风险。 许多数据中心仍在不断提供由24x7全天候工作模式的合格电工,机械工程师和其他技术人员组成的团队。 但是,远程监控技术,复杂形式的建筑物的特殊布置,平衡成本的愿望和其他原因可能促使组织以不同的方式招募人员。
由于对异常事件的响应延迟,因此在任何时候都没有合格人员的情况下管理技术支持制度可能会增加风险。 最终,公司必须做出具有可接受风险水平的决策。
其他全覆盖技术支持模型包括:
- 培训安全人员应对警报并执行解决问题的程序;
- 通过本地或区域建筑物监视系统(BMS)监视数据中心,并请呼叫技术人员参与;
- 在正常工作时间内可在现场工作,并在晚上和周末随时待命;
- 多个数据中心以建筑物的特殊建筑群的形式工作,其团队为多个数据中心提供支持,而无需随时在每个单独的数据中心中进行部署。
这些和其他方法应分别根据有效性进行评估。 为了评估技术支持模型,数据中心必须确定数据中心事件的潜在风险及其对业务的潜在影响。
在过去的20年中,Uptime Institute利用从Uptime Institute Network成员那里收到的信息,建立了异常事件数据库(异常事件报告,AIR)。 Uptime Institute每年都会分析数据,并将结果提供给网络成员。 AIRs数据库包含有关人员问题和数据中心有效人员配置模型的有趣信息。
工作时间以外发生事故
2013年,一小部分事件(共277起)发生在营业时间。 但是,有44%的事件发生在午夜至上午8:00之间,这突显了对24x7全天候技术支持模式的潜在需求(见图1)。
图1. 2013年发生的异常事件中,约有一半发生在上午8点至中午之间,另一半发生在午夜至上午8点之间。
事件可能在一年中的任何时候发生。 将员工在一年中的特定时间的活动重点放在其他活动上不会有效果(例如,休假禁令)。 全年的事件分布相当平均。
图2显示了星期几中事件的分布。 该图显示一周中的每一天所占份额几乎相等,这表明对于一周中每一天的轮班,人员配备应相同。 这是一个重要的结论,因为一些数据中心在星期一至星期五的时间里集中了其技术支持的劳动力资源,而将几天的时间留给了远程监控(见图2)。
图2.数据中心人员必须在一周的每一天准备就绪。行业事件
图3进一步说明了行业事件,并且没有显示行业之间趋势的显着差异。 该图显示,金融服务行业报告的事件远多于其他行业,但这更可能反映了样本的构成。
 图3.数据中心的事件全年发生。
图3.数据中心的事件全年发生。故障原因及检测方法
知道何时发生事件,对于应配备哪些人员几乎无能为力。 了解哪些事件最常发生将有助于改变班次结构,并找出如何最常发现事件。 图4显示,大多数事件影响电气系统,其次是机械系统。 相反,关键的IT工作负载会导致相对较少的事件。
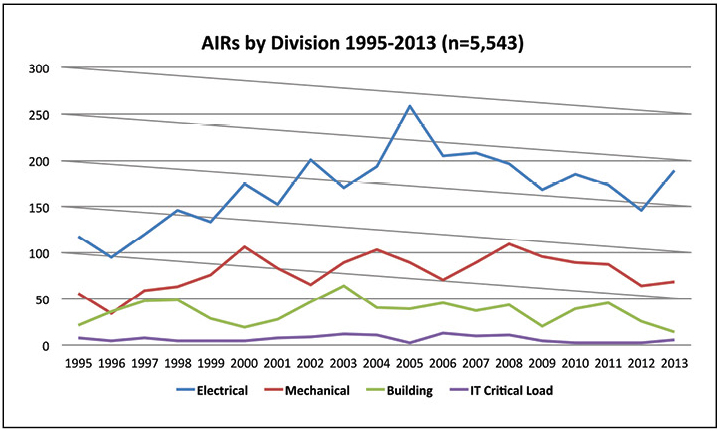 图4. 2013年报告的异常事件中,有一半以上与电气系统有关。
图4. 2013年报告的异常事件中,有一半以上与电气系统有关。因此,所有班次的团队都有足够的经验来应对电气系统中最常见的事件是很有意义的。 支持团队还应应对其他类型的事件。 在机械和建筑系统上对电气工程师进行交叉培训可以提供足够的覆盖范围,并且呼叫服务员可以覆盖相对罕见的IT事件。
AIRs数据库还阐明了如何检测事件。 图5显示,2013年检测到的所有事件的主要信息中,有一半以上是从警报系统获得的,超过40%的事件是由现场技术专家检测到的,总计占案例总数的95%。 图中显示的多年来最大的变化是警报检测到的事件缓慢增长。
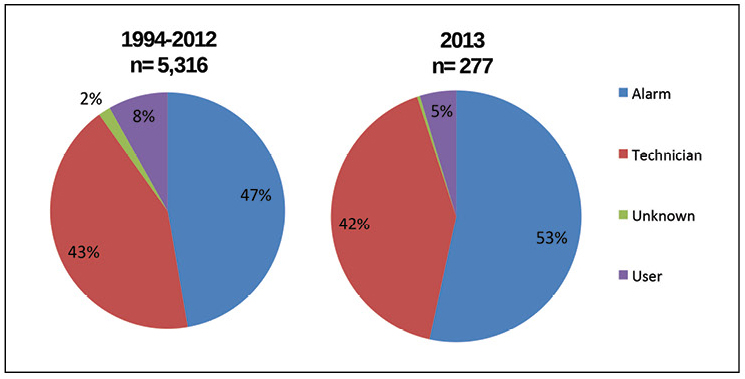 图5.警报现在是检测大多数事件的一种方法; 但是,可访问性问题通常是技术专家发现的。
图5.警报现在是检测大多数事件的一种方法; 但是,可访问性问题通常是技术专家发现的。但是,警报无法响应事件或减轻后果。 Uptime Institute见证了许多方法,这些方法可以使数据中心避免出现故障并减少其影响。 这些方法要求人员对事件做出响应,在关键系统中创建冗余,并需要有效的预测性维护程序来在潜在故障发生之前进行预测。 图6显示了每种方法“拯救”数据中心的频率。
 图6. 2013年设备冗余带来的“救援”比往年更多。
图6. 2013年设备冗余带来的“救援”比往年更多。该图还显示,近年来,设备冗余和预防性维护变得更加高效,并为数据中心节省了越来越多的钱。 对此有几种可能的解释,包括提高系统的可靠性,更广泛地使用主动服务和削减预算,这导致人员数量或其在数据中心外的流动减少。
根本原因下的失败
数据显示,2013年所有可访问性问题都是由电气系统事件引起的。 发生大多数故障是因为维护程序未正确执行。 这一发现强调了采取适当程序和训练有素的员工的重要性。
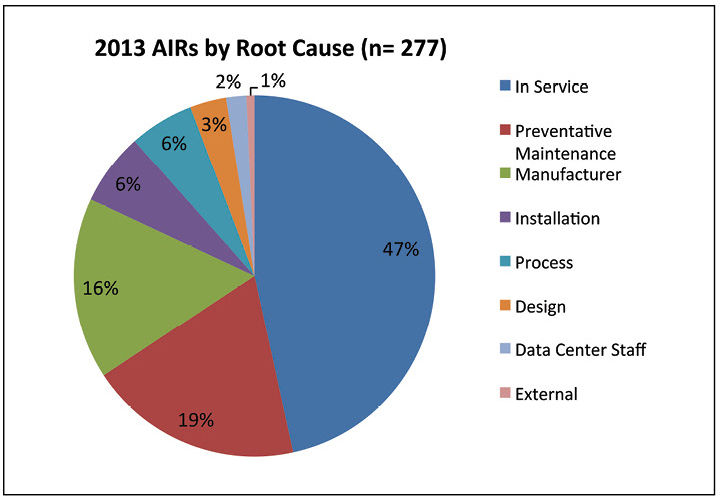 图7. 2013年报告的故障中,近一半是由于维护问题造成的。
图7. 2013年报告的故障中,近一半是由于维护问题造成的。在图。 图7进一步讨论了2013年事件的原因。 大约一半的事件被描述为“服务中”,这被定义为维护不充分,设备设置不正确,无法工作或缺少特定的根本原因。 “预防性维护”实际上是指未正确执行的预防性维护。 数据中心人员仅造成2%的事件,这表明人员和设备的交互不是事件和故障的主要原因。
结论
管理数据中心基础架构(DCIM),建筑物管理系统(BMS)和建筑物自动化系统(BAS)的复杂性日益增加,因此很难找到是否有可能减少数据中心人员数量的问题的答案。 改善这些系统的进步是重要的。 它们可以提高数据中心的性能。 但是,数据表明,事故预防通常需要现场人员。 这就是为什么继续拥有专职同等人员编制(FTE)的目的,是针对Tier III和Tier IV认证数据中心的指示。
主要目标是提供快速响应时间,以减轻任何事件和事件的后果。 数据显示,当事件发生时,没有观察到临时模式。 它们的外观在一周的所有24小时和所有7天中分布良好。
主要目标是预防风险。 数据中心在不断发展,可以通过远程访问进行管理并增加硬件冗余。 每个数据中心都是唯一的,并有其自身的固有风险。 技术支持模式只是一个因素,但非常重要。 决定每个班次要雇用多少员工以及具有什么资格才能对风险预防和数据中心的可用性产生重大影响。 做出明智的选择。
其他Cloud4Y博客文章:→
中小型企业IT基础架构停机的真正成本是多少? (外部链接)→
工业企业自动化中云计算的鼎盛时期(外部链接)→
近年来云计算的价格正在发生什么变化(Habr)→
如何为统一生物特征识别系统创建样本以及其为何可能具有危险性(Habr)