也许今天没有其他技术可以带来如此多的神话,谎言和无能。 谈论技术谎言的记者,谈论成功实施的政治人物,大多数技术卖家都在说谎。 每个月,我都会看到人们尝试在无法使用人脸识别的系统中尝试实现人脸识别的后果。

很久以前,这篇文章的主题变得很痛苦,但是以某种方式太懒了以至于无法编写它。 我已经对不同的人重复了二十多次。 但是,在阅读了下一包垃圾之后,我仍然确定是时候了。 我将提供这篇文章的链接。
这样啊 在本文中,我将回答一些简单的问题:
- 有可能在街上认出你吗? 以及如何自动/可靠?
- 前天,他们写道,罪犯被拘留在莫斯科地铁中,昨天,他们写道, 他们不能在伦敦。 而且在中国,他们认识每个人,大街上的每个人。 他们在这里说28位美国国会议员是罪犯。 或者,他们抓到一个小偷。
- 谁现在发布面部识别解决方案,解决方案,技术功能之间有什么区别?
大多数答案将基于证据,并链接到研究,其中显示了算法的关键参数+以及计算数学。 一小部分将基于各种生物识别系统的实施和操作经验。
我现在不会详细介绍如何实现人脸识别。 在哈布雷(Habré)上有很多关于该主题的好文章:
a ,
b ,
c (当然,还有很多这样的文章会在内存中弹出)。 但是,仍然有一些影响不同决策的观点-我将描述。 因此,阅读以上至少一篇文章将简化对本文的理解。 让我们开始吧!
简介,依据
生物识别技术是一门精确的科学。 短语“始终有效”和“理想”没有余地。 一切都经过深思熟虑。 要计算,您只需要知道两个数量:
- 第一种错误-一种情况,即某人不在我们的数据库中,但我们将其标识为存在于数据库中的某人(以生物识别FAR(错误访问率)表示)
- 第二种错误-当一个人在数据库中但我们错过了他的情况。 (在生物识别FRR(错误拒绝率)中)
这些错误可能具有许多功能和应用标准。 我们将在下面讨论它们。 同时,我会告诉您在哪里获得它们。
特点
第一种选择 。 从前,制造商自己发布了错误。 但问题是:您不能信任制造商。 在什么条件下以及他如何测量这些错误-没有人知道。 而且无论是衡量还是市场部门都吸引。
第二种选择。 开放基地出现了。 制造商开始在基础上指出错误。 对于知名数据库,可以对算法进行改进,以使它们显示出令人敬畏的质量。 但是实际上,这样的算法可能行不通。
第三种选择是公开比赛,采用封闭式解决方案。 组织者检查决定。 本质上是嘲笑。 其中最著名的是
MegaFace 。 这项比赛的第一名曾经获得很高的知名度。 例如,N-Tech和Vocord在MegaFace上大有名气。
一切都会好的,但是说实话。 您可以在此处自定义解决方案。 这更困难,更长。 但是您可以计算人员,可以手动标记基准,等等。 最重要的是-它与系统如何处理实际数据无关。 您现在可以看到谁是MegaFace的领导者,然后在下一段中寻找这些人的解决方案。
第四个选择 。 迄今为止,最诚实的。 我不知道怎么在那儿作弊。 虽然我不排除它们。
一家举世闻名的大型研究所同意部署一个独立的解决方案测试系统。 从制造商处收到的SDK会受到封闭测试,制造商不参与其中。 测试具有许多参数,然后将其正式发布。
现在,这样的
测试是由NIST-美国国家标准技术研究院进行的。 这样的测试是最诚实和有趣的。
我必须说NIST做得很好。 他们开发了五个案例,每两个月发布一次新更新,不断改进并包括新的制造商。 您可以在这里找到最新的研究报告。
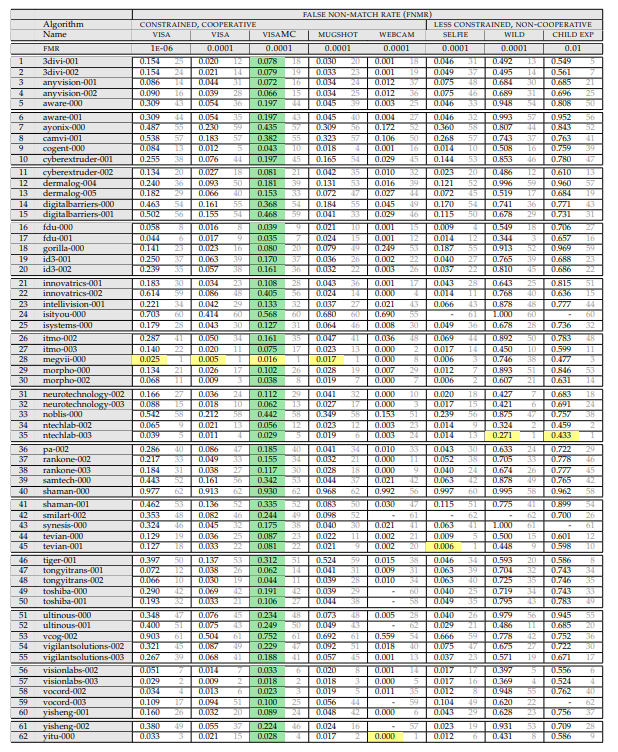
看来该选项非常适合分析。 但是不! 这种方法的主要缺点是我们不知道数据库中包含什么。 在此查看此图表:

这是进行测试的两家公司的数据。 x轴是月份,y轴是错误的百分比。 我参加了“狂野面孔”测试(仅在描述下方)。
在两家独立的公司中,准确性突然提高了10倍(通常,每个人都从那里起飞)。 从哪里来?
NIST日志显示“数据库太复杂了,我们简化了。” 而且没有旧基础或新基础的例子。 我认为这是一个严重的错误。 在旧的基础上,可以看到供应商算法之间的差异。 在新的所有通行证的4-8%。 而在旧的上,它是29-90%。 我在CCTV系统上与人脸识别的交流说早了30%-这是大师算法的真实结果。 从此类照片很难识别:

当然,4%的精度对它们没有影响。 但是,如果不了解NIST的基础,则不可能100%做出此类声明。 但是NIST是主要的独立数据源。
在本文中,我描述了2018年7月的相关情况。 同时,根据旧的人员数据库,我依靠准确性来进行与“野性面孔”任务相关的测试。
半年内可能会完全改变。 也许在未来十年内它将保持稳定。
因此,我们需要此表:
(2018年4月,因为这里更适合野性生活)
让我们看看其中写的内容及其度量方式。
以上是实验列表。 实验包括:
被测量的那个。 集是:
- 护照照片(理想,正面)。 背景为白色,是理想的拍摄系统。 有时可以在检查点找到它,但很少见。 通常,此类任务是将机场人员与基地人员进行比较。

- 摄影是一个很好的系统,但是没有最高质量。 有背景背景,一个人可能站不稳/从相机旁看,等等。

- 来自智能手机/电脑摄像头的自拍照。 当用户合作时,拍摄条件差。 有两个子集,但自拍照中只有很多照片。

- “野性面孔”-几乎从任何侧面拍摄/隐藏拍摄脸部与相机的最大旋转角度为90度。 这就是NIST大大简化了基础的地方。

- 孩子们 所有算法对儿童而言效果不佳。
此外,在什么级别的第一类错误上进行测量(仅对于护照照片考虑此参数):
- 10 ^ -4-FAR(第一种假阳性),用于与基数的一万次比较
- 10 ^ -6-每百万与基数比较的FAR(第一种假阳性)
实验的结果是FRR值。 我们错过了数据库中人员的可能性。
细心的读者已经在这里注意到了第一个有趣的观点。 “ FAR 10 ^ -4是什么意思?” 这是最有趣的时刻!
主要设定
这样的错误在实践中意味着什么? 这意味着以10,000人为基准,对任何普通人进行检查时,都会有一个错误的巧合。 也就是说,如果我们有1000名罪犯,并且每天与10,000人进行比较,那么我们平均会有1000个误报。 有人真的需要吗?
实际上,一切都还不错。
如果您查看建立第一类错误对第二类错误的依赖关系图,就会得到非常酷的画面(这里是十家不同公司的Wild选项,如果将摄像头放在某个地方让人们看不到,这将在地铁站发生) :
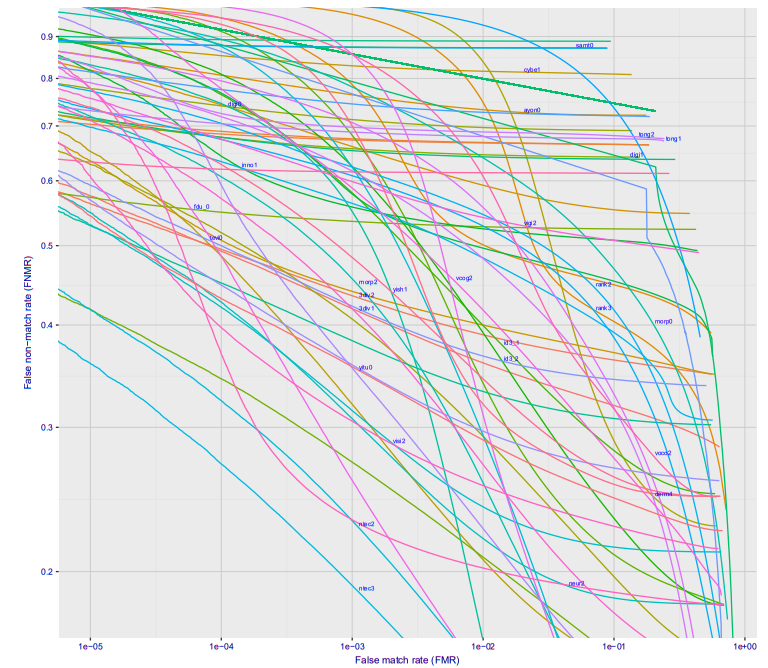
错误为10 ^ -4的人中,有27%无法识别。 10 ^ -5约40%。 10 ^ -6损失最有可能约为50%
那么,这在实数中是什么意思?
最好摆脱“一天可以犯多少错误”的范式。 我们的工作人员站很多,如果系统每20-30分钟给出一次误报,那么没人会认真对待。 我们每天最多可在地铁站修复10个误报事件(如果最好不要因为烦人而关闭系统,则更少)。 莫斯科地铁一站的日流量为
20-120 000人。 平均为6万。
将FAR的固定值设为10 ^ -6(您不能在下面将其设置为零,如果我们乐观的话,我们将失去50%的犯罪分子)。 这意味着我们可以允许10个错误警报,基本人数为160人。
是很多还是一点? 联邦通缉名单上的基地规模约为
30万人 。 国际刑警组织3.5万名。 合理地假设大约需要3万名莫斯科人。
这将提供不切实际的错误警报数量。
值得注意的是,如果系统在线工作,则160人可以满足需要。 如果您要寻找在最后一天犯罪的人-这已经是相当大的工作量了。 同时,戴着黑色眼镜/帽子等,你可以掩饰自己。 但是有多少人在地铁里载着他们呢?
第二个重点。 在地铁中制作一个系统,以提供更高质量的照片很容易。 例如,将其放在摄像机旋转门的框架上。 到10 ^ -6,损失已经不会是50%,而只有2-3%。 并以10 ^ -7 5-10%递增。 从Visa图表的准确性来看,在真实相机上,一切肯定会差很多,但是我认为在10 ^ -6下,您可以留下10%的损失:

同样,系统不会拉低3万的基数,但是实时发生的所有事情都将允许检测。
第一个问题
似乎是时候回答问题的第一部分了:
Liksutov
说 ,已经确认了22名通缉犯。 这是真的吗
在这里,主要的问题是这些人从事什么工作,检查了多少不想要的人,多少面部识别有助于拘留这22人。
如果这些人很可能是“拦截”计划所要寻找的人,那么他们实际上就是被拘留者。 这是一个很好的结果。 但是我的谦虚假设允许我说,要达到这个结果,至少要检查2-3千人,而要检查的人大约是一万人。
伦敦的数字很好地打败了他。 在人们
抗议的时候 ,只有这些数字被诚实地公布了。 我们沉默了...
昨天在哈布雷(Habré)上有一篇关于人脸识别中
虚假面孔的文章。 但这是在相反方向上进行操纵的示例。 亚马逊从来没有一个好的人脸识别系统。 加上如何设置阈值的问题。 通过扭曲设置,我至少可以制成100%的花生;)
关于中国人,他们认识大街上的每个人-一个明显的假货。 虽然,如果他们进行了有效的跟踪,那么您可以在其中进行一些更充分的分析。 但是,老实说,到目前为止,我不认为这是可以实现的。 而是一组插头。
那我的安全呢? 在大街上,在集会上?
让我们走得更远。 让我们再评估一下。 在社交网络中搜索具有知名传记和良好个人资料的人。
NIST检查面对面的识别。 拍摄相同/不同人的两个面孔,并比较它们彼此之间的亲密程度。 如果接近度大于阈值,则这是一个人。 如果进一步-不同。 但是有另一种方法。
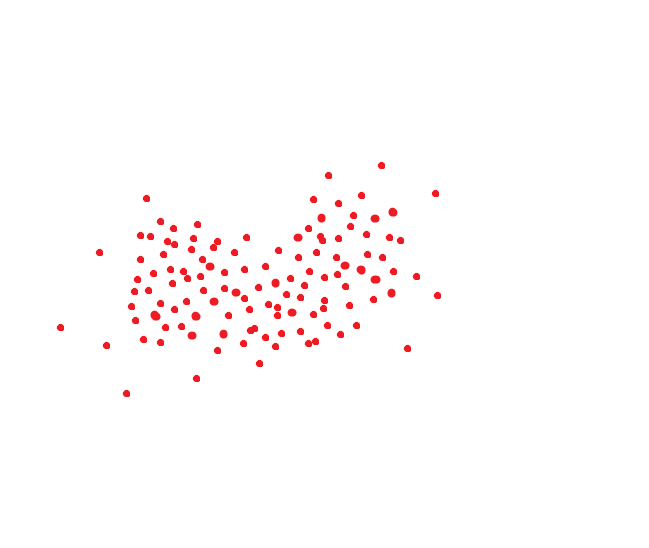
如果您阅读了我一开始就建议的文章,那么您就会知道,识别人脸时,会生成人脸的哈希码,并在N维空间中显示其位置。 通常,这是256/512维空间,尽管所有系统都有不同的方式。
理想的人脸识别系统会将相同的面部转换为相同的代码。 但是,没有理想的系统。 一个人和一个人通常占用一些空间。 好吧,例如,如果代码是二维的,则可能是这样的:
如果我们以NIST所采用的方法为指导,那么此距离将是一个目标阈值,以便我们可以将一个人识别为同一个人,且概率为95%:
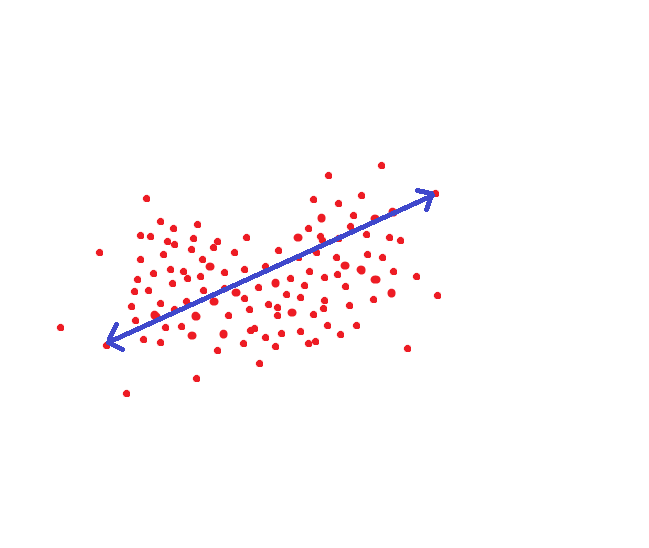
但是您可以选择其他方式。 为每个人配置存储对他有效的值的超空间区域:

然后,在保持精度的同时,阈值距离将减小几倍。
每个人只需要很多照片。
如果一个人在社交网络上有自己的个人资料/以其不同年龄的图片为基础,则可以大大提高识别的准确性。 我不知道FAR | FRR如何增长的确切评估。 评估这样的数量已经是不正确的。 此数据库中某人有2张照片,某人有100张照片。很多包装逻辑。 在我看来,最大额定值为一个/一个半订单。 这使您可以将10 ^ -7添加到错误中,而无法识别20-30%。 但这是投机和乐观的。
总的来说,这个空间的管理当然不存在几个问题(年龄芯片,图像编辑器芯片,噪声芯片,清晰度芯片),但是据我了解,其中大多数已经被需要解决方案的大公司成功解决了。
我为什么要这样做。 此外,使用配置文件可以多次提高识别算法的准确性。 但这远非绝对。 配置文件需要大量的手工工作。 有很多类似的人。 但是,如果您开始设置年龄,位置等方面的限制,那么此方法将为您提供良好的解决方案。 对于他们如何根据“通过照片查找个人资料”->“使用个人资料搜索人”的原理找到一个人的示例,我在开头给出了一个
链接 。
但是,我认为这是一个高度可扩展的过程。 再者,在个人资料中有大量照片的人,上帝禁止在我们国家使用40-50%。 是的,其中许多是儿童,他们的一切工作都很糟糕。
但是,再次-这是一种评估。
所以在这里。 关于您的安全。 您拥有的个人资料照片越少越好。 你去的集会越大越好。 没有人会手动解析2万张照片。 对于那些关心他们的安全性和隐私权的人-我建议您不要使用图片进行个人资料设置。
在一个拥有十万人口的城市举行的集会上,他们可以通过观看1-2场比赛轻松找到您。 在莫斯科,他们陷入了困境。
大约半年前,与我们一起工作的
Vasyutka就这个话题发表了
演讲 :
顺便说一下,关于社交网络
然后,我允许自己进行一些短途旅行。 人脸识别算法的训练质量取决于三个因素:
- 脸的质量。
- 在训练三重态损耗,中心损耗,球面损耗等过程中使用的人员接近度度量。
- 基本尺寸
根据权利要求2,似乎已经达到极限。 原则上,数学在这类事物上发展很快。 即使在三重态损失之后,其余的损失函数也不会产生显着的增加,只是平滑地改善和减小了基址大小。
如果您需要从各个角度查找丢失了百分之几的面部,则很难提取面部。 但是创建这样的算法是一个相当可预测且管理良好的过程。 一切越蓝,越能正确处理大角度越好:

六个月前是这样的:

可以看出,越来越多的公司正在以这种方式缓慢发展,算法开始识别出越来越多的面孔。
但是随着基地的规模-一切都变得更加有趣。 开放式基地很小。 最多可容纳数万人的良好基地。 那些大的文件结构奇怪/不好(
megaface ,
MS-Celeb-1M )。
您认为算法的创建者从何处获得这些数据库?
小提示。 他们目前正在开发的第一个NTech产品是Find Face,这是一个人与人联系的搜索人。 我认为不需要任何解释。 当然,与机器人打斗会缩小所有打开的配置文件。 但是,据我所知,人们仍然在动摇。 和同学们。 和instagram。
好像使用Facebook一样-那里的一切都更加复杂。 但是我几乎可以肯定,还有一些发明。
所以是的,如果您的个人资料是开放的,那么您可以感到骄傲,它是用来学习算法的;)
关于解决方案和公司
在这里,您可以感到自豪。 在全球的5家领先公司中,现在有两家是俄罗斯公司。 这些是N-Tech和VisionLabs。 半年前,NTech和Vocord是领导者,前者在旋转的面孔上效果更好,后者在正面。
现在,其余的领导者-1-2家中国公司和1名美国人,Vocord在评分中超过了某些水平。
在itmo,3divi,intellivision的排名中仍然是俄罗斯人。 Synesis是一家白俄罗斯公司,尽管有些公司曾经在莫斯科,但大约3年前,他们有一个关于Habré的博客。 我也知道它们属于外国公司的几种解决方案,但是开发办公室也在俄罗斯。 仍然有几家俄罗斯公司没有参加竞争,但似乎有很好的解决方案。 例如,千年发展目标就有。 显然,Odnoklassniki和Vkontakte也有自己的好产品,但它们仅供内部使用。
简而言之,是的,我们和中国人的表情大多发生了变化。
通常,NTech是世界上第一个显示良好的新级别参数的人。
2015年底的某个地方。 VisionLabs只追赶NTech。 在2015年,他们是市场领导者。 但是他们的解决方案是上一代产品,直到2016年底他们才开始尝试赶上NTech。
老实说,我不喜欢这两家公司。 非常激进的营销。 我看到那些显然没有适当解决方案并不能解决问题的人。
在这一方面,我更喜欢Vocord。 他以某种方式建议Vokord坦白地说的人:“您的项目将不适用于此类摄像机和安装点。” NTech和VisionLabs高兴地尝试出售。 但是Vokord最近消失了。
结论
在结论中,我想说以下。
人脸识别是一个非常好的强大工具。它确实可以让您今天找到罪犯。但是其实现需要对所有参数进行非常准确的分析。在某些应用程序中,有足够的OpenSource解决方案。在某些应用程序中(在人群中的体育场得到认可),您只需要安装VisionLabs | Ntech,并保留一个服务,分析和决策团队。而且OpenSource不会在这里为您提供帮助。今天,人们无法相信所有可以捉住所有罪犯的故事,或者是看着城市中每个人的故事。但重要的是要记住,此类事情可以帮助抓获犯罪分子。例如,不是每个人都停在地铁里,而是只有系统认为相似的人才能停在地铁里。放置摄像机,以便更好地识别面部并为此创建适当的基础结构。尽管例如,我反对这一点。对于错误的代价,如果您被公认是别人,那就太高了。