我们已经在
公司博客的第一篇文章中写到了用于检测可转让借款的算法的工作原理。 该文章中只有几段专门讨论比较文本的主题,尽管该想法值得更详细的描述。 但是,正如您所知,尽管一个人确实愿意,但不能立即说出一切。 为了向这个话题和我们称之为“
自动编码器 ”的网络体系结构致敬,
Oleg_Bakhteev和我写了这篇评论。

资料来源:
NLP深度学习(无魔术)正如我们在那篇文章中提到的,文本的比较是“语义的”-我们没有比较文本片段本身,而是比较了与它们相对应的向量。 这些向量是通过训练神经网络而获得的,该神经网络将任意长度的文本片段显示为较大但固定尺寸的向量。 如何获得这种映射以及如何教导网络产生期望的结果是一个单独的问题,下面将对此进行讨论。
什么是自动编码器?
形式上,神经网络称为自动编码器(或自动编码器),它训练以恢复在网络输入处接收到的对象。
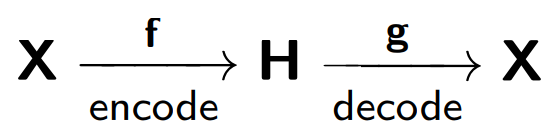
自动编码器由两部分组成:一个编码器
f ,它将样本
X编码为其内部表示
H ;一个解码器
g ,还原原始样本。 因此,自动编码器尝试将每个样本对象的还原版本与原始对象组合在一起。
训练自动编码器时,以下功能被最小化:
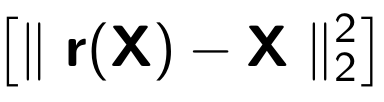
其中
r代表原始对象的还原版本:

考虑
blog.keras.io中提供的
示例 :

网络接收对象
x作为输入(在我们的示例中为数字2)。
我们的网络将此对象编码为隐藏状态。 然后,根据潜在状态,恢复对象
r的重建,该重建应类似于x。 如我们所见,还原的图像(右侧)变得更加模糊。 可以通过以下事实来解释这一点:我们试图仅在对象的最重要标志处保留隐藏的视图,因此对象将丢失而被恢复。
自动编码器模型是根据电话损坏的原理进行训练的,其中一个人(编码器)将信息
(x )传输给第二个人(解码器
) ,然后他又将其告知第三个人
(r(x)) 。
这种自动编码器的主要目的之一是减小源空间的尺寸。 当我们处理自动编码器时,神经网络训练过程本身使自动编码器记住对象的主要特征,从而可以更轻松地恢复原始样本对象。
在这里,我们可以用
主成分法进行类比:这是一种减小维数的方法,其结果是将样本投影到该样本方差最大的子空间上。
的确,自动编码器是主成分方法的概括:在我们只考虑线性模型的情况下,自动编码器和主成分方法给出相同的矢量表示。 当我们考虑将更复杂的模型(例如多层完全连接的神经网络)作为编码器和解码器时,就会出现这种差异。
用神经网络减少数据的维数一文中提供了一个比较主成分方法和自动编码器的示例:
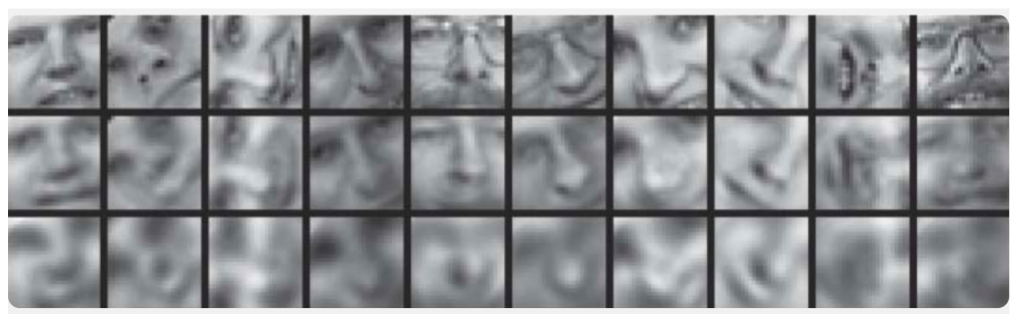
在此,说明自动编码器的训练结果和用于采样人脸图像的主要成分方法。 第一行显示了来自对照样本的人的面孔,即 来自样本的特殊延期部分,该部分在学习过程中未被算法使用。 在第二行和第三行分别是从自动编码器和主成分方法的隐藏状态恢复的相同尺寸的图像。 在这里,您可以清楚地看到自动编码器的效果。
在同一篇文章中,另一个说明性示例:比较自动编码器和
LSA方法的结果以进行信息检索。 与主成分方法一样,LSA方法是一种经典的机器学习方法,通常用于与自然语言处理有关的任务中。

该图显示了使用自动编码器和LSA方法获得的多个文档的2D投影。 颜色表示文档的主题。 可以看出,自动编码器的投影按主题很好地分解了文档,而LSA产生的噪声更大。
自动
编码器的另一个重要应用
是网络预训练 。 当优化的网络足够深时,将使用网络预训练。 在这种情况下,“从头开始”训练网络可能非常困难,因此,首先将整个网络表示为编码器链。
预训练算法非常简单:对于每一层,我们训练自己的自动编码器,然后将下一个编码器的输出同时设置为下一个网络层的输入。 最终的模型由一系列编码器组成,这些编码器经过训练可急于保存对象的最重要特征,每个特征都位于其自己的层上。 预训练方案如下:
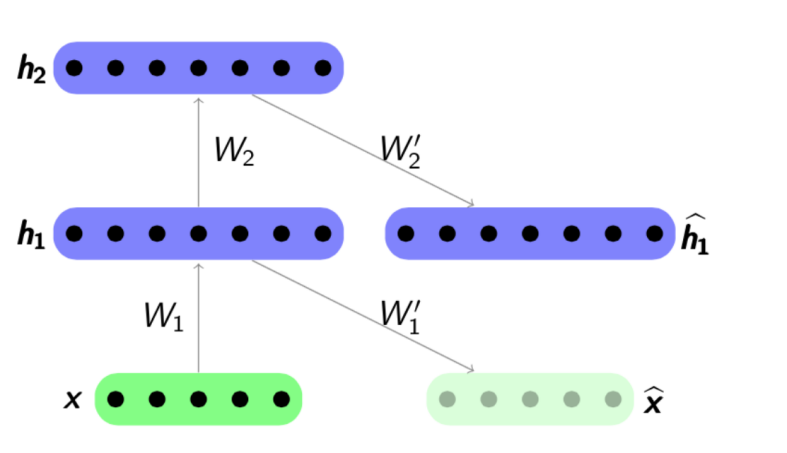
资料来源:
psyyz10.imtqy.com这种结构称为堆叠式自动编码器,通常用作“超频”以进一步训练完整的深度网络模型。 进行神经网络训练的动机是深层神经网络是非凸函数:在训练网络的过程中,参数优化可能会“卡在”局部最小值中。 贪婪的网络参数预训练可以让您找到最终训练的良好起点,从而避免出现此类局部最小值。
当然,我们没有考虑所有可能的结构,因为有
稀疏自动编码器 ,
降噪自动编码器 ,
压缩自动编码器 ,
重构压缩自动编码器 。 它们通过使用各种错误函数和惩罚项而彼此不同。 我们认为,所有这些体系结构都应单独审查。 在本文中,我们首先展示了自动编码器的一般概念以及使用自动编码器解决的特定文本分析任务。
它如何在文本中起作用?
现在我们来看将自动编码器用于文本分析任务的特定示例。 我们对应用程序的两面都感兴趣-两种用于获取内部表示的模型,以及将这些内部表示作为属性使用,例如,在进一步的分类问题中。 关于该主题的文章最常涉及情感分析或措辞检测等任务,但也有一些著作描述了使用自动编码器比较不同语言的文本或进行机器翻译。
在文本分析任务中,对象通常是句子,即 有序的单词序列。 因此,自动编码器恰好接收该单词序列,或者更确切地说,从某些先前训练的模型中获取这些单词的矢量表示。 什么是单词的向量表示形式,例如
在此处 ,已在Habré上进行了足够详细的考虑。 因此,以单词序列作为输入的自动编码器必须根据任务训练整个句子的一些内部表示形式,这些内部表示形式对我们来说很重要。 在文本分析问题中,我们需要将句子映射到向量,以便它们在某种距离函数的意义上很接近,通常是余弦量度:
资料来源:
NLP深度学习(无魔术)Richard Socher是
最早在文本分析中成功使用自动编码器的作者之一。
在他的文章中的
动态池化和展开递归自动编码器的释义检测中,他描述了一种新的自动编码结构-展开递归自动编码器(展开RAE)(请参见下图)。

展开中的RAE
假定句子结构由
句法分析器定义。 考虑了最简单的结构-二叉树的结构。 这样的树由叶子(片段的词,内部节点(分支节点)),短语和终极顶点组成。 以单词序列(x
1 ,x
2 ,x
3 )作为输入(在此示例中为单词的三个向量表示),自动编码器在这种情况下从右到左依次将句子单词的向量表示编码为搭配的向量表示,然后再转换为向量整个报价的介绍。 具体而言,在此示例中,我们首先将向量x
2和x
3连接起来 ,然后将它们乘以尺寸为
hidden×2visible的矩阵
W e ,其中
hidden是隐藏内部表示形式的大小,
visible是词向量的维数。 因此,我们减小尺寸,然后使用tanh函数添加非线性。 第一步,我们得到了短语两个单词
x 2和
x 3的隐藏矢量表示:
h 1 =
tanh(W e [x 2 ,x 3 ] + b e ) 。 在第二个步骤中,我们将其与剩余的单词
h 2 =
tanh(W e [h 1 ,x 1 ] + b e )合并,并获得整个句子
h 2的向量表示。 如上所述,在自动编码器的定义中,我们需要最小化对象及其还原版本之间的错误。 在我们的情况下,这些都是单词。 因此,在接收到整个句子
h 2的最终向量表示之后,我们将解码其还原后的版本(x
1 ',x
2 ',x
3 ')。 此处的解码器与编码器的工作原理相同,只是参数矩阵和移位向量不同:
W d和
b d 。
使用二叉树的结构,您可以将任意长度的句子编码为固定维数的向量-我们始终使用相同的参数
W e矩阵组合一对相同维数的向量。 在非二叉树的情况下,如果我们要组合两个以上的单词-3,4,... n,则只需要提前初始化矩阵,在这种情况下,矩阵将只是
隐藏维
×不可见维。
值得注意的是,在本文中,训练有素的短语矢量表示不仅用于解决分类问题-还是改写了两个句子。 还显示了搜索最近邻居的实验数据-仅基于接收到的要约向量,搜索样本中最接近它的向量,其含义是:

但是,没有人打扰我们使用其他网络体系结构进行编码和解码,以将单词顺序组合为句子。
这是NIPS 2017文章-
反卷积段落表示学习的示例:

我们看到,使用
卷积神经网络将样本
X编码为隐藏表示
h ,并且解码器以相同的原理工作。
或者这是“
跳过思想向量”文章中使用
GRU-GRU的示例。
这里一个有趣的功能是该模型可以处理三元组句子:(
s i-1 ,s i ,s i +1 )。 句子
s i使用标准GRU公式编码,并且解码器使用内部表示信息
si尝试也使用GRU解码
s i-1和
s i +1 。

这种情况下的操作原理类似于
神经网络机器翻译的标准模型,该模型根据编码器-解码器方案工作。 但是,这里我们没有两种语言,我们将一种语言的短语提交给编码单元的输入,然后尝试恢复它。 在学习过程中,一些内部质量函数会最小化(这并不总是一个重构错误),然后,如果需要,将预训练向量用作另一个问题的特征。
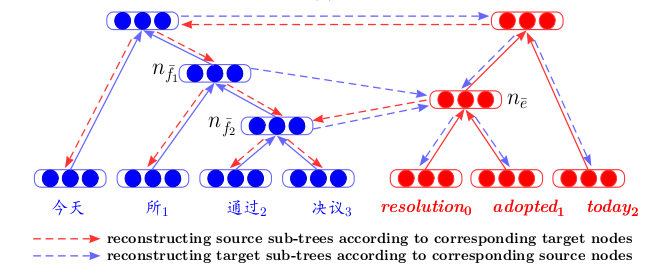
另一篇
名为《统计机器翻译的双语对应递归自动编码器》的论文提出了一种
对机器翻译有新
见解的体系结构。 首先,对于两种语言,分别训练递归自动编码器(根据上述原理-引入了Unfolding RAE)。 然后,在它们之间,训练第三种自动编码器-两种语言之间的映射。 这样的体系结构具有明显的优势-当将不同语言的文本显示在一个公共的隐藏空间中时,我们可以在不使用机器翻译作为中间步骤的情况下进行比较。
关于文本片段的自动编码器的训练通常可以在有关
排名训练的文章中找到。 同样,我们正在训练排名质量的最终功能这一事实很重要,我们首先要对自动编码器进行预训练,以更好地初始化提交给网络输入的请求和响应的向量。

而且,当然,我们不能不提及“
变分自动编码器 ”或
VAE作为生成模型。 当然,最好只是看
一下Yandex的演讲内容 。 我们只要说以下话就足够了:如果要从常规自动编码器的隐藏空间
生成对象,则这种生成的质量会很低,因为我们对隐藏变量的分布一无所知。 但是您可以立即训练自动编码器生成,并引入分布假设。
然后,使用VAE,您可以从此隐藏空间生成文本,例如,文章
“从连续空间生成句子”或
“混合卷积变分自动编码器用于文本生成”一文的作者 。
VAE的生成属性在比较不同语言的文本的任务中也能很好地发挥作用-
诱导跨语言单词嵌入的变体自动编码方法就是一个很好的例子。
最后,我们要作一个小的预测。
表征学习 -准确地使用VAE进行内部表征培训,尤其是与
生成对抗网络结合使用,是近年来发展最快的方法之一-至少可以通过最近
ICLR 2018顶级机器学习
会议上文章中最常见的主题来判断和
ICML 2018 。 这是很合逻辑的-因为它的使用有助于提高许多任务的质量,而不仅仅是与文本有关。 但这是完全不同的评论的主题...